はじめに
私は化学メーカーの現場で技術開発を行っています。
これまで業務の一環で、部署の実験データを集約するデータベースの構築にも関わりました。
また、実際の自己研鑽で「東野圭吾さんの書籍をデータベースにする」記事を投稿しており、まだの方はぜひこちらもご覧ください。
No.1 https://qiita.com/MicroCheese/items/8acb216d4831b4fa7f1c
No.2 https://qiita.com/MicroCheese/items/8df6a08b02ce1ca47832
今回も、前回にひきつづきこの東野圭吾DBを題材にして、既存のデータベースに後からテーブルを追加する方法を勉強していきます。
(自分の学びの備忘録も含んでいます)
どんなテーブルを追加するのか
私が東野圭吾さんの本を読む中で、以前読んだ作品をもう一度読むことがよくあります。
これまでのデータベースでは、そのような再読情報を記録する仕組みがありませんでした。
そこで、新しくテーブルを追加することで再読情報を残せるようにしましょう。
アンチパターン
ここまでの内容から、もしかすると以下のような解決法を思いついた方もいるかもしれません。
書籍情報のあるKH_booksのテーブルに、「1回目再読」「2回目再読」とカラムを横に付け加えていく方法です。

もちろん、これでも不可能ではないですが
- 準備した再読記録カラム以上に再読した場合、またカラム追加をしなくてはならず、面倒である(前回記事参照)
- 再読記録用カラムをたくさん作ってしまうと、テーブルが不必要に大きくなってしまう
ことからナンセンスと考えます。
そこで、新しくテーブルを作ってこの問題を解決することを考えましょう。
どのようなテーブルを作ればよいか(① ERDを修正しよう)
新しく作ったERDはこちらになります。
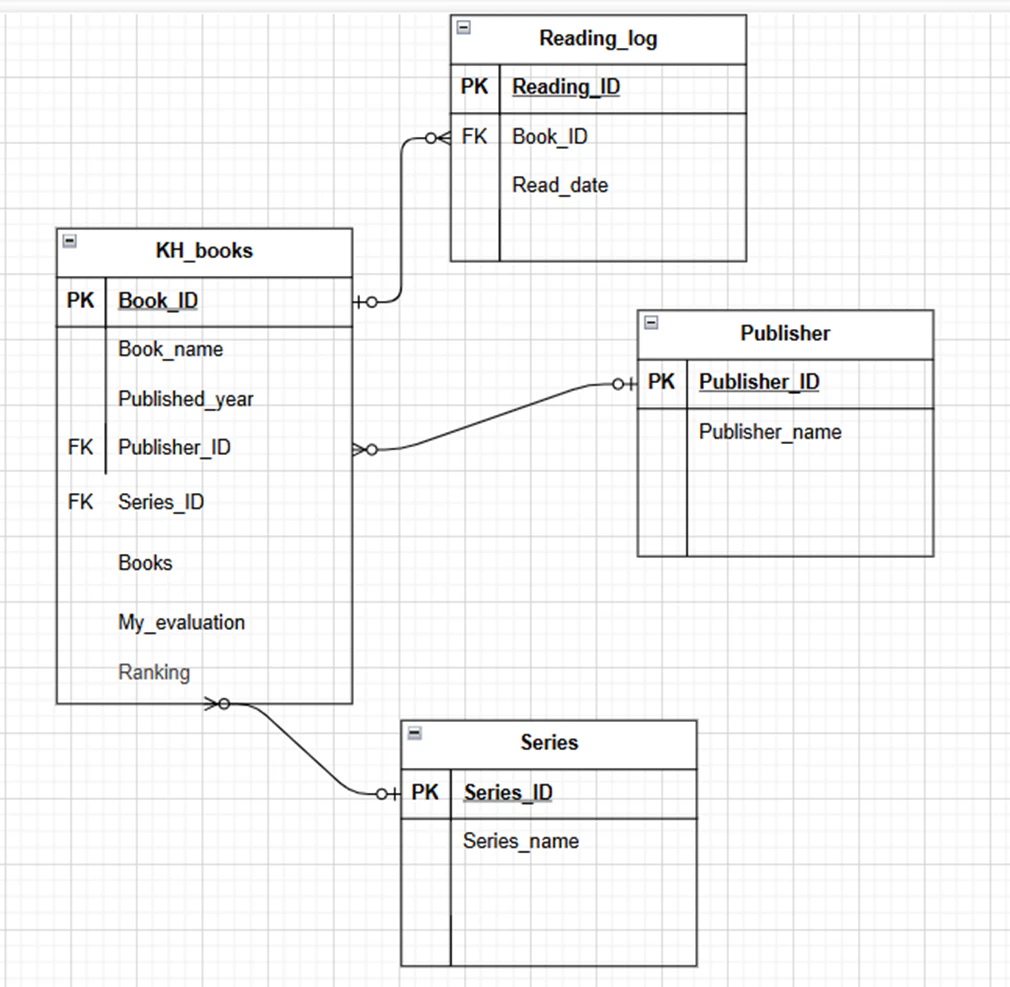
新しく、読書履歴を記録するreadoing_logというエンティティを作りました。
-
reading_id:読書履歴を一意に識別するID -
book_id:どの本を読んだかを表すID -
read_date:読んだ日付
ポイントは、書籍そのものの情報は kh_books に残し、「いつ読んだか」という読書履歴は reading_log に分けて管理することです。
こうすることで、同じ本を2回、3回と読んでも異なるreading_IDで登録されるため、テーブルを横ではなく縦に伸ばすことができます。
また、SQLで各作品を何回読んだのかを集計することも可能です。
このERDをもとに、DBを修正していきましょう。
データベースにテーブルを追加するには
① ERDを修正する(すでに実施済)
② Excelデータを修正する
③ DDLを修正する
④ データベースにテーブルを追加する
⑤ ETLプログラムを修正し、実行する
⑥ データベースを確認・可視化する
という順番で行います。
お察しの通り、カラム追加の際とやるべきことはとても似ています。
次項より、②から始めてみましょう。
② Excelデータを修正する
すでに東野圭吾さんの書籍DBに使用しているExcelに、「Reading_log」というシートを準備し、そこにテーブルを作って読書履歴を記録していきます。

ポイントは、データベースのカラム名と、Excelシートのカラム名を合わせておくことです。
これにより
- ETL処理(CSV → DB)のコードがシンプルになる
- カラム対応ミスを防げる
といったメリットがあります。
また、データベースには投入する予定はないですが、念のため備考欄を設けています。
