これは何?
こんな記事
を先日書いた。
Kahan のアルゴリズムがあるのは知っていたけど、自分で書いたことは一度もなく。
それとは別に部分和を使うと誤差が減らせるという
ノウハウもある。
で。
どれがいいのか比べてみた。
実験内容
100個〜1万個の数値を足す。
数値は全部単精度。
単精度の値を有理数にしてから加算することで誤差のない値を求めておく。
で。
各アルゴリズムで計算する。
そして。
誤差 = ([誤差のない値] - [各アルゴリズムで計算した値]) ÷ [誤差のない値]
という形で誤差を計算して、誤差の二乗の平均値の平方根を評価する。
加算アルゴリズム
頭から順に加算
普通に足す。
float sum(float const *begin, float const *end)
{
float s = 0;
for (auto it = begin; it != end; ++it)
{
s += *it;
}
return s;
}
素朴だけど、誤差が多めになる。
倍精度を使う
float with_double(float const *begin, float const *end)
{
double s = 0;
for (auto it = begin; it != end; ++it)
{
s += *it;
}
return static_cast<float>(s);
}
倍精度が使えるのなら、使っちゃうのが簡単。
データが倍精度だったら 4倍精度を使いたいところだけど、現実的かどうかはケースバイケース。
部分和の和
前述の記事の方法。
書き方が違うけど、方針はだいたい同じ。
float sum_of_parts(float const *begin, float const *end)
{
auto len = end - begin;
switch (len)
{
case 0:
return 0;
case 1:
return *begin;
default:
break;
}
auto mid = begin + len / 2;
return sum_of_parts(begin, mid) + sum_of_parts(mid, end);
}
値のばらつきが少ない場合、前半と後半は同じぐらいの値になるので加算による情報欠落が少ないだろうという読み。
並列実行と相性が良いはず。
Kahan
詳細は Wikipedia
を参照のこと。
float kahan(float const *begin, float const *end)
