前回は、optimizerを可視化して、その性質の一端を見た。
今回は、さらに深堀して性質からどのように利用できるかを考える。
前回の追記にするか迷ったが、角度を変えて記述することにより、より理解が深まると考えて、続編というよりは別偏とすることにしました。
とりあえず、内容と直接関係ないが、以下を参考として挙げておく
【参考】
①Optimization Algorithms in Deep Learning-AdaGrad, RMSProp, Gradient Descent with Momentum & Adam Optimizer demystified;AdaGrad、RMSProp、勢いのある最急降下法とAdamOptimizerの謎を解き明かす
やったこと
・VGD、momentum、そしてgrad規格化という3つの性質
・momentumの変数beta1の役割
・grad規格化の変数beta2の役割
・adamでRMSpropとmomentumを再現する
・Cifar10のカテゴライズでoptimを試してみる
・VGD、momentum、そしてgrad規格化という3つの性質
数式で見ると以下のとおり
以下が勾配降下法VGDで単純に等高線に垂直に移動する。これが極小値を求めるための基本原理。
x = x - alpha * grad(x)
以下がVGDに運動量(履歴)概念を導入したVDGで、収束が早まると期待できる。
m = beta*v + (1-beta)*grad(x)
x = x - alpha * mc
以下は、VDGとは異なり、傾きの異方性を排除するため(傾きの大きい方ばかりに行かないよう)にgradで規格化するRMSpropの手法。
v = beta2*v + (1-beta2)*grad(x)**2
x = x - alpha * grad(x) / (eps + np.sqrt(v))
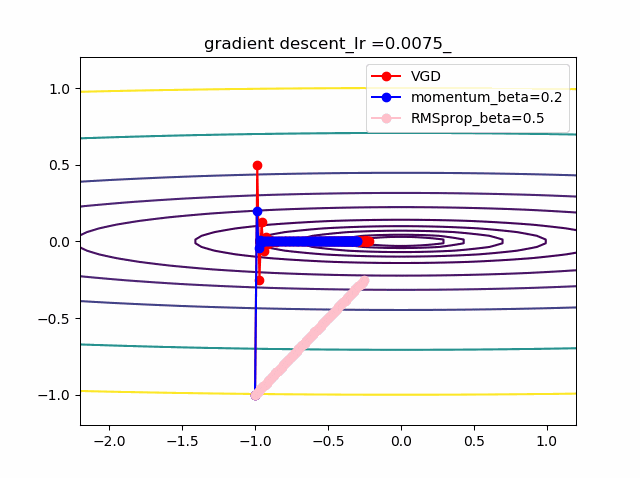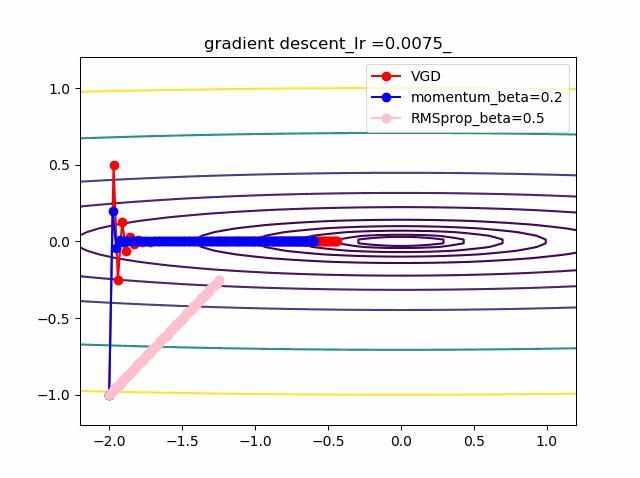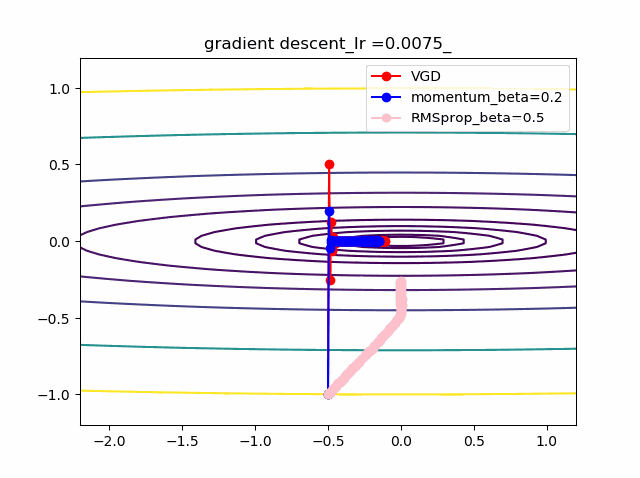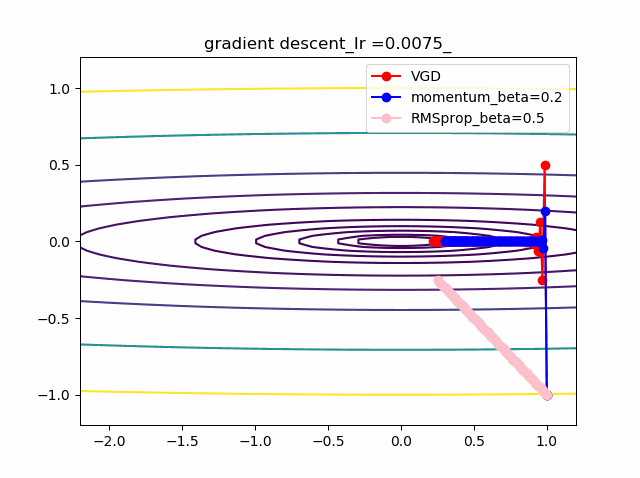
以下のコードでbeta1=0.2及びbeta2=0.5の場合の初期値の違いによる収束の様子を見ます。
p_list = {-2,-1,-0.5,1}
for p in p_list:
x0 = np.array([p,-1])
x = np.linspace(-2.2, 1.2, 100)
y = np.linspace(-1.2, 1.2, 100)
X, Y = np.meshgrid(x, y)
levels = [0.1,0.2,0.5,1,2,5,10,20,50,100]
Z = x**2 + 100*Y**2
beta1 =0.2
beta2 =0.5
al_list = {0.0075}
for al in al_list:
alpha = al
xs = gd2(x0, grad2, alpha, max_iter=100)
xsm = gd2_momentum(x0, grad2, alpha, beta=beta1, max_iter=100)
xsg = gd2_rmsprop(x0, grad2, alpha, beta2=beta2, max_iter=100)
c = plt.contour(X, Y, Z, levels)
plt.plot(xs[:, 0], xs[:, 1], 'o-', c='red', label ='VGD')
plt.plot(xsm[:, 0], xsm[:, 1], 'o-', c='blue', label = 'momentum_beta={}'.format(beta1))
plt.plot(xsg[:, 0], xsg[:, 1], 'o-', c='pink', label = 'RMSprop_beta={}'.format(beta2))
