本記事は「2025 Japan AWS Jr. Chanpions 夏のQiitaリレー 」の53日目の記事です。
過去の投稿はこちらからご覧ください!
はじめに
近頃はAWSで様々な生成AI系のサービスが提供されていますが、その中でもAmazon Comprehendはあまり馴染みが無くどういったことができるのかもピンと来ていませんでした。
そこで、今回は軽く触ってみて感触を掴むのと、触りながらどうしても気になったので日本の方言を食わせてどんな分析をするのか見てみます。
Amazon Comprehendとは
Amazon Comprehendとはざっくり言うと入力したドキュメントから情報抽出を行い、感情分析・エンティティ認識・キーフレーズ抽出・言語検出・構文解析などを行う自然言語処理サービスのことです。
ユースケースとしてはECサイトでの購入者レビューから感情分析を行ったり、キーフレーズ、エンティティ抽出機能を用いたドキュメント整理をしたりなどがあるそうです。
少し前まで日本語をNLPにかけて分析するのは難しいと聞いた記憶があるのですが、技術の進化はすごいですね。
料金は入力した文字数で決まります。100文字を1ユニットとし、ユニット量に応じて課金されます。100文字以下なら無料なのかと言えばそうではなく、1度の実行につき最低料金として3ユニット分の料金がかかります。詳細は公式サイトをご覧ください。
触ってみる
マネジメントコンソールから簡単に利用することができるので、まず標準的な日本語の短文を投げてみて、どのような分析がされるのか目で見ていきます。
利用準備
マネジメントコンソールからComprehendのページに飛び、左メニューで「Real-time analysis」を選ぶだけですぐに利用ができます。
Input dataのテキストボックス内に分析したい文章を入力し、Analyzeボタンを押すことで分析を行ってくれます。

今回は「子供たちにご飯を食べさせないとダメだから、早く帰るね!」という文を投げてみます。何気ない日常会話ですね。
分析結果
分析結果はInsights内のタブからカテゴリ別に確認することができます。
まずはSentiment(感情)から見ていきます。

感情はNeutral、Positive、Negative、Mixedの4つの観点が割合で表示されるようです。
この文だとNeutralが0.72、PositiveとNegativeが同じ0.13となっています。
一見中性的な内容の文ですが、言葉の裏にポジティブさやネガティブさを感じ取っているのだとしたら意外と深いところまで読んでくれるんだなあという印象です。
次にKey phrasesとLanguageを見てみます。


キーフレーズは「子供たち」、「ご飯」を挙げていますね。Confidenceというパラメータは自信や確度を表しているのでしょうか。「ダメ」や「帰る」は入らないのか?と思うものの、一旦納得します。
言語は日本語が挙げられています。こちらもConfidenceのパラメータがありますね。1.00なので相当自信があるのでしょう。正解です。
少しずつComprehendがやってくれることが見えてきました。
方言を投げてみる
本来なら他のカテゴリも見ながら標準語の文をどんどん投げてどういった分析をするのか見たいところですが、ここからは同じ意味で方言が異なる文を投げてやります。
今回は私の地元大阪の方言である関西(大阪)弁と、方言の中でもかなり難解で有名な津軽弁を例に挙げて試してみます。
「子供たちにご飯を食べさせないとダメだから、早く帰るね!」をそれぞれの方言に訳すと以下のようになります。
- 関西弁
「子供らにご飯食べさせなあかんから、はよ帰るわ!」
(訳:わたし) - 津軽弁
「わらはんどさ ままかせねばまいねはんで、へぐけーるじゃ!」
(訳:あおもりだいぼうけん(https://aomori-daibouken.com/4641 )様からお借りしました)
言葉遣いによる違いはあるかもしれないものの、ほとんど同じ意味の文なので正しく分析できていれば結果も概ね標準語と同じになるはずです。投げてみましょう。
関西弁の結果
関西弁の結果は以下のようになりました。
- Sentiment

- Key phrases

- Language

センチメントではかなりネガティブの値が高くなっています。もうすでに標準語の場合と大きく異なっていますが、キーフレーズを見ると「あかん」が入っているので、もしかするとこれが原因かもしれません。
そのキーフレーズは「子供ら」、「ご飯」まで同じなのは感心しました。ただ関西弁で「あかん」が入って標準語で「ダメ」が入らなかったのはなぜなんだろう…。
言語は日本語でConfidenceも1なので、ここは自信を持っているようです。
センチメントの結果と標準語との差が気になりますがこれはこれである程度理解できる結果です。少しチューニングすれば差も縮められそう。
津軽弁の結果
次に津軽弁を投げてみます。結果はどうなるのか。
- Sentiment
- Key phases

