GoogleColaboratoryで、Seleniumで株式チャートをスクレイピングし、CNNでN日後の株価予測する
概要
チャートを見て株取引している人がいるので、チャート画像から株価が予測できるのでは?って思ったのでやってみます。
結論から言うと、5日後の予測で60%前後の正解率になり、予測できたとは言えませんでした。。。
でも、「Seleniumを使て画像をスクレイピングする」ってことができたので、よかったかなと思います。
- 環境はGoogleColaboratoryを利用します。
- チャート画像、翌日株価(CSV)のスクレイピングには、Seleniumを利用します。
- WebDriverは、PhantomJSを利用します。(サポート廃止っぽいが動きました。。。自己責任でお願いします)
- 株式チャート画像から、N日後の株価を2クラス(上がったか、下がったか)で分類し予測します。
- 銘柄は日経平均です。
- フレームワークはChainerです。
Seleniumを使って、株式チャートの画像を取得する
Seleniumをインストールする
Seleniumをインストールする
!pip install selenium
WebDriver(PhantomJS)をダウンロードする
webdriverについて
google、firefoxは、なんかだめだったので、
警告がでますが「PhantomJS」を使用します。
%%bash
mkdir ~/src
cd ~/src
wget https://bitbucket.org/ariya/phantomjs/downloads/phantomjs-2.1.1-linux-x86_64.tar.bz2
%%bash
ls ~/src
phantomjs-2.1.1-linux-x86_64.tar.bz2
PhantomJSを解凍し、パスを通す
よくわかってないですが解凍した「phantomjs」を「/usr/local/bin/ 」に移すことで、パスが通るみたいです。
%%bash
cd ~/src
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2
cd phantomjs-2.1.1-linux-x86_64/bin/
mv phantomjs /usr/local/bin/
パスが通った確認する。
phantomjs> って表示されれば、OKです。
%%bash
phantomjs
phantomjs>
seleniumを使って、Googleのページをとってみる。
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
options = Options()
options.set_headless(Options.headless)
browser = webdriver.PhantomJS()
browser.implicitly_wait(3)
browser.get('https://www.google.com')
browser.save_screenshot("google.com.png")
browser.quit()
/usr/local/lib/python3.6/dist-packages/selenium/webdriver/phantomjs/webdriver.py:49: UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead
warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '
from PIL import Image
Image.open('google.com.png')
seleniumを使って、株式チャート画像を取得します。
参考にしたサイト
日経平均のCSVデータを取得する
import requests
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.implicitly_wait(3)
nikkei225_url = 'https://finance.yahoo.com/quote/%5EN225/history?period1=1356966000&period2=1528642800&interval=1d&filter=history&frequency=1d'
browser.get(nikkei225_url)
download_link = browser.find_element_by_xpath('//*[@id="Col1-1-HistoricalDataTable-Proxy"]/section/div[1]/div[2]/span[2]/a').get_attribute('href')
session = requests.Session()
cookies = browser.get_cookies()
for cookie in cookies:
session.cookies.set(cookie['name'], cookie['value'])
response = session.get(download_link)
with open('nikkei225.csv', 'wb') as f:
f.write(response.content)
browser.quit()
/usr/local/lib/python3.6/dist-packages/selenium/webdriver/phantomjs/webdriver.py:49: UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead
warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '
日経平均のCSVデータが取得できたか確認する
import pandas as pd
df = pd.read_csv("nikkei225.csv")
df.tail()
| Date | Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|---|
| 1342 | 2018-06-05 | 22552.169922 | 22602.130859 | 22470.039063 | 22539.539063 | 22539.539063 | 65800.0 |
| 1343 | 2018-06-06 | 22520.310547 | 22662.820313 | 22498.589844 | 22625.730469 | 22625.730469 | 67900.0 |
| 1344 | 2018-06-07 | 22748.720703 | 22856.369141 | 22732.179688 | 22823.259766 | 22823.259766 | 72200.0 |
| 1345 | 2018-06-08 | 22799.380859 | 22879.000000 | 22694.500000 | 22694.500000 | 22694.500000 | 85200.0 |
