こんにちにゃんです。
水色桜(みずいろさくら)です。
今回は世界最高精度を達成した言語モデルLUKEを用いて感情分析を行っていきたいと思います。
目標としては、48の感情(喜怒哀楽、悲、落胆など)の内どの感情が含まれているかを判定できるモデルの作成を行いたいと思っています。
2022年12月27日追記:LUKEをファインチューニングして感情分析に用いれるモデルを作成してみました。下記の記事に載せたリンクからモデルをダウンロードできます。LUKEを試してみたいという方はぜひ使ってみてください。
環境
ja-ginza-electra 5.1.0
pandas 1.4.4
numpy 1.23.4
spacy 3.2.4
torch 1.12.1
transformers 4.24.0
Python 3.9.13
LUKE

2020年4月当時、5つのタスクで世界最高精度を達成した新しい言語モデル。
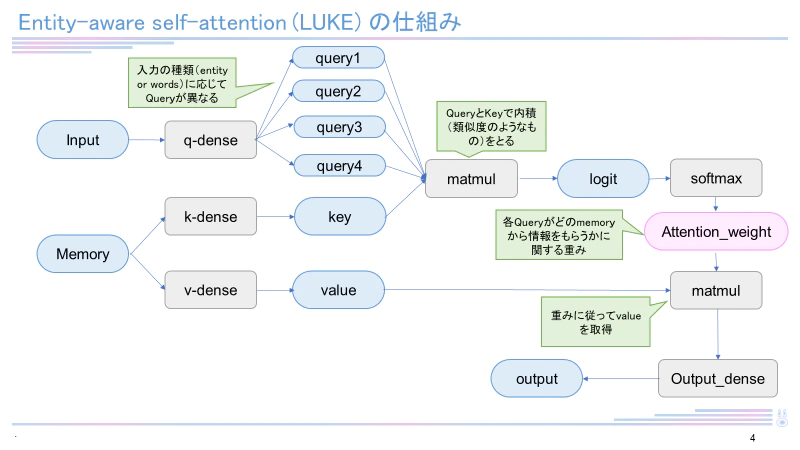
日本語バージョンのLUKEは執筆現在(2022年12月)も4つのタスクで最高スコアを有しています。RoBERTaを元として構成され、entity-aware self-attentionという独自のメカニズムを用いています。LUKEに関して詳しくは下記記事をご覧ください。
データセットの準備
本記事ではまずデータセットを準備します。長岡技術科学大学・言語商会、山本先生の作成された日本語感情表現辞書と言語モデルGiNZAを用いて、
夏目漱石さんの「こころ」(青空文庫)の各文の感情を取得します。これを教師データとしてLUKEのファインチューニングを行います。
夏目漱石さんの「こころ」(青空文庫)をkokoro.txtとして保存します。次に日本語感情表現辞書の各シートをそれぞれ'長岡技術科学大学_被験者1.txt、'長岡技術科学大学_被験者2.txt、'長岡技術科学大学_被験者3.txt、長岡技術科学大学_感情分類.txtとして保存します。
まずGiNZAのインストールを行います。
pip install ja-ginza-electra
make_feel_file.py
import spacy
import re
import statistics as st
nlp = spacy.load('ja_ginza_electra') # GiNZAのロード
text_prov=[]
ids_prov=[]
with open('kokoro.txt',encoding='utf-8') as g1: # テキストファイルの読み込み
g2=g1.read() # テキストファイルを変数に格納
g3=re.split('\n|。',g2) # \nで区切る
for j in range(len(g3)):
doc=nlp(g3[j]) #GiNZAによる入力したテキストの解析
words=[]
sen1=[]
for sent in doc.sents: #文章群の中から文章を一つずつ抽出
for token in sent: #文章の中から形態素を一つずつ抽出
words.append(token.lemma_) # 原形を保存
# 感情辞書を用いて感情を検索
with open('長岡技術科学大学_被験者1.txt',encoding='utf-8') as f:
lines=f.read()
dic=re.split('\t|\n',lines) # \nと\tで分割
for word in words:
for i in range(int(len(dic)/4)):
if word==dic[4*i]: # 感情辞書にその単語があるか検索
sen1.append(dic[4*i+2]) #リストに追加
sen2=[]
with open('長岡技術科学大学_被験者2.txt',encoding='utf-8') as f:
lines=f.read()
dic=re.split('\n|\t',lines)
for word in words:
for i in range(int(len(dic)/4)):
if word==dic[4*i]:
sen2.append(dic[4*i+2])
sen3=[]
with open('長岡技術科学大学_被験者3.txt',encoding='utf-8') as f:
lines=f.read()
dic=re.split('\n|\t',lines)
for word in words:
for i in range(int(len(dic)/4)):
if word==dic[4*i]:
sen3.append(dic[4*i+2])
sen4=sen1+sen2+sen3 # リストを結合
if bool(sen4)==False: # もしリストが空の場合
sen5='' # 空を返す
else:
sen5=st.mode(sen4) #一番出現回数の多い感情を返す
with open ('長岡技術科学大学_感情分類.txt',encoding='utf-8') as f:
lines=f.read()
dic=re.split('\n',lines) # \nで分割
for p in range(49):
if dic[2*p+1] in sen5:
text_prov.append(g3[j])
ids_prov.append(p)
f=open('kokoro_feel.txt','a',encoding='utf-8')
g=open('kokoro_feel_ans.txt','a',encoding='utf-8')
for i in range(len(text_prov)):
f.writelines(text_prov[i])
f.write('\n')
g.writelines(str(ids_prov[i]))
g.write('\n')
f.close()
g.close()
上記のコードを実行すると、kokoro_feel.txtとkokoro_feel_ans.txtというテキストファイルが出力されます。kokoro_feel.txtは一文ずつ分けられた文章が、kokoro_feel_ans.txtにはその文章に対するラベル(感情の番号)が振られています。以降ではこの二つのファイルを教師データとして学習を行っていきます。
