
はじめに
MetricFireのPrometheusインスタンスは、すべてのscrape_interval期間のスクレイピングターゲットをスクレイピングします。しかし、一部のアプリケーションが、Prometheusによって検出およびスクレイピングされるほど長く存続しない場合はどうなるでしょうか?たとえば、Kubernetesサービスディスカバリを使用していて、ポッドがピックアップされるほど十分に生きていない場合はどうでしょうか。その後、Prometheusのすべてのターゲットを検出または削ることができないため、Prometheusの一般的なプルモデルは適合しなくなるため、ある種の解決策が必要です。
これが、Prometheus Pushgatewaysの出番です。短命のスクリプトからメトリックデータをPushgatewayに送信すると、最終的にメトリックはPrometheusに取り込まれます。 この記事では、Pushgatewaysをすぐに使い始めることができるようにするために知っておくべきことをすべて説明していきます。(以下の説明では、Prometheus Pushgatewayのバージョン1.2.0でテストされています。)
独自のPrometheusインスタンスでブログをフォローするには、MetricFireが提供するHosted Prometheusを設定してみてください。無料デモでご相談いただき、無料トライアルにサインインし、インストールやセットアップ、メンテナンスなどの煩わしさなしにPrometheusとGrafanaのすべての利点を得ることができます。
基本的な使い方
Pushgatewayの実行
最初の最も重要なこととしては、実際にPrometheus Pushgatewayを実行するには何が必要であるかを確認することです。ソフトウェアはGoで記述されているため、Goでサポートされている任意のオペレーティングシステムとアーキテクチャで実行できる自己完結型のバイナリとなります。 最も便利なのは、Prometheus Pushgatewayリリースのgithubページにアクセスして、そこにそれらのバイナリをダウンロードする方法です。 以下は、指定したバージョンをダウンロード、抽出、実行するための便利なbashスクリプトです。
# !/bin/bash
VERSION="1.2.0"
wget "https://github.com/prometheus/pushgateway/releases/download/v${VERSION}/pushgateway-${VERSION}.linux-amd64.tar.gz"
tar xvzf "pushgateway-${VERSION}.linux-amd64.tar.gz" "pushgateway-${VERSION}.linux-amd64/pushgateway"
rm -f "pushgateway-${VERSION}.linux-amd64.tar.gz"
mv "pushgateway-${VERSION}.linux-amd64/pushgateway" ./
rmdir "pushgateway-${VERSION}.linux-amd64"
明らかに、マシン上で異なる場合は、このスニペットのオペレーティングシステムとアーキテクチャを変更する必要があります。 これにより、現在の作業ディレクトリにバイナリpushgatewayが提供されます。 これを使用して、独自のプッシュゲートウェイを開始できます。
コンテナーを使用する場合は、Docker hubで既に作成済みのDockerイメージが待機しています。
docker run -it -p 9091:9091 --rm prom/pushgateway
localhost:9091のシャットダウン時に自動的に削除されるPushgatewayコンテナーを提供します。
最後に、Kubernetesについて話しましょう。 Helmは、使用するKubernetesのユビキタスパッケージマネージャーです。 次のコマンドでPushgatewayの素晴らしいチャートがインストールできます。
helm install stable/prometheus-pushgateway
デフォルトでは、チャートはポート9091でもリッスンしているサービスを作成します。すべてのオプションのリファレンスリストはこちらを参考にしてください。 さらに、チャートはPrometheusオペレーターと統合することもできます。 この統合が意味することは、serviceMonitor.enabledをそのチャートに追加すると、PushgatewayがPrometheusによって自動的にスクレイピングされるということです。 これはそれ自体が大きなトピックであり、PushgatewaysよりもKubernetesに関連しているため、この記事ではスキップさせて頂きます。 詳細については、上のリンクを自由に探索してみてください。
