前回は単にYahooから取得した60個/カテゴリのデータをそのまま学習した。
以下の課題があった。
③【課題】Fine-Tuningだけだと、データ入れ替えしてエラーが消えても、Tuning後Testデータに対するエラーが75%まで低下してしまった。
⇒ここはもう少し、追及して理解しておきたい
また、普通にフィッティングした場合は、Testデータのフィッティング率は75%程度でそれ以上上がらない。
そこで、今回は各データから顔抽出し、かつデータ数も増やしてその効果を見てみた。
yahooからAKB総選挙上位者の写真ダウンロード
以下の手順とコードを利用
一回60個しかダウンロード出来ないが、繰り返しは可能で毎回ヒットするのは少し異なる。しかし検索ワードにかわいいとか顔写真とか追加すると別の絵がヒットする確率が上がるようだ。コンタミネーションにはAKBとかを検索ワードに入れるのは効果があった。それでもコンタミネーション(他人の画像や同じ画像が入る)は発生するので、クレンジングが必要。
今回は顔抽出してから実施した。
【コード】
get_images_yahoo.py
https://github.com/MuAuan/DataManage
【参考】Aidemy Inc. (id:aidemy-blog) の以下のサイト
http://blog.aidemy.net/entry/2017/12/17/214715
OpenCVでダウンロードしたデータから顔抽出
この方法は確立しているようで、以下のサイトを参考にして作成した。
そのままのコードを自分のDir構成に変更するだけで動いたが、注意すべきなのは、顔抽出するときのXMLデータをダウンロードして格納し、フルパスで指定すること。
また、XMLデータは以下のサイトからダウンロードすることが必要。
cascade_path = '/Users/user/haarcascade_frontalface_default.xml'
cascade_path = '/Users/user/haarcascade/haarcascade_frontalface_alt2.xml'
※上記二つのxmlだと、haarcascade_frontalface_alt2.xmlが優れていた。
また、ダウンロードサイトが重いのでゆっくり待つこと