{
float sum = 0;
float c = 0;
for (auto it = begin; it != end; ++it)
{
auto y = *it - c;
auto t = sum + y;
c = (t - sum) - y;
sum = t;
}
return sum;
}
足してから、足した結果増えた分と増やしたかった値を比べて次に活かす、みたいな話。
整列してから Kahan
絶対値が大きい順に整列してから Kahan で加算する。
float sort_kahan(float const *begin, float const *end)
{
std::vector<float> v(begin, end);
float *b = v.data();
float *e = b + v.size();
std::sort(b, e, //
[](float a, float b) -> bool
{
return !(std::abs(a) <= std::abs(b));
});
return kahan(b, e);
}
小さい順より大きい順の方が誤差が少なかった。何故なのかはよくわからない。
Kahan-Babuska
Kahan と ruby の sum という記事を書いて、ruby の sum と Wikipedia の カハンのアルゴリズムはちょっと違うことを知ったのでアルゴリズムを追加。
ruby の sum と同様の計算
float kb1(float const *begin, float const *end)
{
float sum = 0;
float c = 0;
for (auto it = begin; it != end; ++it)
{
auto t = sum + *it;
c += std::abs(*it) <= std::abs(sum)
? sum - t + *it
: *it - t + sum;
sum = t;
}
return sum + c;
}
kb は、Kahan-Babuska の頭文字。計算内容は ruby の Enumerable#sum と同様。
Kahan-Babuska 2段
float kb2(float const *begin, float const *end)
{
float sum = 0;
float c0 = 0;
float c1 = 0;
