これは何?
Twitter で軽率に
と書いたので、本当にそうなのかどうか調べてみたら驚くべき結果に!
となったので記事にしてみた。
とはいえ。
これはマイクロベンチマークに過ぎないので、全体的な性能とかではなく、そういう事がありうるとうだけのこと。
調べたこと
なんとなく、動的に定められる関数を呼び出すのがいいなと思って、こんなコードにしてみた。
あと、メモリ確保にもたくさん時間を使っている。
go 版
package main
import (
"fmt"
"os"
"runtime"
"strconv"
"time"
)
type proc = func(a uint32) uint32
func test(num uint32) uint32 {
m := make([]proc, 0, num)
for ix := uint32(0); ix < num; ix++ {
i := ix
m = append(m, func(a uint32) uint32 {
x := (i+a)*7 + 11
y := (x+a)*13 + 15
z := (y+i)*17 + 19
w := (z+i+a)*23 + 29
t := x ^ (x << 11)
return ((w ^ (w >> 19)) ^ (t ^ (t >> 8))) % num
})
}
sum := uint32(0)
for i := uint32(0); i < num; i++ {
sum += func(s0 uint32) uint32 {
s := s0
b := make([]bool, num)
for {
if b[s] {
return s
}
b[s] = true
s = m[s](i)
}
}(i)
sum %= 1 << 24
}
return sum
}
func main() {
num, err := strconv.ParseInt(os.Args[1], 10, 32)
if err != nil {
panic(err)
}
t0 := time.Now()
r := test(uint32(num))
tick := time.Now().Sub(t0)
ms := float64(tick.Nanoseconds()) * 1e-6
fmt.Printf("r:%d, Go version:%q, tick:%.2fms\n", r, runtime.Version(), ms)
}
C++ 版
C++ でも同じ趣旨のコードを書いた。
コード
#include <cstdio>
#include <cstdlib>
#include <cstdint>
#include <chrono>
#include <vector>
#include <functional>
namespace ch = std::chrono;
using cl = std::chrono::steady_clock;
uint32_t test(uint32_t num){
std::vector<std::function<uint32_t(uint32_t)>> m;
m.reserve(num);
for( uint32_t i=0; i<num ; ++i ){
m.emplace_back( [i,num](uint32_t a)->uint32_t{
uint32_t x = (i+a)*7 + 11;
uint32_t y = (x+a)*13 + 15;
uint32_t z = (y+i)*17 + 19;
uint32_t w = (z+i+a)*23 + 29;
uint32_t t = x ^ (x << 11);
return ((w ^ (w >> 19)) ^ (t ^ (t >> 8))) % num;
});
}
uint32_t sum=0;
for(uint32_t i=0 ; i<num ; i++){
sum += [num,&m,i](uint32_t s)->uint32_t{
std::vector<bool> b(num);
for(;;){
if (b[s]){
return s;
}
b[s]=true;
s = m[s](i);
}
}(i);
sum %= (1u<<24);
}
return sum;
}
int main( int argc, char const * argv[]){
uint32_t num = argc<=1 ? 1000 : std::atoi(argv[1]);