plt.title('gradient descent_Ir ={}_'.format(alpha))
plt.legend()
plt.savefig('fig_y=x^2+100y^2_Ir{}withVGD_mbeta1{}_gbeta2{}_{}.png'.format(alpha,beta1,beta2,p))
plt.pause(1)
plt.clf()
結果は以下のとおりです。
特徴は、一目瞭然ですが、
①momentumの効果は、振動の安定化に寄与しています。しかしより原点に近いということはありません。
②gradでの規格化;RMSpropは、いきなり45度の方向へ進んでいます。beta2=0.5だとX=0の切片まで(1,1)方向など等方的な方向へ直線的に移動しているのが分かります。
③VGDが最も原点(これが今の極小値)に一番近づいています
学習率を大きくする
VGDは発散しやすく、次にmomentumを導入したものという順に発散してしまいます。
最後に残るのが、RMSpropで以下のように大きな学習率でも収束して原点まで到達してくれました。しかし、よく見るとIr=0.05の時は原点近傍で振動しているのが分かります。
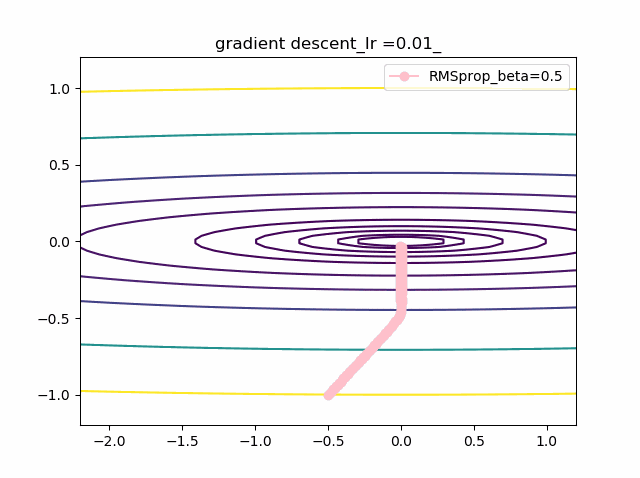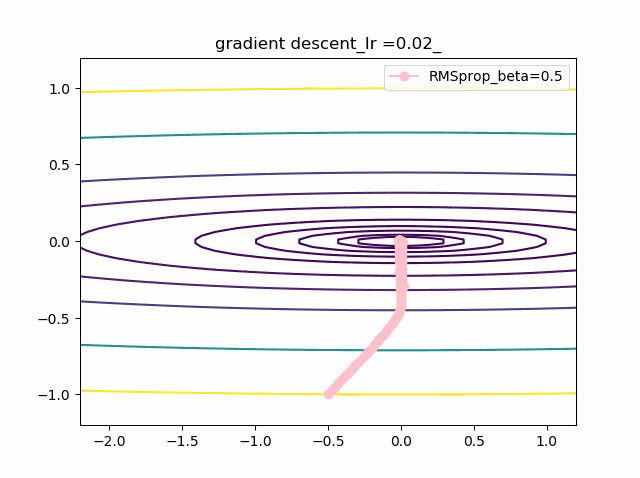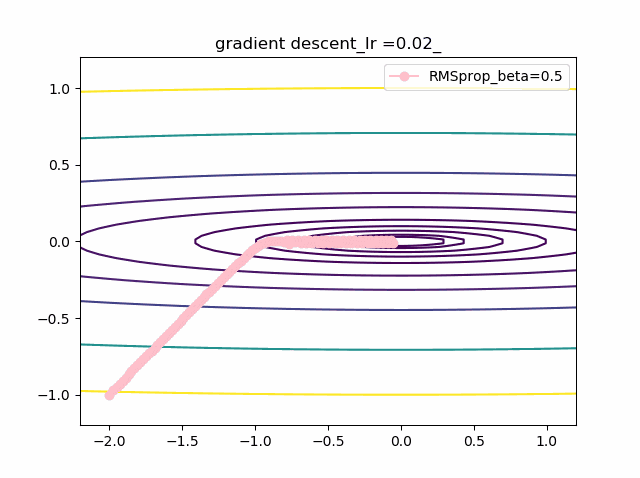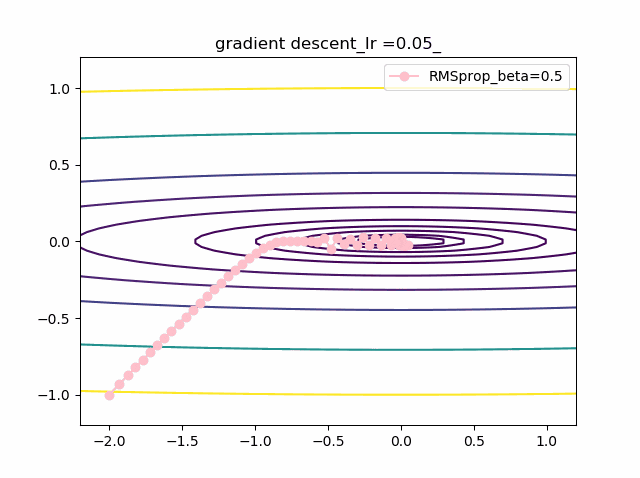
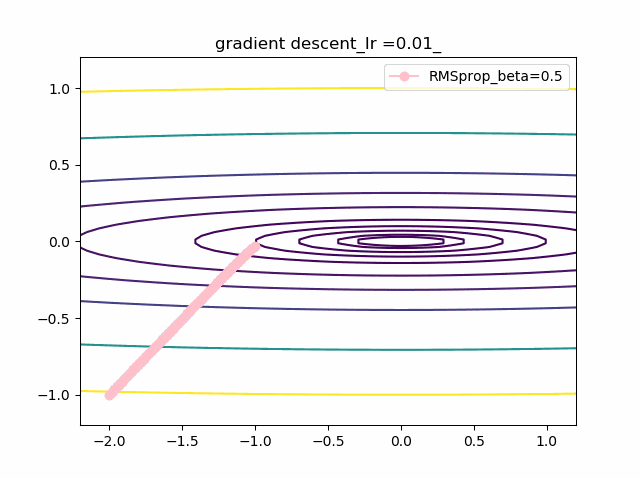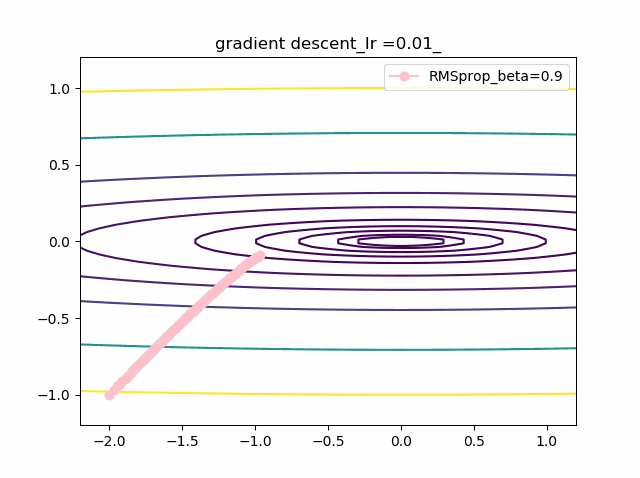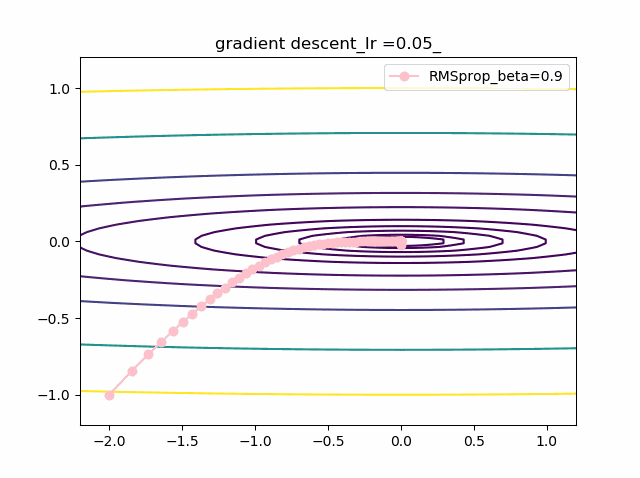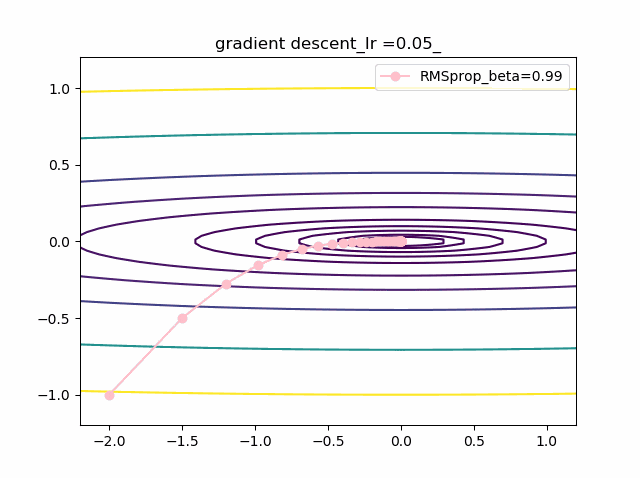
・grad規格化の変数beta2の役割
adamを見る前に、RMSpropのbeta2の役割を見てみましょう。
結果は以下のようになりました。
①beta2の効果は0.9, 0.99 と変えることにより、その場の傾きの寄与が小さくなって、それまでの傾きの履歴に依存して向きが段々原点の方向へ回り込むようになりました
②収束性能が上がって、beta2=0.99, Ir=0.05では数えられる程度のポイントで急速に解に近づいて収束しているのが分かります
③上記の学習率が大きいときに発生していた原点近傍も消えました。
・adamでRMSpropとmomentumを再現する
adamのコードは以下のとおり、RMSpropとmomentumを両者取り入れたものとなっています。
m = beta1*m + (1-beta1)*grad(x)
v = beta2*v + (1-beta2)*grad(x)**2
x = x - alpha * m / (eps + np.sqrt(v))
上記のコードでbeta1=0と置くと上のRMSpropと同じコードになります。
また、beta2=1, v =定数 が、momentumのコードになります。
ということで、adamの最適なパラメータを見てみます。
RMSpropと同じ結果から調査を始めます。
AdamとRMSpropを比較する
まず、beta1=0-0.9まで変化したときのAdamの振る舞いをRMSpropと比較します。
lrを0.005から0.01に増加すると、RMSpropはより急速に原点に収束しているのが分かります。そして、Adamはbeta1=0ではRMSpropと同じ振る舞いですが、beta1が大きくなると、蛇行して原点に接近するのが分かります。
この時点ではAdamの優位性(beta1の効果)が良い方向に寄与しているかどうか不明です。
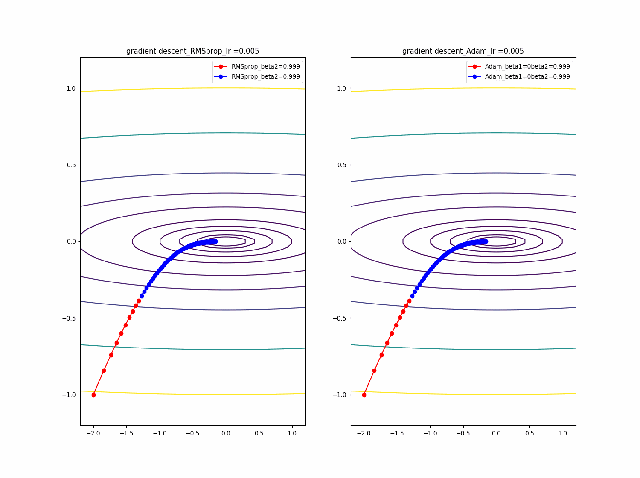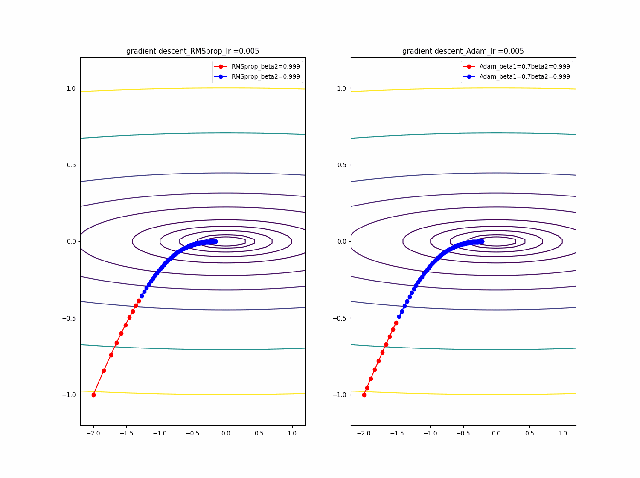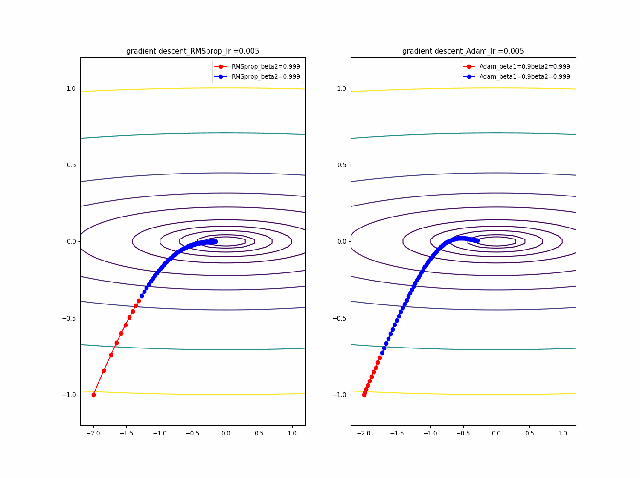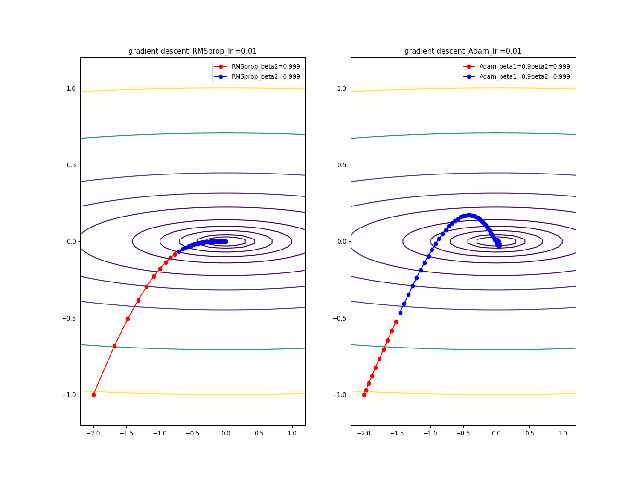
