1 この記事は
Pandas ,pythonの各種操作方法をメモする。
| 題名 | リンク |
|---|---|
| 【python】Pandasの使い方 | LINK |
| 【python】Pandas2の使い方 | LINK |
| 【python】Pandas3の使い方 | LINK |
| 【python】Pandas4の使い方 | LINK |
| 【python】Pandas5の使い方 | LINK |
| 【python】Pandas ,pythonコードメモ 6 | LINK |
2 内容
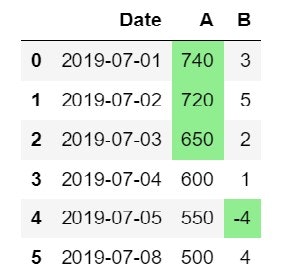
2-1 DateFrameの数値に着色する。
#出力したデータフレームの値に対して着色する。各列にそれぞれの着色ルールを適用する。
import pandas as pd
import numpy as np
dat = [
['2019-07-01',740,3],
['2019-07-02',720,5],
['2019-07-03',650,2],
['2019-07-04',600,1],
['2019-07-05',550,-4],
['2019-07-08',500,4]
]
df = pd.DataFrame(dat,columns=["Date","A","B"])
#ルールcolor0の定義
def color0(val):
color = 'lightgreen' if val >500 and val>600 else '' #1より大なら薄緑、その他は白
return 'background-color: %s' % color
#ルールcolor1の定義
def color1(val):
color = 'lightgreen' if val<0 else '' #1より大なら薄緑、その他は白
return 'background-color: %s' % color
#A列には着色ルールcolor0、B列には着色ルールcolor1を適用する。
df.style.applymap(color0,subset=['A']).applymap(color1,subset=['B'])
実行結果
2-2 各グループ内で条件に合致したデータが何個あるか算出する
#各グループ内で条件に合致したデータが何個あるか算出する。
import pandas as pd
df = pd.DataFrame(
{'id': list('aaabbcccc'),
'val': [1,2,3,1,2,1,2,4,5]})
print("dfを出力する")
display(df)
out1 = df.groupby('id').apply(lambda d: d[d.val >= 3]['val'].count())
print("各グループにおいて条件に合致するデータがいくらあるか出力する。")
print(out1)
出力結果

2-2 2次元データを対象に、該当データがDataFrameの何行目にあるかを探索する。
import pandas as pd
import numpy as np
print("列A,列Bを2次元を対象に、対象データがDataFrameの何行目にあるかを探索する。")
#dataを定義する。
dat = [
[100,111,'9997','740'],
[100,123,'9997','749'],
[100,200,'9997','757'],
[200,201,'9997','769'],
[200,202,'9997','762'],
[300,301,'9997','760']
]
#datをDataFrame型変数dfに格納する。
df = pd.DataFrame(dat,columns=["A","B","C","D"])
lst0=df["A"].to_list()
lst1=df["B"].to_list()
mi = pd.MultiIndex.from_arrays([lst0, lst1])
mi.get_loc((100, 200)) #A列100, B列200がDataFrameの何行目にあるかを返す。 出力→2
2-3 単独列を対象に、対象データがDataFrameの何行目にあるかを探索する。
import pandas as pd
import numpy as np
print("単独列を対象に、対象データがDataFrameの何行目にあるかを探索する。")
#dataを定義する。
dat = [
[100,111,'9997','740'],
[100,123,'9997','749'],
[100,200,'9997','757'],
[200,201,'9997','769'],
[200,202,'9997','762'],
[300,301,'9997','760']
]
#datをDataFrame型変数dfに格納する。
df = pd.DataFrame(dat,columns=["A","B","C","D"])
df=df.set_index(["A"])
print("#列Aの300は何行目にあるか?")
print(df.index.get_loc(300))
(出力)
単独列を対象に、対象データがDataFrameの何行目にあるかを探索する。
#列Aの300は何行目にあるか?
