はじめに
新年あけましておめでとうございます。
つい先日気絶して緊急搬送されてました。Mikanerです。
さて、皆さんは強化学習というものを御存じでしょうか?
...あ、知ってる?名前だけなら?
結構。いい情報がありますよ。
自然言語の方で有名なTransformerを強化学習に応用するモデルとかも出てきたりして、それなりに発展しているような気がしますね。
まあ大体DeepmindさんかOpenAIさんがいるんですけど!
マジリスペクト。
強化学習ってなに
いっぱい情報あるからそこまで触れるほどじゃないけど一応。
いわゆるAIという分野に入ってくるわけですが、その中でも実行してほっとけば勝手に学習していってくれるようなやつのことです。
Agentと呼ばれるキャラクターのモデルと、StageだのEnvironmentだの呼ばれる学習環境のモデル、キャラクターを動かすBrainとか呼ばれる学習機によって構成されていれば大体強化学習です。
ちなみにBrainがAgentに入ってて書かれていない場合もあります。
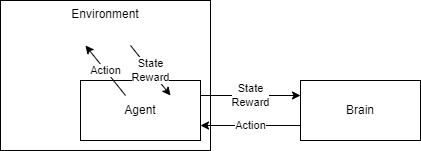
なるほど????
まあ簡単に言うと、ゲームとプレイヤーを選んで学んでいく経過を楽しむお遊びとか思っていただけるのがわかりやすいかと。
突き詰めると実世界に有用な研究になれます。
環境の種類
さて、そんな強化学習の環境ですが、割といろいろあります。
2Dレトロゲームであったり、3Dゲームだったり、自分で環境モデルやらゲームやら作れたりします。
- OpenAI Gym
- Atari
- Gym Retro
- Mujoco
- robotics
- PGE : parallel game engine
- gym-city
- gym-gazebo
- gym-miniworld
- gym-donkeycar
- gym-duckietown
- GymFC
- GEM : Gym Electric Motor
- PyBullet
- Unity ML-Agents
- AnimalAI
- Obstacle tower
- MarLO
- PySC2
- その他もろもろ
大体OpenAI Gymを通して実装されています。
Mujocoは2021年夏までは有料でしたが、なんかDeepMind社が買い取ってOSS化したおかげで無料で扱えるようになりました。
最高か?![]()
ちなみに環境によってはもともと用意されている学習機があったりします。
Mujocoのコラム
Mujocoが無料化したからってインストールしようと思って少しはまったのでここに書いておきます。
2.1.0以降のバージョンはライセンスキーが必要ないです。
それ以前のライセンスキーはRoboti LLCのサイトで入手できます。
ライセンスキーの場所わからんくてgithubの方探してたのが悪い。
pipで入れたmujocoのバージョンが古かったのも悪い。
学習機のライブラリの種類
ライブラリも多種多様です。それぞれ実装されているアルゴリズムが違ったりしますが、前々から有名なものはある程度揃っているはずです。
え?実装されてないやつが使いたい?
論文の著者がGithubに公開してるんじゃないかな。
あるいは自分で実装するんだよ。
まあ、実装されているパッケージを探した方が早い場合もあります。
ここが詳しい
Top 20 Reinforcement Learning Libraries You Should Know
学習機の種類
星の数ほど出てきます。気になったのを使えばいいです。
論文ようわからん、解説記事意味不明だったら実際に動かして「この動きっ!気に入ったぁ!!」ってやつでもいいと思います。趣味であれば。
ちなみに現在の主流はPPOあたりみたいですね。使いやすいそうです。
環境整備(Google Colaboratoryの場合)
少しやっていきます?
いいでしょうとも。
Pythonは持ちましたか?
では仮想環境の準備は?
Google Colaboratoryでやる?