さらに、学習率を大きくする。
lr=0.05-0.1に増加して同じことをやってみます。
RMSpropはかなり遠い位置に飛ばされてしまいますが、二度目に戻ってきて収束しています。一方、Adamはそれほど飛ばされることもなく、ゆっくりですが、原点近傍を振動しつつ収束します。一応、Adamのbeta1の効果があると言えると思います。
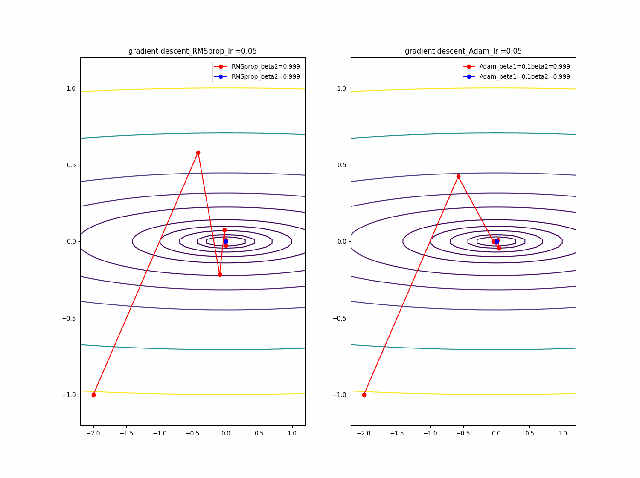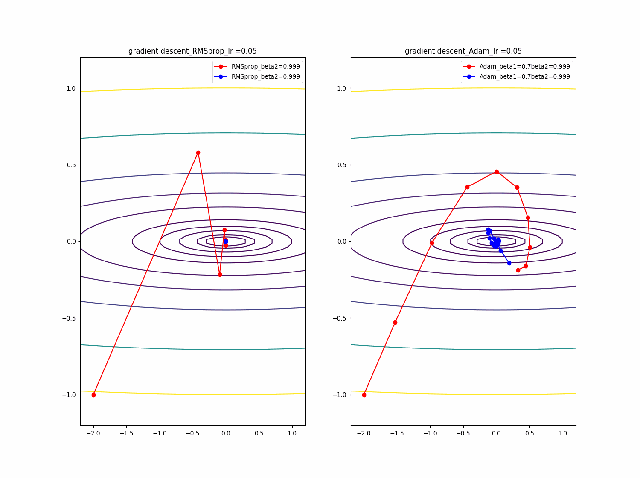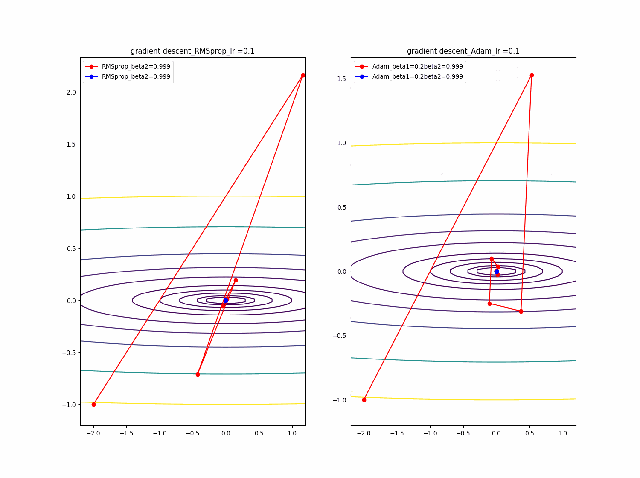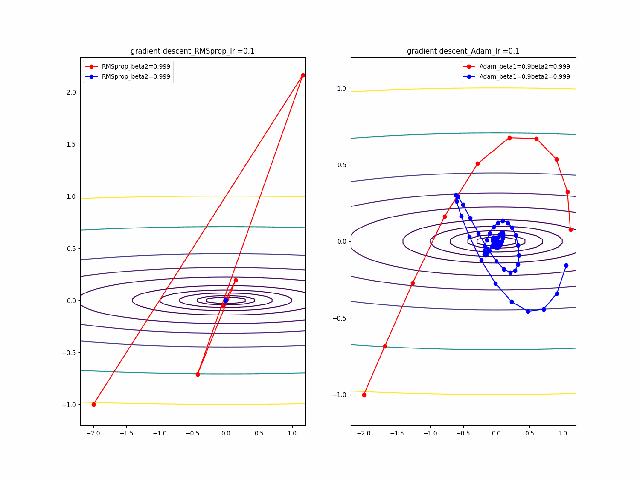
そして、さらに学習率の大きなところを見てみます。
RMSpropはさらに遠方に飛ばされますがそれでも戻ってきているようです。そしてAdamは学習率0.2では一定の割合で近いところで収束していますが、学習率が0.5で、特に最後のものは振動して収束していないように見えます。
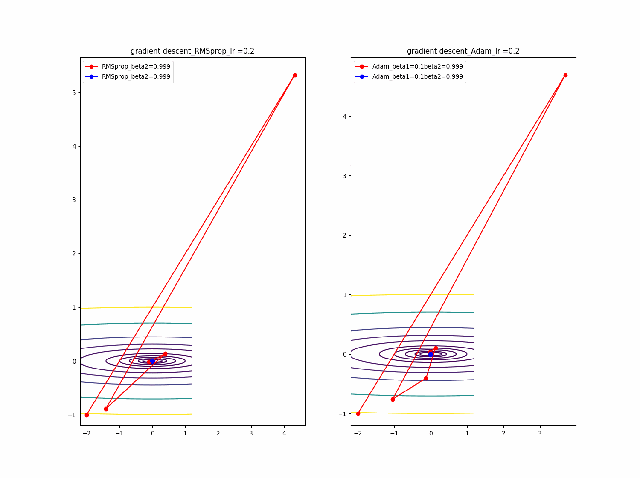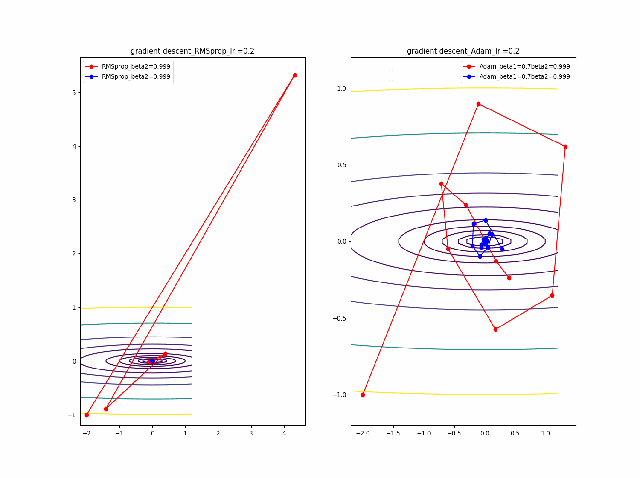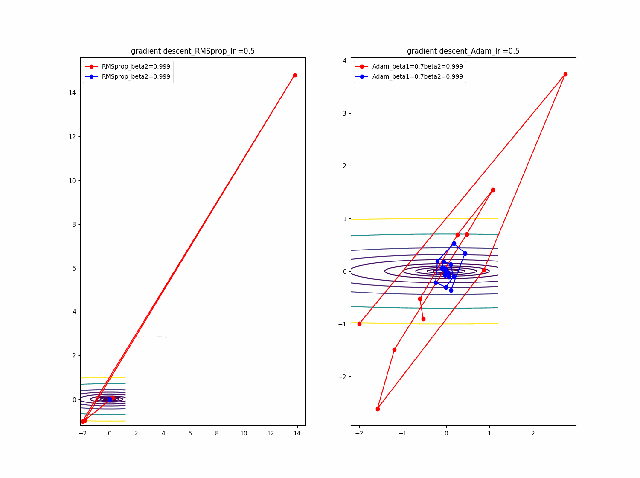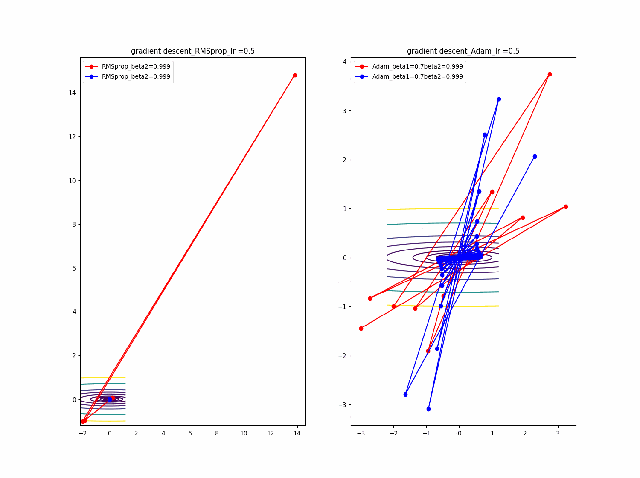
ここまでの解析は以下のコード、つまり自前のgradient descentのコードでやっています。
自前のgradient descentのコード
def gd2_rmsprop(x, grad, alpha, beta2=0.9, eps=1e-8, max_iter=10):
xs = np.zeros((1 + max_iter, x.shape[0]))
xs[0, :] = x
v = 0
for i in range(max_iter):
v = beta2*v + (1-beta2)*grad(x)**2
x = x - alpha * grad(x) / (eps + np.sqrt(v))
xs[i+1, :] = x
return xs
def gd2_adam(x, grad, alpha, beta1=0.9, beta2=0.999, eps=1e-8, max_iter=10):
xs = np.zeros((1 + max_iter, x.shape[0]))
xs[0, :] = x
m = 0
v = 0
for i in range(max_iter):
m = beta1*m + (1-beta1)*grad(x)
v = beta2*v + (1-beta2)*grad(x)**2
#mc = m/(1+beta1**(i+1))
#vc = v/(1+beta2**(i+1))
x = x - alpha * m / (eps + np.sqrt(v))
xs[i+1, :] = x
return xs
p = -2 #0.5
beta2_list = {0.999}
beta1 = 0.1 #0.2 #0.7 #0 #0.5 #0.9
fig = plt.figure(figsize=(15, 10))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
for beta2 in beta2_list:
al_list = {0.5}
x0 = np.array([p,-1])
x = np.linspace(-2.2, 1.2, 100)
y = np.linspace(-1.2, 1.2, 100)
X, Y = np.meshgrid(x, y)
levels = [0.1,0.2,0.5,1,2,5,10,20,50,100]
Z = x**2 + 100*Y**2
for al in al_list:
alpha = al #0.01