例えば、基本的にRead_dateはブクログや自分のXの読書記録をさかのぼって記録しましたが、どうしてもさかのぼれなかったものはその旨を備考に記載しています。
さらに、今回reading_idはSERIAL型(自動採番)として扱うため、Excel上では記載していません。
SERIAL型とは、データを追加するたびに自動で連番を振ってくれる仕組みです。
データベース側で自動処理を行うことで、
- 手動でIDを考える必要がない
- 主キーの重複ミスを防げる
という利点があります。
③ DDLを修正する
前回に引き続き、今回もDDLを修正しましょう。
以下のようなコードをDDLに追加しました。
-- reading log (1 row = 1 reading record)
CREATE TABLE IF NOT EXISTS reading_log (
reading_id SERIAL PRIMARY KEY,
book_id TEXT NOT NULL,
read_date DATE NOT NULL,
CONSTRAINT fk_reading_log_book
FOREIGN KEY (book_id)
REFERENCES kh_books(book_id)
);
CREATE INDEX IF NOT EXISTS idx_reading_log_book_id
ON reading_log(book_id);
・ポイント①:SERIALで自動採番
上記からもわかる通り、reading_idをSERIALにしています。
・ポイント②:外部キーでテーブル同士をつなぐ
FOREIGN KEY (book_id)
REFERENCES kh_books(book_id)
「reading_logに存在するbook_idは、必ずkh_booksに存在していなければならない」
というルールを定義しています。
・ポイント③:インデックスで検索を高速化
最後の3行は、book_idで検索する際の処理を高速化するための設定です。
例えば、今後のSQLでのSELECT文における
SELECT *
FROM reading_log
WHERE book_id = 'KH_001';
のようなクエリが速く実行されるようになります。
④ データベースにテーブルを追加する
DBeaverのSQLエディタで、以下を実行します。
CREATE TABLE IF NOT EXISTS reading_log (
reading_id SERIAL PRIMARY KEY,
book_id TEXT NOT NULL,
read_date DATE NOT NULL,
CONSTRAINT fk_reading_log_book
FOREIGN KEY (book_id)
REFERENCES kh_books(book_id)
);
実行することにより、新しくreading_logのテーブルが作られたことがわかります。
もちろん、まだデータは入っていません。
⑤ ETLプログラムを修正し、実行する
ETLプログラムを書き換えて実行し、データを入れていきます。
対象テーブル指定の変更
もともとは publisher, series, kh_books だけをロードしていたので、reading_log のCSVができていてもDB投入対象になっていませんでした。
新しいテーブルも入るように、リストを変更していきます。
TARGET_TABLES = ["publisher", "series", "kh_books", "reading_log"]
また、ETLを何度も実行すると、前回のデータが残ったまま追加される可能性があります。
そこで、既存データを削除する処理にも reading_log を追加しました。