OK,そしたらGoogle Colaboratoryにいろいろ設定しましょう。
!apt -q update > /dev/null
!apt-get -qq -y install libcusparse8.0 libnvrtc8.0 libnvtoolsext1 > /dev/null
!ln -snf /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so.8.0 /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so
!apt -qq install xvfb freeglut3-dev ffmpeg> /dev/null
!pip -q install gym
!pip -q install JSAnimation
!pip -q install pyglet
!pip -q install pyopengl
!pip -q install pyvirtualdisplay
!pip -q install stable-baselines3[extra]
from pyvirtualdisplay import Display
display = Display(visible=0, size=(1024, 768))
display.start()
import os
os.environ["DISPLAY"] = f":{display.display}"
from JSAnimation.IPython_display import display_animation
from matplotlib import animation
from IPython.display import HTML
def make_anim(frames):
plt.figure(figsize=(frames[0].shape[1]/72.0, frames[0].shape[0]/72.0),
dpi=72)
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames),
interval=50)
return anim
def play_anim(frames):
return make_anim(frames).to_jshtml()
def save_frames_as_gif(frames, filename : str):
"""
DISPLAYs a list of frames as a gif, with controls
"""
anim = make_anim(frames)
anim.save(filename+'.mp4')
return anim.to_jshtml()
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import gym
OpenAI Gymを動かす
こちらのコードでランダムに動かすCartPoleが動かせます。
frames = []
env = gym.make("CartPole-v1")
env.reset()
for step in range(0, 200):
frames.append(env.render(mode='rgb_array'))
env.step(env.action_space.sample())
env.close()
再生はこうです。
HTML(play_anim(frames))
# HTML(save_frames_as_gif(frames, 'movie_cartpole_DQN')) # gifとして保存したいならこっち
動きました?
軽く説明
gym.make(環境ID) : 環境を設定。環境IDは以下のコードで確認できる。
from gym import envs
for e in envs.registry.all():
print(e.id)
Google Colaboratoryはもともと結構入ってますねぇ...
env.reset() : 初期化
env.render(mode=モード) : レンダリング。以下のモードがあります
| モードID | 説明 |
|---|---|
| human | 人間にやさしい(ディスプレイに描画)。 Google Colabじゃディスプレイが出てこないので使えない |
| rgb_array | ピクセル画像のRGBを戻り値として返す。 今回はこれをHTML形式で描画してJavaScriptで動かす |
| ansi | テキストが戻り値 |
env.action_space.sample() : envの行動コマンドをランダムに返す。CartPoleの場合はnp.random.choice(2)とかでもOK。
env.step(行動) : ステップの実行。行動後の状態、報酬、エピソード完了フラグ、情報が返ってくる。以下のコードの感じで受け取る。
state, reward, done, info = env.step(行動)
とまあそんな感じで
環境変えてみますか。
環境IDを以下の内の適当なものに変えてみましょう。
以下がgymのClassic controlと呼ばれるCartPole-v1と似たような設定で実行できるやつです。
- Acrobot-v1
- MountainCar-v0
- MountainCarContinuous-v0
- Pendulum-v0
他はAtariのRomとかBox2dとかMujocoとか必要になってきたり、そもそも実行形式が違ったりします。
詳しくはこちら
学習
なんとなしにgymの使い方がわかりましたでしょうか?
次は学習機のお時間です。
バージョン確認
とりあえずライブラリが入っているか確認。
import stable_baselines3
stable_baselines3.__version__
ちなみに執筆時のバージョンは1.3.0でした。
学習機作成
では次に学習機を作成します。
今回の環境はCartPole-v1です。
from stable_baselines3 import PPO
env = gym.make("CartPole-v1")
model = PPO("MlpPolicy", env, verbose=1)
これだけ。
学習
学習させましょうか。
model.learn(total_timesteps=10000)
これだけ。
結果観測
学習した結果を見てみましょう。
frames = []
obs = env.reset()
for i in range(1000):
action, _states = model.predict(obs) # モデルの推論
obs, rewards, dones, info = env.step(action)
frames.append(env.render(mode='rgb_array'))
if dones:
print("Done in {} frame.".format(i))
break
env.close()
HTML(play_anim(frames))
どうでした?インテリジェンス感じました?
以上
PPOとかポリシーとかの説明や改良とかした方がいいかなとは思いますが今回はこの辺で。
Stable Baselilnes3のチュートリアルに改良とかいろいろ乗ってるのでご参考程度に。
Stable Baselines3 Tutorial - Getting Started
あるいは
__________________________________________________________
|$(gymのステージ名) $(学習アルゴリズム名) |検索|
¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯
とかで検索するのもよいかと。
おい、このコード動かんぞ~とかあればコメントにお願いします。
気づいたら直すか注釈入れるか放置するかなどしておきます。
それでは、良い強化学習ライフを。
参考文献