はじめに
自分用のメモに近いですがせっかくやってみたので記事にしてみました。
元々ラズパイサイネージをやるために色々調べたのですが、
なかなかピンポイントで欲しい情報がなく結局スクレイピングやり方だけ調べて自力でなんとかしました。
(Python使いでもweb界隈の人でもないので一瞬苦戦しました...)
yahooだと天気のapiがありますが使わなかったのは降水量しかわからないためです。
C#編は
https://qiita.com/MonoShobel/items/3ae0c051d2aadba698a4
あります。
参考にしたもの
Pythonでのスクレイピングに当たり下記の記事を参考にしました。 [pythonでスクレイピングして天気予報をGoogleHomeにしゃべらせる](https://xn--u9jwc776tibf.net/?p=1494) [Python Webスクレイピング 実践入門](https://qiita.com/Azunyan1111/items/9b3d16428d2bcc7c9406)スクレイピング自体に関する良い悪い説明もあるので読んでおいたほうがいいと思います。
ちなみにYahoo天気ですが、たぶんスクレイピングは禁止されていません。
Yahooファイナンスは明確に禁止されていましたが、天気に関しては禁止しているような記述は見つかりませんでした。
ただ節度は守りましょう。定期的にスクレイピングするとしても天気は1時間または30分ごとくらいのアクセスで十分だと思います。
やること
色々取りたい情報はありますがとりあえず東京の今日の天気を取得しました。 下記の画像の今日と明日の天気を取得します。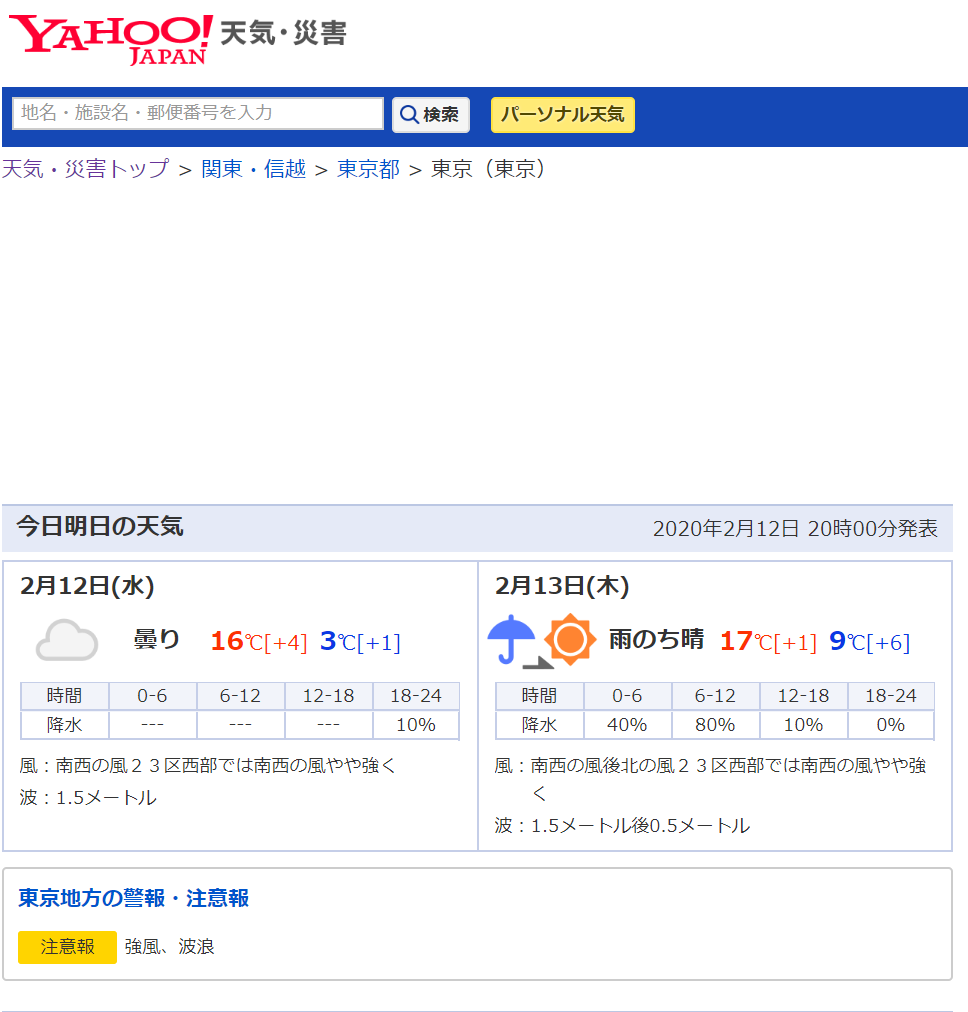
コード
実際にコードを実行すれば今日と明日の東京の天気を取得できます。(Visual Codeで色々書いたりデバックしました。) だいたいコメントに何をやっているか書いてあります。 ほぼコピペのソースですが注目ポイントはselect_oneでtextの部分を取得しているところです。 Google Chromeで自動で取得しようとしたのですがうまくいかなかったので手打ちで探っていったところうまくいきました。tenki.py
import urllib3
from bs4 import BeautifulSoup
# アクセスするURL
url = 'https://weather.yahoo.co.jp/weather/jp/13/4410.html'
# URLにアクセスする 戻り値にはアクセスした結果やHTMLなどが入ったinstanceが帰ってきます
http = urllib3.PoolManager()
instance = http.request('GET', url)
# instanceからHTMLを取り出して、BeautifulSoupで扱えるようにパースします
soup = BeautifulSoup(instance.data, 'html.parser')
# CSSセレクターで天気のテキストを取得します。
# 今日の天気
tenki_today = soup.select_one('#main > div.forecastCity > table > tr > td > div > p.pict')
print ("今日の天気は"+tenki_today.text)
# 明日の天気
tenki_tomorrow = soup.select_one('#main > div.forecastCity > table > tr > td + td > div > p.pict')
print ("明日の天気は"+tenki_tomorrow.text)
# 一瞬で画面が消えないよう入力されるまで待機
input()
以下、実行結果
