Google Colaboratory を使って、Chainer で 犬、猫の分類に挑戦する!
概要
Connpassの「Chainer x Azure ML Hackathon CV編」に参加してきた際に、
「Cats and Dogs」の分類にをしてみてはどうでしょう と頂いたので、挑戦してみました。
GPUを持っていないので、「Google Colaboratory」を使いました。
以下の点で勉強になりました。
・Chainerを利用し、CNN用の画像を読み込ませる方法
・画像のリサイズ、リシェイプ
・Google Colaboratoryと、GoogleDriveの連携
DeepLearning は、理解できていない部分もあるので、間違っているかもしれません。
その時は、指摘いただけると、ありがたいです!
環境構築
Google Colaboratory で、ノートブックを新規作成する
「ファイル 」ー 「Python3のノートブックを新規作成」をクリックします。
colabをGPUインスタンスにする。
ランタイム - ランタイムのタイプを選択 より、ハードウェアアクセラレータをGPUに変更し、保存します。
Chainerのインストール
ここを参考にしました。
!pip uninstall chainer -y
!pip uninstall cupy-cuda80 -y
!apt -y install libcusparse8.0 libnvrtc8.0 libnvtoolsext1
!ln -snf /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so.8.0 /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so
!pip install 'chainer==4.0.0b4' 'cupy-cuda80==4.0.0b4'
[33mSkipping chainer as it is not installed.[0m
[33mSkipping cupy-cuda80 as it is not installed.[0m
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following NEW packages will be installed:
libcusparse8.0 libnvrtc8.0 libnvtoolsext1
0 upgraded, 3 newly installed, 0 to remove and 0 not upgraded.
Need to get 28.9 MB of archives.
After this operation, 71.6 MB of additional disk space will be used.
Get:1 http://archive.ubuntu.com/ubuntu artful/multiverse amd64 libcusparse8.0 amd64 8.0.61-1 [22.6 MB]
Get:2 http://archive.ubuntu.com/ubuntu artful/multiverse amd64 libnvrtc8.0 amd64 8.0.61-1 [6,225 kB]
Get:3 http://archive.ubuntu.com/ubuntu artful/multiverse amd64 libnvtoolsext1 amd64 8.0.61-1 [32.2 kB]
Fetched 28.9 MB in 1s (16.4 MB/s)
7[0;23r8[1ASelecting previously unselected package libcusparse8.0:amd64.
(Reading database ... 18298 files and directories currently installed.)
Preparing to unpack .../libcusparse8.0_8.0.61-1_amd64.deb ...
7[24;0f[42m[30mProgress: [ 0%][49m[39m [..........................................................] 87[24;0f[42m[30mProgress: [ 6%][49m[39m [###.......................................................] 8Unpacking libcusparse8.0:amd64 (8.0.61-1) ...
7[24;0f[42m[30mProgress: [ 12%][49m[39m [#######...................................................] 87[24;0f[42m[30mProgress: [ 18%][49m[39m [##########................................................] 8Selecting previously unselected package libnvrtc8.0:amd64.
Preparing to unpack .../libnvrtc8.0_8.0.61-1_amd64.deb ...
7[24;0f[42m[30mProgress: [ 25%][49m[39m [##############............................................] 8Unpacking libnvrtc8.0:amd64 (8.0.61-1) ...
7[24;0f[42m[30mProgress: [ 31%][49m[39m [##################........................................] 87[24;0f[42m[30mProgress: [ 37%][49m[39m [#####################.....................................] 8Selecting previously unselected package libnvtoolsext1:amd64.
Preparing to unpack .../libnvtoolsext1_8.0.61-1_amd64.deb ...
7[24;0f[42m[30mProgress: [ 43%][49m[39m [#########################.................................] 8Unpacking libnvtoolsext1:amd64 (8.0.61-1) ...
7[24;0f[42m[30mProgress: [ 50%][49m[39m [#############################.............................] 87[24;0f[42m[30mProgress: [ 56%][49m[39m [################################..........................] 8Setting up libnvtoolsext1:amd64 (8.0.61-1) ...