auto t0 = cl::now();
uint32_t r = test(num);
auto t1 = cl::now();
auto ms = ch::duration_cast<ch::microseconds>(t1-t0).count() * 1e-3;
printf( "r:%d, compiler:%s, tick:%.2fms\n" ,r, __VERSION__, ms);
return 0;
}
C++ の方は、関数呼び出しが std::function だったりするのはちょっとチューニングの余地があるかもと思ったけど、気楽に書いてみた。
std::vector<bool> が吉と出るか凶と出るか、という面もある。
結果
実行すると
$ cmd 50000
r:8223390, Go version:"go1.18", tick:766.56ms
のようになる。
これをグラフにまとめると
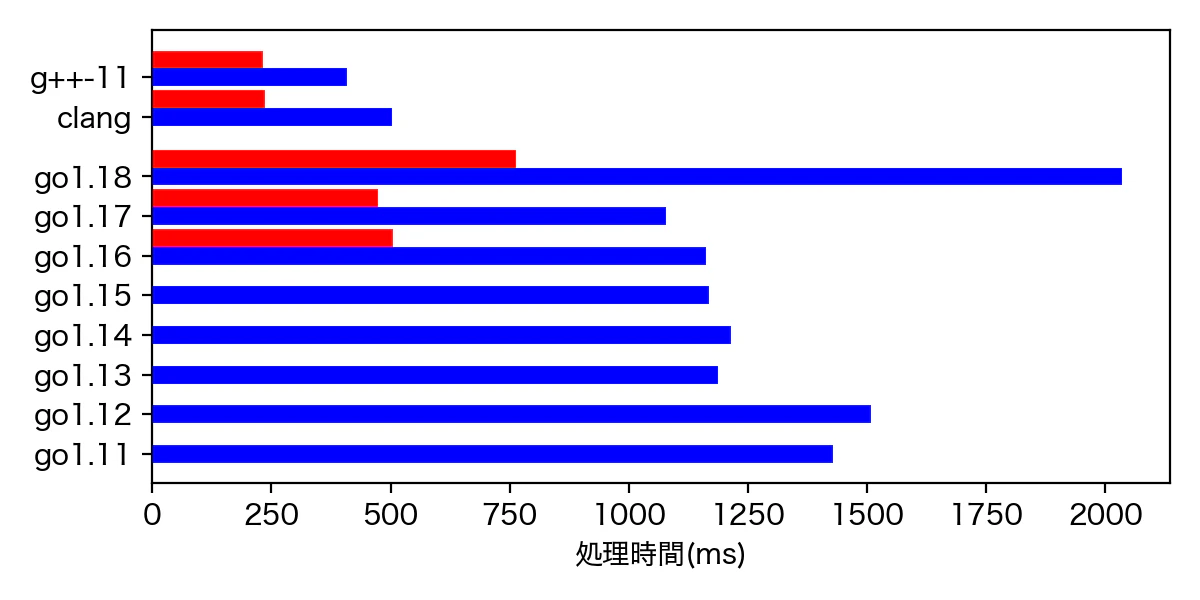
こうなる。
赤が MacBook Pro(14インチ、2021)。つまり、M1 Pro 非 MAX。
青が MacBook Pro (Retina, 15-inch, Mid 2015)。つまり、Intel Core i7 2.2GHz。
Darwin ARM64 は 1.16以降しかなかった。
Intel版も 1.10 以前はなんかうまく動かせなかった。
こうしてみると、1.11 から 1.17 までは多少凸凹はあるものの概ね順調に速くなっていたが、1.18 で突然遅くなっている。
intel 版を見ると、
r:8223390, Go version:"go1.17", tick:1076.87ms
r:8223390, Go version:"go1.18.4", tick:2033.70ms
M1 Pro(非MAX) だと
r:8223390, Go version:"go1.17", tick:473.50ms
r:8223390, Go version:"go1.18", tick:763.09ms
となっており、intel 版では倍近く、M1 Pro(非MAX) でも 1.6倍の時間がかかるようになっている。
先のツイートでは
C / C++ と同じぐらい速い印象です。
などと書いていたが、このマイクロベンチマークを見る限り、差は詰まっているものの倍ぐらいの処理時間を要している。
なお繰り返しておくと。
これはマイクロベンチマークに過ぎない。そういうこともあるよ、というだけのこと。
調査
なんで go1.18 が遅いんだろうと思い。
こう
for i := uint32(0); i < num; i++ {
sum += func(s0 uint32) uint32 {
s := s0
b := make([]bool, num)
// 略
}(i)
sum %= 1 << 24
}
なっていた箇所を、こう
b := make([]bool, num)
for i := uint32(0); i < num; i++ {
sum += func(s0 uint32) uint32 {
s := s0
for ix := range b {
b[ix] = false
}
// 略
}(i)
sum %= 1 << 24
}
変えてみたら
r:8223390, Go version:"go1.16", tick:352.04ms
r:8223390, Go version:"go1.17", tick:345.57ms
r:8223390, Go version:"go1.18", tick:324.06ms
となった。新しいほど速い。順当。
b := make([]bool, num) が go1.18 で遅くなったように見える。
1.18 では、従来 763ms だったのが、この改変で 324ms になっている。
半分以上をこの make につかっていたということか。メモリ確保って恐ろしい。
一方。
C++ で同様の変更をしても誤差程度の違いしか出なかった。メモリの使い回しがうまくてきているということだと思う。
まとめ
go1.18 が go1.17 よりもはっきり遅くなるようなことがあると思っていなかったのでたいへん驚いた。
あと。
この内容なら C++ が速い。
蛇足
go1.18 の実行結果が、intel 版は "go1.18" なのに、 ARM64版は go1.18.4 なのはが気持ち悪い。
同じソースコードなのに。