概要
研究室の後輩のために作成した画像分類のサンプルコードです.
ipynbファイルは以下のgithubで公開してあるのでダウンロードして動かしてみてください!
実行環境
- Python : 3.10.12 (pyenv)
- torch : 2.0.1+cu118
- torchvision : 0.15.2+cu118
- timm : 1.0.7
- matplotlib : 3.7.2
基本的に最新版をインストールしておけば大丈夫だと思います.
モジュールのimport
モデルの学習や画像の読み込みなどに使用するモジュールをimportします.
import timm
import glob
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from PIL import Image
from tqdm import tqdm
from torchvision import datasets
from torch.utils.data import DataLoader
画像データの準備
今回は,kaggleで公開されている100種類のスポーツ画像を分類するデータセットを利用します. 以下のURLからデータセットをダウンロードできます.(kaggleのデータセットのダウンロード方法はこちら)
https://www.kaggle.com/datasets/gpiosenka/sports-classification

ダウンロードしたzipファイルを展開すると,trainフォルダ, validフォルダ,testフォルダが生成されます. trainフォルダ,validフォルダ,testフォルダの中にはそれぞれスポーツ名のフォルダが配置されています.
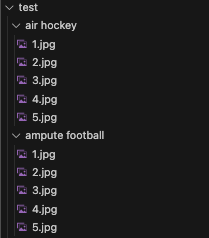
このipynbファイルと同じ場所にdataフォルダを作成し,その中にtrainフォルダ,validフォルダ,testフォルダを配置してください.以下のようになればOK.

データセットは,学習用(train)データ,検証用(valid)データ,テスト用(test)データに分かれています.それぞれ使用方法は以下の通りです.
- 学習用データ
モデルを訓練するために使用する. - 検証用データ
モデルの性能を確認しながらハイパーパラメータ(学習率やエポック数など)を調整するために使用する. - テスト用データ
学習済みモデルの精度を評価するために使用する.
このようにデータを分けることで,特定のデータ(検証用データ)に対してモデルの過学習が起きることを回避できます.
画像データを表示してみる
-
画像が配置されているディレクトリのパス(場所)を指定する
train, valid, testフォルダの下には,以下のような100種類のスポーツ画像が用意されています.['air hockey', 'ampute football', 'archery', 'arm wrestling', 'axe throwing', 'balance beam', 'barell racing', 'baseball', 'basketball', 'baton twirling', 'bike polo', 'billiards', 'bmx', 'bobsled', 'bowling', 'boxing', 'bull riding', 'bungee jumping', 'canoe slamon', 'cheerleading', 'chuckwagon racing', 'cricket', 'croquet', 'curling', 'disc golf', 'fencing', 'field hockey', 'figure skating men', 'figure skating pairs', 'figure skating women', 'fly fishing', 'football', 'formula 1 racing', 'frisbee', 'gaga', 'giant slalom', 'golf', 'hammer throw', 'hang gliding', 'harness racing', 'high jump', 'hockey', 'horse jumping', 'horse racing', 'horseshoe pitching', 'hurdles', 'hydroplane racing', 'ice climbing', 'ice yachting', 'jai alai', 'javelin', 'jousting', 'judo', 'lacrosse', 'log rolling', 'luge', 'motorcycle racing', 'mushing', 'nascar racing', 'olympic wrestling', 'parallel bar', 'pole climbing', 'pole dancing', 'pole vault', 'polo', 'pommel horse', 'rings', 'rock climbing', 'roller derby', 'rollerblade racing', 'rowing', 'rugby', 'sailboat racing', 'shot put', 'shuffleboard', 'sidecar racing', 'ski jumping', 'sky surfing', 'skydiving', 'snow boarding', 'snowmobile racing', 'speed skating', 'steer wrestling', 'sumo wrestling', 'surfing', 'swimming', 'table tennis', 'tennis', 'track bicycle', 'trapeze', 'tug of war', 'ultimate', 'uneven bars', 'volleyball', 'water cycling', 'water polo', 'weightlifting', 'wheelchair basketball', 'wheelchair racing', 'wingsuit flying']
↓ このように,スポーツの名前が付けられたフォルダの下にそのスポーツの画像が用意されています.
今回は,trainフォルダにある"air_hockey"と"basketball", "baseball"の画像を見てみます.
# trainフォルダ下のair hockey, basketball, baseballを選択 train_air_hockey_dir = "./data/train/air hockey" train_basketball_dir = "./data/train/basketball" train_baseball_dir = "./data/train/baseball" -
スポーツの名前が付けられたフォルダの下に用意されているスポーツ画像のパスを取得する
ここでは,globモジュール を用いることで,フォルダ下の画像のパスを一括で取得することができます.globモジュールの使い方 : glob.glob(フォルダ名 + '/*')
- 「*」は,「ワイルドカード」で検索してみてね.