7[24;0f[42m[30mProgress: [ 62%][49m[39m [####################################......................] 87[24;0f[42m[30mProgress: [ 68%][49m[39m [#######################################...................] 8Setting up libcusparse8.0:amd64 (8.0.61-1) ...
7[24;0f[42m[30mProgress: [ 75%][49m[39m [###########################################...............] 87[24;0f[42m[30mProgress: [ 81%][49m[39m [###############################################...........] 8Setting up libnvrtc8.0:amd64 (8.0.61-1) ...
7[24;0f[42m[30mProgress: [ 87%][49m[39m [##################################################........] 87[24;0f[42m[30mProgress: [ 93%][49m[39m [######################################################....] 8Processing triggers for libc-bin (2.26-0ubuntu2.1) ...
7[0;24r8[1A[JCollecting chainer==4.0.0b4
[?25l Downloading https://files.pythonhosted.org/packages/89/4f/4507635cc3257964928653ea7aace55dfaa2616e41b5909ecdba2be8ffe9/chainer-4.0.0b4.tar.gz (372kB)
[K 100% |████████████████████████████████| 378kB 4.8MB/s
[?25hCollecting cupy-cuda80==4.0.0b4
[?25l Downloading https://files.pythonhosted.org/packages/bf/f2/7e4770a2a46ac1de3ad379446ff5e3f54eb0606c3aa589d90fab6ffcc007/cupy_cuda80-4.0.0b4-cp36-cp36m-manylinux1_x86_64.whl (205.4MB)
[K 5% |█▊ | 11.3MB 32.5MB/s eta 0:00:06[K 100% |████████████████████████████████| 205.4MB 124kB/s
[?25hCollecting filelock (from chainer==4.0.0b4)
Downloading https://files.pythonhosted.org/packages/2d/ba/db7e0717368958827fa97af0b8acafd983ac3a6ecd679f60f3ccd6e5b16e/filelock-3.0.4.tar.gz
Requirement already satisfied: numpy>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from chainer==4.0.0b4) (1.14.3)
Requirement already satisfied: protobuf>=3.0.0 in /usr/local/lib/python3.6/dist-packages (from chainer==4.0.0b4) (3.5.2.post1)
Requirement already satisfied: six>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from chainer==4.0.0b4) (1.11.0)
Collecting fastrlock>=0.3 (from cupy-cuda80==4.0.0b4)
[?25l Downloading https://files.pythonhosted.org/packages/fa/24/767ce4fe23af5a4b3dd229c0e3153a26c0a58331f8f89af324c761663c9c/fastrlock-0.3-cp36-cp36m-manylinux1_x86_64.whl (77kB)
[K 100% |████████████████████████████████| 81kB 19.1MB/s
[?25hRequirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.0.0->chainer==4.0.0b4) (39.2.0)
Building wheels for collected packages: chainer, filelock
Running setup.py bdist_wheel for chainer ... [?25ldone
[?25h Stored in directory: /content/.cache/pip/wheels/89/2e/12/fe6441d846a967c24ded700e140bc2a71f56044199b72f33dc
Running setup.py bdist_wheel for filelock ... [?25ldone
[?25h Stored in directory: /content/.cache/pip/wheels/35/ba/67/4cc48738870c3b54f9e3b5d78bf9de130befb70c1d359faf8b
Successfully built chainer filelock
Installing collected packages: filelock, chainer, fastrlock, cupy-cuda80
Successfully installed chainer-4.0.0b4 cupy-cuda80-4.0.0b4 fastrlock-0.3 filelock-3.0.4
!pip install chainer -U
!pip install cupy-cuda80 -U
Collecting chainer
[?25l Downloading https://files.pythonhosted.org/packages/75/6c/04cc710209faae050d14c12d9a12ea6097f86fed968005d7b69eb2774814/chainer-4.1.0.tar.gz (395kB)
[K 100% |████████████████████████████████| 399kB 5.2MB/s
[?25hRequirement not upgraded as not directly required: filelock in /usr/local/lib/python3.6/dist-packages (from chainer) (3.0.4)
Requirement not upgraded as not directly required: numpy>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from chainer) (1.14.3)