def truncate_tables(conn) -> None:
with conn.cursor() as cur:
cur.execute("TRUNCATE TABLE publisher, series, reading_log CASCADE;")
conn.commit()
print("[OK] 既存データをTRUNCATEしました")
CASCADE を付けているため、外部キーで関連しているテーブルのデータもあわせて削除されます。
これで、ETLを再実行しても古いデータが残らず、Excelの内容をもとにデータベースを更新できます。
また、今回のようにExcelとDBで名前が違う列を安全に処理するために、以下の処理を加えることとします。
勉強になりましたら幸いです。
学び①:データベースに不要な列がCSVにあるときの処理
今回追加した reading_log.csv には、もともと以下のような列がありました。
book_id,book_name,read_date,備考
一方で、データベース側の reading_log テーブルは以下の構成です。
reading_id SERIAL PRIMARY KEY,
book_id TEXT NOT NULL,
read_date DATE NOT NULL
つまり、CSVの列とデータベースの列が完全には一致していません。
特に以下の点に注意が必要です。
-
reading_idはデータベース側で自動採番するため、CSVから入れない -
book_nameはkh_booksテーブルにすでにあるため、reading_logには入れない -
備考は今回のテーブルには入れない
そこで、テーブルごとに「どの列をデータベースへ入れるか」を定義しました。
TABLE_COLUMNS = {
"publisher": ["publisher_id", "publisher_name"],
"series": ["series_id", "series_name"],
"kh_books": [
"book_id",
"book_name",
"published_year",
"publisher_id",
"series_id",
"book_type",
"my_evaluation",
"ranking",
],
"reading_log": ["book_id", "read_date"],
}
これにより、reading_log では book_id と read_date だけを投入できます。
学び②:CSVとデータベースの列名が違うときの対応
CSVとデータベースで、列名が少し違うものがありました。たとえばCSV側では、
publisher
series
books_type
となっていましたが、データベース側では以下の列名にしています。
publisher_name
series_name
book_type
このままだと列名が合わないため、ETL側で列名を変換します。
COLUMN_RENAMES = {
"publisher": {"publisher": "publisher_name"},
"series": {"series": "series_name"},
"kh_books": {"books_type": "book_type"},
}
なお、reading_log の日付列はデータベース側も read_date にしたため、変換は不要です。
学び③:データベースに入れる前に列を整える
CSVをそのまま入れるのではなく、投入前に列名や列順を整える関数を追加しました。
