はじめに
この人は何を言ってるんだ..?といったタイトルですが(笑)..自然言語処理の勉強も兼ねて、4連休を利用してつくってみました。近々、どこかしらにWebで見られるようにしようと思います。
コンセプトと完成イメージ
このネタを見つけた瞬間、現状(As is)→課題→あるべき姿(To be)を書き出していました。
さすがビジネスマン(笑)

どんな感じでつくろうかなと考えて思いついたのが以下の様な仕組みです。↓
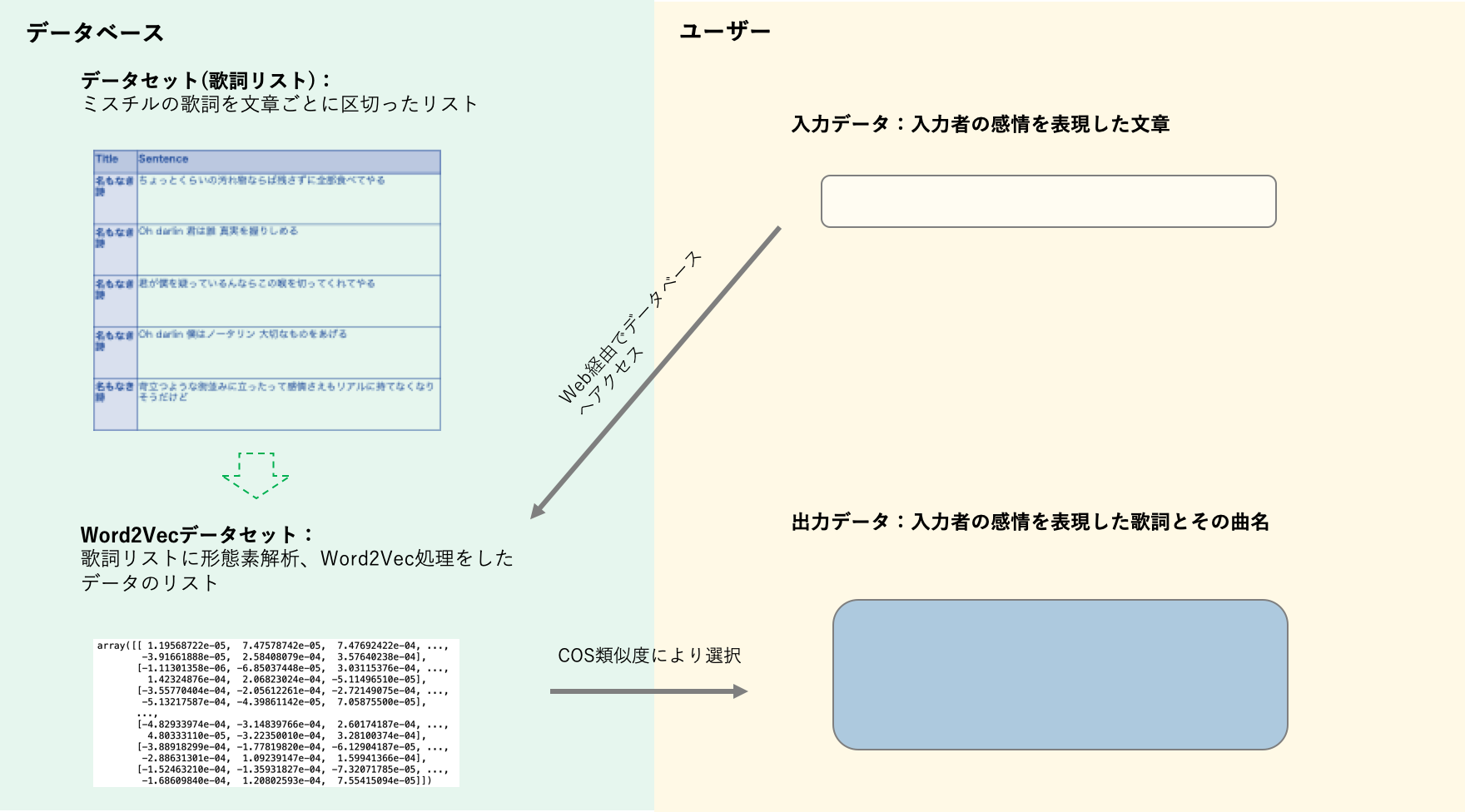
内部でミスチル歌詞データセットの作成およびWord2Vec化。自分の感情も同様にWord2Vec処理し、cos類似度にて似ている歌詞を引っ張ってきます。
PoCできた!
上記の全体像が実現できそうかさくっとトライしました。
結果...**「寝れなくてしんどいなぁ」**という自分の感情に対して 「社会人になって 重荷を背負って 思い知らされてらぁ -光の射す方へ」 が一番目に返ってきました。え...恐いぐらい深読みしてくる...笑

使っているもの
形態素解析:janome.tokenizer
Word2Vec:gensim.modelsのword2vec
from janome.tokenizer import Tokenizer
from gensim.models import word2vec
形態素解析で歌詞を細切れにし、その一言ごとにWord2Vecしています。
最終的にベクトルの平均を取得する事で、歌詞1セットのWord2Vecができあがるという魂胆です。
 ↓形態素解析をした結果
↓形態素解析をした結果

文章をWord2Vecする部分
# skip-gram Mr.Childrenの歌詞(sentences)で、w2vのモデルをつくる。
skipgram_model = word2vec.Word2Vec(sentences,
sg=1,
size=250,
min_count=2,
window=10, seed=1234)
# 形態素解析をした1単語ごとにWord2Vecを行い、最後に平均をとる関数=>歌詞の文脈を反映したWord2Vecができる?
def avg_document_vector(data, num_features):
document_vec = np.zeros((len(data), num_features))
for i, doc_word_list in enumerate(data):
feature_vec = np.zeros((num_features,), dtype="float32")
for word in doc_word_list:
try:
feature_vec = np.add(
feature_vec, skipgram_model.wv.__getitem__(word))
except:
pass
feature_vec = np.divide(feature_vec, len(doc_word_list))
document_vec[i] = feature_vec
return document_vec
おわりに
言葉をベクトルに変換して、一致度を見るというのが面白いなぁと思いました。
BERTとかも勉強してみたいなぁ〜と。
このお遊びをサービスにしていくためには曲数の拡張が急務です。(2020/7/29現在:5曲..笑)
コツコツと曲を貯めていきます。
にしても、こういったお遊びが4連休のスキマ時間でできるようになってきたのが、スキルが付いてきている様で嬉しいですね!!