さらに,取得した各フォルダ下のパスを len関数 を用いて表示することで画像の枚数を確認します.
len関数の使い方:len(オブジェクト)
- リストの要素の総数を知りたいときは,len関数を用いる.
# 各フォルダ下の画像のパスを取得 train_air_hockey_files = glob.glob(train_air_hockey_dir + "/*.jpg") train_basketball_files = glob.glob(train_basketball_dir + "/*.jpg") train_baseball_files = glob.glob(train_baseball_dir + "/*.jpg") # 各フォルダ内の画像の枚数を確認 print("[train] : air hockey", len(train_air_hockey_files), "枚") print("[train] : basketball", len(train_basketball_files), "枚") print("[train] : baseball ", len(train_baseball_files), "枚") print() # 実際にパスを出力してみる print(train_air_hockey_files)# 出力結果 [train] : air hockey 112 枚 [train] : basketball 169 枚 [train] : baseball 174 枚 ['./data/train/air hockey/001.jpg', './data/train/air hockey/002.jpg', './data/train/air hockey/003.jpg', './data/train/air hockey/004.jpg', './data/train/air hockey/005.jpg', './data/train/air hockey/006.jpg', './data/train/air hockey/007.jpg', './data/train/air hockey/008.jpg', './data/train/air hockey/009.jpg', './data/train/air hockey/010.jpg', './data/train/air hockey/011.jpg', './data/train/air hockey/012.jpg', './data/train/air hockey/013.jpg', './data/train/air hockey/014.jpg', './data/train/air hockey/015.jpg', './data/train/air hockey/016.jpg', './data/train/air hockey/017.jpg', './data/train/air hockey/018.jpg', './data/train/air hockey/019.jpg', './data/train/air hockey/020.jpg', './data/train/air hockey/021.jpg', './data/train/air hockey/022.jpg', './data/train/air hockey/023.jpg', './data/train/air hockey/024.jpg', './data/train/air hockey/025.jpg', './data/train/air hockey/026.jpg', './data/train/air hockey/027.jpg', './data/train/air hockey/028.jpg', './data/train/air hockey/029.jpg', './data/train/air hockey/030.jpg', './data/train/air hockey/031.jpg', './data/train/air hockey/032.jpg', './data/train/air hockey/033.jpg', './data/train/air hockey/034.jpg', './data/train/air hockey/035.jpg', './data/train/air hockey/036.jpg', './data/train/air hockey/037.jpg', './data/train/air hockey/038.jpg', './data/train/air hockey/039.jpg', './data/train/air hockey/040.jpg', './data/train/air hockey/041.jpg', './data/train/air hockey/042.jpg', './data/train/air hockey/043.jpg', './data/train/air hockey/044.jpg', './data/train/air hockey/045.jpg', './data/train/air hockey/046.jpg', './data/train/air hockey/047.jpg', './data/train/air hockey/048.jpg', './data/train/air hockey/049.jpg', './data/train/air hockey/050.jpg', './data/train/air hockey/051.jpg', './data/train/air hockey/052.jpg', './data/train/air hockey/053.jpg', './data/train/air hockey/054.jpg', './data/train/air hockey/055.jpg', './data/train/air