学習
ここから学習を行っていきます。まず学習に用いたファイル全体をtrain.pyに示します。学習を行う際はコピペして使ってみてください。なおコードの作成に当たっては下記記事を参考にしました。
BERTでは基本的に学習済みモデルを利用する為、そのモデルが読み込めるフォーマットにデータを変換する必要があります
具体的には、以下の4つ手続きが必要になります
1. BERT Tokenizerを用いて単語分割・IDへ変換
学習済みモデルの作成時と同じtokenizer(形態素解析器)を利用する必要がある
日本語ではMecabやJuman++を利用されることが多い
2. Special tokenの追加
文章の最後に[SEP]という単語する
文章のはじめに[CLS]という単語を追加する(分類問題に利用される)
3. 文章の長さの固定
BERTでは全ての文書の長さ(単語の数)を同じにする必要がある(1文章あたりの最大の単語数は512単語)
そこで、Padding/Truncatingを用いて固定長に変換する
Paddingとは、指定した長さに満たない文章を[Pad]という意味を持たない単語の埋める処理
Truncatingとは、指定した長さを超える単語を切り捨てること
4. Attention mask arrayの作成
[Padding]を0、それ以外のTokenを1とした配列
train.py
import numpy as np
with open('kokoro_feel.txt',encoding='utf-8') as f:
f2=f.read()
f3=f2.split('\n')
text_prov=f3[:-1]
with open('kokoro_feel_ans.txt',encoding='utf-8') as g:
g2=g.read()
ids=g2.split('\n')[:-1]
ids_prov=np.zeros(len(ids))
for i in range(len(ids)):
ids_prov[i]=int(ids[i])
MODEL_NAME = "studio-ousia/luke-japanese-base-lite"
from transformers import MLukeTokenizer
import torch
from keras.utils import np_utils
tokenizer = MLukeTokenizer.from_pretrained(MODEL_NAME)
input_ids = []
attention_masks = []
# 1文づつ処理
for sent in text_prov:
encoded_dict = tokenizer.encode_plus(
sent,
add_special_tokens = False, # Special Tokenの追加
max_length = 128, # 文章の長さを固定(Padding/Trancatinating)
pad_to_max_length = True,# PADDINGで埋める
return_attention_mask = True, # Attention maksの作成
return_tensors = 'pt', # Pytorch tensorsで返す
)
# 単語IDを取得
input_ids.append(encoded_dict['input_ids'])
# Attention maskの取得
attention_masks.append(encoded_dict['attention_mask'])
# リストに入ったtensorを縦方向(dim=0)へ結合
input_ids = torch.cat(input_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
labels = torch.tensor(ids_prov)
from torch.utils.data import TensorDataset, random_split
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
# データセットクラスの作成
dataset = TensorDataset(input_ids, attention_masks, labels)
# 90%地点のIDを取得
train_size = int(0.9 * len(dataset))
val_size = len(dataset) - train_size
# データセットを分割
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
print('訓練データ数:{}'.format(train_size))
print('検証データ数: {} '.format(val_size))
# データローダーの作成
batch_size = 32
# 訓練データローダー
train_dataloader = DataLoader(
train_dataset,
sampler = RandomSampler(train_dataset), # ランダムにデータを取得してバッチ化
batch_size = batch_size
)
# 検証データローダー
validation_dataloader = DataLoader(
val_dataset,
sampler = SequentialSampler(val_dataset), # 順番にデータを取得してバッチ化
batch_size = batch_size
)
from transformers import LukeForSequenceClassification, AdamW
# LukeForSequenceClassification 学習済みモデルのロード
model = LukeForSequenceClassification.from_pretrained(