- Language
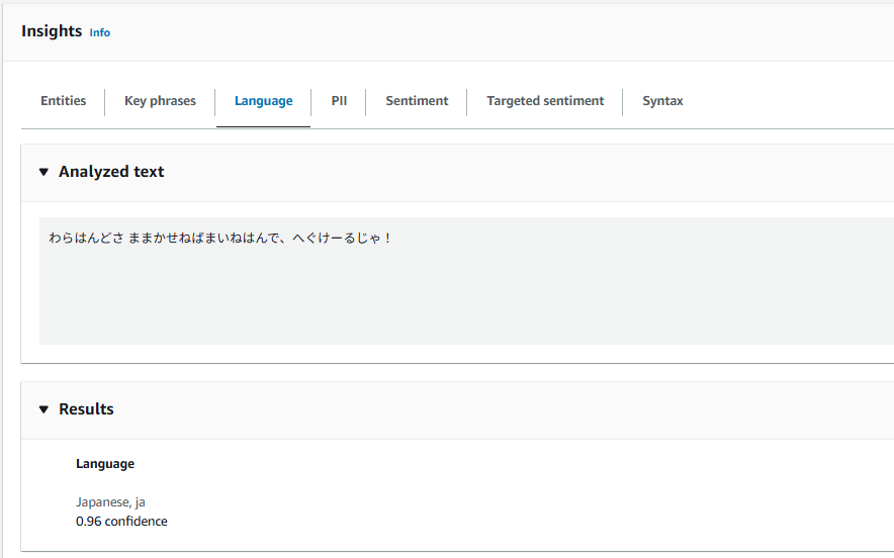
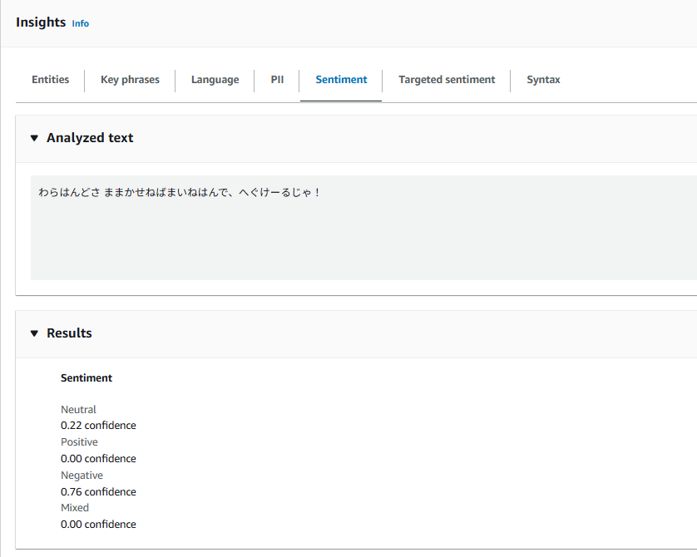
全然違う!
センチメントではポジティブ要素が消え、ネガティブの値が大きく上昇しています。
キーフレーズを見ると「わらはんどさ ままかせ」、「へぐ」が挙げられており、こちらも他の2つとは大きく異なります。ちなみに標準語であった「子供たち」、「ご飯」は津軽弁だとそれぞれ「わらはんど」、「まま」だそうです。
Confidenceも0.65なのでかなり混乱している様子です。
最後の言語も日本語が0.96で、あまりの難解さに自信を無くしていますね。
正直これがちゃんと分析できるなら相当優秀なモデルか中の人が津軽弁話者のどちらかだと思いますが…。
方言の中でもメジャーな関西弁はまだしも、津軽弁は圧倒的に学習データが足りないのでしょう。
日本語でも使えるComprehendですが、方言だとなかなか厳しいところがありそうです。
まとめ
Comprehendを触ってみるついでに、2つの方言を投げてどんな分析を行うのか見てみました。
思ったよりいろいろな観点で分析してくれるんだなとう印象ですが、まだ方言で書かれた文を分析するのは難しいようです。
今回は好奇心で方言を試してみたものの、とはいえ実際にシステムに利用する上でこれはある種注意点になるような気もします。
例えば話者の多い方言だとレビューサイト等でもそのような文章を見る機会は少なくないですし、コールセンターだとなおさらですよね。そこで統一感のある分析を行うならば文章を加工する必要も場合によっては出てくると考えられます。
Bedrockなんかで標準語に訳させてComprehendに投げるとか…と考えましたがそのBedrockは方言を訳せるのか?と疑問が浮かんだので次やるならこれを試してみたいなと思います。
最後まで読んでいただきありがとうございました。それでは。