最近、参考記事が話題になっていた。
話には聞いていたが、それぞれ中身がそうなんだということで少し遊んでみた。
4つの記事ともそれぞれ魅力的で少し眺めて何か出てくるようなら合わせて記事にしようかとも思った。
特に、参考③は任意関数を一層のニューラルネットワークで表現(近似関数)可能ということで、すごい話(深層がと言っていたのが層ではなく。。。)なので絡めたいなと思ったが、ちょっとむりげー。
また、参考④は中間層の綺麗な絵が得られて任意関数の表現やだましテクニックの解析に役立ちそう。。だが、。。
せめてだましのテクニックを利用して作成した図柄のどこを見てだましたのかとか面白いと思ったが、そこだけでも長くなりすぎたので、今回はAdversarialAttackのみについて遊んだことをまとめておこうと思う。その範囲でも理解できてないことがかなり膨大である。
ということで、今日のところは断念して、ほぼ参考①の範囲で書くことにする、。。。
【参考】
・①ディープラーニングを騙す
・②adityac94/Grad_CAM_plus_plus
・③ニューラルネットワークが任意の関数を表現できることの視覚的証明
・④An exploration of convnet filters with Keras
・⑤はじめてのAdversarial Example
関係なさそうであるがなんとなく関係ありそうな絵が参考②にあるので貼っておく。
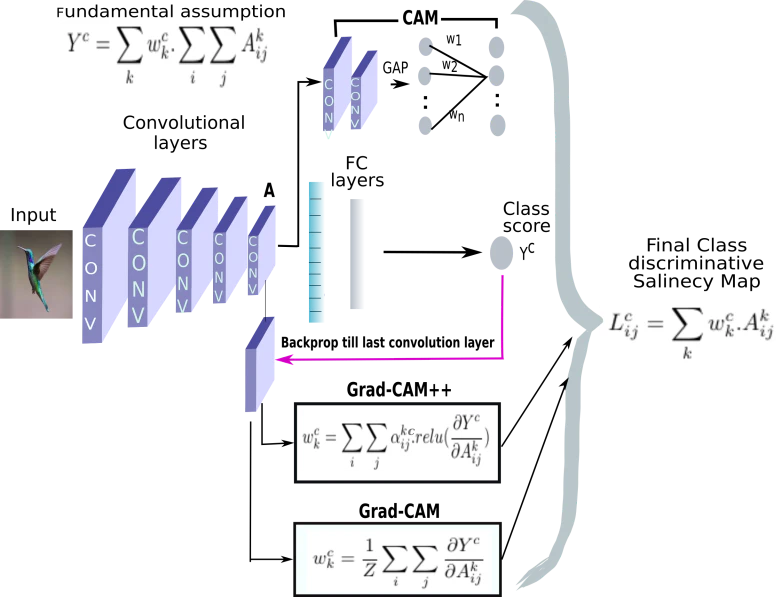
直感では、だましのテクニックの多くは、上の図の最後の式の$A_{ij}^k$及び/又はその係数$w_k^C$を変えて、$Y_k^C$から異なる$Y_k^{C'}$を導くように誘導しているのだと思う。
ちなみに、参考②はこの$w_k^C$を求めて$L_{ij}^c$を求めヒートマップを作成し、元画像に重畳して描画する手法です。
今回は触れません。
やったこと
・Fast Gradient Sign Methodを動かしてみる
・Attack画像で再学習し、さらにGaussian Noiseを乗っける
・Carlini-Wagner L2 attackを動かしてGaussian Noiseの効果を見る
・Carlini-Wagner L2 attackをAttack画像で再学習して効果を見る
・Fast Gradient Sign Methodを動かす
理論は、参考⑤と以下の参考⑥を参考にします。

まず上記の画像は、Box-constraind L-BFGSという手法で誤選択を誘導しています。参考⑤によれば、
「実際には論文ではBox-constraind L-BFGSという手法を使っていて、下記の条件下で問題を解いています。
Minimize\ c∥x−x'∥^2_2 +Loss(x ~ ,l)\\subject\ to\ x' ∈[0,1]_n
」
ということで、小さな摂動$x-x'$を付加することにより、簡単に誤選択させられるという手法です。
【元論文】
・Intriguing properties of neural networks@Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, Rob Fergus
(Submitted on 21 Dec 2013 (v1), last revised 19 Feb 2014 (this version, v4))
ちなみに元論文では以下の説明(上とノーテーションが異なる)になっています。(これも要約です)
「$f:R_m\ →\ ${ $1...k$ }として$f(x)=l$、...Box-constrained L-BFGSを使って、以下を$c>0$で近似的に最小化する...