Requirement not upgraded as not directly required: protobuf>=3.0.0 in /usr/local/lib/python3.6/dist-packages (from chainer) (3.5.2.post1)
Requirement not upgraded as not directly required: six>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from chainer) (1.11.0)
Collecting cupy-cuda80==4.1.0 (from chainer)
[?25l Downloading https://files.pythonhosted.org/packages/3f/23/c051fb66543a48b44376eed0320350a04750521d588553bac508ba66bcc7/cupy_cuda80-4.1.0-cp36-cp36m-manylinux1_x86_64.whl (194.0MB)
[K 79% |█████████████████████████▍ | 154.1MB 20.2MB/s eta 0:00:02[K 100% |████████████████████████████████| 194.0MB 89kB/s
[?25hRequirement not upgraded as not directly required: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.0.0->chainer) (39.2.0)
Requirement not upgraded as not directly required: fastrlock>=0.3 in /usr/local/lib/python3.6/dist-packages (from cupy-cuda80==4.1.0->chainer) (0.3)
Building wheels for collected packages: chainer
Running setup.py bdist_wheel for chainer ... [?25ldone
[?25h Stored in directory: /content/.cache/pip/wheels/f7/bc/ce/ded86aa42c54308c8bc62410164af1c614cdecc0df3a204af4
Successfully built chainer
Installing collected packages: cupy-cuda80, chainer
Found existing installation: cupy-cuda80 4.0.0b4
Uninstalling cupy-cuda80-4.0.0b4:
Successfully uninstalled cupy-cuda80-4.0.0b4
Found existing installation: chainer 4.0.0b4
Uninstalling chainer-4.0.0b4:
Successfully uninstalled chainer-4.0.0b4
Successfully installed chainer-4.1.0 cupy-cuda80-4.1.0
Requirement already up-to-date: cupy-cuda80 in /usr/local/lib/python3.6/dist-packages (4.1.0)
Requirement not upgraded as not directly required: six>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from cupy-cuda80) (1.11.0)
Requirement not upgraded as not directly required: fastrlock>=0.3 in /usr/local/lib/python3.6/dist-packages (from cupy-cuda80) (0.3)
Requirement not upgraded as not directly required: numpy>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from cupy-cuda80) (1.14.3)
GPUが有効になっていることを確認する
★ランタイムの再起動が必要かも
以下のようになっていれば、有効になっているようです
GPU availability: True
cuDNN availablility: True
import chainer
import cupy
chainer.print_runtime_info()
print('GPU availability:', chainer.cuda.available)
print('cuDNN availablility:', chainer.cuda.cudnn_enabled)
Chainer: 4.1.0
NumPy: 1.14.3
CuPy:
CuPy Version : 4.1.0
CUDA Root : None
CUDA Build Version : 8000
CUDA Driver Version : 9000
CUDA Runtime Version : 8000
cuDNN Build Version : 7102
cuDNN Version : 7102
NCCL Build Version : 2104
GPU availability: True
cuDNN availablility: True
犬、猫のデータを取得、解凍する
データのダウンロード
import os
import requests
import zipfile
file_name = "dogscats.zip"
url='http://files.fast.ai/data/dogscats.zip'
response = requests.get(url)
with open(os.path.join("./", file_name), 'wb') as f:
f.write(response.content)
# ダウンロードできた確認する
%%bash
ls
datalab
dogscats.zip
マイクロソフトのサイトからダウンロードしたら、「unzip」に失敗したので、この記事を見て、ここからダウンロードすることにしました。
解凍する
学習データは、「dogscats/train/cats/」、「dogscats/train/dogs/」というような感じで、
検証データは、「dogscats/valid/cats/」、「dogscats/valid/dogs/」というような感じで入っているようです。
!unzip dogscats.zip
Archive: dogscats.zip
creating: dogscats/
creating: dogscats/sample/
creating: dogscats/sample/train/
creating: dogscats/sample/train/cats/
inflating: dogscats/sample/train/cats/cat.2921.jpg
inflating: dogscats/sample/train/cats/cat.394.jpg
inflating: dogscats/sample/train/cats/cat.4865.jpg