xsg = gd2_adam(x0, grad2, alpha, beta1 = beta1, beta2=beta2, max_iter=100)
xsr = gd2_rmsprop(x0, grad2, alpha, beta2=beta2, max_iter=100)
c1 = ax1.contour(X, Y, Z, levels)
ax2.plot(xsg[:10, 0], xsg[:10, 1], 'o-', c='red', label = 'Adam_beta1={}beta2={}'.format(beta1,beta2))
ax2.plot(xsg[10:, 0], xsg[10:, 1], 'o-', c='blue', label = 'Adam_beta1={}beta2={}'.format(beta1,beta2))
ax2.set_title('gradient descent_Adam_Ir ={}'.format(alpha))
c2 = ax2.contour(X, Y, Z, levels)
ax1.plot(xsr[:10, 0], xsr[:10, 1], 'o-', c='red', label = 'RMSprop_beta2={}'.format(beta2))
ax1.plot(xsr[10:, 0], xsr[10:, 1], 'o-', c='blue', label = 'RMSprop_beta2={}'.format(beta2))
ax1.set_title('gradient descent_RMSprop_Ir ={}'.format(alpha))
ax1.legend()
ax2.legend()
plt.savefig('fig_y=x^2+100y^2_Ir{}withadam_mbeta1_{}gbeta2{}_{}.png'.format(alpha,beta1,beta2,p))
plt.pause(1)
plt.clf()
・Cifar10のカテゴライズでoptimを試してみる
どうも上記の結果だとRMSpropの性能がいいように感じるが、普段の学習ではAdamの方がいいような気がしており、そのギャップを再度確認するために、いろいろなoptimizerで同じ条件で試してみる。ここでは、一応pytorch推奨のパラメータを利用するnetworkは自前のVGG16で10epochのみの学習で精度をみた。
結果は、それぞれ以下のとおりとなり、残念ながら差はあまり出なかったと言える。
optimizer = torch.optim.Adam(self.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
Epoch 0: 100%|██████████████████| 1563/1563 [01:07<00:00, 23.23it/s, loss=1.24, v_num=11, val_loss=1.43, val_acc=0.501]
Epoch 1: 100%|████████████████| 1563/1563 [01:07<00:00, 23.03it/s, loss=0.903, v_num=11, val_loss=0.994, val_acc=0.653]
Epoch 2: 100%|█████████████████| 1563/1563 [01:07<00:00, 23.04it/s, loss=0.74, v_num=11, val_loss=0.842, val_acc=0.709]
Epoch 3: 100%|████████████████| 1563/1563 [01:08<00:00, 22.89it/s, loss=0.662, v_num=11, val_loss=0.797, val_acc=0.731]
Epoch 4: 100%|████████████████| 1563/1563 [01:07<00:00, 23.31it/s, loss=0.554, v_num=11, val_loss=0.817, val_acc=0.735]