【コード】
face_detect.py
https://github.com/MuAuan/DataManage
【参考】
TensorFlowを使ってDir en greyの顔分類器を作ってみた - ④顔抽出編
https://qiita.com/neriai/items/cedc0de9e3722f53287a
haarcascade_frontalface_default.xmlのダウンロードサイト
https://github.com/opencv/opencv/tree/master/data/haarcascades
目検と顔抽出されたデータをクレンジングする
方法は、以下の二通り
①目検でやる
顔画像は、どうやら違いが分かりやすくて、この段階で100枚程度ならどうにか違う人の画像は選り分けられる
顔抽出されると、ウワンといえども目の識別能力が上がるようだ。
とにかくランキング10位までの人をほぼ認識できるようになった。
②好みの顔で学習された分類器で分類する
ここで、好みのというのは、最終的にどういう分類器を作りたいかで決まる。
より汎用的な分類器を目指すのであれば、対象は多様にして、変顔とか怒った顔とかも含め、本人以外の人を除外する目的で使う。また、データ数も多いことが要求される。
そうではなくて、あくまで笑った顔や澄ました顔、美しく見える顔を分類したければ、そういう例で確実に本人であるものを選んで学習させた分類器を使うのが良い。
因みに、ここで重要なことはこの目的で作る分類器はデータ数が20程度でもある程度は分類可能であった。
※ここは、次の「Fine-Tuningの学習データはどこまで削減できるか」で取り上げたい
ということで、今回は汎用性を選んで本人以外を除いたもので分類器を作り、その分類器で全体を識別してフィッティング率の高いものを本人として、分類してみた。
※元画像が多い場合は、①の方法では限界があるので有効な方法だと思う。それほど多くなければ、その分類後外れている画像について、目検で判断することもできる。
同一画像を選別する
上記のように多数回検索で収集した画像には、同一画像が含まれていることが多い。
しかし、上記で得られる画像の一致率は、同じ画像については同一の一致率が得られるので、同一画像が2枚以上入っている場合にはこの数字でセレクトできる。