Minimize\ c|r| +loss_f(x + r ,l)\\subject\ to\ x+r ∈[0,1]_m
このペナルティ関数法は、凸計画問題ならば正確な解を求められる。しかしneural networkでは、一般的には凸計画問題ではない。そこで近似的に解くこととする。」
【参考】凸計画問題については以下の参考を見てください(簡単に云えば準安定ではない下に凸な場合の極値問題です)
また、ペナルティ関数法は制約付き最適化の記述が分かりやすいと思います
・機械学習をやる上で知っておきたい連続最適化
・制約付き最適化
上記は、乱暴な言い方をすれば、制約付き最小化問題をラグランジュ未定係数法などで解くことにより、誤選択を誘導する手法でした。
そして、この原理を線形性が原因だと説明する手法であり、最適化などしなくても誤選択を誘導する手法が参考①でも扱っている、以下の手法です。
・Explaining and Harnessing Adversarial Examples
ここでは、以下の摂動を加えると誤選択が起きることを報告しています。
すなわち、$\theta$はDNNのパラメータ、入力xに対してクラスyが正解のとき、$x'=x+\eta$とすると誤選択が高頻度で発生するというものです。
η = ε\ sign (∇_xJ(θ, x, y))
この説明は、以下の参考が分かりやすいです。
【参考】
・⑥Adversarial examples@八谷大岳の覚え書きブログ
すなわち、完全引用に近いが、少し補足すると
「単純な1階層の線形モデルを考えた場合、入力画像にノイズを加えることは、以下のように、$\eta$を足していることに対応する。
x' = x+η = x+ ε\ sign (∇_xJ(θ, x, y))
ここで、weight $w$を左から演算し、activationすると、クラス$y$が得られることから以下を評価する。
w^Tx~=w^Tx+w^Tη
ここで、$\eta=sign(w)$となるので、ノイズ項は、$w$の絶対値和に対応し、max normの制約(最大値が以下)のもとでは最大の値をとることができる。例えば、$w=(0.1,-0.2,-0.5)^T$だとすると、$\eta=(1,-1,-1)$となり、$w^T\eta=0.1+0.2+0.5=0.8$となる。特に、$w$の次元が高い場合、$w^T\eta$は次元数に比例した大きな値をとり、インパクトのあるノイズを加えることが出来る。つまり、線形和でノイズを積算してしまっている。」
ここで解説終わりにしようと思いましたが、以下の参考にさらに示唆的な話があったので、参考だけ載せておきます。この話は奥が深い。。。
【参考】
・Adversarial Examples をやってみる。
コードは参考①のものが分かりやすいので使わせてもらって、以下のようになっています。
このコードでx_testデータを変更して$x_{adv}$を作成し、その予測結果をみます。
# FGSM.py
target = K.placeholder()
loss = K.sum(K.square(model.output - target))
grads = K.gradients(loss, model.input)[0]
fn = K.function([model.input, target], [K.sign(grads)])
grad_sign = []
for i in range(20):
part = np.arange(i * 500, (i + 1) * 500)
grad_sign.append(fn([x_test[part], y_test[part]])[0])
grad_sign = np.concatenate(grad_sign)
eps = 0.25
x_adv = np.clip(x_test + eps * grad_sign, 0, 1)
print(x_adv[0].shape)
x_test
[[ 972 0 3 1 0 1 3 0 0 0]
[ 0 1127 1 2 3 0 0 1 1 0]
[ 1 2 1012 6 0 0 1 7 3 0]
[ 0 0 2 1000 0 5 0 2 1 0]
[ 1 0 1 0 968 0 1 2 1 8]
[ 2 2 1 10 1 868 5 0 1 2]
[ 5 3 0 1 1 3 941 0 4 0]
[ 1 5 8 7 1 1 0 996 3 6]
[ 3 1 1 6 0 2 1 3 955 2]
[ 3 3 1 4 1 3 1 3 3 987]]

x_train+Noise
[[ 0 1 496 15 4 65 201 11 114 94]
[ 0 0 260 59 231 4 11 261 298 3]
[ 16 113 7 445 24 0 5 150 221 10]
[ 4 11 140 9 2 255 0 58 269 284]
[ 6 36 36 37 1 6 32 199 230 397]
[ 13 3 4 244 11 0 77 0 315 196]
[ 90 13 41 50 382 237 6 1 186 8]