| 1346 | 2018-06-11 | 22686.949219 | 22856.080078 | 22667.300781 | 22804.039063 | 22804.039063 | 55700.0 |
df.describe()
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| count | 1333.000000 | 1333.000000 | 1333.000000 | 1333.000000 | 1333.000000 | 1333.000000 |
| mean | 17504.436762 | 17603.798866 | 17399.636172 | 17503.307298 | 17503.307298 | 145364.516129 |
| std | 2951.455511 | 2945.909275 | 2953.304942 | 2951.124517 | 2951.124517 | 60485.992544 |
| min | 10405.669922 | 10602.120117 | 10398.610352 | 10486.990234 | 10486.990234 | 0.000000 |
| 25% | 15204.309570 | 15326.780273 | 15124.360352 | 15224.110352 | 15224.110352 | 109000.000000 |
| 50% | 17306.640625 | 17400.769531 | 17162.210938 | 17290.490234 | 17290.490234 | 135300.000000 |
| 75% | 19737.210938 | 19840.000000 | 19679.369141 | 19746.199219 | 19746.199219 | 167900.000000 |
| max | 24078.929688 | 24129.339844 | 23917.140625 | 24124.150391 | 24124.150391 | 595200.000000 |
前日終値と当日終値の差を「NextDayClose」とする
import numpy as np
# Close(終値)が無い行を削除する
df = df.dropna(subset=['Close'])
# #翌日終値カラムを追加する
# df['NextDayClose'] = df['Close'].shift(-1).fillna(0)
# #翌日アップ金額を追加する
# df['NextDayUpPrice'] = (df['NextDayClose'] - df['Close']).fillna(0)
# #翌日アップ率を追加する
# df['NextDayUpLate'] = (df['NextDayUpPrice'] / df['Close'] * 100).fillna(0)
past_n_day = -5
# N日後の終値カラムを追加する
df['N_DaysLaterClose'] = df['Close'].shift(past_n_day).fillna(0)
# N日後のアップ金額を追加する
df['N_DaysLaterUpPrice'] = (df['N_DaysLaterClose'] - df['Close']).fillna(0)
# N日後のアップ率を追加する
df['N_DaysLaterUpLate'] = (df['N_DaysLaterUpPrice'] / df['Close'] * 100).fillna(0)
df.head()
| Date | Open | High | Low | Close | Adj Close | Volume | N_DaysLaterClose | N_DaysLaterUpPrice | N_DaysLaterUpLate | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013-01-04 | 10604.500000 | 10734.230469 | 10602.240234 | 10688.110352 | 10688.110352 | 219000.0 | 10801.570313 | 113.459961 | 1.061553 |
| 1 | 2013-01-07 | 10743.690430 | 10743.690430 | 10589.700195 | 10599.009766 | 10599.009766 | 187700.0 | 10879.080078 | 280.070312 | 2.642420 |
| 2 | 2013-01-08 | 10544.209961 | 10602.120117 | 10463.429688 | 10508.059570 | 10508.059570 | 211400.0 | 10600.440430 | 92.380860 | 0.879143 |
| 3 | 2013-01-09 | 10405.669922 | 10620.700195 | 10398.610352 | 10578.570313 | 10578.570313 | 215000.0 | 10609.639648 | 31.069335 | 0.293701 |
| 4 | 2013-01-10 | 10635.110352 | 10686.120117 | 10619.650391 | 10652.639648 | 10652.639648 | 268500.0 | 10913.299805 | 260.660157 | 2.446907 |
チャート作成対象のリストを作る
target_list = df.where(df['Date'] <= '2018-03-01').dropna()
target_list.tail()
| Date | Open | High | Low | Close | Adj Close | Volume | N_DaysLaterClose | N_DaysLaterUpPrice | N_DaysLaterUpLate | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1270 | 2018-02-23 | 21789.720703 | 21903.390625 | 21741.630859 | 21892.779297 | 21892.779297 | 64600.0 | 21181.640625 | -711.138672 | -3.248280 |
| 1271 | 2018-02-26 | 22134.640625 | 22226.529297 | 22040.869141 | 22153.630859 | 22153.630859 | 64600.0 | 21042.089844 | -1111.541015 | -5.017421 |
| 1272 | 2018-02-27 | 22391.669922 | 22502.050781 | 22325.070313 | 22389.859375 | 22389.859375 | 74300.0 | 21417.759766 | -972.099609 | -4.341696 |