for (auto it = begin; it != end; ++it)
{
auto t = sum + *it;
auto v0 = std::abs(*it) <= std::abs(sum)
? sum - t + *it
: *it - t + sum;
auto t0 = c0 + v0;
c1 += std::abs(v0) <= std::abs(c0)
? c0 - t0 + v0
: v0 - t0 + c0;
c0 = t0;
sum = t;
}
return sum + c0 + c1;
}
ruby の Enumerable#sum の計算を見て、もっと精度上げられるなと思ったので、それを実装した。
調査結果
以下、 sum は単純加算。
with_double は倍精度で単純加算。
sum_of_parts は、前半と後半の合計を再帰。
kahan は Kahan のアルゴリズム。
sort_kahan は、大きい順に整列してから Kahan のアルゴリズム。
kb1 は、ruby の sum と同等。
kb2 は、ruby の sum で誤差を積んでいるんだけど、その加算に ruby の sum と同様の計算をする。
そして、データのばらつき方をいろいろ変えて試してみた。
横軸は対数目盛にした。
棒がないのは誤差ゼロということ。
2の±32乗
2のn乗をデータとするんだけど、 n は、-32〜32 までの一様乱数。
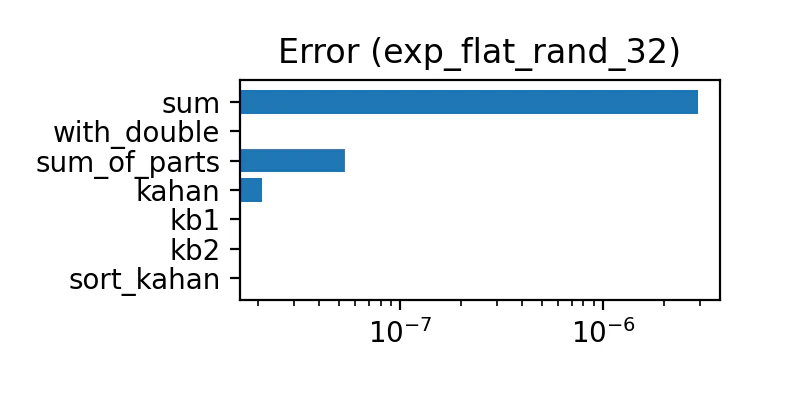
±2の±32乗
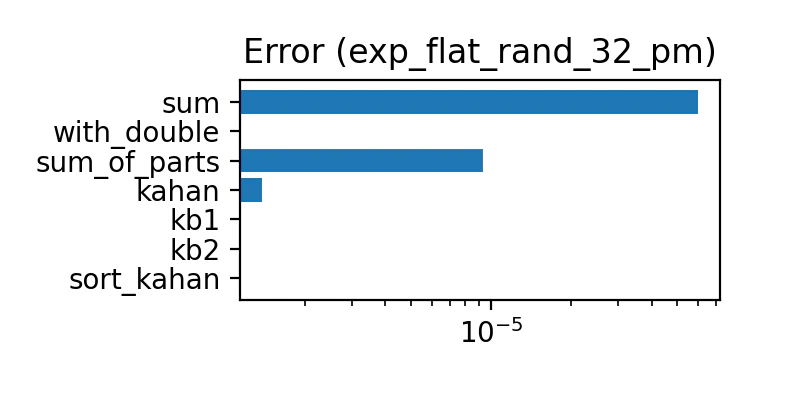
±2のn乗をデータとするんだけど、 n は、-32〜32 までの一様乱数。符号も乱数で決める。
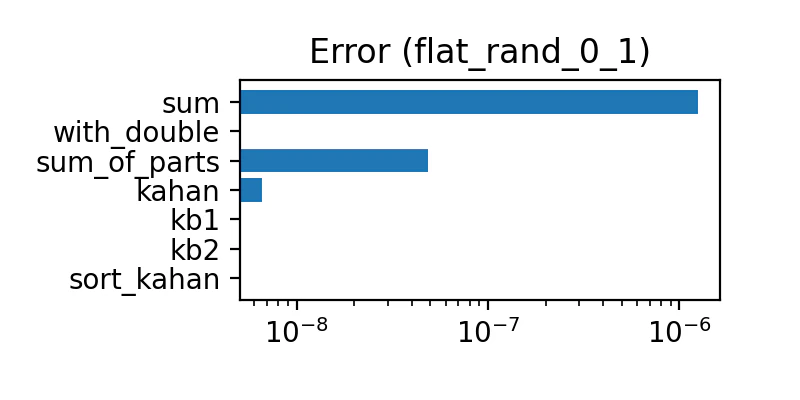
0〜1
0〜1 の一様乱数。
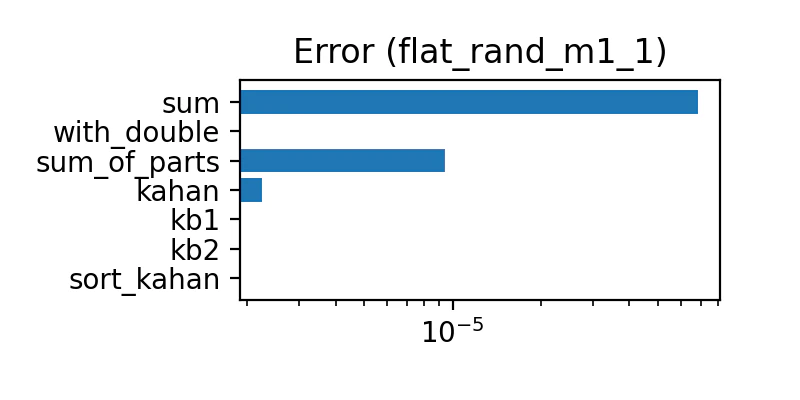
-1〜1
-1〜1 の一様乱数
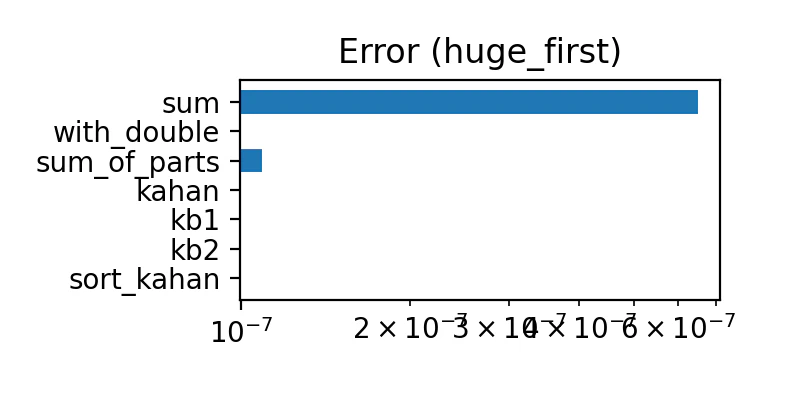
最初が巨大
先頭に $2^{22}$ があり、残りは 0.9〜1.1 の一様乱数。
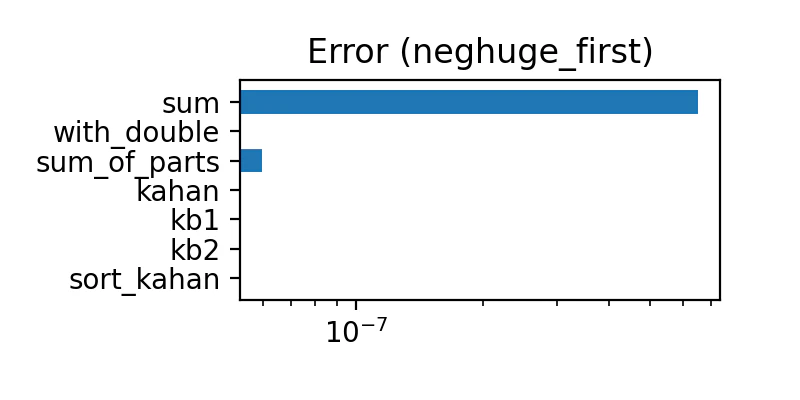
最初が負の巨大
先頭に $-2^{22}$ があり、残りは 0.9〜1.1 の一様乱数。
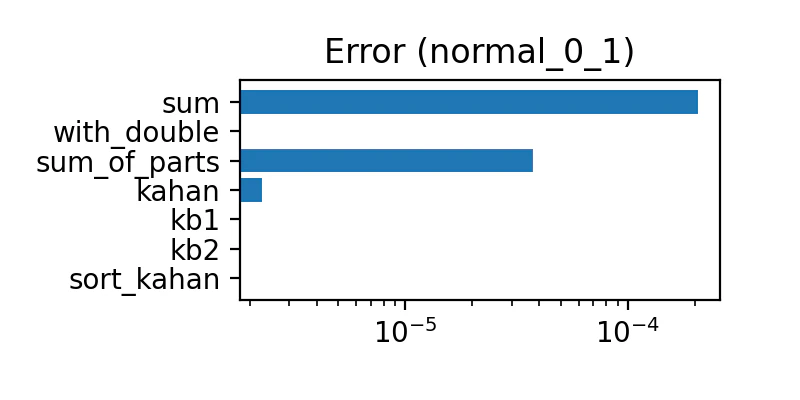