[ 10 39 69 469 29 8 0 0 30 416]
[ 6 26 241 331 17 89 57 24 0 153]
[ 8 4 14 240 185 27 0 221 279 0]]
x_adv=x_test+Noise
[[ 1 0 491 7 3 63 197 9 109 100]
[ 4 0 235 54 256 3 8 244 331 0]
[ 23 136 10 490 15 0 12 168 169 9]
[ 0 6 164 7 1 282 4 61 223 262]
[ 5 19 30 31 0 5 28 187 228 449]
[ 17 6 1 282 4 0 36 1 328 217]
[121 9 37 37 400 216 8 0 127 3]
[ 3 39 91 436 20 13 0 0 41 385]
[ 7 12 244 288 19 129 45 40 0 190]
[ 7 7 8 226 202 51 1 228 279 0]]
もうボロボロというか、ほとんど他のものに誤選択している。

x_train+Noiseを再学習する。x_adv=x_test+Noiseは学習しない。
x_test
[[ 903 0 4 13 3 4 45 0 6 2]
[ 0 1051 6 2 61 0 4 0 11 0]
[ 2 19 882 75 31 0 4 7 6 6]
[ 0 0 9 979 3 4 1 4 5 5]
[ 1 1 0 0 978 1 0 0 1 0]
[ 2 4 1 51 2 796 13 1 20 2]
[ 5 1 0 1 21 4 924 0 2 0]
[ 2 13 60 11 37 4 0 857 12 32]
[ 3 17 21 113 12 14 20 9 756 9]
[ 3 2 4 14 236 43 0 5 17 685]]
再学習により、上記と比較すると、x_testはコンフュージョン・マトリクス見ると2,5,7,8,9あたりが落ちており、特に9が酷い。

x_train+Noise
[[1001 0 0 0 0 0 0 0 0 0]
[ 0 1127 0 0 0 0 0 0 0 0]
[ 0 0 991 0 0 0 0 0 0 0]
[ 0 0 0 1032 0 0 0 0 0 0]
[ 0 0 0 0 980 0 0 0 0 0]
[ 0 0 0 0 0 863 0 0 0 0]
[ 0 0 0 0 0 0 1014 0 0 0]
[ 0 0 0 0 0 0 0 1070 0 0]
[ 0 0 0 0 0 0 0 0 944 0]
[ 0 0 0 0 0 0 0 0 0 978]]
x_adv = x_test + Noise(1st)
[[ 979 0 0 0 0 0 0 0 0 1]
[ 0 1133 1 1 0 0 0 0 0 0]
[ 0 1 1030 1 0 0 0 0 0 0]
[ 0 0 0 1010 0 0 0 0 0 0]
[ 0 1 0 0 981 0 0 0 0 0]
[ 0 0 1 0 0 891 0 0 0 0]
[ 0 0 0 0 1 1 956 0 0 0]
[ 0 0 1 2 1 1 0 1023 0 0]
[ 0 0 2 2 0 0 1 0 969 0]
[ 1 0 1 2 3 1 1 0 1 999]]
x_trainは学習しているので、100%正解は当たり前だが、x_advもかなり精度があがっており、一度目のノイズは学習できている。

x_adv_adv = x_adv + Noise(2nd)
[[ 55 51 109 90 100 89 113 105 140 128]
[ 27 136 116 91 124 104 124 113 190 110]
[ 20 73 173 63 96 102 115 98 162 130]
[ 19 51 95 150 87 106 94 107 179 122]
[ 19 46 108 74 157 111 93 105 164 105]
[ 15 36 87 71 90 174 91 78 153 97]
[ 15 50 102 62 98 89 220 95 119 108]
[ 15 56 94 77 113 113 43 241 146 130]
[ 16 60 102 71 86 95 114 92 221 117]
[ 21 53 126 76 102 99 86 109 154 183]]
そして、この学習で同様なノイズは学習してほしいところだが、上記のとおり一部正解を出すまでに改善しているが、まだまだ平均より少し高い程度である。

しかし、この手法のポイントはノイズということで、入力画像にGaussianNoiseを乗っけてみた。
x_test
[[ 969 0 2 0 0 0 6 1 2 0]
[ 0 1131 2 1 0 0 1 0 0 0]
[ 9 15 960 6 8 0 4 24 5 1]
[ 2 6 4 956 0 18 1 13 2 8]
[ 1 6 1 0 939 0 6 3 1 25]
[ 4 4 0 1 0 868 4 3 2 6]
[ 8 4 2 0 4 5 934 0 1 0]
