はじめに
私は化学メーカーの現場で技術開発を行っています。
これまで業務の一環で、部署の実験データを集約するデータベースの構築にも関わりました。
また、実際の自己研鑽で「東野圭吾さんの書籍をデータベースにする」記事を投稿しており、まだの方はぜひこちらもご覧ください。
https://qiita.com/MicroCheese/items/8acb216d4831b4fa7f1c
今回は、この東野圭吾DBを題材にして、既存のデータベースに後から変更を加える方法を勉強していきます。
どんな修正を加えるのか
私の作った東野圭吾DBをもとに、新しくカラム、つまり列を追加してみましょう。
具体的には、東野圭吾さんの作品の中で、自分なりに面白いと思ったTop10作品をデータベースに登録できるようにしたいと考えました。
そのために、書籍情報を管理しているテーブルに、ランキングを表すカラムを追加していきます。
データベースにカラムを追加するには
① ERDを修正する
② Excelデータを修正する
③ DDLを修正する
④ データベースにカラムを追加する
⑤ ETLプログラムを修正し、実行する
⑥ データベースを確認・可視化する
という順番で行います。
特に、処理がうまくいくように、DBにカラムを追加した後は必ずETLプログラムを確認し、適宜修正することが必要となります。
次項から、一つ一つ見ていきましょう。
① ERDを修正する
今回は、ランキングという新しいカラムを追加するだけなので、ERDは以下のようにKH_booksのエンティティに、Rankingという属性が加わりました。
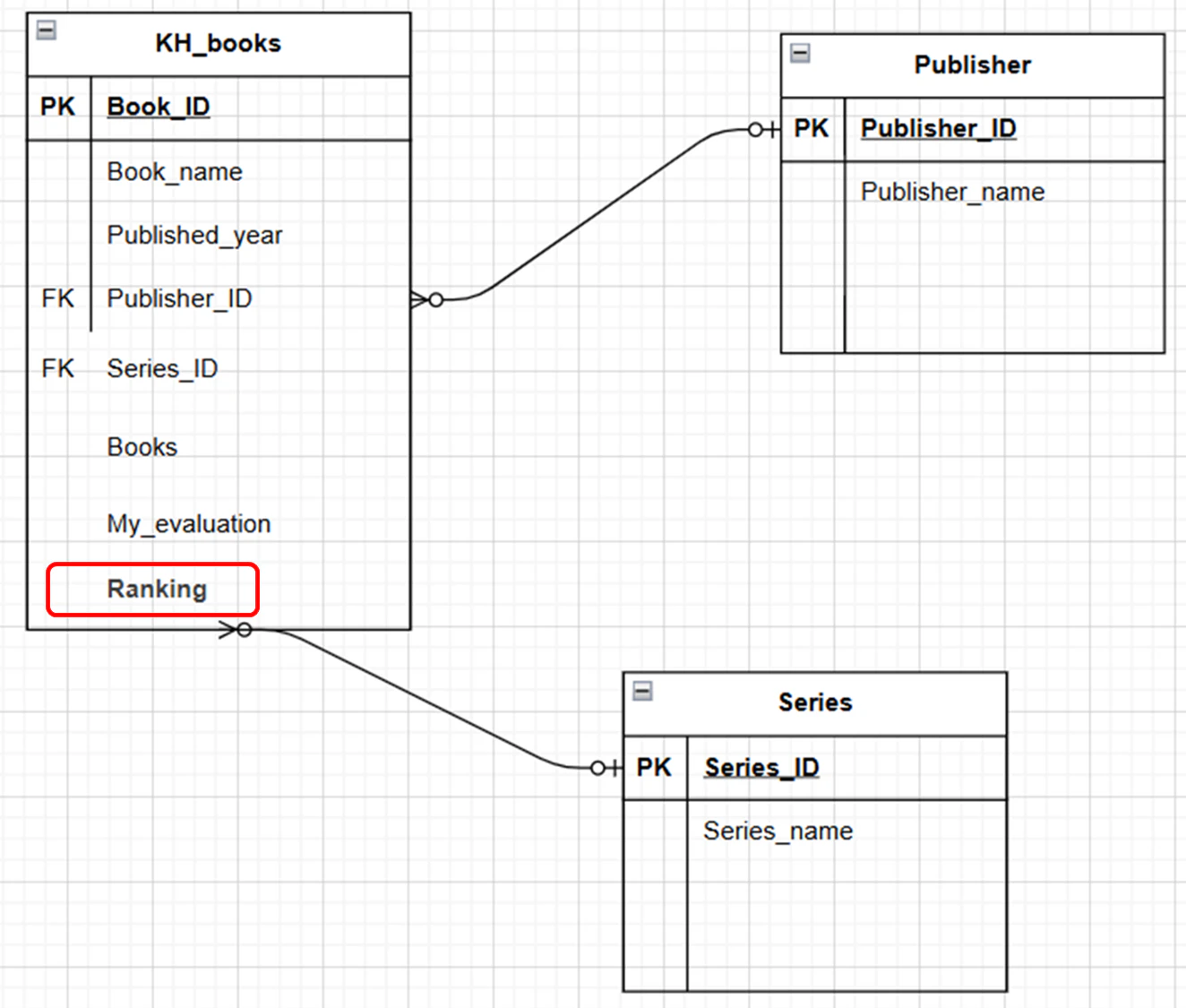
極論、ERDの修正を行わなくてもカラムを追加することはできます。
ですが、できたDBと整合性を取るうえでも、必ずERDの修正も行うことが大切です。
② Excelデータを修正する
ここははっきり言って難しくありません。
すでに作ってあるExcelファイルに、ERDに合うよう「Ranking」という列を追加して、数字を該当書籍の行に1~10までの半角数字を入れるだけです。

③ DDLを修正する
DDLは以前の記事でお伝えした通り、データベースの構造を作るSQLコードでした。
今回、すでにデータベースが出来上がっているため、DDLを修正しなくてもカラムを追加することはできます。
しかし
- 出来上がったDBと整合性を取る
- 何らかの理由で、再度DBを初期化し作り直すかもしれない
などを想定し、DDLの修正も行うことが大切だと思います。
幸いにも、今回は以下のようにDDLの修正箇所は少なく、rankingを追加するだけです。
create table if not exists kh_books (
book_id text primary key, -- e.g., B001