平均0、標準偏差1 の正規分布
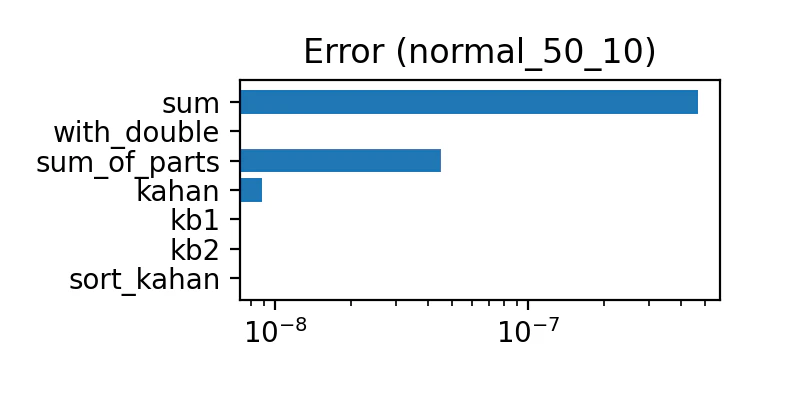
平均50、標準偏差10 の正規分布
二乗
1〜1万 をシャッフルしてからそれぞれを二乗した。
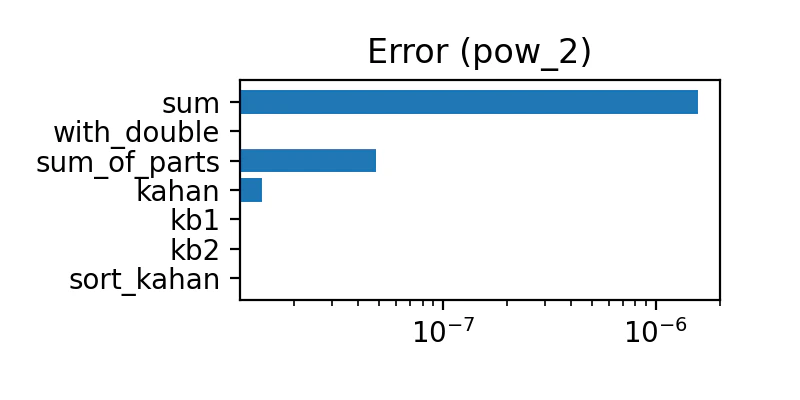
悪意のあるデータ
最初に合計がゼロにならないようにちょっとデータがあって、残りは$$10^{18}, 10^{12}, 10^{6}, rand, -10^{18}, -10^{12}, -10^{6}$$の繰り返し。 $rand$ は、 ±1 の範囲の一様乱数。

まとめ
誤差の量は下表のようになった
| アルゴリズム | 悪意のあるデータ以外 | 悪意のあるデータ |
|---|---|---|
| sum | 多い | 多い |
| with_double | 全部ゼロ | 普通 |
| sum_of_parts | 少ない | 多い |
| kahan | とても少ない | 多い |
| kb1 | 全部ゼロ | 少ない |
| kb2 | 全部ゼロ | とても少ない |
| sort_kahan | 全部ゼロ | ゼロ |
となっていた。
kahan も相当強いと思ったけど、sort_kahan は全データで誤差ゼロという圧倒的な強さだった。
びっくりした。
というわけで、誤差少なく総和を求めたい場合
- より高い精度での加算が現実的ならそうする。
- 並列実行で速度を稼ぎたいとかそういう事情があるなら sum_of_parts のような感じのことをする。精度はちょっとしかよくならない。
- より高い精度での加算が現実的ではないけど精度を上げたい場合。
- ruby の sum と同様の kb1 がおすすめ。加算の経過をモニタしながら中断とかもできる。
- データの性質によっては、kb2 を選ぶことで何桁か精度を上げることができるけど、稀だと思う。
- 時間に余裕があり、加算の経過のモニタが不要なら sort_kahan のような計算が最強みたいだけど、これが必要なケースは極めて稀だと思う。
こんな感じで選べば良いと思う。
kahan は kb1 と比べるとメリットがないので、 kb1 を使うのが良い。
sort_kahan で kahan 使っちゃってるけど、これも kb1 に書き換えたほうが良かったか。ぐぬぬ。
なお。
実験のソースコードは https://github.com/nabetani/kahanchallenge においてある。