Epoch 5: 100%|████████████████| 1563/1563 [01:06<00:00, 23.35it/s, loss=0.469, v_num=11, val_loss=0.834, val_acc=0.742]
Epoch 6: 100%|████████████████| 1563/1563 [01:08<00:00, 22.91it/s, loss=0.405, v_num=11, val_loss=0.725, val_acc=0.786]
Epoch 7: 100%|████████████████| 1563/1563 [01:06<00:00, 23.38it/s, loss=0.291, v_num=11, val_loss=0.727, val_acc=0.794]
Epoch 8: 100%|████████████████| 1563/1563 [01:07<00:00, 23.26it/s, loss=0.244, v_num=11, val_loss=0.831, val_acc=0.779]
Epoch 9: 100%|█████████████████| 1563/1563 [01:07<00:00, 23.01it/s, loss=0.169, v_num=11, val_loss=0.918, val_acc=0.78]
Epoch 9: 100%|█████████████████| 1563/1563 [01:07<00:00, 23.01it/s, loss=0.169, v_num=11, val_loss=0.918, val_acc=0.78]
Files already downloaded and verified
Files already downloaded and verified
Testing: 100%|███████████████████████████████████████████████████████████████████████| 313/313 [00:05<00:00, 53.45it/s]
--------------------------------------------------------------------------------
DATALOADER:0 TEST RESULTS
{'val_acc': tensor(0.7801, device='cuda:0'),
'val_loss': tensor(0.7414, device='cuda:0')}
--------------------------------------------------------------------------------
optimizer = torch.optim.RMSprop(self.parameters(), lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)
Epoch 0: 100%|██████████████████| 1563/1563 [01:03<00:00, 24.68it/s, loss=1.72, v_num=12, val_loss=1.67, val_acc=0.358]
Epoch 1: 100%|██████████████████| 1563/1563 [01:03<00:00, 24.50it/s, loss=1.26, v_num=12, val_loss=1.54, val_acc=0.439]
Epoch 2: 100%|█████████████████| 1563/1563 [01:03<00:00, 24.71it/s, loss=0.946, v_num=12, val_loss=1.42, val_acc=0.534]
Epoch 3: 100%|███████████████████| 1563/1563 [01:03<00:00, 24.66it/s, loss=0.8, v_num=12, val_loss=1.33, val_acc=0.589]
