昨夜のアプリはどうも精度が悪いという評価で、なんらかのバグが潜んでいるような気がしていたが、。。。
最近参考のような記事が出て、普通のsvm.LinearSVC()で識別していて、まあ精度から言えばVGG16の方がいいはずということで、見直ししてみました。
【参考】
・scikit-learnとMacカメラで撮影した顔写真を使って、リアルタイム顔判別を行ってみた
やったこと
・カメラ画像で学習
・前回コードに明らかなバグ
・識別画像を識別結果保存して検証
・コード説明
・カメラ画像で学習
学習用のカメラ画像は参考のコードを参考させていただいて、以下のようなものとしました。
・face_recognition/camera_face.py
主な変更点は、以下のとおり
①画像収集時点の顔画像を見えるように出力
②収集画像のサイズ(224,224)
③minSize=(30,30)とした
④画像名は通し番号
。。。
今回は、まゆゆとあかりんだーすーさん、そしてウワンの顔を200枚ずつ収集した。
学習は前回同様、VGG16のFinetuningで実施した。
poch loss acc val_loss val_acc
100 0.000000 1.000000 0.045002 0.980000
なお、まゆゆもあかりんだーすーさんも画像は全身像から顔認識して抽出しており、さらに全身像は一部の画像のみを利用している。
・前回コードに明らかなバグ
前回、コードを部分部分で検証した結果、以下に明らかなバグがありました。
つまり、x = image.img_to_array(img) としていましたが、出力してみると輝度が変わってしまっていて、これでは学習データと違いすぎるので、学習時と同じx = img/255としました。
前回精度が悪い原因は、これが原因だったと思われます。
def yomikomi(model,img):
name_list=['まゆゆ','あかりんだーすー','ウワン'] #['まゆゆ','さっしー','きたりえ','じゅりな','おぎゆか','あかりんだーすー']
x = img/255 #image.img_to_array(img)
cv2.imshow("x",x)
x = np.expand_dims(x, axis=0)
preds = model.predict(x)
index=np.argmax(preds[0])
print(preds[0])
print(index,name_list[index],preds[0][index])
return name_list[index], preds[0][index]
・識別画像を識別結果保存して検証
上記のバグ改修しても実はどうもたまに予期した識別結果と異なる文字が出ます。
ということで、それぞれの識別画像を保存しました。
しかも識別結果と識別確率をその画像ファイルのファイル名に入れることとしました。
そのために、識別名をPykakasiを利用してアルファベットにしました。
その結果、以下のように識別名と画像はほぼ正しく表示されていることがわかりました。
異なる結果を出しているのは、ピンボケカメラ画像と顔以外の部分を判別している場合だというのがわかります、そしてその場合の確率は100%よりかなり小さな値を示しています。

・コード説明
コード全体は以下に置きました。
・face_recognition/recognize_vgg16_camera.py
pykakasiを使います。カナ、かなも漢字もアルファベットに変換します。
def main():
kakasi_ = kakasi()
kakasi_.setMode('H', 'a')
kakasi_.setMode('K', 'a')
kakasi_.setMode('J', 'a')
conv = kakasi_.getConverter()
出力先を数字0などでディレクトリ指定します。
#カスケード分類器の特徴量を取得する
cascade = cv2.CascadeClassifier(cascade_path)
color = (255, 255, 255) #白
path = "./img/"
label = str(input("人を判別する数字を入力してください ex.0:"))
OUT_FILE_NAME = "./img/face_recognition.avi"
FRAME_RATE=1
w=224 #1280
h=224 #960
out = cv2.VideoWriter(OUT_FILE_NAME, \
cv_fourcc('M', 'P', '4', 'V'), \
FRAME_RATE, \
(w, h), \
True)
cap = cv2.VideoCapture(1)
is_video = 'False'
s=0.1
日本語を画像(動画)に出力するために、Fonts指定をします。
model=model_definition()
