はじめに
同じ様式で作成された複数のWord文書(.docxファイル)から、表の指定セルのテキストを抽出する案件に対応した際のメモとして残しておきます。
Python + python-docx を使った事例はよく見かけますが、ここでは、F# + Open XML SDK for Office を採用しました。
ここを読めば Office のファイルに関して大半のことはできそうです。
環境
- Windows 11 Pro 23H2
- F# 8.0 (.NET SDK 8.0.304)
- ThinkPad L15 Gen 1 (Core i5-10210U 8.00GB)
とりあえずテキスト抽出(表などを無視)
次の内容が記録されたファイル example.docx を材料にします。
表などを無視して、段落単位でテキスト抽出・保存する場合は簡潔に記述できます。
#r "nuget: DocumentFormat.OpenXml"
open DocumentFormat.OpenXml.Packaging
open DocumentFormat.OpenXml.Wordprocessing
let docxPath = @"C:\Users\User\example.docx"
let txtPath = @"C:\Users\User\example.txt"
let doc = WordprocessingDocument.Open(docxPath, false) // Read only
let txt =
doc.MainDocumentPart.Document.Body.Elements<Paragraph>()
|> Seq.map _.InnerText
doc.Dispose()
System.IO.File.WriteAllLines(txtPath, txt)
F# Interactive での実行結果です。
続けてcat(Get-Content)コマンドで、保存されたテキストの内容を確認しています。
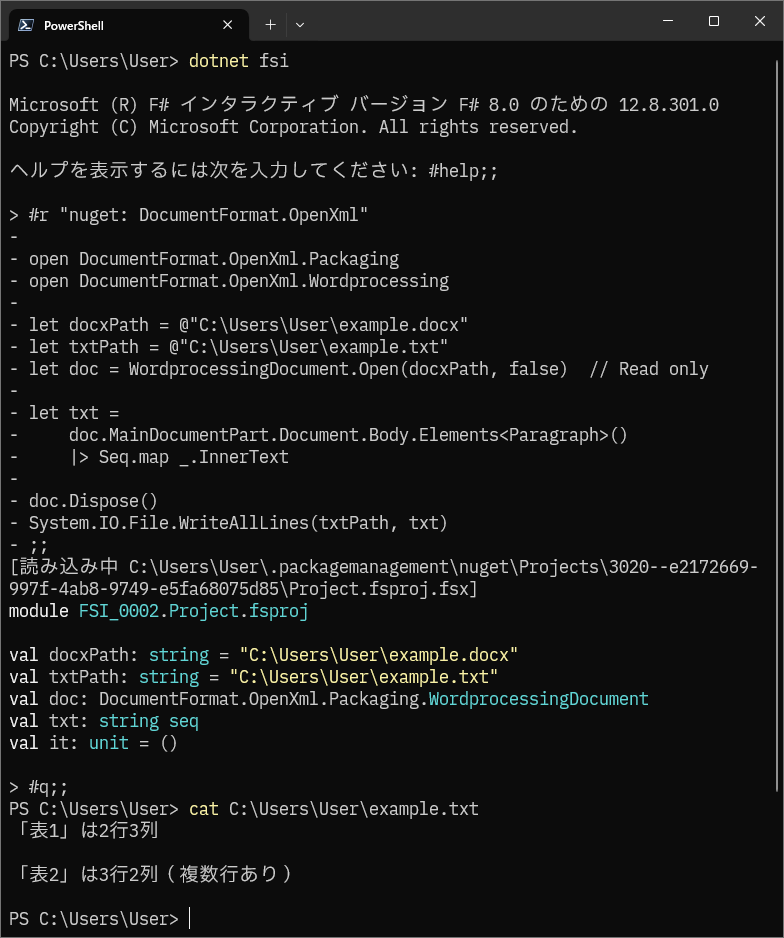
表以外の文字列がテキストファイルになっています。
処理の際、対象になるWord文書は閉じておく必要があります。
表の内容も含めて抽出
こちらが参考になります。
文書中の表も含めてテキスト抽出・保存してみます。
表は列をタブ区切りにします。
複数行を持つセルについてはセル内改行によるイメージの乱れを防ぐために、改行の代わりに文字列<LF>を挿入しています。
表をテキストにする関数も、F#のパイプラインによる記述で処理がつかみやすいと思います。
ここでは、理解しやすくするために型も可能な限り明記しています。
#r "nuget: DocumentFormat.OpenXml"
open DocumentFormat.OpenXml
open DocumentFormat.OpenXml.Packaging