Epoch 4: 100%|██████████████████| 1563/1563 [01:03<00:00, 24.66it/s, loss=0.669, v_num=12, val_loss=1.13, val_acc=0.66]
Epoch 5: 100%|████████████████| 1563/1563 [01:03<00:00, 24.51it/s, loss=0.554, v_num=12, val_loss=0.917, val_acc=0.714]
Epoch 6: 100%|████████████████| 1563/1563 [01:04<00:00, 24.25it/s, loss=0.432, v_num=12, val_loss=0.807, val_acc=0.755]
Epoch 7: 100%|████████████████| 1563/1563 [01:04<00:00, 24.22it/s, loss=0.383, v_num=12, val_loss=0.727, val_acc=0.776]
Epoch 8: 100%|█████████████████| 1563/1563 [01:03<00:00, 24.64it/s, loss=0.33, v_num=12, val_loss=0.771, val_acc=0.783]
Epoch 9: 100%|████████████████| 1563/1563 [01:03<00:00, 24.62it/s, loss=0.272, v_num=12, val_loss=0.781, val_acc=0.792]
Epoch 9: 100%|████████████████| 1563/1563 [01:03<00:00, 24.62it/s, loss=0.272, v_num=12, val_loss=0.781, val_acc=0.792]
Files already downloaded and verified
Files already downloaded and verified
Testing: 100%|███████████████████████████████████████████████████████████████████████| 313/313 [00:05<00:00, 53.76it/s]
--------------------------------------------------------------------------------
DATALOADER:0 TEST RESULTS
{'val_acc': tensor(0.7639, device='cuda:0'),
'val_loss': tensor(0.7649, device='cuda:0')}
--------------------------------------------------------------------------------
optimizer = torch.optim.SGD(self.parameters(), lr=0.1, momentum=0, dampening=0, weight_decay=0, nesterov=False)
Epoch 0: 100%|████████████████████| 1563/1563 [00:56<00:00, 27.48it/s, loss=1.7, v_num=9, val_loss=1.87, val_acc=0.345]
Epoch 1: 100%|████████████████████| 1563/1563 [00:57<00:00, 27.21it/s, loss=1.23, v_num=9, val_loss=1.26, val_acc=0.54]
Epoch 2: 100%|█████████████████| 1563/1563 [00:57<00:00, 27.18it/s, loss=0.856, v_num=9, val_loss=0.926, val_acc=0.685]
