はじめに
本記事では、Databricks の外部 BIサービングレイヤー として Snowflake を活用するケースを例に、Databricks の Delta Lake UniForm を使用して Icebergフォーマット で作成したテーブルを Snowflake から直接参照するための設定方法(AWS環境)と、そのメリットについて解説します。
この連携により、Databricks の強力な ETL、AI、BI、機械学習、および ストリーミング分析機能 と、Snowflake の SQL によるシンプルかつ柔軟なデータ分析能力を最大限に活用することで、より効率的でコスト効果の高い データ分析基盤 を構築できます。
Delta Lake UniFormとは?
Delta Lake UniForm は、データレイクハウスの相互運用性を向上させる革新的な機能です。
大規模なデータセットを効率的に管理するための代表的なオープンテーブルフォーマットである Delta Lake、Apache Iceberg、および Apache Hudi に対応し、単一のデータファイルから各フォーマットのメタデータを自動的に生成します。これにより、Snowflake をはじめとする、これらのフォーマットに対応した製品とのシームレスな相互運用性を実現します。
参考リンク:https://www.databricks.com/jp/product/delta-lake-on-databricks
以下は、外部BIサービングレイヤー として Snowflake を活用した、Databricks と Snowflake の代表的な連携アーキテクチャの例です。

Delta Lake UniFormの特徴とメリット
-
マルチフォーマット対応によるベンダーロックインの回避
Deltaテーブルを Iceberg や Hudi クライアントから直接読み取ることができ、異なるデータプラットフォームやツール間でのデータ共有が容易になり、ベンダーロックインを回避可能 -
単一データ管理によるコストの削減
データの冗長な保存を排除しストレージコストを最適化。さらに、Databricks の高速かつ高機能なETL機能を活用しつつ、Snowflakeへのデータロードコストの削減が可能 -
メタデータ同期の自動化とクエリパフォーマンスの向上
メタデータ同期を有効化すると、データ変更時に自動でメタデータが更新され、Liquid Clustering などの Databricks の高度な最適化技術により、Snowflake 側での最適化やチューニングが不要になり、高速かつ最新のデータにアクセスできます。 -
信頼性とガバナンス
Unity Catalogとの統合により、連携するデータエコシステムのデータのガバナンスやセキュリティが強化されます。
Delta Lake UniFormは、Delta LakeテーブルをApache Iceberg/Hudiクライアントから読み取り可能にする機能です。
本記事で取り上げたSnowflake以外にもTrino, Presto, Spark, Hive, Flink, Impalaなど、様々なクエリエンジンからIceberg/Hudiテーブルにアクセスすることを可能にします。
Delta UniFormによる連携方法の概要
Snowflake から Databricks で作成した Iceberg テーブルを直接参照するための設定方法を紹介します。
作業の概要は以下の通りです。
Databricks側の設定
- ステップ1:Unity Catalogで管理されたDeltaテーブルにUniFormを有効化
- ステップ2:Snowflakeからの接続に使用する認証情報を生成