def prepare_for_table(df: pd.DataFrame, table_name: str) -> pd.DataFrame:
df = df.rename(columns=COLUMN_RENAMES.get(table_name, {}))
required_columns = TABLE_COLUMNS[table_name]
missing_columns = [col for col in required_columns if col not in df.columns]
if missing_columns:
raise ValueError(
f"{table_name} に必要な列がCSVにありません: {missing_columns}"
)
df = df[required_columns].copy()
if "read_date" in df.columns:
df["read_date"] = pd.to_datetime(
df["read_date"], errors="coerce"
).dt.date
return df
この関数では、主に以下を行っています。
- CSVの列名をデータベースの列名に合わせる
- データベースに入れる列だけを残す
- 列順をそろえる
-
read_dateを日付として扱える形に変換する
必要な列がCSVにない場合はエラーにすることで、Excel側の列名変更にも気づきやすくなります。
学び④:CSV出力前に整形処理を呼び出す
Excelシートを読み込んだあと、CSVに書き出す前に prepare_for_table() を通します。
actual_sheet_name = sheet_map[table]
df = read_excel_sheet(XLSX_PATH, actual_sheet_name)
df = prepare_for_table(df, table)
csv_path = CSV_DIR / f"{table}.csv"
df.to_csv(csv_path, index=False, encoding="utf-8")
これにより、出力されるCSVもデータベース投入用の形になります。
たとえば reading_log.csv は以下のようになります。
book_id,read_date
KH_001,2025-02-20
KH_002,2023-02-13
KH_003,2024-01-29
学び⑤:COPY時に投入する列を指定する
もともとは、以下のようにテーブル名だけを指定してCSVをロードしていました。
cur.copy_expert(
f"COPY {table_name} FROM STDIN WITH CSV HEADER",
f
)
しかしこの書き方だと、CSVの値をデータベースの全列に順番通り入れようとします。
reading_log には reading_id という自動採番の列があります。
この列にはCSVから値を入れたくないため、投入する列を明示します。
def load_csv(conn, table_name: str, csv_path: Path) -> None:
columns = ", ".join(TABLE_COLUMNS[table_name])
with conn.cursor() as cur:
with open(csv_path, "r", encoding="utf-8") as f:
cur.copy_expert(
f"COPY {table_name} ({columns}) FROM STDIN WITH CSV HEADER",
f
)
conn.commit()
print(f"[OK] {table_name} にロードしました")