結果
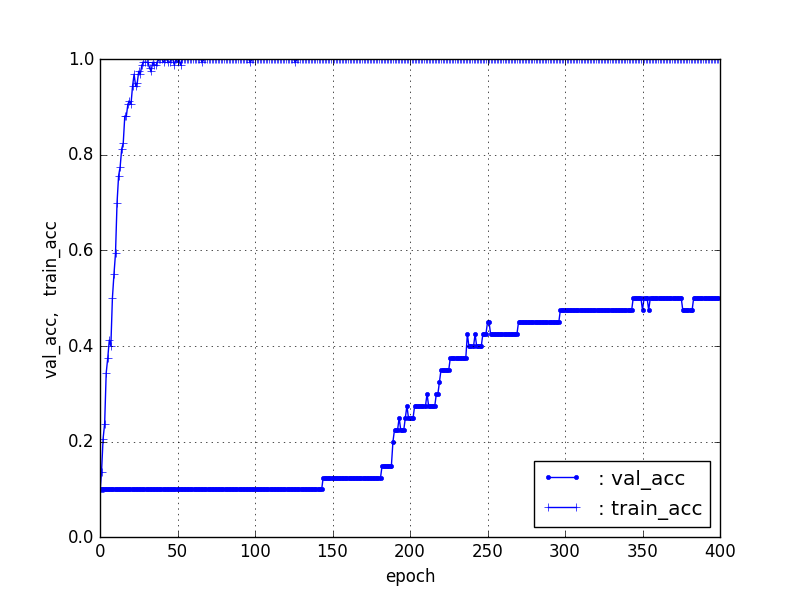
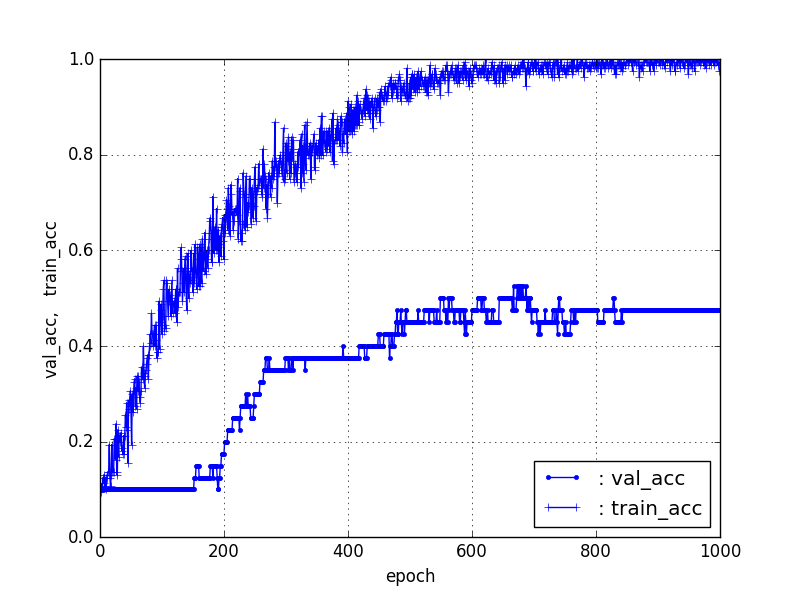
①データ20個/カテゴリ(Train16,Test4)10カテゴリで作成した分類器は、以下のとおりである。
Trainはほぼ100%の一致率が得られる。問題は、Testデータに対する一致率であるが、今回はテストデータ20%(4個/カテゴリ)にして、ResNet50[90層固定]のFine-Tuning50%程度、[174層固定]の転移学習でも50%弱であった。
フィッティングの経過グラフ(データ数20個/カテゴリ)
【ResNet5090層固定】
【ResNet174層固定】
②データクレンジング後、40個、60個、80個、そして100個/カテゴリでのフィッティング
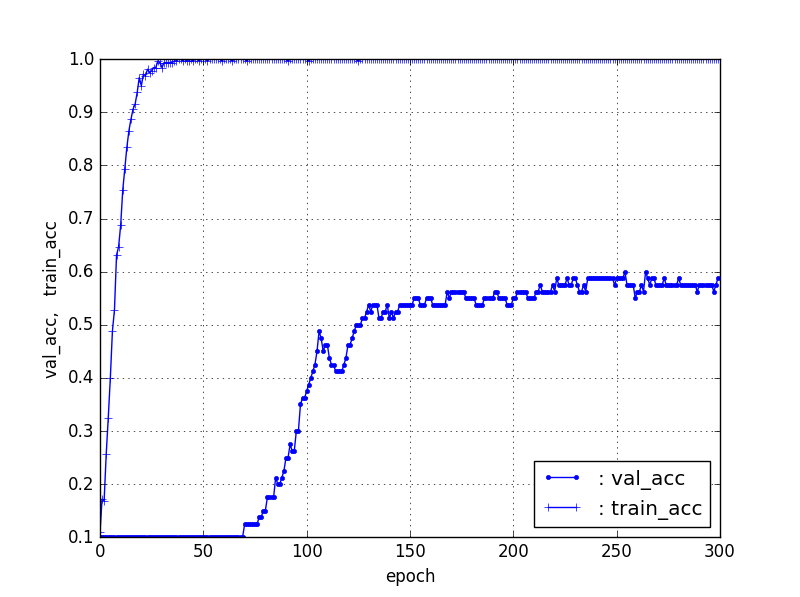
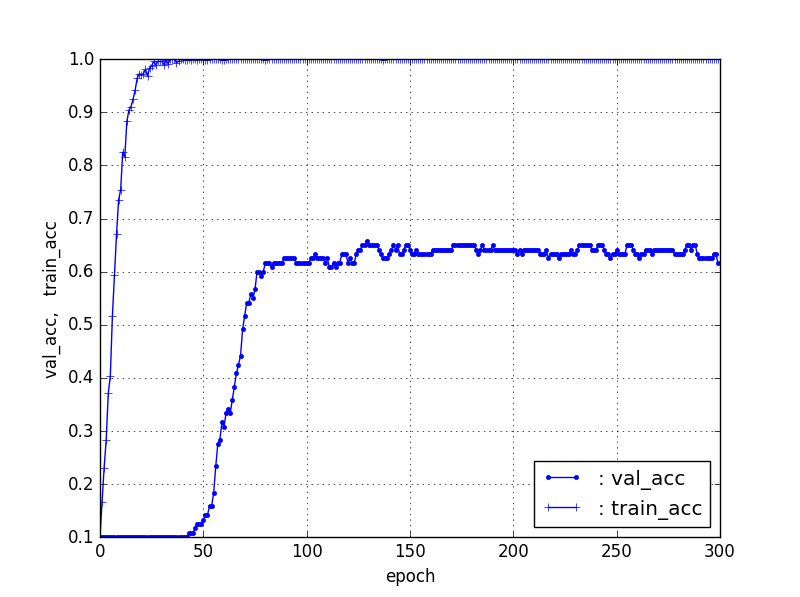
①で選別された100個/カテゴリのデータを利用して、フィッティングすると以下のとおり、Fine-Tuningの場合で、40個/カテゴリでは60%程度、60個/カテゴリでは65%程度、80個/カテゴリは72%程度のフィッティング率になった。
ここから、データ数を増加するとFine-TuningではTestデータのフィッティング率が増加することがわかる。ただし、100個/カテゴリも72%程度であり、このあたりで、増加傾向は止まったように見える。
また、立ち上がりのepochを見ると、学習は総バッチデータ数で決まっているようだ。
【それぞれのval_accとtrain_accのグラフ】
【40個/カテゴリ(train32、test8)】ResNet5090層固定
【60個/カテゴリ(train48、test12)】ResNet5090層固定
【80個/カテゴリ(train64、test16)】ResNet5090層固定
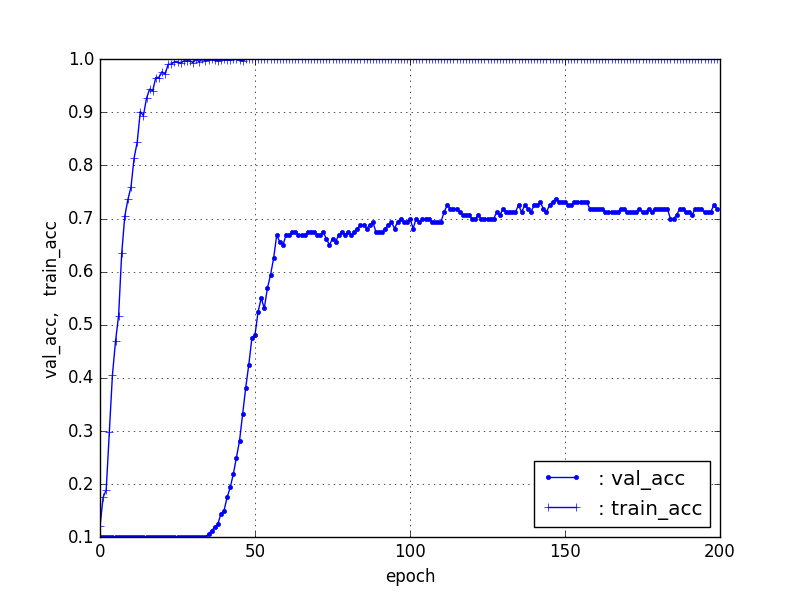
【100個/カテゴリ(train80、test20)】ResNet5090層固定