| 1273 | 2018-02-28 | 22292.529297 | 22380.279297 | 22068.240234 | 22068.240234 | 22068.240234 | 88800.0 | 21252.720703 | -815.519531 | -3.695444 |
| 1274 | 2018-03-01 | 21901.130859 | 21901.130859 | 21645.220703 | 21724.470703 | 21724.470703 | 90300.0 | 21368.070313 | -356.400390 | -1.640548 |
株式チャートを取得するメソッドの定義
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait as wait
from selenium.webdriver.firefox.options import Options
import base64
from time import sleep
画像ファイルパス、ファイル名を作成するメソッドの定義
def create_dir_and_file_name(code, year=1, month=1, day=1):
file_name = "{}_{}_{}.png".format(year, month, day)
chart_file_path = "./stock_chart/{}/".format(code)
return chart_file_path, file_name
年、月、日は、ドロップダウンを回して、動的にやりたい気もする。。。
YEAR_DIC = {2018:1, 2017:2, 2016:3, 2015:4, 2014:3, 2013:2}
def save_chart_by_selenium(browser, code, year=1, month=1, day=1):
#日経のチャートへ接続する
browser.get('https://www.nikkei.com/markets/chart/#!/' + code)
#チャートの期間を3か月にする
browser.find_element_by_id("ViewTerm3m").click()
#2018年 1月 1日にする
#期間指定のポップアップ表示
browser.find_element_by_id("TermConfBtn").click()
#ポップアップを取得
popup = browser.find_element_by_class_name("popup")
#Toの期間指定をクリック
popup.find_element_by_css_selector("p.EnDateSelect.daybox_2.font14").click()
#年のドロップダウンをクリック
browser.find_element_by_xpath("/html/body/div[3]/div/div/div/div[2]/div[1]/div/a").click()
#年を指定する
browser.find_element_by_xpath('/html/body/div[3]/div/div/div/div[2]/div[1]/div/ul/li[{}]'.format(YEAR_DIC[year])).click()
#月のドロップダウンをクリック
browser.find_element_by_xpath("/html/body/div[3]/div/div/div/div[2]/div[2]/div/a").click()
#月を指定する
browser.find_element_by_xpath('/html/body/div[3]/div/div/div/div[2]/div[2]/div/ul/li[{}]'.format(month)).click()
#日のドロップダウンをクリック
browser.find_element_by_xpath("/html/body/div[3]/div/div/div/div[2]/div[3]/div/a").click()
#日を指定する
browser.find_element_by_xpath('/html/body/div[3]/div/div/div/div[2]/div[3]/div/ul/li[{}]'.format(day)).click()
#設定ボタンクリック
popup.find_element_by_css_selector("p.SetTermConf.btn01.font14").click()
#スリープしないと、チャートが変わらないっぽいので、、、3秒スリープでなんとかいけた
sleep(3)
#canvas→pngに変換する
chart_canvas = browser.find_element_by_css_selector("#ChartGraphTop")
chart_canvas_base64 = browser.execute_script("return arguments[0].toDataURL('image/png').substring(21);", chart_canvas)
chart_canvas_png = base64.b64decode(chart_canvas_base64)
#保存先
chart_file_path, chart_file_name = create_dir_and_file_name(code, year, month, day)
os.makedirs(chart_file_path, exist_ok=True)
with open(chart_file_path + chart_file_name, 'wb') as f:
f.write(chart_canvas_png)
return chart_file_path + chart_file_name
#browser.save_screenshot("test.png")
確認する
options = Options()
options.set_headless(Options.headless)
browser = webdriver.PhantomJS()
browser.implicitly_wait(3)
save_chart_by_selenium(browser, "0101", 2018, 8, 13)
Image.open('./stock_chart/0101/2018_8_13.png')
/usr/local/lib/python3.6/dist-packages/selenium/webdriver/phantomjs/webdriver.py:49: UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead
warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '
GoogleDriveの認証をしておく
結構時間のかかる処理のため、処理終了後に、GoogleDriveに保存しときたいと思います。
保存するために、認証を行っておきます。
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