inflating: dogscats/sample/train/cats/cat.3570.jpg
inflating: dogscats/sample/train/cats/cat.2266.jpg
inflating: dogscats/sample/train/cats/cat.9021.jpg
inflating: dogscats/sample/train/cats/cat.11737.jpg
inflating: dogscats/sample/train/cats/cat.4600.jpg
creating: dogscats/sample/train/dogs/
inflating: dogscats/sample/train/dogs/dog.1402.jpg
inflating: dogscats/sample/train/dogs/dog.1614.jpg
inflating: dogscats/sample/train/dogs/dog.8643.jpg
inflating: dogscats/sample/train/dogs/dog.6391.jpg
inflating: dogscats/sample/train/dogs/dog.2423.jpg
inflating: dogscats/sample/train/dogs/dog.9077.jpg
inflating: dogscats/sample/train/dogs/dog.8091.jpg
inflating: dogscats/sample/train/dogs/dog.6768.jpg
creating: dogscats/sample/valid/
inflating: dogscats/sample/valid/features.npy
creating: dogscats/sample/valid/cats/
inflating: dogscats/sample/valid/cats/cat.10435.jpg
inflating: dogscats/sample/valid/cats/cat.4319.jpg
inflating: dogscats/sample/valid/cats/cat.5202.jpg
inflating: dogscats/sample/valid/cats/cat.4785.jpg
creating: dogscats/sample/valid/dogs/
inflating: dogscats/sample/valid/dogs/dog.11314.jpg
inflating: dogscats/sample/valid/dogs/dog.4090.jpg
inflating: dogscats/sample/valid/dogs/dog.10459.jpg
inflating: dogscats/sample/valid/dogs/dog.5697.jpg
inflating: dogscats/sample/valid/labels.npy
creating: dogscats/train/
creating: dogscats/train/cats/
inflating: dogscats/train/cats/cat.2921.jpg
inflating: dogscats/train/cats/cat.10435.jpg
inflating: dogscats/train/cats/cat.394.jpg
inflating: dogscats/train/cats/cat.4319.jpg
inflating: dogscats/train/cats/cat.5202.jpg
inflating: dogscats/train/cats/cat.4865.jpg
inflating: dogscats/train/cats/cat.3570.jpg
inflating: dogscats/train/cats/cat.2266.jpg
inflating: dogscats/train/cats/cat.9021.jpg
inflating: dogscats/train/cats/cat.4785.jpg
データを、Chainerで利用可能な形に成型する
- 画像サイズを統一する
- shapeを「チャンネル,縦,横」にする(ChainerでCNNを利用する場合、左記のようなshapeにする必要がある)
- TransformDataset型にする
データを確認する
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
img_path = './dogscats/train/cats/cat.9021.jpg'
Image.open(img_path)

画像サイズを変更する
def img_resize(img, out_size, is_file_path=True):
if (is_file_path):
img = Image.open(img)
else:
#Chainerの「チャネル、縦、横」→「縦、横、チャネル」にする
#後で、TransformDatasetを作ると気にこちらを使います
#※image_dataset.pyの中で、transpose(2, 0, 1)をしてくれているので、
# リサイズするなら、transpose(1, 2, 0)が必要なようです
img = Image.fromarray(img.transpose(1, 2, 0))
resized_img = img.resize(out_size, Image.BICUBIC)
return resized_img
resized_img = img_resize('./dogscats/train/cats/cat.9021.jpg', (120, 120))
print(resized_img)
resized_img
<PIL.Image.Image image mode=RGB size=120x120 at 0x7F3F6F281240>

shapeを「チャンネル,縦,横」にする
# ndarray型に変換(縦、横がわかりやすいように、サイズを変えてます)
resized_img = img_resize('./dogscats/train/cats/cat.9021.jpg', (120, 200))
img_array = np.array(resized_img)
# shapeを確認する
img_array.shape
(200, 120, 3)
**※image_dataset.pyの中で、transpose(2, 0, 1)をしてくれているので、
リサイズをしないのであれば、不要な処理です。 **
# shapeを「チャンネル,縦,横」にする
def img_to_chainer_shape(img):
img_array = np.array(img)
return img_array.transpose(2, 0, 1)
# 変わっていることを確認する
img = np.array(img_to_chainer_shape(img_resize('./dogscats/train/cats/cat.9021.jpg', (120, 200))))
img.shape
(3, 200, 120)
TransformDataset型にする
メモリに展開しないで、データセットを作ります。ここを参考にしました。
from chainer import datasets
cats_train_path = 'dogscats/train/cats/'
dogs_train_path = 'dogscats/train/dogs/'
cats_valid_path = 'dogscats/valid/cats/'
