はじめてのGet Wild 駆動開発
先日発表されたAmazon Athenaを使えばWebサーバのログもそのまま分析にかけられるということなので、手始めにApacheのログを分析してどれだけGETでリクエストが来ているか調べてみました。
GETリクエストは即ちGet Wildリクエストです(暴論)。
下準備
Athenaで分析するためのログが必要ですが、自前でサーバを用意してログがたまるのを待ってると時間がかかるのでProcessing Logs in Hiveにあったサンプルデータを拝借しました。
こいつをS3に放り込んでおきます。
今回はこのためにget-wild-athena161208というバケットを作り、apache-logsフォルダに保存しました。
バケット名はグローバルで一意である必要がありますが、日付を入れることで他の人もget-wild-athenaYYMMDDの命名ができます。
今思えばHHMMぐらいまで入れときゃよかったな。
それはさておき、これでデータの準備は完了です。
Amazon Athenaで分析
さて、ここからAthenaを操作します。2016-12-08時点では北バージニアかオレゴンでしか使えないのでご注意ください。
Athenaのコンソールはこんな感じ。なんかスッキリしていていいですね。
テーブルの作成
先ほどS3に保存したログからテーブルを作成します。
コンソール左にある「Add tables...」をクリックしたくなりますが、今回は使いません。
なぜならProcessing Logs in Hiveの「Combined Log Format File」という項目にこのログをHiveに取り込むための文が載っているからです。
あ、AthenaはHiveを使ってるみたいです。
DROP TABLE IF EXISTS apache_combined_log;
CREATE TABLE apache_combined_log (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (-|\\[[^\\]]*\\]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\"[^\"]*\") ([^ \"]*|\"[^\"]*\"))?",
"output.format.string" = "%1$s %2$s %3$s %4$s %5$s %6$s %7$s %8$s %9$s"
)
STORED AS TEXTFILE;
LOAD DATA LOCAL INPATH "/home/user/combinedlog" INTO TABLE apache_combined_log;
SELECT * FROM apache_combined_log ORDER BY time LIMIT 5;
Processing Logs in Hiveにこんな文が書いていたので、必要な箇所だけ書き換えます。