5
2-4 2つのDataFrameを結合させる。
import pandas as pd
import numpy as np
print("2つのDataFrameを結合させる。")
#dataを定義する。
dat0 = [
[1,120],
[3,140],
[4,201],
[5,202],
[6,301]
]
dat1 = [
[1,12],
[4,21],
[6,31],
[8,70]
]
#datをDataFrame型変数dfに格納する。
df0 = pd.DataFrame(dat0,columns=["A","B"])
df1 = pd.DataFrame(dat1,columns=["A","C"])
print("display df0")
display(df0)
print("display df1")
display(df1)
print("df0とdf1を結合させる。key列はA。列Aを基準にdf0とdf1に共通のものを残す")
df=pd.merge(df0, df1, on="A",how='inner')
display(df)
print("df0とdf1を結合させる。key列はA。列Aを基準にdf0とdf1の双方に含まれるものを出力する")
df=pd.merge(df0, df1, on="A",how='outer')
display(df)
print("df0とdf1を結合させる。key列はA。列Aを基準にdf0のみ含まれるものを出力する")
df=pd.merge(df0, df1, on="A",how='left')
display(df)
print("df0とdf1を結合させる。key列はA。列Aを基準にdf1のみ含まれるものを出力する")
df=pd.merge(df0, df1, on="A",how='right')
display(df)
(出力)
2つのDataFrameを結合させる。
display df0
A B
0 1 120
1 3 140
2 4 201
3 5 202
4 6 301
display df1
A C
0 1 12
1 4 21
2 6 31
3 8 70
df0とdf1を結合させる。key列はA。列Aを基準にdf0とdf1に共通のものを残す
A B C
0 1 120 12
1 4 201 21
2 6 301 31
df0とdf1を結合させる。key列はA。列Aを基準にdf0とdf1の双方に含まれるものを出力する
A B C
0 1 120.0 12.0
1 3 140.0 NaN
2 4 201.0 21.0
3 5 202.0 NaN
4 6 301.0 31.0
5 8 NaN 70.0
df0とdf1を結合させる。key列はA。列Aを基準にdf0のみ含まれるものを出力する
A B C
0 1 120 12.0
1 3 140 NaN
2 4 201 21.0
3 5 202 NaN
4 6 301 31.0
df0とdf1を結合させる。key列はA。列Aを基準にdf1のみ含まれるものを出力する
A B C
0 1 120.0 12
1 4 201.0 21
2 6 301.0 31
3 8 NaN 70
2-5 列単位にて重複している要素を抽出する
import pandas as pd
import numpy as np
print("列単位にて重複している要素を抽出する")
def dupli_get(df,COL):
list1=df[COL].values.tolist()
dup = [x for x in set(list1) if list1.count(x) > 1]
return dup
#dataを定義する。
dat0 = [
[1,120],
[3,140],
[3,201],
[5,202],
[5,301]
]
#datをDataFrame型変数dfに格納する。
df0 = pd.DataFrame(dat0,columns=["A","B"])
display(df0)
print("A列にて重複している要素を抽出する")
dupli_get(df0,"A")
(出力)
列単位にて重複している要素を抽出する
A B
0 1 120
1 3 140
2 3 201
3 5 202
4 5 301
A列にて重複している要素を抽出する
[3, 5]
2-6 DataFrame内の文字を置換する
df = pd.DataFrame({'A': [0, 1, 2, 3, 4],
'B': [5, 6, 7, 8, 0],
'C': ['a', 'b', 'c', 'd', 'e']})
print("置換前 DataFrameの0を5に置換する。")
display(df)
#DataFrameの0を5に置換する。
df=df.replace(0, 5)
print("置換後")
display(df)

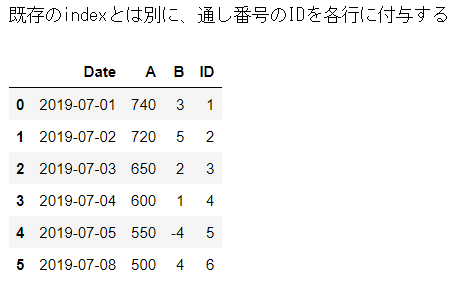
2-7 既存のindexとは別に、通し番号のIDを各行に付与する
import pandas as pd
import numpy as np
dat = [
['2019-07-01',740,3],
['2019-07-02',720,5],
['2019-07-03',650,2],
['2019-07-04',600,1],
['2019-07-05',550,-4],
['2019-07-08',500,4]
]
df = pd.DataFrame(dat,columns=["Date","A","B"])
df['ID'] = pd.RangeIndex(start=1, stop=len(df.index) + 1, step=1)
print("既存のindexとは別に、通し番号のIDを各行に付与する")
display(df)
2-8 scipyで極大値、極小値を探索する
2-9 所定の期間の営業日数を数える
def eigyobi_get(start_date,end_date):
# 日数を計算
delta = end_date - start_date
# 営業日数
business_days = 0
for i in range(delta.days + 1):
day = start_date + datetime.timedelta(days=i)
# 曜日を取得(月曜日は0,日曜日は6)
if calendar.weekday(day.year, day.month, day.day) < 5 and jpholiday.is_holiday(day)==False:
business_days += 1
return business_days-1
start_date = datetime.datetime.strptime("2023/1/15","%Y/%m/%d")
# 本日
end_date = datetime.datetime.today()
eigyobi_get(start_date,end_date)