[ 0 19 15 1 0 1 0 969 1 22]
[ 11 9 7 7 10 12 5 8 873 32]
[ 8 11 0 4 6 4 0 14 5 957]]
コンフュージョンマトリクスは少し誤選択が多くなっている。すべての画像がノイズ乗っているのでこういうものかも知れない。

x_train+Noise
[[662 4 39 31 4 95 112 18 22 14]
[ 0 891 57 8 8 9 8 94 42 10]
[ 67 127 297 105 69 2 30 94 159 41]
[ 32 41 76 293 4 328 5 32 104 117]
[ 9 54 12 0 154 3 27 28 4 689]
[ 37 58 6 200 31 130 98 20 128 155]
[106 77 22 3 55 113 586 10 23 19]
[ 12 52 24 10 30 14 0 369 2 557]
[ 24 134 123 90 33 132 49 17 170 172]
[ 17 24 4 11 237 17 3 281 14 370]]
x_adv=x_test+Noise
[[606 3 44 30 5 90 155 18 11 18]
[ 0 938 51 6 2 11 13 64 47 3]
[ 64 137 333 116 57 7 48 100 126 44]
[ 21 30 65 286 5 384 8 40 88 83]
[ 4 30 14 0 99 1 32 32 7 763]
[ 48 42 2 191 27 179 75 28 164 136]
[122 35 21 1 89 101 535 11 25 18]
[ 12 60 50 11 17 6 0 364 5 503]
[ 36 68 130 89 32 152 57 39 175 196]
[ 15 22 8 11 269 30 2 246 15 391]]
ここが大改善して、誤選択が大幅に減少。もう少しで耐タンパ性ありと言えるレベルのものもあるが、種類によっては酷い。これは、単に入力時にGaussianNoiseをのせただけである。

再学習後
x_test
[[880 0 13 3 0 26 53 1 4 0]
[ 0 794 295 5 0 14 5 3 19 0]
[ 8 1 958 12 17 4 8 14 10 0]
[ 7 0 83 780 0 117 1 12 10 0]
[ 1 0 21 0 896 15 17 5 11 16]
[ 7 1 29 80 4 685 26 5 53 2]
[ 7 1 8 0 11 19 910 0 2 0]
[ 2 6 96 2 2 5 1 903 3 8]
[ 1 0 95 53 2 51 15 13 741 3]
[ 6 1 18 11 204 42 8 156 93 470]]
カテゴリ9が酷いのと、全体に精度が落ちている。

x_train=x_train+Noise
[[ 998 0 0 0 1 0 0 0 1 1]
[ 0 1120 0 4 0 0 0 2 0 1]
[ 1 1 973 2 1 3 4 2 0 4]
[ 1 2 3 1008 2 0 1 6 1 8]
[ 1 0 0 0 975 1 1 1 1 0]
[ 0 0 0 0 0 861 0 0 1 1]
[ 1 0 1 1 0 0 1010 0 1 0]
[ 0 2 0 1 1 0 0 1060 1 5]
[ 0 1 1 3 2 3 2 1 928 3]
[ 1 0 0 4 0 4 1 1 3 964]]
x_adv=x_test+Noise(1st)
[[ 977 2 0 0 0 0 0 0 0 1]
[ 0 1133 1 1 0 0 0 0 0 0]
[ 2 0 1017 0 2 2 0 0 1 8]
[ 0 0 0 998 0 0 1 1 0 10]
[ 0 0 0 0 980 0 1 0 1 0]
[ 0 0 1 0 0 890 0 0 0 1]
[ 0 0 0 0 0 2 955 0 0 1]
[ 0 5 1 1 0 0 1 1013 7 0]
[ 2 1 0 1 1 2 3 4 952 8]
[ 3 0 0 1 0 4 1 1 1 998]]
学習しただけあって、x_advもかなり精度が上がっている。

x_adv_adv=x_adv+Noise(2nd)
[[759 49 2 40 8 36 35 12 17 22]
[ 1 969 4 19 3 26 4 26 62 21]
[ 50 188 397 80 41 26 54 35 94 67]
[ 25 102 7 672 20 24 25 18 70 47]
[ 19 121 2 29 578 15 34 71 46 67]
[ 26 144 2 77 33 403 41 39 73 54]
[ 34 103 7 28 36 17 645 19 38 31]
[ 20 114 7 32 79 12 18 671 34 41]
[ 19 138 8 69 25 29 33 28 579 46]
[ 14 129 4 46 43 7 21 27 28 690]]
