参考の記事をちょっと試したら、少しはまったので備忘録で残しておく。
【参考】
・①K-meansクラスタリング
少し古い記事らしくて、言語仕様やリンクがちょっとということで、その修正を以下の通り、実施しました。
やったこと
・urllib.urlretrieveをurllib.request.urlretrieveに変更する
・color=colorsをc=colorsに変更する
・urllib.urlretrieveをurllib.request.urlretrieveに変更する
コード全体はおまけに載せておきます。
参考のとおり、「urlretrieveは、ネット上からファイルをダウンロードし保存するのに使う。しかし、2系と3系とで違いがありググラビリティが低い。なので、書き記す。」ということで、以下のとおり書き換えると動きました。
import urllib.request
# ウェブ上のリソースを指定する
url = 'https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/SchoolScore.txt'
# 指定したURLからリソースをダウンロードし、名前をつける。
urllib.request.urlretrieve(url, 'SchoolScore.txt')
【参考】
・②python3 urlretrieve
・color=colorsをc=colorsに変更する
こちらは、少し英文読まないといけないのですが、つまりmatplotlibに渡すとき混乱するので、colorではなくcで渡しましょうということで、colorをcにするとカラーが反映しました。
原文引用「For the time been, as suggested, use c instead of color」
【参考】
・③ValueError: Supply a 'c' kwarg or a 'color' kwarg but not both; they differ but their functionalities overlap
まとめ
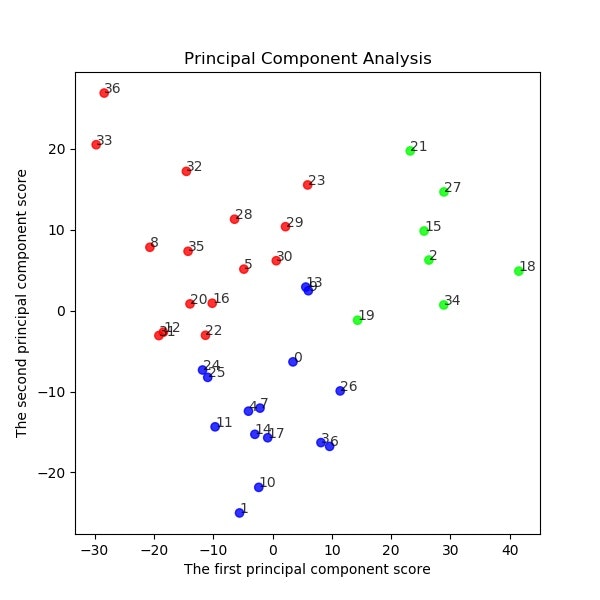
・k-meansクラスタリングと主成分分析をやってみた
・離散データには応用できそうだけど、残念ながら音声の分類には不適当なようだ
おまけ
以下のコードは上記記載の変更以外は前出の参考①のとおりです。
# URL によるリソースへのアクセスを提供するライブラリをインポートする。
import urllib.request
import pandas as pd # データフレームワーク処理のライブラリをインポート
# 図やグラフを図示するためのライブラリをインポートする。
import matplotlib.pyplot as plt
from pandas.tools import plotting # 高度なプロットを行うツールのインポート
from sklearn.cluster import KMeans # K-means クラスタリングをおこなう
# import sklearn #機械学習のライブラリ
from sklearn.decomposition import PCA #主成分分析器
# ウェブ上のリソースを指定する
url = 'https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/SchoolScore.txt'
# 指定したURLからリソースをダウンロードし、名前をつける。
urllib.request.urlretrieve(url, 'SchoolScore.txt')
# ('SchoolScore.txt', <httplib.HTTPMessage instance at 0x104143e18>)
df = pd.read_csv("SchoolScore.txt", sep='\t', na_values=".") # データの読み込み
df.head() #データの確認
df.iloc[:, 1:].head() #解析に使うデータは2列目以降
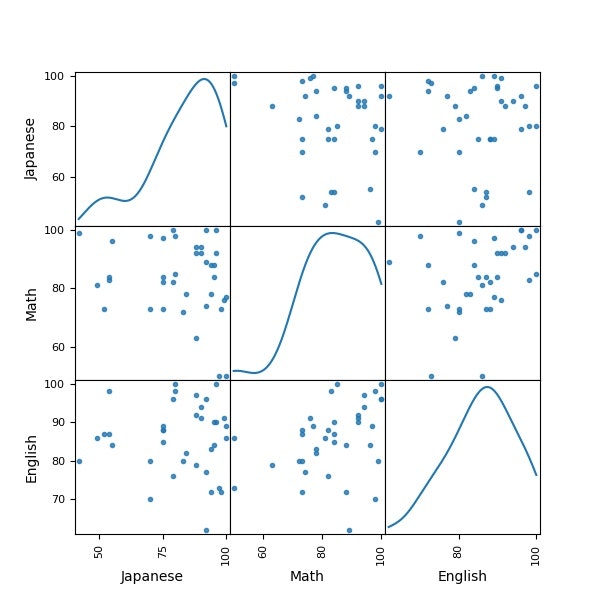
plotting.scatter_matrix(df[df.columns[1:]], figsize=(6,6), alpha=0.8, diagonal='kde') #全体像を眺める
plt.savefig('k-means/scatter_plot.jpg')
plt.pause(1)
plt.close()
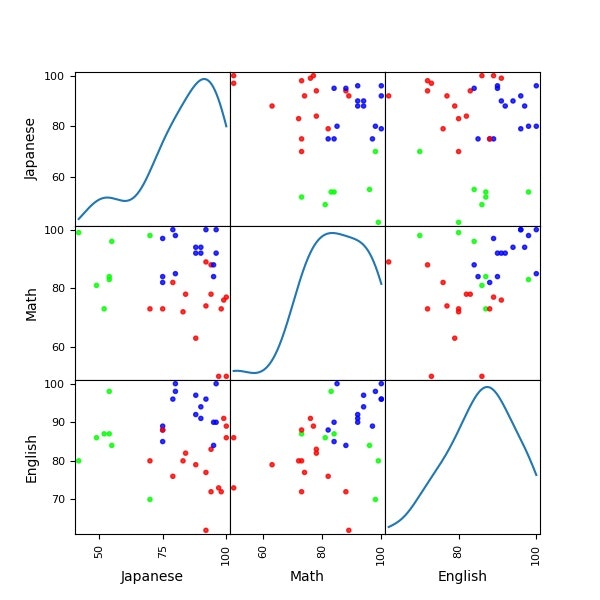
# この例では 3 つのグループに分割 (メルセンヌツイスターの乱数の種を 10 とする)
kmeans_model = KMeans(n_clusters=3, random_state=10).fit(df.iloc[:, 1:])
# 分類結果のラベルを取得する
labels = kmeans_model.labels_