MODEL_NAME, # 日本語Pre trainedモデルの指定
num_labels = 49, # ラベル数
problem_type="multi_label_classification",
output_attentions = False, # アテンションベクトルを出力するか
output_hidden_states = False, # 隠れ層を出力するか
)
# 最適化手法の設定
optimizer = AdamW(model.parameters(), lr=2e-5)
# 訓練パートの定義
def train(model):
model.train() # 訓練モードで実行
train_loss = 0
for batch in train_dataloader:# train_dataloaderはword_id, mask, labelを出力する点に注意
b_input_ids = batch[0]
b_input_mask = batch[1]
b_labels = batch[2]
optimizer.zero_grad()
bb_labels = torch.tensor(np_utils.to_categorical(b_labels, 49))
loss = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=bb_labels).loss
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
train_loss += loss.item()
return train_loss
# テストパートの定義
def validation(model):
model.eval()# 訓練モードをオフ
val_loss = 0
with torch.no_grad(): # 勾配を計算しない
for batch in validation_dataloader:
b_input_ids = batch[0]
b_input_mask = batch[1]
b_labels = batch[2]
bb_labels = torch.tensor(np_utils.to_categorical(b_labels, 49))
with torch.no_grad():
loss = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=bb_labels).loss
val_loss += loss.item()
return val_loss
# 学習の実行
max_epoch = 10
train_loss_ = []
test_loss_ = []
for epoch in range(max_epoch):
train_ = train(model)
test_ = validation(model)
train_loss_.append(train_)
test_loss_.append(test_)
print(str(epoch+1)+'回目終了')
print(test_loss_)
torch.save(model, 'C:Users\\[My_luke_model.pthのあるディレクトリ]\\My_luke_model.pth')
print('finished')
以下train.pyの説明です。
まずファイルから文字列とラベルを取り出します。
import numpy as np
with open('kokoro_feel.txt',encoding='utf-8') as f:
f2=f.read()
f3=f2.split('\n')
text_prov=f3[:-1]
with open('kokoro_feel_ans.txt',encoding='utf-8') as g:
g2=g.read()
ids=g2.split('\n')[:-1]
ids_prov=np.zeros(len(ids))
for i in range(len(ids)):
ids_prov[i]=int(ids[i])
一つ一つ文章をトークン化していきます。その際、128トークンに満たない部分はPADDINGで埋めます。
# 1文づつ処理
for sent in text_prov:
encoded_dict = tokenizer.encode_plus(
sent,
add_special_tokens = False, # Special Tokenの追加
max_length = 128, # 文章の長さを固定(Padding/Trancatinating)
pad_to_max_length = True,# PADDINGで埋める
return_attention_mask = True, # Attention maksの作成
return_tensors = 'pt', # Pytorch tensorsで返す
)
データローダーを定義していきます。データローダーはdatasetsからバッチごとに取り出すことを目的に使われます。
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
print('訓練データ数:{}'.format(train_size))
print('検証データ数: {} '.format(val_size))
# データローダーの作成
batch_size = 32
# 訓練データローダー
train_dataloader = DataLoader(
train_dataset,
sampler = RandomSampler(train_dataset), # ランダムにデータを取得してバッチ化
batch_size = batch_size
)
# 検証データローダー
validation_dataloader = DataLoader(
val_dataset,
sampler = SequentialSampler(val_dataset), # 順番にデータを取得してバッチ化
batch_size = batch_size
)