この方法だと、2や5あたりは誤選択が多いが、アタックをかなり回避して、これは1への誤選択が目立つが効果はあると言える。

x_trainの学習済weightを使って学習開始
ほぼ同じで改善無し。。ちゃんと元々のx_trainで学習しないとだめなようだ
※今回はこれ以上の追求はパスします
x_test
[[ 968 0 1 0 0 0 8 1 2 0]
[ 0 1128 2 1 0 0 3 1 0 0]
[ 12 34 925 6 13 0 6 26 9 1]
[ 4 7 3 936 0 30 2 18 4 6]
[ 1 8 0 0 938 0 7 2 1 25]
[ 4 4 0 1 2 851 16 4 2 8]
[ 6 4 0 0 3 3 942 0 0 0]
[ 0 27 12 1 1 1 0 967 1 18]
[ 12 13 3 9 12 11 18 12 853 31]
[ 6 13 0 4 8 2 0 11 1 964]]
x_train+Noise
[[ 693 4 17 19 9 80 125 24 14 16]
[ 0 1023 30 1 7 12 15 20 9 10]
[ 48 176 310 85 83 0 59 86 100 44]
[ 29 59 65 334 4 309 7 47 73 105]
[ 9 57 6 0 296 2 40 28 3 539]
[ 30 77 4 142 35 164 134 28 99 150]
[ 82 88 10 1 51 67 670 8 19 18]
[ 9 79 17 5 48 6 1 505 1 399]
[ 25 151 71 89 41 84 93 12 185 193]
[ 17 30 1 14 257 8 3 273 8 367]]
x_adv=x_test+Noise
[[ 634 4 18 26 9 75 157 26 8 23]
[ 0 1039 29 3 3 8 16 13 22 2]
[ 56 199 324 94 64 4 64 91 96 40]
[ 21 51 55 320 9 363 14 48 51 78]
[ 4 36 7 0 274 2 39 23 7 590]
[ 39 43 2 150 39 201 124 39 113 142]
[ 100 41 11 1 91 62 615 8 19 10]
[ 10 87 39 4 26 5 0 490 6 361]
[ 40 89 74 83 48 80 111 33 182 234]
[ 14 27 3 12 297 22 3 240 6 385]]
再学習
x_test
[[ 937 0 6 3 0 8 13 1 12 0]
[ 0 1092 28 2 0 0 3 1 9 0]
[ 13 16 920 1 15 2 5 12 48 0]
[ 6 9 71 763 1 75 2 10 72 1]
[ 3 14 11 0 863 4 9 11 28 39]
[ 11 8 14 98 2 628 14 4 111 2]
[ 33 6 9 0 19 11 854 2 24 0]
[ 3 30 54 1 4 3 0 882 23 28]
[ 3 5 28 8 5 19 3 8 891 4]
[ 8 11 11 4 117 16 4 88 125 625]]
x_train=x_train+Noise(1st)学習後
[[ 988 11 0 0 1 0 0 0 0 1]
[ 0 1123 0 1 1 0 1 1 0 0]
[ 3 9 950 3 4 5 6 8 1 2]
[ 1 15 4 991 2 1 1 10 0 7]
[ 2 8 0 0 969 0 1 0 0 0]
[ 0 2 0 0 0 859 0 0 1 1]
[ 1 0 0 0 0 0 1012 0 1 0]
[ 0 5 0 1 0 0 2 1060 0 2]
[ 2 19 1 4 5 7 11 11 882 2]
[ 1 9 0 8 0 2 6 1 0 951]]
x_adv=x_test+Noise(1st)
[[ 970 9 0 0 0 0 0 0 0 1]
[ 0 1134 1 0 0 0 0 0 0 0]
[ 2 9 999 0 3 6 4 2 2 5]
[ 1 12 0 982 1 1 3 3 0 7]
[ 0 5 0 0 976 0 1 0 0 0]
[ 0 3 0 0 0 887 1 0 0 1]
[ 1 2 0 0 0 0 954 0 0 1]
[ 0 14 2 0 0 0 1 1010 1 0]
[ 0 15 0 3 5 3 7 15 912 14]
[ 2 5 2 5 0 3 5 2 0 985]]
x_adv_adv=x_adv+Noise(2nd)
[[510 266 0 20 7 49 65 56 0 7]
[ 0 985 0 1 4 28 13 94 2 8]
[ 16 615 117 37 19 34 94 80 3 17]
[ 9 450 1 352 9 45 69 58 1 16]
[ 7 402 0 12 339 21 47 140 0 14]
[ 7 487 1 23 15 206 56 86 2 9]