hockey/056.jpg', './data/train/air hockey/057.jpg', './data/train/air hockey/058.jpg', './data/train/air hockey/059.jpg', './data/train/air hockey/060.jpg', './data/train/air hockey/061.jpg', './data/train/air hockey/062.jpg', './data/train/air hockey/063.jpg', './data/train/air hockey/064.jpg', './data/train/air hockey/065.jpg', './data/train/air hockey/066.jpg', './data/train/air hockey/067.jpg', './data/train/air hockey/068.jpg', './data/train/air hockey/069.jpg', './data/train/air hockey/070.jpg', './data/train/air hockey/071.jpg', './data/train/air hockey/072.jpg', './data/train/air hockey/073.jpg', './data/train/air hockey/074.jpg', './data/train/air hockey/075.jpg', './data/train/air hockey/076.jpg', './data/train/air hockey/077.jpg', './data/train/air hockey/078.jpg', './data/train/air hockey/079.jpg', './data/train/air hockey/080.jpg', './data/train/air hockey/081.jpg', './data/train/air hockey/082.jpg', './data/train/air hockey/083.jpg', './data/train/air hockey/084.jpg', './data/train/air hockey/085.jpg', './data/train/air hockey/086.jpg', './data/train/air hockey/087.jpg', './data/train/air hockey/088.jpg', './data/train/air hockey/089.jpg', './data/train/air hockey/090.jpg', './data/train/air hockey/091.jpg', './data/train/air hockey/092.jpg', './data/train/air hockey/093.jpg', './data/train/air hockey/094.jpg', './data/train/air hockey/095.jpg', './data/train/air hockey/096.jpg', './data/train/air hockey/097.jpg', './data/train/air hockey/098.jpg', './data/train/air hockey/099.jpg', './data/train/air hockey/100.jpg', './data/train/air hockey/101.jpg', './data/train/air hockey/102.jpg', './data/train/air hockey/103.jpg', './data/train/air hockey/104.jpg', './data/train/air hockey/105.jpg', './data/train/air hockey/106.jpg', './data/train/air hockey/107.jpg', './data/train/air hockey/108.jpg', './data/train/air hockey/109.jpg', './data/train/air hockey/110.jpg', './data/train/air hockey/111.jpg', './data/train/air hockey/112.jpg'] -
画像を表示する
2.で取得した画像のパスとPillowのImageクラスを用いて画像を読み込み,matplotlibを用いて読み込んだ画像を表示します.# 画像を読み込む img = Image.open(train_air_hockey_files[0]) # 画像を表示 plt.imshow(img) plt.show()
以下のように,subplotを用いることで複数の画像をまとめて表示することもできます.(ここはざっと見るだけでOK!)
# 複数枚の画像をまとめて表示 plt.figure(figsize=(10, 3)) plt.subplot(1,3,1) # 1行3列の1番目の位置 plt.imshow(Image.open(train_air_hockey_files[0])) plt.subplot(1,3,2) # 1行3列の2番目の位置 plt.imshow(Image.open(train_basketball_files[0])) plt.subplot(1,3,3) # 1行3列の3番目の位置 plt.imshow(Image.open(train_baseball_files[0])) plt.show()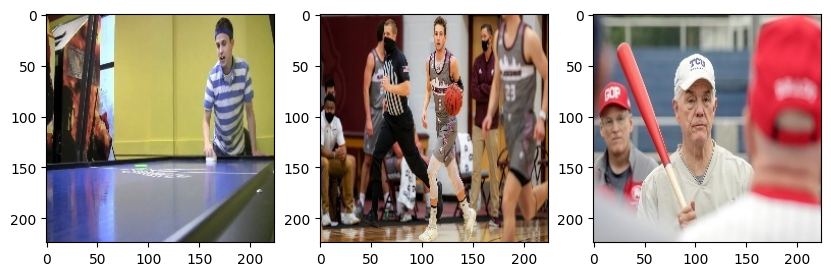
-
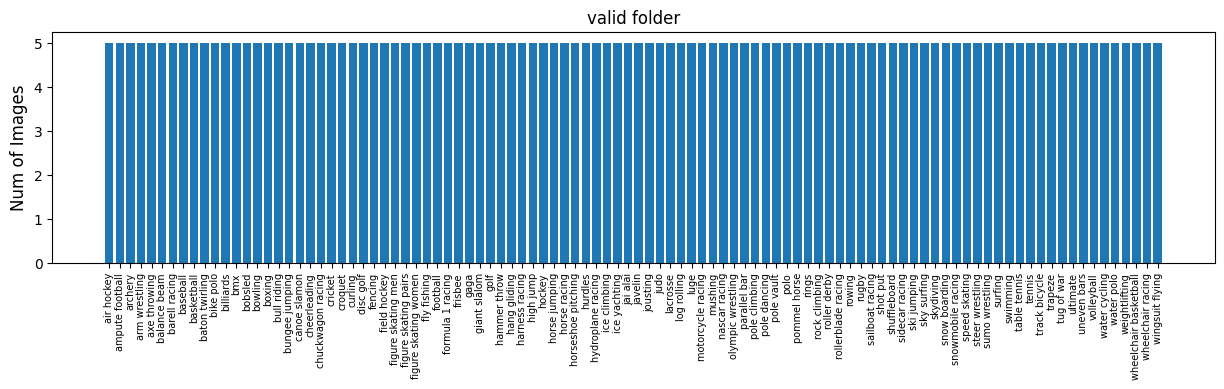
全てのスポーツ画像の枚数を把握する (ここはざっと見るだけでOK!)