## Use HGS創英角ゴシックポップ体標準 to write Japanese.
fontpath ='C:\Windows\Fonts\HGRPP1.TTC' # Windows10 だと C:\Windows\Fonts\ 以下にフォントがあります。
font = ImageFont.truetype(fontpath, 16) # フォントサイズが32
font0 = cv2.FONT_HERSHEY_SIMPLEX
sk=0
以下は前回のコードと同一です。
while True:
b,g,r,a = 0,255,0,0 #B(青)・G(緑)・R(赤)・A(透明度)
timer = cv2.getTickCount()
ret, frame = cap.read()
sleep(s)
fps = cv2.getTickFrequency() / (cv2.getTickCount() - timer);
# Display FPS on frame
cv2.putText(frame, "FPS : " + str(int(1000*fps)), (100,50), font0, 0.75, (50,170,50), 2);
#グレースケール変換
image_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
facerect = cascade.detectMultiScale(image_gray, scaleFactor=1.1, minNeighbors=2, minSize=(30, 30))
顔の矩形はわかりやすいコードにしました。
一応、本来不要ですが、img=frameとして、imgを利用します。
img=frame
if len(facerect) > 0:
#検出した顔を囲む矩形の作成
for rect in facerect:
x=rect[0]
y=rect[1]
width=rect[2]
height=rect[3]
roi = img[y:y+height, x:x+width]
cv2.rectangle(img, tuple(rect[0:2]),tuple(rect[0:2]+rect[2:4]), color, thickness=2)
上で抽出した顔(roi)をVGG16の入力画像サイズに合わせて、(224,224)にサイズ変更します。
本来必要ありませんが、確認の意味でここで画面にroiを出力しています。
yomikomi関数を使って、顔識別を行い、その確率を取得します。
取得した識別結果を表示します。
try:
roi = cv2.resize(roi, (int(224), 224))
cv2.imshow('roi',roi)
txt, preds=yomikomi(model,roi)
print("txt, preds",txt,preds*100 ," %")
識別結果は複数の顔を抽出した場合を考えて、ここで動画に貼り付けることとしました。
txt2=conv.do(txt)
cv2.imwrite(path+"/"+label+"/"+str(sk)+'_'+str(txt2)+'_'+str(int(preds*100))+'.jpg', roi)
img_pil = Image.fromarray(img) # 配列の各値を8bit(1byte)整数型(0~255)をPIL Imageに変換。
draw = ImageDraw.Draw(img_pil) # drawインスタンスを生成
position = (x, y) # テキスト表示位置
draw.text(position, txt, font = font , fill = (b, g, r, a) ) # drawにテキストを記載 fill:色 BGRA (RGB)
img = np.array(img_pil) # PIL を配列に変換
except:
txt=""
continue
最後に動画を画面に出力し、録画モード(is_video=="True")の場合は動画として出力します(out.write(img_dst))。
cv2.imshow('test',img)
sk +=1
key = cv2.waitKey(1)&0xff
if is_video=="True":
img_dst = cv2.resize(img, (int(224), 224)) #1280x960
out.write(img_dst)
print(is_video)
if key == ord('q'): #113
break
結果
以下のような複数顔抽出の場合も綺麗に顔識別できました。
顔学習が不十分なところもあって、反応しない顔やあかりんだーすーさんをまゆゆと間違えることもありました。
face recognition by vgg16
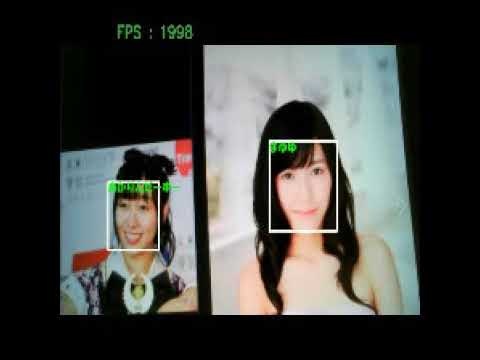
※画像をクリックするとYouTube動画につながります
まとめ
・まゆゆとあかりんだーすーさんと(ウワンの)顔識別が出来ました
・学習が若干不足しているので、まだ間違えることがあるようです
・いよいよ「ウワンさん、こんにちわ」をやりたいと思う