チャート画像の取得
1時間以上データ取得に時間がかかります。
理由は、1300件くらいデータがあり、1件当たり3秒のスリープをしているからです。
options = Options()
options.set_headless(Options.headless)
browser = webdriver.PhantomJS()
browser.implicitly_wait(3)
for target in target_list.values:
year, month, day = [int(x) for x in target[0].split('-')]
save_chart_by_selenium(browser, '0101', year, month, day)
browser.quit()
/usr/local/lib/python3.6/dist-packages/selenium/webdriver/phantomjs/webdriver.py:49: UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead
warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '
パスとラベルのリストを作る
上がったか、下がったかで分類します。
0:0未満
1:0以上
def get_label_2(val):
if val < 0:
return 0
else:
return 1
path_and_label = []
for target in target_list.values:
year, month, day = [int(x) for x in target[0].split('-')]
path, file_name = create_dir_and_file_name('0101', year, month, day)
label = get_label_2(target[-1])
path_and_label.append((path + file_name, label))
path_and_label[:10]
[('./stock_chart/0101/2013_1_4.png', 1),
('./stock_chart/0101/2013_1_7.png', 1),
('./stock_chart/0101/2013_1_8.png', 1),
('./stock_chart/0101/2013_1_9.png', 1),
('./stock_chart/0101/2013_1_10.png', 1),
('./stock_chart/0101/2013_1_11.png', 0),
('./stock_chart/0101/2013_1_15.png', 0),
('./stock_chart/0101/2013_1_16.png', 0),
('./stock_chart/0101/2013_1_17.png', 1),
('./stock_chart/0101/2013_1_18.png', 1)]
作成データの圧縮、タブ区切り化
画像データは、ZIPで圧縮します。
import shutil
shutil.make_archive('./stock_chart', 'zip', root_dir='./stock_chart')
'/content/stock_chart.zip'
path_and_labelは、スペース区切りのファイルとして、出力します。
import csv
with open('stock_chart_path_label.txt', 'w') as f:
writer = csv.writer(f, lineterminator='\n', delimiter=' ')
writer.writerows(path_and_label)
df = pd.read_csv('stock_chart_path_label.txt')
df.tail(10)
| ./stock_chart/0101/2013_1_4.png 1 | |
|---|---|
| 1254 | ./stock_chart/0101/2018_2_16.png 1 |
| 1255 | ./stock_chart/0101/2018_2_19.png 1 |
| 1256 | ./stock_chart/0101/2018_2_20.png 1 |
| 1257 | ./stock_chart/0101/2018_2_21.png 1 |
| 1258 | ./stock_chart/0101/2018_2_22.png 0 |
| 1259 | ./stock_chart/0101/2018_2_23.png 0 |
| 1260 | ./stock_chart/0101/2018_2_26.png 0 |
| 1261 | ./stock_chart/0101/2018_2_27.png 0 |
| 1262 | ./stock_chart/0101/2018_2_28.png 0 |
| 1263 | ./stock_chart/0101/2018_3_1.png 0 |
GoogleDriveに保存する
save_files = ["stock_chart_path_label.txt", "stock_chart.zip", "nikkei225.csv"]
for save_file in save_files:
upload_file = drive.CreateFile()
upload_file.SetContentFile(save_file)
upload_file.Upload()
取得画像の確認
from PIL import Image
img = Image.open('stock_chart/0101/2017_3_1.png').convert('RGB')
img
デバッグ用
画像の取得がうまくいかないって時に、ブラウザが今どんな状態か見るために、
browser.save_screenshot("test.png")で出力した画像を見てました。
# from PIL import Image
# Image.open('test.png')
Chainer(CNN)で、チャート画像から翌日株価を予測する
Chainerのインストール
!pip uninstall chainer -y
!pip uninstall cupy-cuda80 -y
!pip uninstall chainercv -y
!apt -y install libcusparse8.0 libnvrtc8.0 libnvtoolsext1
!ln -snf /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so.8.0 /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so
!pip --no-cache-dir install 'chainer==4.0.0b4' 'cupy-cuda80==4.0.0b4'
!pip install chainer -U
!pip install cupy-cuda80 -U