book_name text not null unique, -- e.g., 白夜行
published_year int check (published_year between 1900 and 2100),
publisher_id text not null references publisher(publisher_id),
series_id text references series(series_id),
book_type text not null,
my_evaluation int check (my_evaluation between 1 and 5),
ranking int check (ranking between 1 and 10) --新しく追加したカラム
);
今回、ランキングはTOP10までであり、列には1~10の整数を入れる予定です。
そのため、データ型はINT型で1~10の制約を持たせています。
④ データベースにカラムを追加する
すでにデータベースがあるため、わざわざ初期化しなくてもpsglかDBeaverで簡単にカラムを追加することができます。
今回はDBeaverでカラムを作ってみましょう。
DBeaverで下図の赤で囲んだ所をクリックしてSQLを起動し、カラムを作るSQLコードを書いて実行します。
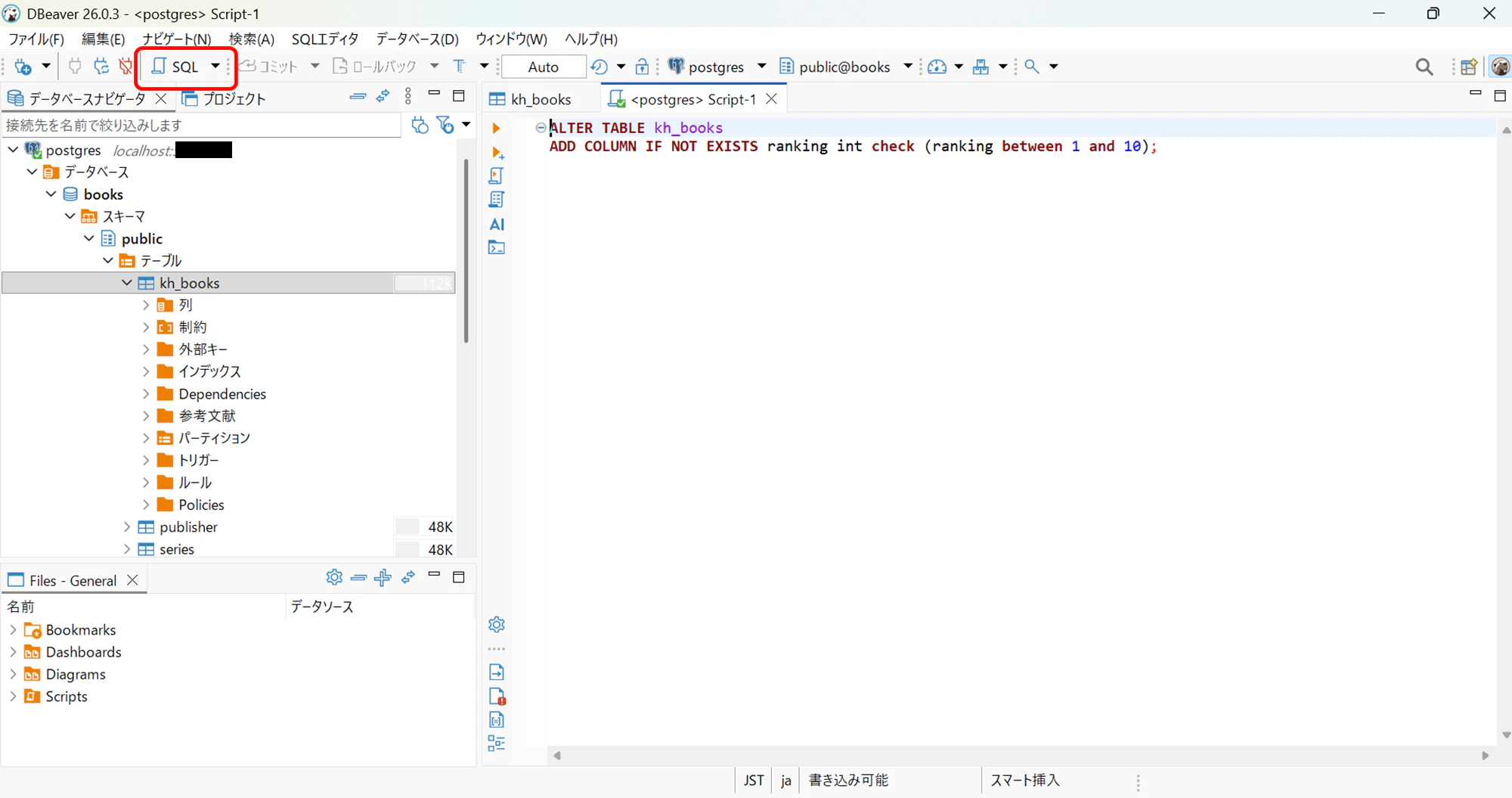
今回は、以下のようなSQLを書きました
ALTER TABLE kh_books
ADD COLUMN IF NOT EXISTS ranking int check (ranking between 1 and 10);
このALTERとは、「既存のデータベースに変更を加えますよ」という意味になります。
従って、この2行のSQL文で「kh_booksテーブルに新しい列(ranking)を追加する」という命令になります。
実行することで、既存のデータベースに新しい列を付け加えることができました。
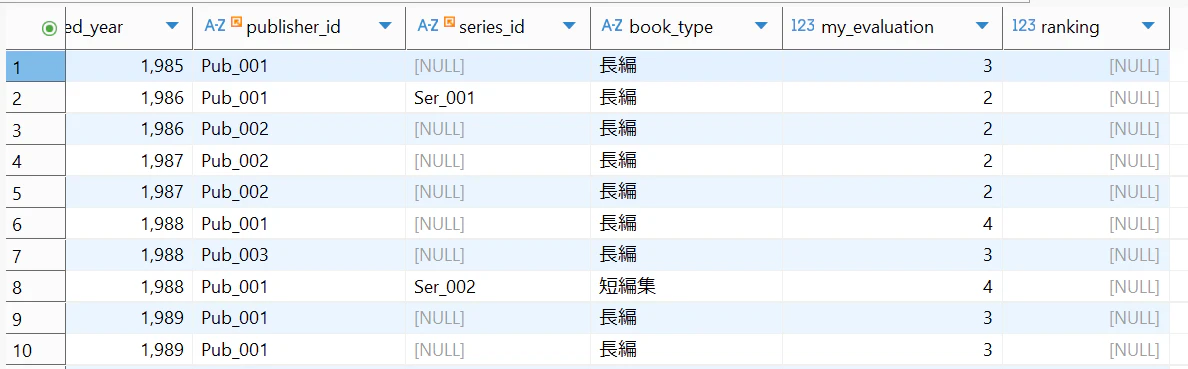
もちろんまだ、実際のデータは入っていません。
⑤ ETLプログラムを修正し、実行する
このプロセスを行うことで、追加したカラムに実際のデータを入れることができます。
ここで、実際のETLソースコードの中身を確認し、どのようにデータベースにデータを入れているかを見てみましょう。
ソースコードの全体像は、前記事をご覧ください。
⑤-1. まず、Excelの各シートからデータフレームを取得し、列名を正規化します。
def read_excel_sheet(xlsx_path: Path, sheet_name: str) -> pd.DataFrame:
"""
Excelの1シートを読み込む