Snowflake側の設定
- ステップ1:カタログ統合を作成
- ステップ2:外部ボリューム(S3バケット)を登録
- ステップ3:Snowflakeで外部Icebergテーブルを作成
設定コマンドの具体例
以下、具体的なコマンド例と考慮すべきポイントについて説明します。
Databricks側の設定
ステップ1:Unity Catalogで管理されたDeltaテーブルにUniFormを有効化
Databricksのテーブルは、内部テーブル(マネージドテーブル)または外部テーブル(アンマネージドテーブル)として作成できます。
以下のように、TBLPROPERTIES を使用して UniForm を有効化してください。
参考リンク:https://docs.databricks.com/aws/ja/delta/uniform
CREATE TABLE customer_dbx (
C_CUSTKEY int,
C_NAME varchar(25),
C_ADDRESS varchar(40),
C_NATIONKEY int,
C_PHONE varchar(15),
C_ACCTBAL decimal(15,2),
C_MKTSEGMENT varchar(10),
C_COMMENT varchar(117)
)
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
);
内部テーブル(マネージドテーブル)として作成すると、UniFormテーブルに対しても Databricks のさまざまな最適化機能が適用されます。
また、Snowflake アカウントから S3ストレージ へのダイレクトアクセスが実行されるため、 セキュリティ上、必要に応じてテーブルを作成する カタログ または スキーマ には、Delta UniForm専用の S3ボリューム(外部ロケーション) を割り当てておくと良いでしょう。
ステップ2:Snowflakeからの接続に使用する認証情報を生成
Snowflake からの接続に使用するユーザーの Token またはサービスプリンシパルの OAuthシークレット を作成してください。
これらのいずれかの認証情報を、Snowflake でのカタログ統合作成時に指定します。
また、使用するユーザーまたはサービスプリンシパルには、適切なテーブルデータの参照権限(USE CATALOG、USE SCHEMA、SELECT など)を付与しておいてください。
参考リンク:https://docs.databricks.com/aws/ja/dev-tools/auth/pat
参考リンク:https://docs.databricks.com/aws/ja/dev-tools/auth/oauth-m2m
サービスプリンシパルは、自動化ツールやスクリプトに対して API専用のアクセス権 を提供し、ユーザーアカウントを使用する場合よりも 優れたセキュリティ を実現します。
Snowflake側の設定
ステップ1:カタログ統合を作成
UniFormを有効化したテーブルは、Iceberg REST を介してアクセス可能です。
Snowflake にカタログ統合を作成することで、Iceberg REST を通じて最新のメタデータロケーションを自動的に取得し、常に最新のデータへのアクセスを可能にします。
参考リンク:https://docs.snowflake.com/ja/sql-reference/sql/create-catalog-integration-rest
CREATE OR REPLACE CATALOG INTEGRATION uniform_catalog
CATALOG_SOURCE = ICEBERG_REST