dogs_valid_path = 'dogscats/valid/dogs/'
filepath_and_label_list = []
import os
def get_image_filepath_list(dir, label):
filepath_list = []
files = os.listdir(dir)
for file in files:
filepath_list.append((dir + file, label))
return filepath_list
# 学習と検証データを一緒にしてます
filepath_and_label_list.extend(get_image_filepath_list(cats_train_path, 0))
filepath_and_label_list.extend(get_image_filepath_list(dogs_train_path, 1))
filepath_and_label_list.extend(get_image_filepath_list(cats_valid_path, 0))
filepath_and_label_list.extend(get_image_filepath_list(dogs_valid_path, 1))
# 各データに行う変換
def transform(inputs):
img , label = inputs
#サイズ変換
img = img_resize(img.astype(np.uint8), (120, 120), False)
#Chainer用のChapeにする
img = img_to_chainer_shape(img)
#スケーリング(データを0~1の間にする)
img = img.astype(np.float32) / 255
# ランダムに左右反転
if np.random.rand() > 0.5:
img = img[..., ::-1]
return img, label
from chainer.datasets import LabeledImageDataset
# データセット作成
d = LabeledImageDataset(filepath_and_label_list)
from chainer.datasets import TransformDataset
# 変換をメソッドを設定する
td = TransformDataset(d, transform)
学習する
データセットを学習、検証で分ける
from chainer import datasets
train, valid = datasets.split_dataset_random(td, int(len(d) * 0.8), seed=0)
モデルを定義する
ここを参考にしました。
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import training,serializers,Chain,datasets,sequential,optimizers,iterators
from chainer.training import extensions,Trainer
from chainer.dataset import concat_examples
class CNN(Chain):
def __init__(self):
super(CNN, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(None, out_channels=32, ksize=3, stride=1, pad=1)
self.conv2 = L.Convolution2D(in_channels=32, out_channels=64, ksize=3, stride=1, pad=1)
self.conv3 = L.Convolution2D(in_channels=64, out_channels=128, ksize=3, stride=1, pad=1)
self.conv4 = L.Convolution2D(in_channels=128, out_channels=256, ksize=3, stride=1, pad=1)
self.l1 = L.Linear(None, 1000)
self.l2 = L.Linear(1000, 2)
def __call__(self, x):
f = F.max_pooling_2d(F.relu(self.conv1(x)), ksize=2, stride=2)
f = F.max_pooling_2d(F.relu(self.conv2(f)), ksize=2, stride=2)
f = F.max_pooling_2d(F.relu(self.conv3(f)), ksize=2, stride=2)
f = F.max_pooling_2d(F.relu(self.conv4(f)), ksize=2, stride=2)
f = F.dropout(F.relu(self.l1(f)), ratio=0.75)
f = self.l2(f)
return f
batchsize = 32
max_epoch = 10
gpu_id = 0
model = L.Classifier(CNN())
model.to_gpu(gpu_id)
<chainer.links.model.classifier.Classifier at 0x7f3f090b3e10>
train_iter = iterators.MultiprocessIterator(train, batchsize)
valid_iter = iterators.MultiprocessIterator(valid, batchsize, False, False)
optimaizer = optimizers.Adam().setup(model)
updater = training.StandardUpdater(train_iter, optimaizer, device=gpu_id)
trainer = Trainer(updater, stop_trigger=(max_epoch, 'epoch'))
trainer.extend(extensions.LogReport())
trainer.extend(extensions.Evaluator(valid_iter, model, device=gpu_id), name='val')
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'main/accuracy', 'val/main/loss', 'val/main/accuracy', 'elapsed_time']))
trainer.extend(extensions.snapshot(filename='snapshot_epoch-{.updater.epoch}'))
trainer.extend(extensions.PlotReport(['main/loss', 'val/main/loss'], x_key='epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(['main/accuracy', 'val/main/accuracy'], x_key='epoch', file_name='accuracy.png'))
trainer.extend(extensions.ProgressBar())
trainer.extend(extensions.dump_graph('main/loss'))
学習スタート!