先ほどまでは,trainフォルダ内の3種類のスポーツ画像の枚数を確認し,画像の表示を行ったが,全てのフォルダのスポーツごとの枚数を表示すると以下のようになります.# 指定したフォルダ内のスポーツごとの枚数を表示する関数 def plot_bar_graph(dir_name): sport_dirs = glob.glob(dir_name + "/*") sport_names = [] sport_counts = [] for sport_dir in sport_dirs: sport_name = sport_dir.split("/")[-1] sport_names.append(sport_name) sport_files = glob.glob(sport_dir + "/*.jpg") sport_counts.append(len(sport_files)) plt.figure(figsize=(15, 3)) plt.bar(sport_names, sport_counts) plt.xticks(rotation=90, fontsize=7) plt.ylabel('Num of Images', fontsize=12) plt.title(dir_name.split("/")[-1] + " folder", fontsize=12) plt.show() # 訓練データのスポーツごとの枚数を表示 plot_bar_graph("./data/train") # 検証用データのスポーツごとの枚数を表示 plot_bar_graph("./data/valid") # テスト用データのスポーツごとの枚数を表示 plot_bar_graph("./data/test")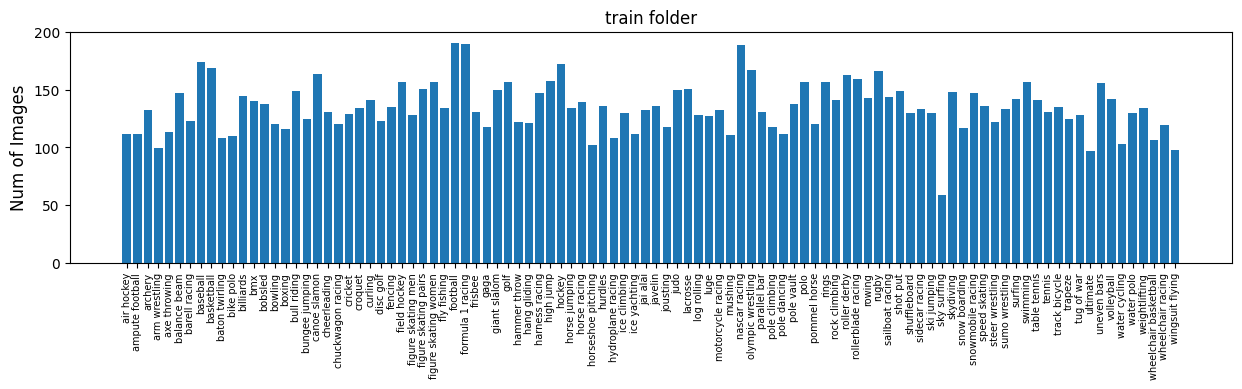
DatasetとDataloaderを作成
モデルを学習させるときには,データを小さなグループ(ミニバッチ)に分けて処理するミニバッチ学習が良く用いられます.このとき,ミニバッチのサイズはバッチサイズ(batch_size)と呼ばれます.
ミニバッチごとにデータを取り出す際に使用するのが,DataLoaderとDatasetです.DataLoaderは,Datasetを用いてミニバッチにまとめたデータを取り出します.
DatasetとDataLoaderの詳しい説明は以下の通りです.
-
Datasetは,データソースからデータを1つずつ(画像とラベル)取り出し,そのデータに必要な前処理(transform)を行う.
今回は,trainフォルダ, validフォルダ,testフォルダの下にスポーツの種類ごとにフォルダが用意されているため,datasets.ImageFolderを用いてdatasetを作成する.
例えば,train_datasetは,trainフォルダとtrain_transformを指定して作成する.# train_datasetの作成例 train_dataset = datasets.ImageFolder("./data/train", transform=train_transform)(データの様式によっては,自作でdatasetクラスを定義する必要がある)
-
DataLoaderは,画像やラベルを指定されたバッチサイズごとにまとめ,順次取り出す.
DataLoaderには,suffleという引数があり,Trueにするとランダムにデータを取り出すことができ,Falseにすると同じ順番でデータを取り出すことができる.
そのため,学習用のdataloaderを作成する場合は,shuffle=Trueとし,検証用やテスト用のdataloaderを作成する場合は,shuffle=Falseとする.
例えば,train_dataloaderは,train_datasetとバッチサイズを128で指定し,shuffleはTrueとする.# train_loaderの作成例 train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True) -
前処理(transform) は,通常,学習用とテスト用で異なる設定を行う.
学習用には,データ拡張(ランダムな回転や反転など)を追加し,データのバリエーションを増やす工夫を行う.検証用やテスト用には,一貫した形で画像が用意できるように主にリサイズや正規化だけを行うことが一般的である.
以下のセルで,transform, dataset, dataloaderを作成しています.
