世の中、面白いものはいっぱいありますけども、一番面白いのは統計的機械翻訳(SMT)とニューラル機械翻訳(NMT)について調べたときですよね。
近年の機械翻訳
近年、機械翻訳の研究が活発的に行われています。馴染みが深いところで言いますと、やはりGoogle翻訳でしょう。Google翻訳は直接ページに入力するほか、WEBページ全体を翻訳したり、選択した文章のみを翻訳してくれるため、非常に重宝しています。少し前にはもっと精度が高い!と謳ってみらい翻訳も登場しましたね。
近年ではニューラルネットワークを使った機械翻訳が多く登場しています。NMT(ニューラル機械翻訳)は2014年に提案され、あっという間に従来研究の精度を超えました。自然言語処理という分野自体もBERTやXLNetといったSOTAモデルが登場し、SOTA合戦が止まりません。
なお、ニューラルネットワークを使わず、統計的な情報を利用して翻訳する手法はSMT(統計的機械翻訳)、さらにそれを句で拡張したものをPBSMT(Phrase-Based SMT)と呼びます。特定のルールに基づいて翻訳する手法はRMT(ルールベース)と呼ばれます。
GNMT
Google翻訳にも2016年にNMTが採用されました(GNMTと呼ばれます):Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
SMTとPBSMT(統計的機械翻訳)
SMTは学習データから統計モデルを学習し、統計モデルを翻訳器として機械翻訳を実現します。統計モデルは翻訳モデルと言語モデルに分かれ、それぞれ翻訳の確かさと文法の確かさを評価します。
要するに、大量の対訳文から統計モデルを作成し、確率の最も高い文を翻訳結果とするわけですね。
PBSMTはSMTが単語ごとに翻訳するために文脈情報を活用しにくいという問題を抱えていたため、フレーズ(句/部分単語列)を単位として翻訳するように拡張したモデルです。
PBSMTの詳細:Statistical Phrase-Based Translation
言語モデル
言語モデルは言語らしさを確立としてモデル化します。例えば長さ$M$の単語列$w_1...w_M$の生起確率は
P(w_1, ... , w_M) = \prod_{t=1}^mP(w_t|w_1, ... , w_{t-1})
と表せます。N-gram言語モデルでは$N$番目の単語がその直前の$N-1$個の単語に依存すると仮定しています。すなわち言語モデルでは直前の単語の並びによってその文が自然か(自然であれば高い確率を出力)を評価します。
翻訳モデル
翻訳モデルは原言語$f$(入力側)と目的言語$e$(出力側)の意味的な等価性を確率的に評価します。
アライメント(両フレーズの対応)を$a$とし、翻訳モデルを$P(f|e)$とすると
$$
P(f|e) = \sum_aP(f,a|e) = \sum_aP(f|e,a)P(a|e)
$$
となります。式変形にはベイズの定理を使っています。
翻訳確率
言語モデルと翻訳モデルを使って翻訳する確率(翻訳結果としてどれだけふさわしいか)を得られます。
翻訳確率を$\hat{e}$、原言語を$f$、目的言語を$e$とすると
\begin{align}
\hat{e} &= argmax_eP(e|f) \\
&= argmax_eP(f|e)P(e)
\end{align}
と表せます。ここで出てきた$P(f|e)$は翻訳モデル、$P(e)$は言語モデルです。$argmax_ef(x)$は$f(x)$が最大となる$x$を返します。つまり$P(f|e)P(e)$が最大となる解をふさわしい翻訳結果として出力します。
その他の統計的機械翻訳の参考資料
さらに詳しくSMTが知りたい方は以下の資料が参考になるかと思います。
NMT(ニューラル機械翻訳)
NMTは1つのニューラルネットワークを用意することで、訓練と翻訳を完結させることができます。このように入力から出力が単一のモデルで完結するものをend-to-endと呼びます。それに対してSMTは上述した統計モデルの構築の他、単語対応の推定、フレーズテーブルの構築といった多くの段階を踏まなければなりません。
seq2seq
ここではNMTの例として、最も広く知られているであろうseq2seq(Encoder-Decoderモデル)を紹介します。seq2seqは入力文を変換するEncoder、出力文を生成するDecoder(と、入力文のどこに注視するかを決定するAttention)で構成されています。
Effective Approaches to Attention-based Neural Machine Translationより