!pip --no-cache-dir install chainercv
import chainer
import cupy
chainer.print_runtime_info()
print('GPU availability:', chainer.cuda.available)
print('cuDNN availablility:', chainer.cuda.cudnn_enabled)
Chainer: 4.4.0
NumPy: 1.14.5
CuPy:
CuPy Version : 4.4.1
CUDA Root : None
CUDA Build Version : 8000
CUDA Driver Version : 9000
CUDA Runtime Version : 8000
cuDNN Build Version : 7102
cuDNN Version : 7102
NCCL Build Version : 2213
GPU availability: True
cuDNN availablility: True
GoogleDriveよりデータ取得する
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
id = '******************'
downloaded = drive.CreateFile({'id':id})
downloaded.GetContentFile('stock_chart_path_label.txt')
import pandas as pd
df = pd.read_table('stock_chart_path_label.txt')
df.tail(10)
id = '******************'
downloaded = drive.CreateFile({'id':id})
downloaded.GetContentFile('stock_chart.zip')
%%bash
unzip stock_chart.zip -d stock_chart
ls
from PIL import Image
img = Image.open('stock_chart/0101/2013_2_27.png')
print("shape is ", np.array(img).shape)
img
shape is (250, 611, 4)
データを、Chainerで利用可能な形に成型する
from chainercv.transforms import scale
from chainercv.transforms import resize
from PIL import Image
# 各データに行う変換
def transform(inputs):
img , label = inputs
#RGBにする
img = img.astype('u1')
img = Image.fromarray(img.transpose(1, 2, 0))
img = img.convert('RGB')
img = np.array(img, dtype='f').transpose(2, 0, 1)
#サイズ変換
img = resize(img, (224, 224))
#print(img.shape)
#スケーリング(データを0~1の間にする)
img = img.astype(np.float32) / 255
return img, label
import numpy as np
from chainer.datasets import LabeledImageDataset, TransformDataset
d = LabeledImageDataset("stock_chart_path_label.txt")
td = TransformDataset(d, transform)
from chainer import datasets
train, valid = datasets.split_dataset_random(td, int(len(d) * 0.8), seed=0)
シードの固定
import random
import numpy
import chainer
def reset_seed(seed=0):
random.seed(seed)
numpy.random.seed(seed)
if chainer.cuda.available:
chainer.cuda.cupy.random.seed(seed)
reset_seed(0)
学習
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import training,serializers,Chain,datasets,sequential,optimizers,iterators
from chainer.training import extensions,Trainer
from chainer.dataset import concat_examples
from chainercv.links import VGG16
from chainercv.links import ResNet152,ResNet50,ResNet101
from chainer.links import Classifier
import numpy as np
batchsize = 32
max_epoch = 60
gpu_id = 0
e_shift = 20
e_shift_lr = 0.1
VGG16
class FinetuneNet(chainer.Chain):
def __init__(self, extractor, n_units, n_class):
super().__init__()
w = chainer.initializers.HeNormal()
with self.init_scope():
self.extractor = extractor
self.l1 = L.Linear(None, n_units, initialW=w)
self.l2 = L.Linear(None, n_units, initialW=w)
self.l3 = L.Linear(None, n_class, initialW=w)
def __call__(self, x):
h = x
h = self.extractor(h)
h.unchain()
h = F.relu(self.l1(h))
h = F.dropout(h)
h = F.relu(self.l2(h))
h = F.dropout(h)
h = self.l3(h)
return h
# extractor = ResNet152(pretrained_model='imagenet', arch='he')
extractor = VGG16(pretrained_model='imagenet')
extractor.pick = 'pool5'
model = Classifier(FinetuneNet(extractor, 4098, 2))
model.to_gpu(gpu_id)
Downloading ...