TABLE_FORMAT = ICEBERG
CATALOG_NAMESPACE = 'iceberg_db' <-- DatabricksのUCスキーマ名を指定
REST_CONFIG = (
CATALOG_URI = 'https://<workspace-url>/api/2.1/unity-catalog/iceberg',
WAREHOUSE = 'uniform_catalog' <-- DatabricksのUCカタログ名を指定
)
REST_AUTHENTICATION = (
TYPE = BEARER <-- ユーザToken認証の例:サービスプリンシパルnのOAuthもサポート
BEARER_TOKEN = '<DatabricksのユーザToken>'
)
ENABLED = TRUE;
ステップ2:外部ボリューム(S3バケット)を登録
Snowflake から Databricks の UniForm テーブルが格納されている S3 を対象に、外部ボリュームを登録し、特定の S3バケット へのアクセス権限を付与します。
これにより、Snowflake は必要なデータのみにアクセスできるため、セキュリティ と データガバナンス の両方が向上します。
参考リンク:https://docs.snowflake.com/ja/user-guide/tables-iceberg-configure-external-volume-s3
create or replace external volume databricks_catalog_volume
storage_locations =
(
(
name = 'databricks_catalog_volume'
storage_provider = 's3'
storage_base_url = 's3://xxxxx/yyy/' <--Uniformテーブルに割り当てたS3ボリューム
storage_aws_role_arn = 'arn:aws:iam::xxxx:role/yyyy' <--S3アクセス用AIMロール
storage_aws_external_id = 'iceberg_table_external_id'<--IAMロールに関連付けられた外部ID
)
);
ステップ3:Snowflakeで外部Icebergテーブルを作成
上で作成した カタログ統合 と 外部ボリューム を指定し、CREATE ICEBERG TABLE コマンドを使用してIcebergテーブル を作成します。
自動リフレッシュを有効にした場合、外部 Icebergカタログ(UnityCatalog) をポーリングするインターバルはデフォルトで 30秒 です。
参考リンク:https://docs.snowflake.com/ja/user-guide/tables-iceberg-create
USE ICEBERG_DB;
CREATE OR REPLACE ICEBERG TABLE customer_dbx
EXTERNAL_VOLUME = 'databricks_catalog_volume' <-- 上で指定した外部ボリューム
CATALOG = 'uniform_catalog' <-- 上で指定したカタログ統合
CATALOG_TABLE_NAME = 'customer_dbx' <-- 参照するDatabricksのUniformテーブル名
CATALOG_NAMESPACE = 'iceberg_db' <-- Databricksのスキーマ名
;
-- 手動リフレッシュする場合
ALTER ICEBERG TABLE customer_dbx REFRESH;