[ 12 342 2 10 17 12 521 34 1 7]
[ 5 373 0 16 40 7 22 556 0 9]
[ 4 517 0 42 23 51 109 106 106 16]
[ 12 424 0 18 32 21 56 95 0 351]]
・Carlini-Wagner L2 attackを動かしてGaussian Noiseの効果を見る
これも参考①のコード+とりあえず動かしました。
原理は以下のとおりです。
【参考】
・Towards Evaluating the Robustness of Neural Networks
この論文でまず、上記のBox-constraind L-BFGSをおさらいしています。二番目に上記のFGSMのアルゴリズムを引用。そして、JSMA(Jacobian-based Saliency Map Attack)を振り返っています。そして、彼らの提案するアルゴリズムは以下のようなものです。
Minimize\ ||\delta||_p +cf(x + \delta)\\s.t.\ \ x+\delta ∈[0,1]_n
ここで$||\delta||_p$はp次の正則化項であり、$\delta = \frac{1}{2}(tanh(w_i)+1)-x_i$を導入し、この$w_i$のフィッティング問題に置き換えています。すなわち、アタック画像が$\frac{1}{2}(tanh(w_i)+1)$、元画像が$x_i$です。したがって、彼らはこのpの次数に応じて3つのアタック画像の生成を実施して、それぞれ$L_0,L_2,L_∞$と呼んでいます。
論文では、$L_2$においては$f(x)$として以下のような関数を採用している。
f(x)= max(max\{Z(x')_i:i≠t)\}-Z(x')_t,-\kappa)
$\kappa$は解の信頼性を調整する因子とのことだが、論文では$\kappa=0$としている。 また、$Z(x)$はsoftmax関数を適用する前のネットワークの出力です。
ということで、原理はなんとなくわかりますが、これをコードに落とせていないので、参考①のコードと以下の参考サイトのコードを利用させていただきました。
ただし、このライセンスが著作権ありで、改版も制約が書いてあるので、掲載は控えリンクすることとしました。
動かすには、参考サイトから必要な資材をダウンロードして置いておくことが必要でした。
【参考】
・carlini/nn_robust_attacks
x_testについては、
[[ 8 0 0 0 0 0 0 0 0 0]
[ 0 14 0 0 0 0 0 0 0 0]
[ 0 0 7 0 0 0 0 1 0 0]
[ 0 0 0 11 0 0 0 0 0 0]
[ 0 0 0 0 14 0 0 0 0 0]
[ 0 0 0 0 0 6 1 0 0 0]
[ 0 0 0 0 0 0 10 0 0 0]
[ 0 0 0 0 0 0 0 14 0 1]
[ 0 0 0 0 0 0 0 0 2 0]
[ 0 0 0 0 1 0 0 1 0 9]]

そして、アタック画像に対しては、以下のとおりとなりました。
コンフュージョンマトリクスからはわかりにくいですが、下の絵から見事に、そのターゲットに誤選択を誘導しているのが分かります。
[[0 2 1 1 0 1 1 0 2 0]
[0 1 3 3 0 4 1 1 1 0]
[1 2 1 1 0 0 1 0 1 1]
[2 1 0 0 3 1 2 1 0 1]
[0 1 3 0 4 1 2 3 0 0]
[1 0 0 0 0 0 2 1 1 2]
[2 0 1 2 1 1 1 1 0 1]
[2 1 1 1 0 1 1 2 3 3]
[0 0 0 1 0 0 0 0 1 0]
[2 1 0 2 1 1 0 1 2 1]]

最後にアタック画像を再学習した結果は以下のとおり、ほとんど1、6、そして7になりました。うーんという感じです。
[[0 6 0 0 0 0 0 2 0 0]
[0 8 0 0 0 0 1 5 0 0]
[0 5 0 0 1 0 0 2 0 0]
[0 5 0 0 0 0 1 5 0 0]
[0 7 0 0 0 0 0 7 0 0]
[0 3 0 0 0 0 0 4 0 0]
[0 8 0 0 0 0 1 1 0 0]
[0 8 0 0 0 0 2 5 0 0]
[0 1 0 0 0 0 1 0 0 0]
[0 8 0 0 0 0 1 2 0 0]]

まとめ
・AdversarialAttackで遊んでみた
・アタック画像による再学習は、FGSMについては回避効果があったが、さらに重畳してアタックするとほとんど効果が無かった
・GasussianNoiseをのせることにより、FGSMについては一定の回避効果があったが、十分な回避効果とは言えない
・L2アタックについては、計算速度が遅く十分なアタックデータを用意できないかったが、アタック画像による学習が結果に影響があることは分かった
・その他のアタック方法や回避方法も提案されているのが分かったので、種類ごとにアタックと回避効果を分類したいと思う
おまけ