From: https://chainercv-models.preferred.jp/vgg16_imagenet_converted_2017_07_18.npz
To: /root/.chainer/dataset/_dl_cache/4f02fe8a8af16cdedf8200a6701dcb0a
% Total Recv Speed Time left
94 490MiB 462MiB 4610KiB/s 0:00:06
<chainer.links.model.classifier.Classifier at 0x7f89bd5330f0>
train_iter = iterators.MultiprocessIterator(train, batchsize)
valid_iter = iterators.MultiprocessIterator(valid, batchsize, False, False)
optimaizer = optimizers.MomentumSGD(lr=0.001).setup(model)
optimaizer.add_hook(chainer.optimizer.WeightDecay(0.0001))
updater = training.StandardUpdater(train_iter, optimaizer, device=gpu_id)
trainer = Trainer(updater, stop_trigger=(max_epoch, 'epoch'))
chainer.cuda.set_max_workspace_size(1024 * 1024 * 1024)
chainer.global_config.autotune = True
chainer.global_config.type_check = False
trainer.extend(extensions.observe_lr())
trainer.extend(extensions.LogReport())
trainer.extend(extensions.Evaluator(valid_iter, model, device=gpu_id), name='val')
trainer.extend(extensions.ExponentialShift('lr', e_shift_lr), trigger=(e_shift, 'epoch'))
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'main/accuracy', 'val/main/loss', 'val/main/accuracy', 'lr', 'elapsed_time']))
trainer.extend(extensions.snapshot(filename='snapshot_epoch-{.updater.epoch}'))
trainer.extend(extensions.PlotReport(['main/loss', 'val/main/loss'], x_key='epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(['main/accuracy', 'val/main/accuracy'], x_key='epoch', file_name='accuracy.png'))
trainer.extend(extensions.ProgressBar())
trainer.extend(extensions.dump_graph('main/loss'))
trainer.run()
epoch main/loss main/accuracy val/main/loss val/main/accuracy lr elapsed_time
[J1 1.25676 0.553711 0.970616 0.436826 0.001 31.1777
[J2 1.43051 0.535156 0.960703 0.574892 0.001 157.184
[J3 1.54337 0.530242 1.12323 0.425108 0.001 280.327
[J total [##................................................] 5.27%
this epoch [########..........................................] 16.21%
100 iter, 3 epoch / 60 epochs
inf iters/sec. Estimated time to finish: 0:00:00.
[4A[J4 0.970235 0.524414 0.679433 0.574892 0.001 404.73
[J5 0.761617 0.508789 0.702564 0.497845 0.001 529.202
[J6 0.717731 0.541331 0.673392 0.594423 0.001 654.141
[J total [#####.............................................] 10.54%
this epoch [################..................................] 32.41%
200 iter, 6 epoch / 60 epochs
0.26594 iters/sec. Estimated time to finish: 1:46:23.007901.
[4A[J7 0.69833 0.587891 0.668774 0.582705 0.001 778.987
[J8 0.710047 0.52621 0.684186 0.522495 0.001 904.168
[J9 0.68308 0.56543 0.674996 0.610048 0.001 1029.01
[J total [#######...........................................] 15.81%
this epoch [########################..........................] 48.62%
300 iter, 9 epoch / 60 epochs
0.26571 iters/sec. Estimated time to finish: 1:40:12.243024.
[4A[J10 0.683418 0.557617 0.667301 0.594828 0.001 1153.93
[J11 0.688133 0.5625 0.666684 0.582705 0.001 1279.7
[J12 0.680461 0.569336 0.677656 0.554957 0.001 1405.49
[J total [##########........................................] 21.08%
this epoch [################################..................] 64.82%
400 iter, 12 epoch / 60 epochs
0.26494 iters/sec. Estimated time to finish: 1:34:12.307453.
[4A[J13 0.669613 0.587891 0.672255 0.60264 0.001 1531.83
[J14 0.670181 0.608871 0.666808 0.578798 0.001 1656.16
[J15 0.67315 0.602539 0.672514 0.574892 0.001 1783.35
[J total [#############.....................................] 26.35%
this epoch [########################################..........] 81.03%
500 iter, 15 epoch / 60 epochs
0.26424 iters/sec. Estimated time to finish: 1:28:08.803435.
[4A[J16 0.674236 0.581653 0.666224 0.590113 0.001 1911.16
[J17 0.669897 0.588867 0.669224 0.606546 0.001 2038.06
[J18 0.662643 0.604492 0.667773 0.578798 0.001 2164.56
[J total [###############...................................] 31.62%
this epoch [################################################..] 97.23%
600 iter, 18 epoch / 60 epochs
0.26395 iters/sec. Estimated time to finish: 1:21:55.787767.