# 学習用の前処理
train_transform = transforms.Compose([
transforms.Resize((256,256)), # 256x256にリサイズ
transforms.CenterCrop((224,224)), # 224x224にクロップ
transforms.RandomHorizontalFlip(p=0.5), # 50%の確率で左右反転
transforms.ToTensor(), # Tensorに変換([0, 1]の範囲に正規化)
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 平均と標準偏差で正規化
])
# 検証用とテスト用の前処理
val_transform = transforms.Compose([
transforms.Resize((256,256)),
transforms.CenterCrop((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# Datasetの作成
train_dataset = datasets.ImageFolder("./data/train", transform=train_transform)
val_dataset = datasets.ImageFolder("./data/valid", transform=val_transform)
test_dataset = datasets.ImageFolder("./data/test", transform=val_transform)
# DataLoaderの作成
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
train_epoch関数とval_epoch関数を定義
train_epoch関数とval_epoch関数でモデルの学習と検証を行います.
-
train_epoch関数
この関数は,1エポック分の学習を行い,そのエポックにおけるloss(誤差)とacc(精度)を計算する.
学習時には,以下のようにモデルを訓練モードに変更する.model.train() -
val_epoch関数
この関数は,1エポック分の検証を行い,そのエポックにおけるloss(誤差)とacc(精度)を計算する.
検証時には,以下のようにモデルを検証モードに変更する.model.eval()
以下のセルで,train_epoch関数とtest_epoch関数を定義しています.
def train_epoch(model, dataloader, criterion, optimizer, device):
# lossとaccの初期化
train_loss, train_acc = 0, 0 # このtrain_lossとtrain_accにlossとaccを加算していき,最後にデータ数で割ることで平均を計算する
model.train() # モデルを学習モードに設定
for images, labels in tqdm(dataloader): # dataloaderからデータを取り出す
images, labels = images.to(device), labels.to(device) # データをGPUに転送
optimizer.zero_grad() # 勾配の初期化
outputs = model(images) # モデルで推論
loss = criterion(outputs, labels) # lossの計算
train_loss += loss.item() * images.size(0) # lossを蓄積
acc = (outputs.max(1)[1] == labels).sum() # accの計算
train_acc += acc.item() # accを蓄積
loss.backward() # 逆伝播
optimizer.step() # パラメータの更新
avg_train_loss = train_loss / len(dataloader.dataset) # lossの平均を計算
avg_train_acc = train_acc / len(dataloader.dataset) # accの平均を計算
return avg_train_loss, avg_train_acc
def val_epoch(model, dataloader, criterion, device):
# lossとaccの初期化
val_loss, val_acc = 0,0
model.eval() # モデルを評価モードに設定
with torch.no_grad(): # val_epoch関数では,勾配を計算しない
for images, labels in tqdm(dataloader): # dataloaderからデータを取り出す
images, labels = images.to(device), labels.to(device) # データをGPUに転送
outputs = model(images) # モデルで推論
loss = criterion(outputs, labels) # lossの計算
val_loss += loss.item() * images.size(0) # lossを蓄積
acc = (outputs.max(1)[1] == labels).sum() # accの計算
val_acc += acc.item() # accを蓄積
avg_val_loss = val_loss / len(dataloader.dataset) # lossの平均を計算
avg_val_acc = val_acc / len(dataloader.dataset) # accの平均を計算
return avg_val_loss, avg_val_acc
モデルを作成
今回は,timmと呼ばれる事前学習モデルを簡単に利用できるライブラリを用いてモデルを作成します.
timmでは,timm.create_modelという関数を使用してモデルを作成することができます.モデルを作成する際には,timm.create_model("モデル名", pretrained=True, num_classes=クラス数)のように.モデル名やクラス数を指定することで目的に合わせたモデルを作成することができます.
また,モデルはGPUに載せることで学習時と検証時の計算速度を大幅に向上することができます.モデルをGPU載せる時は,model = model.to(device)と使用するデバイスを指定します.
# クラス数の取得,確認
num_classes = len(train_dataset.classes)
print("クラス数: ", num_classes)
# 使用するGPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# モデルの作成
model = timm.create_model("resnet18", pretrained=True, num_classes=num_classes)
model.to(device)
損失関数を定義
損失関数とは,正解値(ラベル)と,モデルの予測値とのロス(ずれ)を計算するための関数です.今回は,多クラスの画像分類を行うため,CrossEntropyLoss関数を使用します.