Pushgatewayによって提供されるデフォルトのオプションは、ほとんどのケースでうまく機能します。 ここにそれらの説明をさせて頂きます:
- --web.listen-address =:9091、リクエストをリッスンするIP(オプション)とポートのペア。
- --web.telemetry-path = / metrics、Pushgatewayのメトリック(ユーザー送信と内部の両方)が公開されるパス。
- --web.external-url =、このPushgatewayが外部から利用できるURL。ドメイン名で公開する場合に便利です。
- --web.route-prefix =が指定されている場合、これをすべてのルートの接頭辞として使用します。デフォルトは--web.external-urlの接頭辞です。
- --web.enable-lifecycleを指定すると、APIを介してPushgatewayをシャットダウンできます。
- --web.enable-admin-apiを指定すると、Admin APIが有効になります。特定の破壊的なアクションを実行できます。次のセクションで詳しく説明します。
- --persistence.file =、指定されている場合、Pushgatewayはその状態を--persistence.interval期間ごとにこのファイルに書き込みます。
- --persistence.interval = 5m、状態を以前に指定したファイルに書き込む頻度。
- --push.disable-consistency-check(指定されている場合)は、取り込み時にメトリックが正しいかどうかがチェックされません。ほとんどの場合は指定しないでください。
- --log.level = info、debug、info、warn、errorのいずれか。それより高いレベルのメッセージのみを出力します。
- --log.format = logfmt、可能な値:logfmt、json。 Elasticsearchなどで使用できる構造化ログが必要な場合は、jsonを指定します。
メトリックの送信
ここまでで、Pushgatewayが稼働しているはずです。 ここからは、短命のバッチジョブから独自のメトリックを送信する2つの方法を紹介します。
-
Webリクエストを実行できるプログラムを使用
-
クライアントライブラリを使用
前者は、バッチジョブがPowershellやBashなどの言語で記述されている場合に適しています。
Powershellでは、特定のURLと特定のデータにWebリクエストを送信する正規のInvoke-WebRequestを使用できます。 Windows PowerShellのPushgatewayにメトリックデータを送信するには、次のスニペットを使用してください。
$metrics = "
# TYPE some_metric
gaugesome_metric 42
# TYPE awesomeness_total counter
# HELP awesomeness_total How awesome is this article.
awesomeness_total 99999999
"Invoke-WebRequest-Uri "http://localhost:9091/metrics/job/metricfire/instance/article" -Body $metrics -Method Post
上記のスニペットを実行すると、localhost:9091のユーザーインターフェイスに次の結果が表示されます。
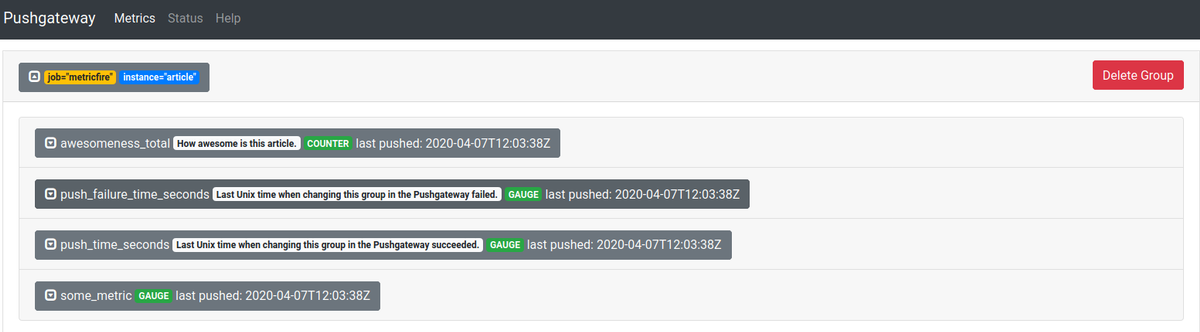
その結果、/ metricsエンドポイントに次のデータが含まれるようになりました。

ご覧のとおり、jobとinstanceの2つのラベルがあります。 Prometheusがそれらを見つけられない場合、構成のhonor_labelsがtrueであれば、それ自体でそれらをアタッチします。 上記のスニペットでは、リクエストの作成に使用したURLを介してメトリックデータに追加されています。
Linuxや他のUnixのようなオペレーティングシステムの場合、広範囲に渡るcURLを使用してこのリクエストを実行できます。 次のスニペットでも、前のスニペットと同じ結果が得られます。
cat <<EOF | curl --data-binary @- http://localhost:9091/metrics/job/metricfire/instance/article