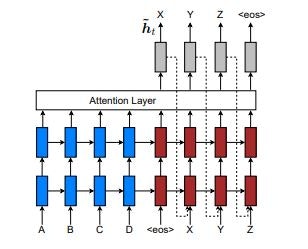
Encoderでは入力となる文字列を単語ごとに分散表現というベクトルに変換します(embedding)。これにより、ベクトルに変換することで定量的に単語が扱える(数値として単語の意味を捉えられる)ようになります。
有名な分散表現を獲得するツールにはWord2Vecがあります。分散表現は通常、大規模なコーパスから学習することも多いですが、ネットワーク内で同時に分散表現を学習することもあります。
embeddingされた単語はRNNに取り込まれます。RNNについて詳しい説明は省略しますが、RNNはループを持つニューラルネットワークであり、時系列データを扱えます。文字列は時系列データです(並び順が存在する)。機械翻訳においてRNNは入力単語とその前後の単語との結びつきを考慮するために使われます。
DecoderはEncoderと同様にRNNで構成されますが、RNNの出力はベクトルであるため、確率の形としてsoftmax関数で正規化します。すなわちsoftmax関数で出力された最も高い確率の単語が殆ど翻訳文として採用されます。
Attentionはseq2seqが提案されたよりも後に出てきた機構ですが、近年の系列変換モデルでは使うのが当然ですので、ここではまとめてseq2seqと呼びます。通常のRNNは系列データが長くなるほど初期の入力がDecoderに伝搬しづらくなるという欠点がありました。何故なら通常、EncoderからDecoderへの伝搬は最後の状態出力のみを使うからです。
入力系列${x_1, ... , x_I}$に対して各時刻で符号化されたベクトル${h_1^{(s)}, ... , h_I^{(s)}}$はRNNの遷移関数を$\Psi^{(s)}$とすると次のように再帰的に計算できます。
h_i^{(s)} = \Psi^{(s)}(x_i, h_{i-1}^{(s)})
すなわちDecoderへ伝搬するのは$h_I^{(s)}$であり、長さ$I$の情報が固定長ベクトルに格納されていることになります。
この問題を解決するためにEncoderの各時刻の中間ベクトル(隠れ状態ベクトル)の重み付き平均を計算します。これはsoft attention(ソフト注意機構)と呼ばれます。重み付き平均ではなく、確率に従って見るべき中間ベクトルを選択する方法はhard attention(ハード注意機構)と呼ばれます。その他、local attention(局所注意機構)などがあります。
NMTに関する論文:Neural Machine Translation by Jointly Learning to Align and Translate
NMTの参考資料
- 深層学習による自然言語処理 | 書籍情報 | 株式会社 講談社サイエンティフィク
- 今更ながらchainerでSeq2Seq(2)〜Attention Model編〜 - Qiita
- Seq2Seq+Attentionのその先へ - Qiita
- Attention Seq2Seqで対話モデルを実装してみた – 戦略コンサルで働くデータサイエンティストのブログ
- Deep Learning で使われてる attention ってやつを調べてみた - 終末 A.I.
- NIP2015読み会「End-To-End Memory Networks」
近年の機械翻訳
近年のNLPは、RNNベースからAttentionをベースとしたモデルが大きな成果を上げています。TransformerはAttention Is All You Needという一見面白いタイトルがついていますが、後のSOTA合戦に大きな影響を与えました。TransfomerについてはRyobotさんの資料が本当にわかりやすいです:論文解説 Attention Is All You Need (Transformer) - ディープラーニングブログ
2018年ではTransformerをベースとしたBERTが登場し、多くのタスクでSOTAを達成しました。…かと思いきや、先月登場したXLNetが20のタスクでBERTのスコアを上回ったため、NLP界隈は大変盛り上がっています。
ただしこれらのSOTAモデルの学習には大資源が必要であるため(XLNetは512 TPU v3 chips)、KaggleコンペではXLNet〇個、BERT〇個、~のすーぱーアンサンブルモデルを貰って誰が嬉しいのかということも懸念されます。
今後の機械翻訳にどう影響していくのか、楽しみですね。