# 損失関数
criterion = nn.CrossEntropyLoss()
最適化アルゴリズムを設定
最適化アルゴリズム(Optimizer)とは,先ほど説明した正解値(ラベル)と,モデルの予測値とのロスをできる限り小さくするアルゴリズムです.学習率(Learning Rate)を調整することで,モデルのパラメータを更新し,最適な解に近づけることができます.今回は,OptimizerとしてAdamWを用いることにしました.
# 学習率
lr = 0.0001
# optimizerの作成
optimizer = optim.AdamW(model.parameters(), lr=lr)
学習を実行する
モデルを学習する際には,学習用データ全体を何回学習するかを示すエポック数(epoch)を設定します.エポック数は,モデルの構造や使用するデータ,ハイパーパラメータなどの条件によって適切な値が異なります.
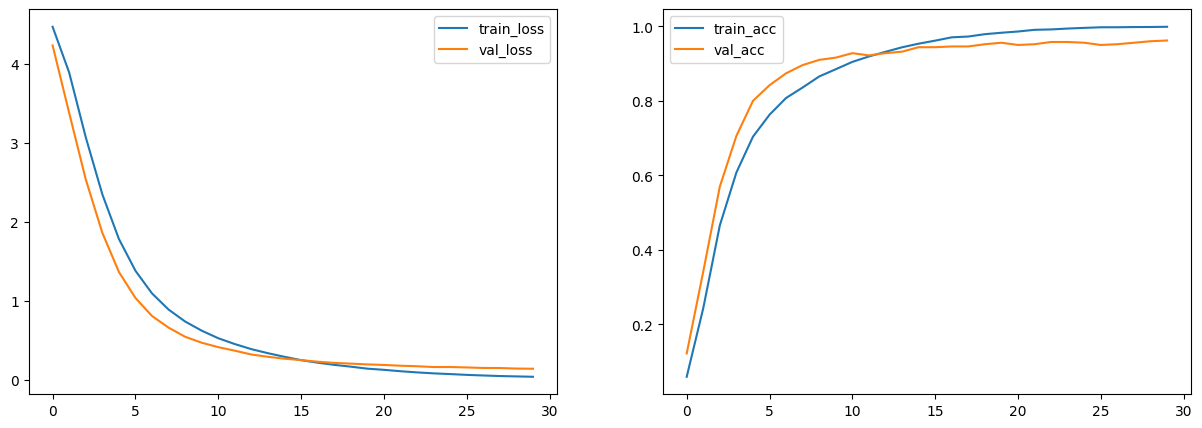
学習は,このエポック数を用いてfor文を回し,そのfor分の中でモデルの学習と検証を行います.エポックごとに計算されたtrain_loss, train_acc, val_loss, val_accはそれぞれリストに保存し,学習曲線の表示に使用します. 指定したエポック数における学習が終わり次第,学習済みのモデルを保存します.
# エポック数
num_epochs = 30
# train_loss, train_acc, val_loss, val_accを保存するリスト
train_loss_list, train_acc_list, val_loss_list, val_acc_list = [], [], [], []
# 学習
for epoch in range(num_epochs):
# train_epoch関数とval_epoch関数で1エポック分の学習と評価を行う
train_loss, train_acc = train_epoch(model, train_loader, criterion, optimizer, device)
val_loss, val_acc = val_epoch(model, test_loader, criterion, device)
# 各値をリストに追加
train_loss_list.append(train_loss)
train_acc_list.append(train_acc)
val_loss_list.append(val_loss)
val_acc_list.append(val_acc)
# ログを出力
print(f"Epoch: {epoch+1}, train_loss: {train_loss:.4f}, train_acc: {train_acc:.4f}, val_loss: {val_loss:.4f}, val_acc: {val_acc:.4f}")
# modelの保存
torch.save(model.state_dict(), f"model_epoch{num_epochs}.pth")
100%|██████████| 106/106 [00:27<00:00, 3.82it/s]
100%|██████████| 16/16 [00:01<00:00, 14.79it/s]
Epoch: 1, train_loss: 4.4732, train_acc: 0.0594, val_loss: 4.2370, val_acc: 0.1220
100%|██████████| 106/106 [00:27<00:00, 3.82it/s]
100%|██████████| 16/16 [00:01<00:00, 15.81it/s]
Epoch: 2, train_loss: 3.8924, train_acc: 0.2437, val_loss: 3.3808, val_acc: 0.3420
100%|██████████| 106/106 [00:27<00:00, 3.83it/s]
100%|██████████| 16/16 [00:00<00:00, 16.13it/s]
Epoch: 3, train_loss: 3.0733, train_acc: 0.4658, val_loss: 2.5400, val_acc: 0.5700
100%|██████████| 106/106 [00:27<00:00, 3.85it/s]
100%|██████████| 16/16 [00:01<00:00, 15.54it/s]
Epoch: 4, train_loss: 2.3504, train_acc: 0.6078, val_loss: 1.8622, val_acc: 0.7060
100%|██████████| 106/106 [00:27<00:00, 3.85it/s]
100%|██████████| 16/16 [00:01<00:00, 15.53it/s]
Epoch: 5, train_loss: 1.7848, train_acc: 0.7038, val_loss: 1.3664, val_acc: 0.8000
100%|██████████| 106/106 [00:27<00:00, 3.89it/s]
100%|██████████| 16/16 [00:01<00:00, 14.49it/s]
Epoch: 6, train_loss: 1.3810, train_acc: 0.7628, val_loss: 1.0362, val_acc: 0.8420
100%|██████████| 106/106 [00:27<00:00, 3.82it/s]
100%|██████████| 16/16 [00:01<00:00, 15.72it/s]
Epoch: 7, train_loss: 1.0939, train_acc: 0.8077, val_loss: 0.8077, val_acc: 0.8740
100%|██████████| 106/106 [00:26<00:00, 3.93it/s]