CREATE EXTERNAL TABLE get_wild_log (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (-|\\[[^\\]]*\\]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\"[^\"]*\") ([^ \"]*|\"[^\"]*\"))?",
"output.format.string" = "%1$s %2$s %3$s %4$s %5$s %6$s %7$s %8$s %9$s"
) LOCATION 's3://get-wild-athena161208/apache-logs/'
こいつをコンソール右のテキストエリアに書いて(LOCATIONはお使いのバケットに合わせてください)「Run Query」をクリックしてしばらく待ちますと、
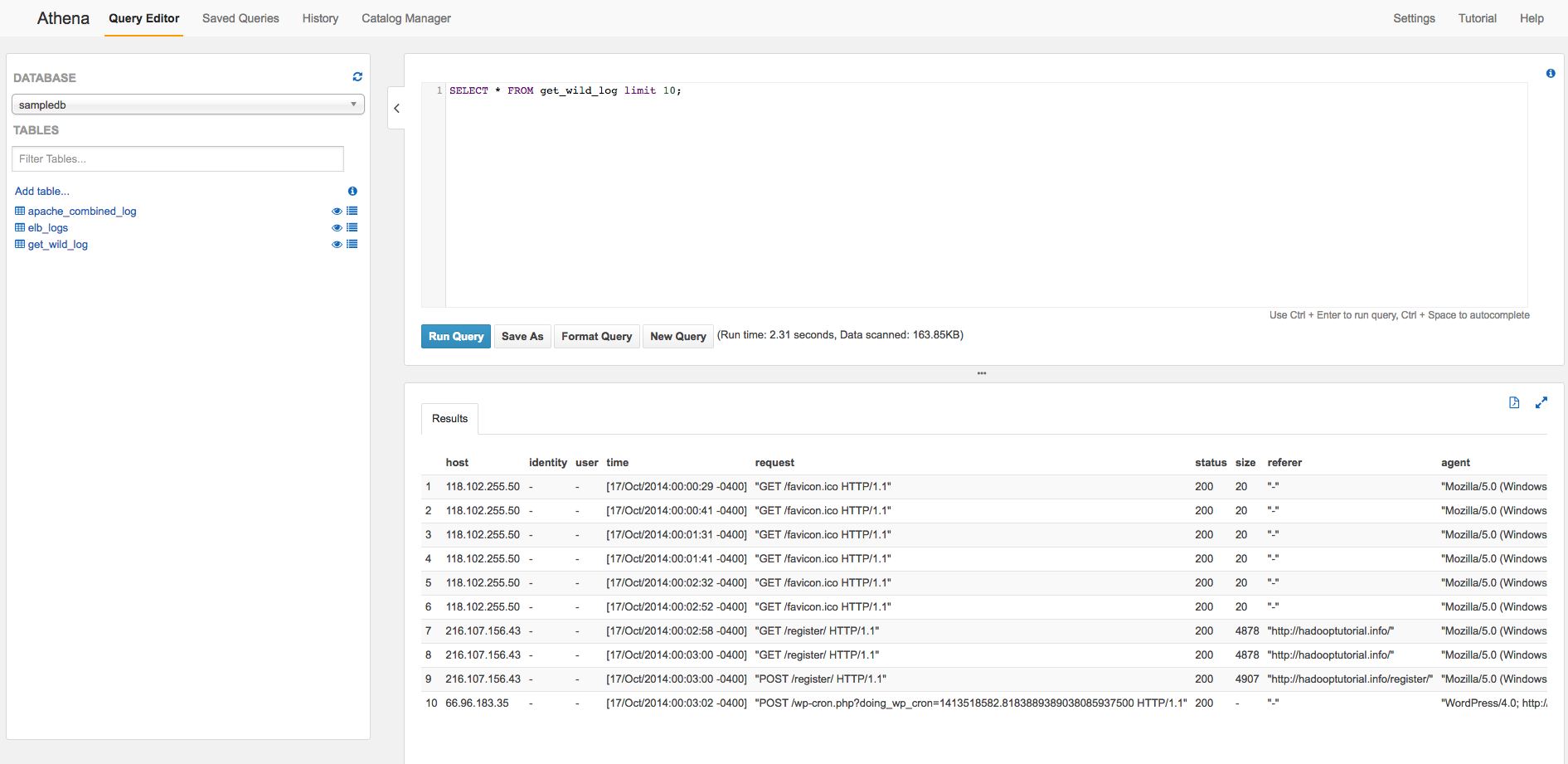
無事にget_wild_logテーブルが作られます。
Apache Web Logをそのまま取り込めるのも便利ですが、正規表現がクソめんどくさいので実用するならCSVとかにしとくのが良さそうです。
Get Wild分析
テーブルができたのでこのログがどれくらいGet Wildか見たいと思います。
AthenaのクエリはSQLと同じ感じでできます。
SELECT
SUM(case WHEN request LIKE '%GET%' then 1 else 0 end) AS get,
COUNT(*) AS wild,
SUM(case WHEN request LIKE '%GET%' then 1 else 0 end) * 100 / COUNT(*) AS get_wild_and_tough
FROM get_wild_log;
GETの件数をget、全件数をwild、GETのパーセンテージをget_wild_and_toughとしてクエリを投げます。
結果はこちら
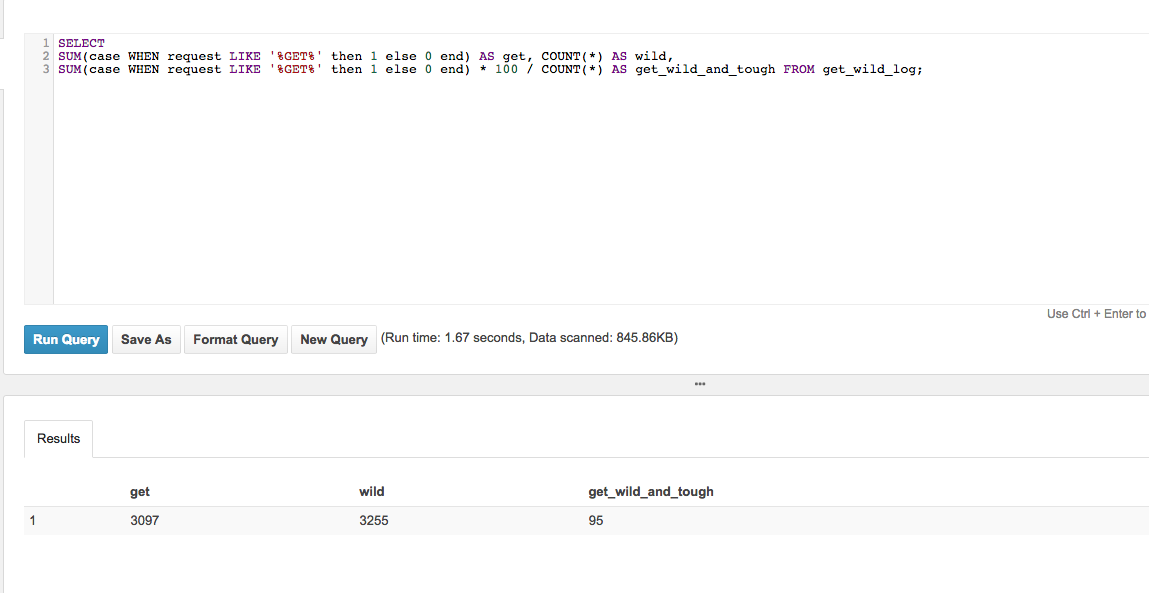
Get Wild率95%
これはかなりGet Wildですね。
ELBでヘルスチェックとかしてる場合はその分を排除しとかないと不当に高いGet Wild率になるので注意しといたほうが良さそうですね。
今後の展望
というわけでWebサーバのログからGet Wild率を求めることができましたが、これだけだと物足りないですね。
ていうかGet Wild駆動開発たるもの音を鳴らさないと、というのが個人的な思いです。
今考えている案としては、
- 簡単なWebページを用意してボタンを設置する
- ボタンを押すとAPI経由でAthenaで分析し、ログ中のGETの回数を返す
- GETの回数に応じた長さでGet Wildをリピート再生する(300回なら300秒)
というのがありますが、他にも何か素敵なアイディアがありましたらコメントいただけると幸いです。
今回初めてGet Wild駆動開発をしてみましたが、
めっちゃ楽しい。