# ディープラーニングを騙す
# https://qiita.com/ryuoujisinta/items/2c566ebea4bc43a62632
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
# import tensorflow.keras.backend as K
from keras import backend as K
import keras
from keras.datasets import mnist
from keras.callbacks import ReduceLROnPlateau, EarlyStopping, CSVLogger
from keras.callbacks import ModelCheckpoint
from keras.layers import *
from keras.models import Model, Sequential
from keras.layers import Input, Dense
def plot_gallery(images, titles, h, w, n_row=9, n_col=9):
"""Helper function to plot a gallery of portraits"""
plt.figure(figsize=(0.9 * n_col, 1.2 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(81): #n_row*n_col
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=10)
plt.xticks(())
plt.yticks(())
# plot the result of the prediction on a portion of the test set
def title(y_pred, y_test, target_names, i):
pred_name = y_pred[i] #target_names[y_pred[i]].rsplit(' ', 1)[-1]
true_name = target_names[i] #.rsplit(' ', 1)[-1]
print(pred_name, true_name)
return 'predicted: {}\ntrue: {}'.format(pred_name, true_name)
# データをロード
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 前処理
x_train = np.expand_dims(x_train, 3)
x_train = x_train.astype("float32") / 255
x_test = np.expand_dims(x_test, 3)
x_test = x_test.astype("float32") / 255
y_train = keras.utils.to_categorical(y_train)
y_test = keras.utils.to_categorical(y_test)
# def model_mnist(input_image=Input(shape=(None, None, 1))):
model = Sequential()
model.add(InputLayer(input_shape=(28,28,1)))
model.add(GaussianNoise(0.8))
model.add(Conv2D(32, (2, 2), activation="relu", padding="same")) #,input_shape=(28,28,1)))
model.add(Conv2D(128, (2, 2), activation="relu", padding="same")) #"valid"))
model.add(Conv2D(128, (1, 1), activation="relu", padding="same")) #"valid"))
model.add(Flatten())
model.add(Dense(10, activation="softmax"))
model.summary()
model.compile(loss="categorical_crossentropy",
optimizer="adam",
metrics=["acc"])
# model.load_weights('mnist_cnn_cifar.hdf5')
# 訓練
checkpointer = ModelCheckpoint(filepath='./cifar100/mnist_cnn_G08.hdf5',
monitor='val_acc', verbose=1, save_best_only=True,save_weights_only=True)
early_stopping = EarlyStopping(monitor='val_acc', patience=5, mode='max',