100%|██████████| 16/16 [00:00<00:00, 16.29it/s]
Epoch: 8, train_loss: 0.8893, train_acc: 0.8358, val_loss: 0.6602, val_acc: 0.8960
100%|██████████| 106/106 [00:27<00:00, 3.86it/s]
100%|██████████| 16/16 [00:01<00:00, 15.54it/s]
Epoch: 9, train_loss: 0.7374, train_acc: 0.8655, val_loss: 0.5441, val_acc: 0.9100
100%|██████████| 106/106 [00:27<00:00, 3.91it/s]
100%|██████████| 16/16 [00:01<00:00, 15.82it/s]
Epoch: 10, train_loss: 0.6216, train_acc: 0.8849, val_loss: 0.4687, val_acc: 0.9160
100%|██████████| 106/106 [00:27<00:00, 3.81it/s]
100%|██████████| 16/16 [00:01<00:00, 15.55it/s]
Epoch: 11, train_loss: 0.5257, train_acc: 0.9046, val_loss: 0.4124, val_acc: 0.9280
100%|██████████| 106/106 [00:27<00:00, 3.85it/s]
100%|██████████| 16/16 [00:01<00:00, 15.92it/s]
Epoch: 12, train_loss: 0.4517, train_acc: 0.9191, val_loss: 0.3678, val_acc: 0.9220
100%|██████████| 106/106 [00:27<00:00, 3.89it/s]
100%|██████████| 16/16 [00:00<00:00, 16.59it/s]
Epoch: 13, train_loss: 0.3873, train_acc: 0.9316, val_loss: 0.3194, val_acc: 0.9280
100%|██████████| 106/106 [00:27<00:00, 3.85it/s]
100%|██████████| 16/16 [00:01<00:00, 15.14it/s]
Epoch: 14, train_loss: 0.3358, train_acc: 0.9437, val_loss: 0.2903, val_acc: 0.9320
100%|██████████| 106/106 [00:27<00:00, 3.89it/s]
100%|██████████| 16/16 [00:00<00:00, 16.56it/s]
Epoch: 15, train_loss: 0.2902, train_acc: 0.9535, val_loss: 0.2663, val_acc: 0.9440
100%|██████████| 106/106 [00:27<00:00, 3.89it/s]
100%|██████████| 16/16 [00:01<00:00, 15.36it/s]
Epoch: 16, train_loss: 0.2479, train_acc: 0.9616, val_loss: 0.2481, val_acc: 0.9440
100%|██████████| 106/106 [00:27<00:00, 3.86it/s]
100%|██████████| 16/16 [00:00<00:00, 17.72it/s]
Epoch: 17, train_loss: 0.2159, train_acc: 0.9705, val_loss: 0.2283, val_acc: 0.9460
100%|██████████| 106/106 [00:27<00:00, 3.88it/s]
100%|██████████| 16/16 [00:01<00:00, 15.17it/s]
Epoch: 18, train_loss: 0.1881, train_acc: 0.9727, val_loss: 0.2131, val_acc: 0.9460
100%|██████████| 106/106 [00:27<00:00, 3.83it/s]
100%|██████████| 16/16 [00:00<00:00, 17.08it/s]
Epoch: 19, train_loss: 0.1653, train_acc: 0.9790, val_loss: 0.2039, val_acc: 0.9520
100%|██████████| 106/106 [00:27<00:00, 3.89it/s]
100%|██████████| 16/16 [00:01<00:00, 15.41it/s]
Epoch: 20, train_loss: 0.1400, train_acc: 0.9828, val_loss: 0.1940, val_acc: 0.9560
100%|██████████| 106/106 [00:27<00:00, 3.90it/s]
100%|██████████| 16/16 [00:00<00:00, 16.09it/s]
Epoch: 21, train_loss: 0.1252, train_acc: 0.9861, val_loss: 0.1869, val_acc: 0.9500
100%|██████████| 106/106 [00:26<00:00, 3.95it/s]
100%|██████████| 16/16 [00:00<00:00, 16.26it/s]
Epoch: 22, train_loss: 0.1075, train_acc: 0.9907, val_loss: 0.1773, val_acc: 0.9520