ファインチューニングをしていきます。
# 最適化手法の設定
optimizer = AdamW(model.parameters(), lr=2e-5)
# 訓練パートの定義
def train(model):
model.train() # 訓練モードで実行
train_loss = 0
for batch in train_dataloader:# train_dataloaderはword_id, mask, labelを出力する点に注意
b_input_ids = batch[0]
b_input_mask = batch[1]
b_labels = batch[2]
optimizer.zero_grad()
bb_labels = torch.tensor(np_utils.to_categorical(b_labels, 49))
loss = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=bb_labels).loss
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
train_loss += loss.item()
return train_loss
# テストパートの定義
def validation(model):
model.eval()# 訓練モードをオフ
val_loss = 0
with torch.no_grad(): # 勾配を計算しない
for batch in validation_dataloader:
b_input_ids = batch[0]
b_input_mask = batch[1]
b_labels = batch[2]
bb_labels = torch.tensor(np_utils.to_categorical(b_labels, 49))
with torch.no_grad():
loss = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=bb_labels).loss
val_loss += loss.item()
return val_loss
# 学習の実行
max_epoch = 10
train_loss_ = []
test_loss_ = []
for epoch in range(max_epoch):
train_ = train(model)
test_ = validation(model)
train_loss_.append(train_)
test_loss_.append(test_)
print(str(epoch+1)+'回目終了')
実行
以下のコードで実行します。
feel_analysis.py
import torch
import re
from transformers import MLukeTokenizer
tokenizer = MLukeTokenizer.from_pretrained('studio-ousia/luke-japanese-base-lite')
model = torch.load('C:\\Users\\[My_luke_model.pthのあるディレクトリ]\\My_luke_model.pth')
with open ('長岡技術科学大学_感情分類.txt',encoding='utf-8') as f:
lines=f.read()
dic=re.split('\n',lines) # \nで分割
i=0
while i<3:
print('システム:ファインチューニングしたLUKEを用いて感情を分析します')
print('システム:文章を入力してください')
text=input()
encoded_dict = tokenizer.encode_plus(
text,
return_attention_mask = True, # Attention maksの作成
return_tensors = 'pt', # Pytorch tensorsで返す
)
pre = model(encoded_dict['input_ids'], token_type_ids=None, attention_mask=encoded_dict['attention_mask'])
num = torch.argmax(pre.logits)
sen=dic[2*num]
print('システム:含まれている感情は'+sen+'です。')
i+=1
実行すると以下のようになります。「楽しい」を嫌悪ととらえてしまうなど、精度としてはまだまだだと感じました。「こころ」だけでなく、もっと多くの文学作品を取り込めばより正確な判定が可能になると思われます(「こころ」だけでも計算量がすごすぎて文章の量を増やす気になれない…>_<)
システム:ファインチューニングしたLUKEを用いて感情を分析します
システム:文章を入力してください
好ましい
システム:含まれている感情は好きです。
システム:ファインチューニングしたLUKEを用いて感情を分析します
システム:文章を入力してください
泣いているようでもあった
システム:含まれている感情は嫌悪です。
システム:ファインチューニングしたLUKEを用いて感情を分析します
システム:文章を入力してください
楽しい
システム:含まれている感情は嫌悪です。
終わりに
LUKEを用いて感情分析を行う方法について書いてきました。結果としてはまだまだ実用に足るレベルには程遠いという感じでした(スーパーコンピュータがほしいです…>_<)
今後の展望としては、学習用の文章数を増やす、感情ごとに偏りのないデータセットを構築するなどが挙げられます。
LUKEを用いて感情分析を行った例は今のところほかにないため、これを機に増えていってくれたらいいなぁと思いました。
LUKEは高性能な言語モデルのわりにまだ浸透してない感じがあるので、LUKEの布教にもなればなぁと思います。
追伸
スーパーコンピュータが欲しい、スーパーコンピュータが欲しい、スーパーコンピュータが欲しい(大事なことなので3回言いました)
参考
著者である山田先生には感謝いたします