ProgressBarも、1エポックごとに表示できたらいいに、、、って思います。
終わる時間が知りたいだけです。
trainer.run()
epoch main/loss main/accuracy val/main/loss val/main/accuracy elapsed_time
[J total [..................................................] 1.60%
this epoch [########..........................................] 16.00%
100 iter, 0 epoch / 10 epochs
inf iters/sec. Estimated time to finish: 0:00:00.
[4A[J total [#.................................................] 3.20%
this epoch [################..................................] 32.00%
200 iter, 0 epoch / 10 epochs
6.177 iters/sec. Estimated time to finish: 0:16:19.434320.
[4A[J total [##................................................] 4.80%
this epoch [########################..........................] 48.00%
300 iter, 0 epoch / 10 epochs
6.133 iters/sec. Estimated time to finish: 0:16:10.154462.
[4A[J total [###...............................................] 6.40%
this epoch [################################..................] 64.00%
400 iter, 0 epoch / 10 epochs
6.1124 iters/sec. Estimated time to finish: 0:15:57.076340.
[4A[J total [####..............................................] 8.00%
this epoch [########################################..........] 80.00%
500 iter, 0 epoch / 10 epochs
6.1181 iters/sec. Estimated time to finish: 0:15:39.832635.
[4A[J total [####..............................................] 9.60%
this epoch [################################################..] 96.00%
600 iter, 0 epoch / 10 epochs
6.1134 iters/sec. Estimated time to finish: 0:15:24.198442.
[4A[J1 0.674315 0.57565 0.619502 0.646696 138.422
[4A[J total [#################################################.] 99.20%
this epoch [##############################################....] 92.00%
6200 iter, 9 epoch / 10 epochs
4.6714 iters/sec. Estimated time to finish: 0:00:10.703371.