[4A[J19 0.65989 0.612903 0.66888 0.613147 0.001 2289.94
[J20 0.67777 0.581055 0.681438 0.561557 0.001 2417.66
[J21 0.671243 0.575195 0.670354 0.574892 0.0001 2544.12
[J22 0.665133 0.595766 0.668622 0.590517 0.0001 2669.51
[J total [##################................................] 36.89%
this epoch [######............................................] 13.44%
700 iter, 22 epoch / 60 epochs
0.25115 iters/sec. Estimated time to finish: 1:19:28.092030.
[4A[J23 0.660549 0.595703 0.667946 0.610857 0.0001 2794.1
[J24 0.658184 0.602823 0.667611 0.614763 0.0001 2919.19
[J25 0.656694 0.603516 0.667329 0.614359 0.0001 3045.04
[J total [#####################.............................] 42.16%
this epoch [##############....................................] 29.64%
800 iter, 25 epoch / 60 epochs
0.25302 iters/sec. Estimated time to finish: 1:12:17.639967.
[4A[J26 0.653186 0.617188 0.666626 0.606546 0.0001 3169.9
[J27 0.650239 0.611895 0.665682 0.610453 0.0001 3296.03
[J28 0.652033 0.625 0.666332 0.618265 0.0001 3420.43
[J total [#######################...........................] 47.43%
this epoch [######################............................] 45.85%
900 iter, 28 epoch / 60 epochs
0.25437 iters/sec. Estimated time to finish: 1:05:21.450960.
[4A[J29 0.650613 0.597656 0.665503 0.614359 0.0001 3546.59
[J30 0.65221 0.61996 0.664578 0.618265 0.0001 3671.57
[J31 0.64734 0.623047 0.663116 0.613955 0.0001 3799.96
[J total [##########################........................] 52.70%
this epoch [###############################...................] 62.06%
1000 iter, 31 epoch / 60 epochs
0.25525 iters/sec. Estimated time to finish: 0:58:36.092228.
[4A[J32 0.649706 0.618952 0.662693 0.626078 0.0001 3925.36
[J33 0.640512 0.62207 0.661959 0.626078 0.0001 4050.78
[J34 0.645955 0.621094 0.660486 0.622171 0.0001 4175.56
[J total [############################......................] 57.97%
this epoch [#######################################...........] 78.26%
1100 iter, 34 epoch / 60 epochs
0.25621 iters/sec. Estimated time to finish: 0:51:52.686599.
[4A[J35 0.639895 0.622984 0.659186 0.63389 0.0001 4300.78
[J36 0.640335 0.636719 0.659116 0.634294 0.0001 4425.67
[J37 0.64521 0.637695 0.660035 0.622171 0.0001 4551.87
[J total [###############################...................] 63.24%
this epoch [###############################################...] 94.47%
1200 iter, 37 epoch / 60 epochs
0.25693 iters/sec. Estimated time to finish: 0:45:14.721765.
[4A[J38 0.643841 0.616935 0.658681 0.622171 0.0001 4677.25
[J39 0.648018 0.615234 0.659794 0.633082 0.0001 4803.14
[J40 0.640266 0.65121 0.659143 0.634294 0.0001 4928.76
[J41 0.640533 0.619141 0.658272 0.6382 1e-05 5054.1
[J total [##################################................] 68.51%
this epoch [#####.............................................] 10.67%
1300 iter, 41 epoch / 60 epochs
0.2513 iters/sec. Estimated time to finish: 0:39:37.606312.
[4A[J42 0.642407 0.635742 0.658007 0.634294 1e-05 5180.53
[J43 0.638421 0.637097 0.657881 0.6382 1e-05 5306.34
[J44 0.638355 0.615234 0.657795 0.634294 1e-05 5432.05
[J total [####################################..............] 73.78%
this epoch [#############.....................................] 26.88%
1400 iter, 44 epoch / 60 epochs
0.25226 iters/sec. Estimated time to finish: 0:32:52.201271.
[4A[J45 0.646939 0.647461 0.657879 0.63389 1e-05 5557.13
[J46 0.633851 0.638105 0.657871 0.63389 1e-05 5681.52
[J47 0.634775 0.65625 0.65795 0.62958 1e-05 5805.18
[J total [#######################################...........] 79.05%
this epoch [#####################.............................] 43.08%
1500 iter, 47 epoch / 60 epochs
0.25325 iters/sec. Estimated time to finish: 0:26:09.585478.