open DocumentFormat.OpenXml.Wordprocessing
let docxPath: string = @"C:\Users\User\example.docx"
let txtPath: string = @"C:\Users\User\example.txt"
// 表をテキストにする関数
let getTableText (tbl: Table) : string =
tbl.Elements<TableRow>()
|> Seq.map (fun (row: TableRow) ->
row.Elements<TableCell>()
|> Seq.map (fun (cell: TableCell) ->
cell.Elements<Paragraph>()
|> Seq.map _.InnerText
|> String.concat "<LF>")
|> String.concat "\t")
|> String.concat "\n"
// 「通常の段落」と「表」に応じた処理をする関数
// 渡された要素に対して型テストパターンで分岐
let getText (element: OpenXmlElement) : string =
match element with
| :? Paragraph as para -> para.InnerText
| :? Table as tbl -> getTableText tbl
| _ -> ""
// docxファイルを開いて Body 内の要素順に処理を進める
let doc: WordprocessingDocument = WordprocessingDocument.Open(docxPath, false) // Read only
let txt: string seq =
doc.MainDocumentPart.Document.Body.Elements()
|> Seq.map getText
doc.Dispose()
System.IO.File.WriteAllLines(txtPath, txt)
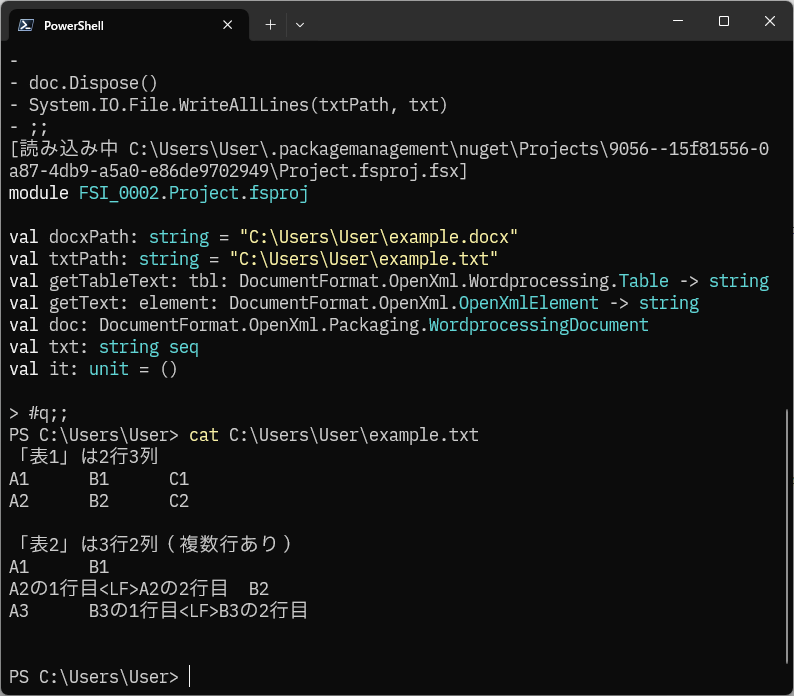
F# Interactive での実行結果(上部省略)とcatコマンドによる確認結果ですが、想定どおりに保存されました。
基本的な操作ができれば、指定した表の指定したセルからのテキスト抽出にも容易に対応できます。最後はスクリプトとして一括処理してミッション完了です。
Open XML SDK for Office は公式ドキュメントも充実していますし、F# Interactive ですぐに確認できるので便利ですね。
おまけ
調査中に発見したこちらの「力技」(下記記事後半のワンライナー:一部改変)も試した結果です。
これ、結構好きです。用途によってはこれで十分。(WSL2 + Ubuntu 22.04.4 で実行)