Epoch 3: 100%|█████████████████| 1563/1563 [00:57<00:00, 27.13it/s, loss=0.664, v_num=9, val_loss=0.847, val_acc=0.717]
Epoch 4: 100%|█████████████████| 1563/1563 [00:58<00:00, 26.70it/s, loss=0.559, v_num=9, val_loss=0.795, val_acc=0.736]
Epoch 5: 100%|█████████████████| 1563/1563 [00:58<00:00, 26.69it/s, loss=0.454, v_num=9, val_loss=0.912, val_acc=0.718]
Epoch 6: 100%|███████████████████| 1563/1563 [00:58<00:00, 26.57it/s, loss=0.4, v_num=9, val_loss=0.745, val_acc=0.774]
Epoch 7: 100%|█████████████████| 1563/1563 [00:58<00:00, 26.76it/s, loss=0.315, v_num=9, val_loss=0.753, val_acc=0.783]
Epoch 8: 100%|█████████████████| 1563/1563 [00:58<00:00, 26.54it/s, loss=0.245, v_num=9, val_loss=0.692, val_acc=0.801]
Epoch 9: 100%|██████████████████| 1563/1563 [00:58<00:00, 26.72it/s, loss=0.22, v_num=9, val_loss=0.754, val_acc=0.794]
Epoch 9: 100%|██████████████████| 1563/1563 [00:58<00:00, 26.72it/s, loss=0.22, v_num=9, val_loss=0.754, val_acc=0.794]
Files already downloaded and verified
Files already downloaded and verified
Testing: 100%|███████████████████████████████████████████████████████████████████████| 313/313 [00:05<00:00, 53.47it/s]
--------------------------------------------------------------------------------
DATALOADER:0 TEST RESULTS
{'val_acc': tensor(0.8036, device='cuda:0'),
'val_loss': tensor(0.6908, device='cuda:0')}
--------------------------------------------------------------------------------
optimizer = torch.optim.AdamW(self.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.01, amsgrad=False)
Epoch 0: 100%|███████████████████| 1563/1563 [01:08<00:00, 22.94it/s, loss=1.22, v_num=13, val_loss=1.3, val_acc=0.527]
Epoch 1: 100%|█████████████████| 1563/1563 [01:08<00:00, 22.75it/s, loss=0.977, v_num=13, val_loss=1.06, val_acc=0.632]