[4A[J48 0.6431 0.63004 0.658035 0.62958 1e-05 5929.65
[J49 0.639157 0.638672 0.657888 0.63389 1e-05 6056.11
[J50 0.634541 0.646484 0.657764 0.6382 1e-05 6181.61
[J total [##########################################........] 84.32%
this epoch [#############################.....................] 59.29%
1600 iter, 50 epoch / 60 epochs
0.25397 iters/sec. Estimated time to finish: 0:19:31.382589.
[4A[J51 0.639131 0.643145 0.657604 0.63389 1e-05 6305.93
[J52 0.63112 0.661133 0.657518 0.6382 1e-05 6431.38
[J53 0.637556 0.638672 0.657599 0.63389 1e-05 6557.23
[J total [############################################......] 89.59%
this epoch [#####################################.............] 75.49%
1700 iter, 53 epoch / 60 epochs
0.25454 iters/sec. Estimated time to finish: 0:12:55.914910.
[4A[J54 0.644531 0.635081 0.657612 0.63389 1e-05 6683.95
[J55 0.630982 0.661133 0.657465 0.63389 1e-05 6808.45
[J56 0.641891 0.639113 0.657525 0.629984 1e-05 6933.97
[J total [###############################################...] 94.86%
this epoch [#############################################.....] 91.70%
1800 iter, 56 epoch / 60 epochs
0.25511 iters/sec. Estimated time to finish: 0:06:22.182383.
[4A[J57 0.637279 0.654297 0.657503 0.629984 1e-05 7060.01
[J58 0.634336 0.637695 0.657457 0.625673 1e-05 7184.33
[J59 0.640313 0.634073 0.657545 0.621767 1e-05 7312.79
[J60 0.641264 0.628906 0.657413 0.63389 1e-05 7437.23
[J
予測
予測する
def img_transform(file_path, model, show=True):
img = Image.open(file_path)
#RGBにする
img = img.convert('RGB')
if show:
plt.imshow(img)
img = np.array(img, dtype='f').transpose(2, 0, 1)
#サイズ変換
img = resize(img, (224, 224))
#スケーリング(データを0~1の間にする)
img = img.astype(np.float32) / 255
# ネットワークと同じデバイス上にデータを送る
img = model.xp.asarray(img)
#[ミニバッチ、チャネル、高さ、幅]にする
img = img[None, ...]
return img
from chainer.cuda import to_cpu
def stock_predict(x, model):
with chainer.using_config('train', False), chainer.using_config('enable_backprop', False):
y = model.predictor(x)
y = to_cpu(y.array)
print(chainer.functions.softmax(y))
y = y.argmax(axis=1)[0]
if y == 0:
y = '下がった'
else:
y = '上がった'
print('予測ラベル:', y)
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
options = Options()
options.set_headless(Options.headless)
browser = webdriver.PhantomJS()
browser.implicitly_wait(3)
save_chart_by_selenium(browser, "0101", 2018, 7, 7)
/usr/local/lib/python3.6/dist-packages/selenium/webdriver/phantomjs/webdriver.py:49: UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead
warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '
'./stock_chart/0101/2018_7_7.png'
img = img_transform('./stock_chart/0101/2018_7_7.png', model);
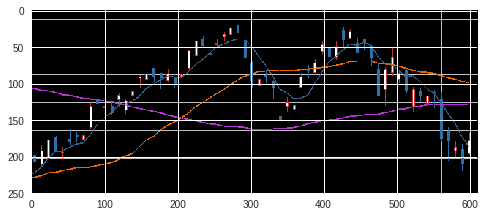
stock_predict(img, model)
variable([[0.44009668 0.5599033 ]])
予測ラベル: 上がった
まとめ
以上で、終わりです。
毎日、全銘柄のチャート画像取得して、上がりそうなやつTOP10とかできないかなって思います。
ほんで、それに対して、ツイッターのデータを取得して、GoogleのAPIで感情分析とかしたりして。。。
ってなかんじで、正解率を上げたりできないかなーって思います。
それと、スクレイピングではなく、自分でチャート画像を作ったほうが自由にできそうなので、
次は、そんな感じのことをやろうかなと思います。