100%|██████████| 106/106 [00:26<00:00, 3.96it/s]
100%|██████████| 16/16 [00:00<00:00, 16.64it/s]
Epoch: 23, train_loss: 0.0925, train_acc: 0.9917, val_loss: 0.1705, val_acc: 0.9580
100%|██████████| 106/106 [00:26<00:00, 3.93it/s]
100%|██████████| 16/16 [00:01<00:00, 14.91it/s]
Epoch: 24, train_loss: 0.0804, train_acc: 0.9941, val_loss: 0.1606, val_acc: 0.9580
100%|██████████| 106/106 [00:27<00:00, 3.92it/s]
100%|██████████| 16/16 [00:00<00:00, 16.10it/s]
Epoch: 25, train_loss: 0.0712, train_acc: 0.9958, val_loss: 0.1609, val_acc: 0.9560
100%|██████████| 106/106 [00:26<00:00, 3.94it/s]
100%|██████████| 16/16 [00:01<00:00, 14.55it/s]
Epoch: 26, train_loss: 0.0612, train_acc: 0.9975, val_loss: 0.1553, val_acc: 0.9500
100%|██████████| 106/106 [00:27<00:00, 3.90it/s]
100%|██████████| 16/16 [00:00<00:00, 16.53it/s]
Epoch: 27, train_loss: 0.0535, train_acc: 0.9976, val_loss: 0.1488, val_acc: 0.9520
100%|██████████| 106/106 [00:26<00:00, 3.98it/s]
100%|██████████| 16/16 [00:01<00:00, 15.78it/s]
Epoch: 28, train_loss: 0.0463, train_acc: 0.9981, val_loss: 0.1480, val_acc: 0.9560
100%|██████████| 106/106 [00:26<00:00, 3.94it/s]
100%|██████████| 16/16 [00:00<00:00, 16.89it/s]
Epoch: 29, train_loss: 0.0417, train_acc: 0.9982, val_loss: 0.1411, val_acc: 0.9600
100%|██████████| 106/106 [00:26<00:00, 3.97it/s]
100%|██████████| 16/16 [00:00<00:00, 17.09it/s]
Epoch: 30, train_loss: 0.0371, train_acc: 0.9988, val_loss: 0.1390, val_acc: 0.9620
Accuracy(正解率)とLoss(誤差)を表示する
plt.figure(figsize=(15, 5))
plt.subplot(1,2,1)
plt.plot(train_loss_list, label="train_loss") # train_loss_listをプロットし,ラベルを指定
plt.plot(val_loss_list, label="val_loss") # val_loss_listをプロットし,ラベルを指定
plt.legend() # 凡例を表示
plt.subplot(1,2,2)
plt.plot(train_acc_list, label="train_acc")
plt.plot(val_acc_list, label="val_acc")
plt.legend()
plt.show()
テスト用データに対する精度
学習用データと検証用データを用いて学習したモデルをロードして,テスト用データに対する精度を検証します.モデルをロードするときは,もう一度モデルを作成し,model.load_state_dict(torch.load("モデルのパス"))のようにモデルのパスを指定してロードします.
model = timm.create_model("resnet18", pretrained=False, num_classes=num_classes)
model.load_state_dict(torch.load(f"model_epoch{num_epochs}.pth"))
model.to(device)
def predict(model, dataloader, device):
test_acc = 0
model.eval()
with torch.no_grad():
for images, labels in tqdm(dataloader):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
acc = (outputs.max(1)[1] == labels).sum() # accの計算
test_acc += acc.item()
avg_test_acc = test_acc / len(dataloader.dataset)
return avg_test_acc
test_acc = predict(model, test_loader, device)
print("テスト用データに対する精度(Acc): ", test_acc*100, "%")
100%|██████████| 16/16 [00:01<00:00, 15.75it/s]
テスト用データに対する精度(Acc): 96.2 %
おわりに
最後まで見ていただきありがとうございました!
ご指摘等ございましたら,ご連絡いただけると嬉しいです!