前提:
- 1行目は空白
- 2行目がヘッダー
"""
df = pd.read_excel(
xlsx_path,
sheet_name=sheet_name,
header=1,
)
# 完全空行・空列を削除
df = df.dropna(how="all")
df = df.dropna(axis=1, how="all")
# 列名を正規化
df.columns = [normalize_colname(c) for c in df.columns]
⑤-2. 種々、データをクリーニング
⑤-3. ExcelをCSVに変換
⑤-4. データベース内のデータを初期化
そして最後に
⑤-5. CSVのデータをデータベースに格納
def load_csv(conn, table_name: str, csv_path: Path) -> None:
"""CSVを1テーブルにロードする"""
with conn.cursor() as cur:
with open(csv_path, "r", encoding="utf-8") as f:
cur.copy_expert(
f"COPY {table_name} FROM STDIN WITH CSV HEADER",
f
)
conn.commit()
print(f"[OK] {table_name} にロードしました")
ここで
conn:Pythonとデータベースをつなぐ接続情報
cur:その接続を使ってSQLを実行するための操作役
を意味しており、実際にデータベースにCSVの内容を入れているのは
cur.copy_expert(
f"COPY {table_name} FROM STDIN WITH CSV HEADER",
f
)
の部分です。
従って、今回のETLプログラムでは、Excelの列名を自動で取得し、CSVとして出力しています。
そのため、Excel側に追加したranking列と、データベース側に追加したrankingカラムの名前が一致していれば、基本的にはそのまま取り込むことができます。
ただし、Excelでは数値が文字列として扱われたり、空欄が含まれたりすることがあります。
そのため、念のため ranking を整数型に変換する処理を入れておくと、より安全です。
# ランキングを整数化(NULLはそのまま)
if "ranking" in df.columns:
df["ranking"] = pd.to_numeric(
df["ranking"], errors="coerce"
).astype("Int64")
ここまでできれば、あとはVSCodeでETLを実行してみましょう。
私の場合、以下のようなコードをVSCodeのターミナルで実行することになります。
python etl/sync_from_excel.py