-- 自動リフレッシュを有効にする場合
ALTER ICEBERG TABLE customer_dbx SET AUTO_REFRESH = TRUE;
CREATE ICEBERG TABLE コマンドではカタログ統合により、CREATE EXTERNAL TABLEコマンドのようにLOCATION句で外部テーブル毎に固有の物理ストレージパスを指定する必要がありません。カタログ名、スキーマ名、テーブル名による論理的な名前解決が可能なためテーブルの管理が非常に容易になります。
SnowflakeからDatabricksのUnifromテーブルへのアクセス
上記の設定が完了すると、Snowflake では通常の外部テーブルと同様に、SELECT 文を使用して UniFormテーブル にアクセスできます。
以下のようにSnowflakeのカタログに作成したIcebergテーブルがリストされます。

外部カタログ統合で作成したIcebergテーブルはREAD-ONLY (読み取り専用) であり、Snowflake側からのINSERT、UPDATE、DELETE などのDML操作はサポートされません。
Unifromテーブルへのチューニング効果を確認
UniFormテーブル において、Databricks 側で実施したチューニングが Snowflake からのアクセスでも有効に作用するかを確認します。
ここでは、Databricks のパフォーマンス最適化機能の一つである Liquid Clustering の設定によって、Snowflake からのクエリ実行時に物理I/Oの削減による処理時間の短縮が可能かを簡単に検証しました。
- Snowflakeのスペック:X-Small
Liquid Clustering設定前
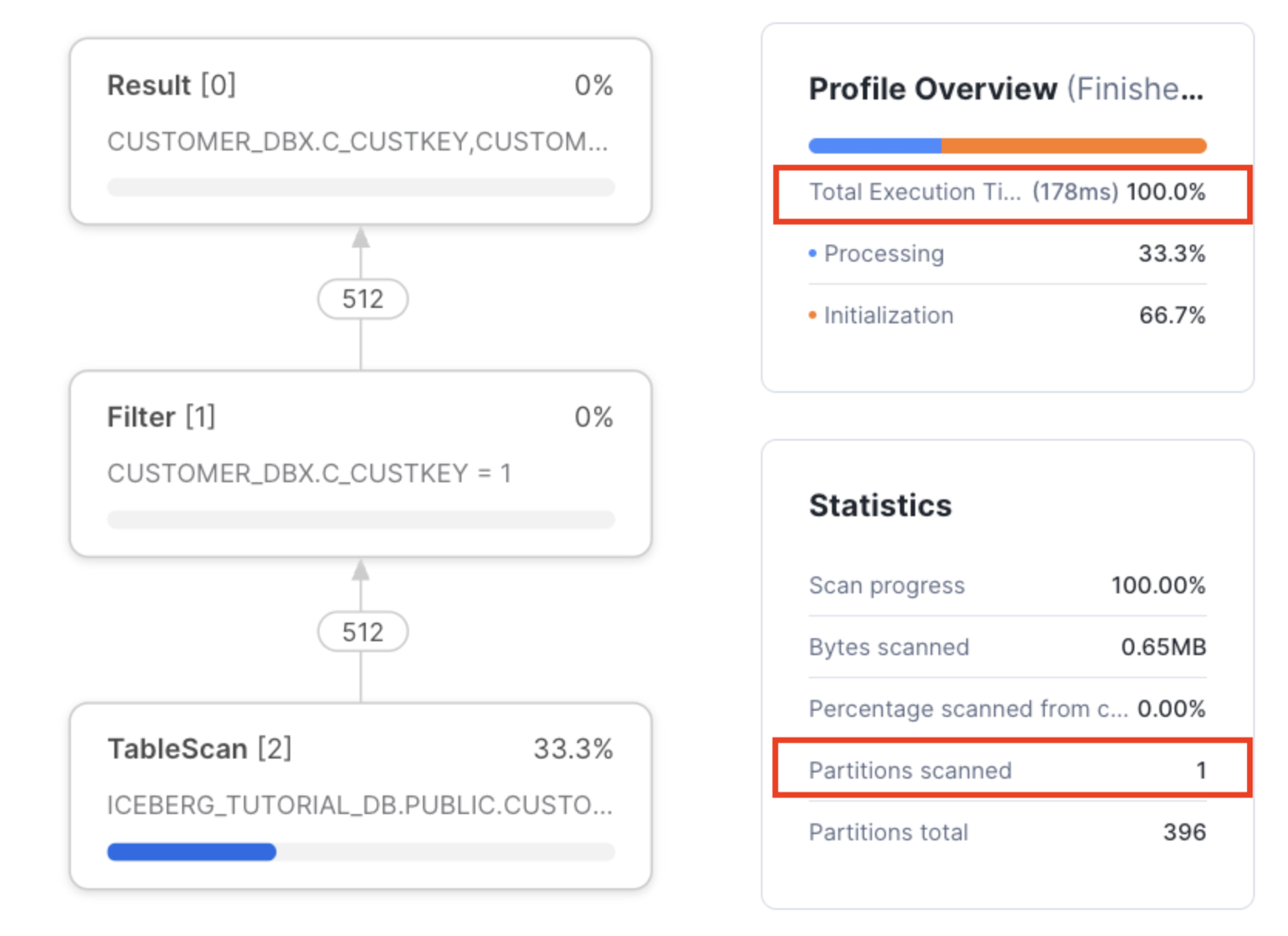
Snowflakeでのクエリの実行時間は16秒、パーティションのスキャン数は232でした。

Liquid Clustering設定後
以下のように、Snowflakeで実行するクエリに合わせてDatabricks 側でテーブル物理配置の最適化を実行します。
alter table customer_dbx cluster by (C_CUSTKEY);
optimize customer_dbx;
Snowflake でのクエリ実行時間は 0.178秒、パーティションのスキャン数は 1 と、大幅に改善されました!
DatabricksとSnowflakeが同じ物理ファイルのIcebergテーブルを参照することで、Snowflake側でのチューニング作業を行わなくても、常に最適化された状態でデータにアクセスできます。
Delta Lake UniFormにより、異なるプラットフォーム間で効率的なデータ共有が可能となり、一貫したパフォーマンスと管理コストの削減が実現できます。
Delta Lake UniFormでもDatabricksの自動チューニング機能である予測最適化機能が有効です。Databricksが以下の操作を自動的に行いメンテナンス操作を手動で管理する必要がなくなります。
1.各種メンテナンス操作が必要なテーブルを特定し、これらの操作をキューに入れて実行します。
2.テーブルにデータが書き込まれるたびに自動で統計情報を収集します。
さいごに
本記事では、Databricks の Delta UniForm を使用して Icebergフォーマット で作成したテーブルを Snowflake から直接参照する方法と、そのメリットについてご紹介しました。
今後の データ駆動型ビジネス において、このような異なる プラットフォーム間の相互運用性 の向上は、ますます重要となるでしょう。