Epoch 2: 100%|████████████████| 1563/1563 [01:08<00:00, 22.73it/s, loss=0.841, v_num=13, val_loss=0.872, val_acc=0.705]
Epoch 3: 100%|████████████████| 1563/1563 [01:08<00:00, 22.67it/s, loss=0.682, v_num=13, val_loss=0.769, val_acc=0.744]
Epoch 4: 100%|████████████████| 1563/1563 [01:08<00:00, 22.67it/s, loss=0.563, v_num=13, val_loss=0.704, val_acc=0.766]
Epoch 5: 100%|████████████████| 1563/1563 [01:08<00:00, 22.67it/s, loss=0.461, v_num=13, val_loss=0.678, val_acc=0.784]
Epoch 6: 100%|████████████████| 1563/1563 [01:08<00:00, 22.74it/s, loss=0.394, v_num=13, val_loss=0.679, val_acc=0.789]
Epoch 7: 100%|████████████████| 1563/1563 [01:08<00:00, 22.75it/s, loss=0.339, v_num=13, val_loss=0.711, val_acc=0.787]
Epoch 8: 100%|████████████████| 1563/1563 [01:08<00:00, 22.86it/s, loss=0.186, v_num=13, val_loss=0.748, val_acc=0.795]
Epoch 9: 100%|████████████████| 1563/1563 [01:08<00:00, 22.85it/s, loss=0.231, v_num=13, val_loss=0.749, val_acc=0.799]
Epoch 9: 100%|████████████████| 1563/1563 [01:08<00:00, 22.85it/s, loss=0.231, v_num=13, val_loss=0.749, val_acc=0.799]
Files already downloaded and verified
Files already downloaded and verified
Testing: 100%|███████████████████████████████████████████████████████████████████████| 313/313 [00:05<00:00, 53.72it/s]
--------------------------------------------------------------------------------
DATALOADER:0 TEST RESULTS
{'val_acc': tensor(0.7835, device='cuda:0'),
'val_loss': tensor(0.6767, device='cuda:0')}
--------------------------------------------------------------------------------
まとめ
・VGD, momentum, そしてgradでの規格化をそれぞれ比較し、性質を明らかにした
・RMSpropとAdamの比較を実施して、性質を明らかにした
・Cifar10のcategorizeに適用して、種々のoptimizerの性能を比較した
・実際の学習への適用のような複雑なポテンシャル問題では、optimizerだけで、精度云々は一概に言えない。