実行後、データベースにデータが入っていきます。
【補足】
⑤-5. では、
- Pythonのf文字列
- SQL文
が組み合わさっており、Pythonの中でSQL文字列を作っている部分になっています。
コード内の
f"COPY {table_name} ..."
の部分では、{table_name} に実際のテーブル名が入ります。
例えば、table_name = "kh_books" の場合、Pythonの中では以下のようなSQL文が作られます。
COPY kh_books FROM STDIN WITH CSV HEADER
copy_expert() は、PostgreSQLのCOPYコマンドをPythonから実行するためのメソッドです。
これにより、CSVファイルの内容を高速にテーブルへ取り込むことができます。
⑥ データベースを確認・可視化する
最後に、実際にデータが入ったことをDBeaverで確認してみましょう。
③の時と同様にDBeaverでSQLエディタを起動し、以下のSQLを実行してみます。
SELECT
book_id,
book_name,
ranking
FROM kh_books
WHERE ranking IS NOT NULL
ORDER BY ranking;
このSQLでは、
① rankingのカラムがNULLでないもの、すなわちランキングが設定されているデータだけWHERE文で抽出し
② ORDER BYで昇順(小さい順)に並び替えて
③ IDと本の名前、ランキングの順位
を表示させています。
実際のSQLを実行すると、以下のような画面が現れます。
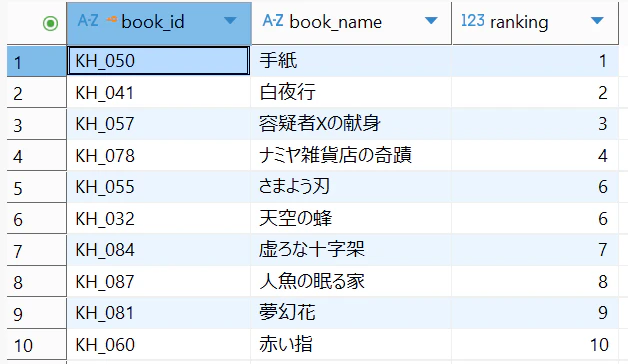
これが、東野圭吾さんの作品をすべて読破した私の、面白かったランキングTop10になります。
仮に今後ランキングに変動があっても、Excelのデータを書き換えてVSCodeで実行すれば、簡単にデータベースが更新される仕組みになっています。
まとめ
今回は、既存のデータベースに後からカラムを追加する方法について解説しました。
ポイントは、
- ERD(設計)
- Excel(元データ)
- DDL(テーブル定義)
- DB(実体)
- ETL(データ投入処理)
これらを一貫して修正することです。
単にデータベースにカラムを追加するだけであれば、SQLを1文書くだけで済みます。
しかし、実務では「データの流れ全体」を意識して修正しないと、不整合やバグの原因になります。
今回の例のように、小さな変更であっても、
「設計 → データ → 処理 → 確認」
という流れを意識して修正することが、安定したデータ基盤を作るうえで非常に重要だと感じました。
今後もこの東野圭吾DBを題材に、データベース設計やETL処理について学んでいきたいと思います。