# 分類結果を確認
print(labels)
以下が出力
[2 2 0 2 2 1 2 2 1 2 2 2 1 2 2 0 1 2 0 0 1 0 1 1 2 2 2 0 1 1 1 1 1 1 0 1 1]
# それぞれに与える色を決める。
color_codes = {0:'#00FF00', 1:'#FF0000', 2:'#0000FF'}
# サンプル毎に色を与える。
colors = [color_codes[x] for x in labels]
# 色分けした Scatter Matrix を描く。
plotting.scatter_matrix(df[df.columns[1:]], figsize=(6,6),c=colors, diagonal='kde', alpha=0.8) #データのプロット
plt.savefig('k-means/scatter_color_plot.jpg')
plt.pause(1)
plt.close()
# 主成分分析の実行
pca = PCA()
pca.fit(df.iloc[:, 1:])
PCA(copy=True, n_components=None, whiten=False)
# データを主成分空間に写像 = 次元圧縮
feature = pca.transform(df.iloc[:, 1:])
# 第一主成分と第二主成分でプロットする
plt.figure(figsize=(6, 6))
for x, y, name in zip(feature[:, 0], feature[:, 1], df.iloc[:, 0]):
plt.text(x, y, name, alpha=0.8, size=10)
plt.scatter(feature[:, 0], feature[:, 1], alpha=0.8, color=colors)
plt.title("Principal Component Analysis")
plt.xlabel("The first principal component score")
plt.ylabel("The second principal component score")
plt.savefig('k-means/PCA12_plot.jpg')
plt.pause(1)
plt.close()
最後にそもそものデータを掲載しておく
https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/SchoolScore.txt
以下のデータでは上記で得られた分類(ラベル)を追加しています。
| Student | Japanese | Math | English | Category |
|---|---|---|---|---|
| 0 | 80 | 85 | 100 | 2 |
| 1 | 96 | 100 | 100 | 2 |
| 2 | 54 | 83 | 98 | 0 |
| 3 | 80 | 98 | 98 | 2 |
| 4 | 90 | 92 | 91 | 2 |
| 5 | 84 | 78 | 82 | 1 |
| 6 | 79 | 100 | 96 | 2 |
| 7 | 88 | 92 | 92 | 2 |
| 8 | 98 | 73 | 72 | 1 |
| 9 | 75 | 84 | 85 | 2 |
| 10 | 92 | 100 | 96 | 2 |
| 11 | 96 | 92 | 90 | 2 |
| 12 | 99 | 76 | 91 | 1 |
| 13 | 75 | 82 | 88 | 2 |
| 14 | 90 | 94 | 94 | 2 |
| 15 | 54 | 84 | 87 | 0 |
| 16 | 92 | 89 | 62 | 1 |
| 17 | 88 | 94 | 97 | 2 |
| 18 | 42 | 99 | 80 | 0 |
| 19 | 70 | 98 | 70 | 0 |
| 20 | 94 | 78 | 83 | 1 |
| 21 | 52 | 73 | 87 | 0 |
| 22 | 94 | 88 | 72 | 1 |
| 23 | 70 | 73 | 80 | 1 |
| 24 | 95 | 84 | 90 | 2 |
| 25 | 95 | 88 | 84 | 2 |
| 26 | 75 | 97 | 89 | 2 |
| 27 | 49 | 81 | 86 | 0 |
| 28 | 83 | 72 | 80 | 1 |
| 29 | 75 | 73 | 88 | 1 |
| 30 | 79 | 82 | 76 | 1 |
| 31 | 100 | 77 | 89 | 1 |
| 32 | 88 | 63 | 79 | 1 |
| 33 | 100 | 50 | 86 | 1 |
| 34 | 55 | 96 | 84 | 0 |
| 35 | 92 | 74 | 77 | 1 |
| 36 | 97 | 50 | 73 | 1 |