reading_log の場合、実行されるSQLは以下のようになります。
COPY reading_log (book_id, read_date) FROM STDIN WITH CSV HEADER
これで reading_id はCSVから入れず、データベース側で自動採番できます。
⑥ データベースを確認・可視化する
ETLをVSCodeで実行したら、DBeaverで確認しましょう。
reading_logのテーブルを開くと、データが入っていることを確認できました。
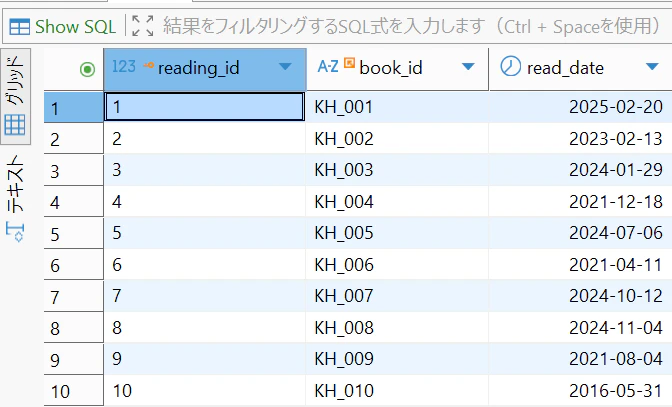
また、これだけではわかりにくいので、見やすく可視化してみましょう。
JOINで可視化
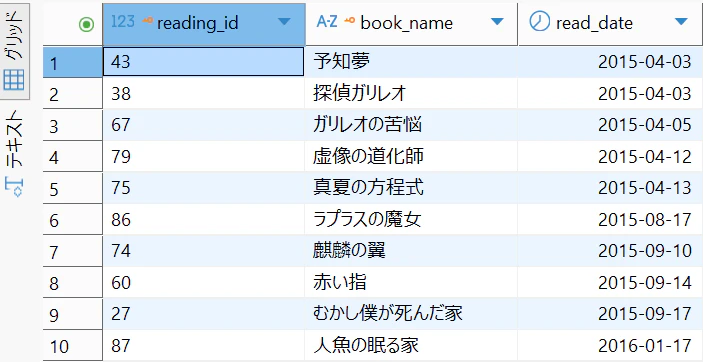
以下のようなSQLを実行することで、book_idが作品名に置き換わり、見やすくなります
SELECT
r.reading_id,
b.book_name,
r.read_date
FROM reading_log r
JOIN kh_books b
ON r.book_id = b.book_id
ORDER BY r.read_date;
book_idで書籍マスタ(kh_books)のテーブルと読書履歴(reading_log)のテーブルをJOINさせた後、read_dateで昇順に並び替えています。
読んだ回数のカウント
以下のようなSQLを実行することで、各作品何回読んだのかを可視化することができます。
SELECT
b.book_id,
b.book_name,
COUNT(r.reading_id) AS read_count
FROM kh_books b
LEFT JOIN reading_log r
ON b.book_id = r.book_id
GROUP BY b.book_id, b.book_name
ORDER BY read_count DESC;
ここでは、書籍マスタ(kh_books)のテーブルと読書履歴(reading_log)のテーブルをbook_idで結合させています。
この時、LEFT JOINを使うことによって、未読も含む全部の本の結果を含めることができます。
その後、
COUNT(r.reading_id) AS read_count
でreading_idの数を数えることで、その本が何回読まれたかを計算し、
GROUP BY b.book_id, b.book_name
で本ごとに集計を行っています。
その後、読んだ数の多い順に並べ替えています。
実行すると、このように出力されます。
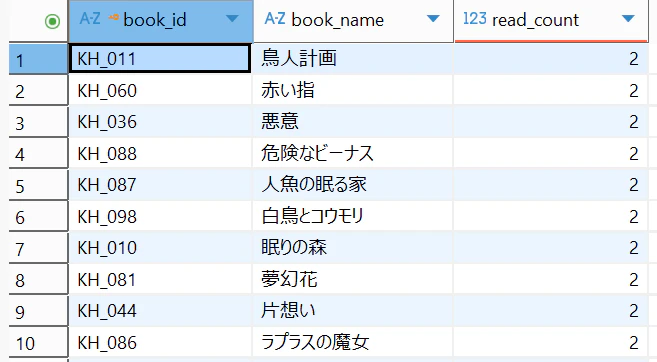
まとめ
今回は、既存のデータベースに新しくテーブルを追加する方法について学びました。
具体的には、
- 読書履歴を管理する reading_log テーブルの設計
- ERDの修正
- DDLの追加
- ETLによるデータ投入
- JOINや集計SQLによる可視化
まで、一連の流れを実装しました。
特に今回のポイントは、テーブルを横に広げるのではなく、縦に伸ばす設計です。
再読のように繰り返し発生するデータを、カラムとして追加するのではなく、別テーブルとして切り出すことで、
- 拡張性が高い
- シンプルで管理しやすい
- SQLで柔軟に集計できる
といったメリットが得られます。
また、外部キー制約やインデックスを設定することで、データの整合性やパフォーマンスも意識した設計を体験できました。
今後もこの東野圭吾DBを題材に、データベース設計やETL処理について学んでいきたいと思います。