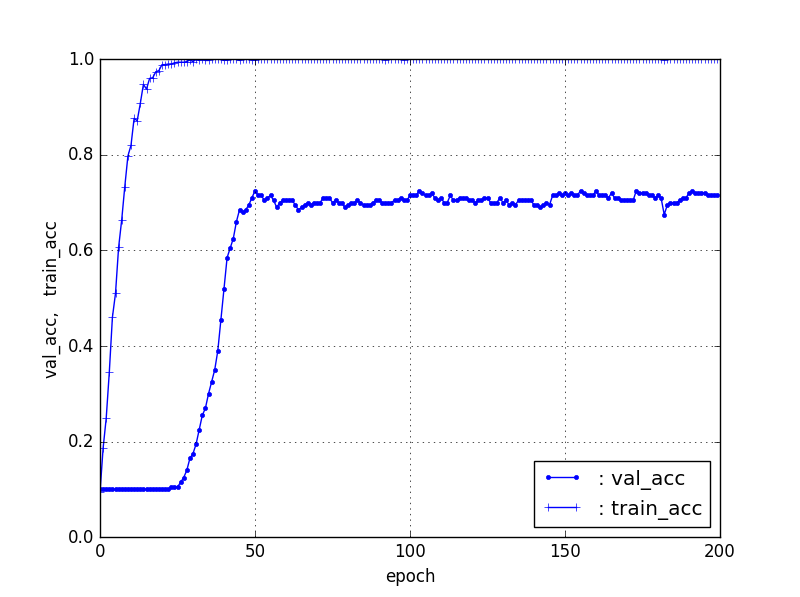
TrainデータとTestデータの比率を変える
上記の結果は、データ数が増加するとTestデータを表現する特徴がTrainデータに含まれる確率が増加することによると推論できる。それならば、その比率を増加すれば当然フィッティング率が増加する。もちろん、Trainデータ100%ならばほぼすべてフィッティングされるので、当然そうなるものと考察できる。
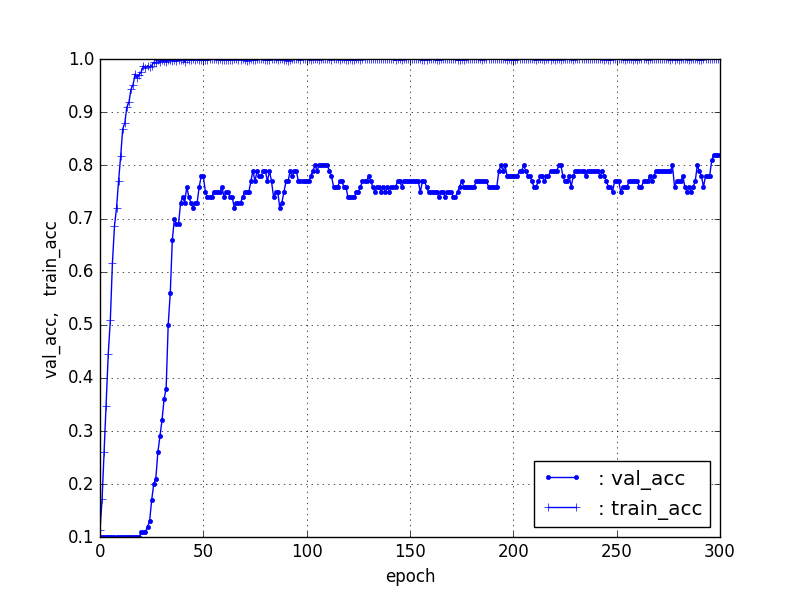
ということで、上記は20%をTestデータとしていたが、10%をTestデータとしたときの100個/カテゴリの場合をやってみると以下のとおり、80%程度の精度が得られた。
【100個/カテゴリ(train90、test10)】ResNet5090層固定
まとめ
Fine-Tuningおよび転移学習のフィッティング精度のデータ数依存性などを調べた
その結果
①データは少なくても、クレンジングすればある程度の精度(とりあえず識別に利用できるレベル)が得られる。100個/カテゴリ程度あると信頼性は80%程度になる。
②Fine-Tuningと転移学習はそれぞれ特徴があり、識別器の利用シーン(リアルタイムで更新する必要があるなど)、得られたデータ量(増えるとFine-Tuningは時間を要する)などにより、特性を意識して利用したい。ただし、データ量が少ない場合は、たいして時間も変わらないのでFine-Tuningが精度の面で有利と言える。
③中身がわからないものでも、一定のクレンジング方法を適用すれば、高精度に収束させることができる可能性がある。
課題
今回は、データ数に対してTrainデータとTestデータの割合を固定して、精度を見たが、Testデータ20%の結果と10%の結果を見ればわかるように、実際はFittingした識別器の汎用性(世の中の識別対象全体に対する有用性)を見る必要がある。
そのためには、本来Testデータは無限にあるデータに対して評価する必要があり、少数データにおける一定割合のデータはそれらを代表しているとは言えない。
ということで、次回はそこを追求して、Fine-Tuningにしろ、少数データで作成した識別器が本当に有用なのかを評価しようと思う。