verbose=1)
lr_reduction = ReduceLROnPlateau(monitor='val_acc', patience=5,
factor=0.5, min_lr=0.00001, verbose=1)
csv_logger = CSVLogger('./cifar100/history_mnist_G08.log', separator=',', append=True)
callbacks = [early_stopping, lr_reduction, csv_logger,checkpointer]
# Learning ; Original x_train, y_train
history = model.fit(x_train, y_train,
batch_size=64,
epochs=10,
callbacks=callbacks,
validation_split=0.2,
shuffle=True)
model.save_weights('./cifar100/mnist_cnn_G08.hdf5', True)
# FGSM.py
target = K.placeholder()
loss = K.sum(K.square(model.output - target))
grads = K.gradients(loss, model.input)[0]
fn = K.function([model.input, target], [K.sign(grads)])
grad_sign = []
for i in range(20):
part = np.arange(i * 500, (i + 1) * 500)
grad_sign.append(fn([x_test[part], y_test[part]])[0])
grad_sign = np.concatenate(grad_sign)
eps = 0.25
x_adv = np.clip(x_test + eps * grad_sign, 0, 1)
print(x_adv[0].shape)
import numpy as np
from sklearn.metrics import confusion_matrix
# check x_test
predict_classes = model.predict_classes(x_test[:10000,], batch_size=32)
true_classes = np.argmax(y_test[:10000],1)
print(confusion_matrix(true_classes, predict_classes))
prediction_titles = [title(predict_classes, y_test, true_classes, i) for i in range(81)]
plot_gallery(x_test[:81], prediction_titles, 28, 28)
plt.savefig('./cifar100/mnist_x_test_G08.jpg')
plt.pause(1)
plt.close()
# check x_train[:10000] += Noise
predict_classes = model.predict_classes(x_train[:10000,], batch_size=32)
true_classes = np.argmax(y_train[:10000],1)
print(confusion_matrix(true_classes, predict_classes))
prediction_titles = [title(predict_classes, y_train, true_classes, i) for i in range(81)]
plot_gallery(x_train[:81], prediction_titles, 28, 28)
plt.savefig('./cifar100/mnist_x_train_G08.jpg')
plt.pause(1)
plt.close()
# check x_adv[:10000] += Noise
predict_classes = model.predict_classes(x_adv[:10000,], batch_size=32)
true_classes = np.argmax(y_test[:10000],1)
print(confusion_matrix(true_classes, predict_classes))
prediction_titles = [title(predict_classes, y_test, true_classes, i) for i in range(81)]
plot_gallery(x_adv[:81], prediction_titles, 28, 28)
plt.savefig('./cifar100/mnist_x_adv_G08.jpg')
plt.pause(1)
plt.close()