[4A[J10 0.178794 0.92595 0.214504 0.909435 1366.39
[J
学習結果を確認する
Image.open('result/loss.png')
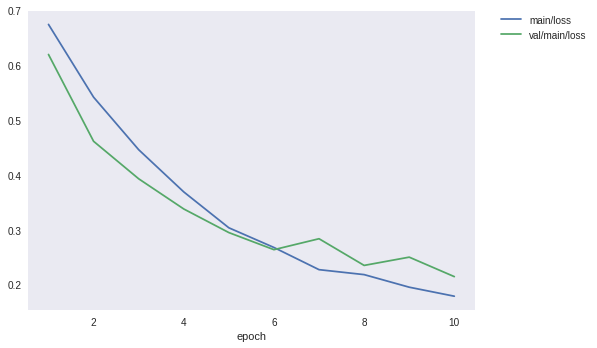
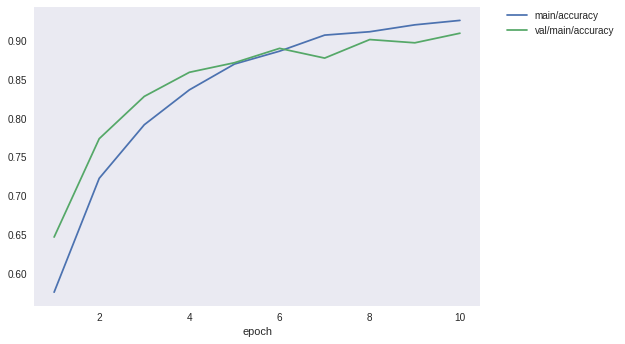
Image.open('result/accuracy.png')
学習済みモデルを保存する
Google Driveに出力します。ここを参考にしました。
# 保存するフォルダを確認する
%%bash
ls
datalab
dogscats
dogscats.zip
result
# resultの中に、snapshotができているので、確認する
%%bash
ls result
accuracy.png
cg.dot
log
loss.png
snapshot_epoch-1
snapshot_epoch-10
snapshot_epoch-2
snapshot_epoch-3
snapshot_epoch-4
snapshot_epoch-5
snapshot_epoch-6
snapshot_epoch-7
snapshot_epoch-8
snapshot_epoch-9
GoogleDriveへの接続
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
最後のエポックのスナップをGoogleDriveに保存する
snap_file_name = "result/snapshot_epoch-" + str(max_epoch)
upload_file = drive.CreateFile()
upload_file.SetContentFile(snap_file_name)
upload_file.Upload()
検証する
GoogleDriveへ接続する(上を参照 既に接続済みなら不要です)
GoogleDriveからファイルを取得する
上で、GoogleDriveにアップロードしたファイルに対し、GoogleDriveで「共有可能なリンクを取得」する必要があります。
downloaded = drive.CreateFile({'id':'ここは、GoogleDriveの共有可能なリンクのIDです'})
downloaded.GetContentFile('snapshot_epoch-'+ str(max_epoch))
学習済みモデルを読み込む
model = L.Classifier(CNN())
infer_net = model
serializers.load_npz('snapshot_epoch-' + str(max_epoch), infer_net, path='updater/model:main/')
infer_net.to_gpu(0)
<chainer.links.model.classifier.Classifier at 0x7f3f0543c320>
※ infer_net.xp.asarray(x)がないと、以下のエラーになります。ここを参考にしました。
※ x[None, ...]がないと、以下のエラーになります。 ここを参考にしました。
def get_x_test(file_path, size, show=True):
if show:
plt.imshow(Image.open(file_path))
#リサイズ
x = img_resize(file_path, size, True)
#リシェイプ
x = img_to_chainer_shape(x)
#型変換
#float32にする
x = x.astype(np.float32)
# ネットワークと同じデバイス上にデータを送る
x = infer_net.xp.asarray(x)
#[ミニバッチ、チャネル、高さ、幅]にする
x = x[None, ...]
return x
from chainer.cuda import to_cpu
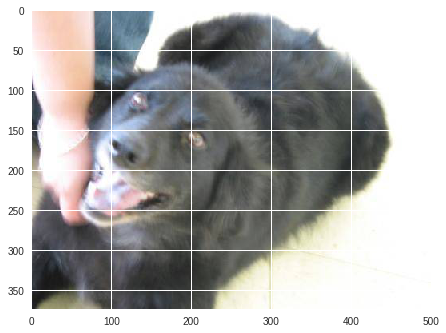
x_test = get_x_test('dogscats/test1/5011.jpg', (120, 120))
with chainer.using_config('train', False), chainer.using_config('enable_backprop', False):
y = infer_net.predictor(x_test)
y = to_cpu(y.array)
print(y)
y = y.argmax(axis=1)[0]
print(y)
if y == 0:
y = '猫'
else:
y = '犬'
print('予測ラベル:', y)
[[-324.16788 299.3006 ]]
1
予測ラベル: 犬
まとめ
画像取得から、検証までの流れができて面白ったです。
これで、いろんなデータセットに挑戦できるという気がしてきたので、
ほかのデータセットにチャレンジしていきます!