# TYPE some_metric gauge
some_metric 42
# TYPE awesomeness_total counter
# HELP awesomeness_total How awesome is this article.
awesomeness_total
99999999
EOF
URLで指定されたラベルは、メトリックをグループ化するために使用されます。 これにより、メトリックの小さなグループを一緒に参照できるため、後で簡単に削除できます。
ジョブまたは他のラベルにスラッシュ(/)が含まれている場合、追加の作業を行う必要があります。 詳細については、こちらをご覧ください。
URLを介してメトリックを渡すために唯一必要なラベルは、ジョブのラベルです。 また、URLを介して渡されるラベルは、本文を介して渡されるメトリックが持つラベルを上書きしてしまうことに注意してください。 疑問がある場合は、常にいくつかのサンプルメトリックをプッシュし、/ metrics(または--web.telemetry-pathで変更した場合は他のパス)をチェックして、Prometheusに公開されているものを確認できます:http:/ / localhost:9091 / metrics。
すべてがうまくいくとと、200 HTTPステータスコードを含む応答が返されるはずです。整合性チェックを無効にした場合、202 HTTPステータスコードが表示される可能性があります。これは、次のスクレイプに含めるためにメトリックがキューに入れられており、まだチェックされていないことを意味しています。まったく同じ名前を書き込んだとしても、異なるタイプでプッシュするなど、無効なメトリクスをプッシュした場合、実際のスクレイピングは失敗する可能性があります。
最後に、400 HTTPステータスコードは、いくつかの無効なメトリックをプッシュしたが、それらが拒否されたことを意味します。このような場合、HTTP応答は何が問題かを示してくれます。
例:プッシュされたメトリクスが無効であるか、既存のメトリクスと一致しない:プッシュされたメトリクスが無効であるか、既存のメトリクスと一致しない:収集されたメトリクス "some_metric" {label: label: label: Gauge:}は、以前に同じ名前とラベル値で収集された。
つまり、1つのリクエストで同じメトリックが2回定義されています。同じリクエストまたはスクレイプでメトリクスの値を再定義すると無効になります。
メトリックをスクレイピング
使用できる構成は、自由に使用できるさまざまなサービス検出メカニズムによって大きく異なります。 ここの資料で利用可能なさまざまな構成オプションを調べてください。 最も簡単なオプションは、メトリックを取得するPushgatewayターゲットをStastically的に定義することです。
scrape_configs:
- job_name: pushgateway
honor_labels: false
static_configs:
- targets: ['localhost:9091']
labels:
pushgateway_instance: metricfire
これにより、ローカルでPushgatewayを実行している場合、Prometheusはlocalhost:9091でPushgatewayインスタンスをスクレイピングします。考慮すべきもう1つのことは、honor_labelsパラメータを有効にすることです。これを有効にすると、Prometheusが特定の予約済みラベルまたはスクレイピング構成で指定したラベルを追加しようとしたときに、Prometheusがアタッチしようとしているものではなく、Pushgatewayからのものを選択することを意味します。たとえば、Pushgateway awesomeness {pushgateway_instance =” notmetricfire”}にメトリックがある場合、上記のコードスニペットで確認できるスクレイピング構成で定義されているmetricfireではなく、そのラベルに値notmetricfireを使用します。これがない場合、元のラベルは、値notmetricfireを持つexported_pushgateway_instanceに名前が変更されます。
honor_labelを有効にすると、必須のジョブラベルなど、Pushgatewayが公開するすべてのラベルを保持したい場合に役立ちます。 Pushgatewayにあるメトリックをクエリするときに同じジョブラベルを使用できると、より明確になります。
メトリックの削除
メトリクスを削除するには3つの方法があります。
-
UIでメトリックのグループの近くをクリック
-
--web.enable-admin-apiによって有効にされている場合、管理APIのワイプエンドポイントを介す
-
DELETEを使用してHTTPリクエストを作成。
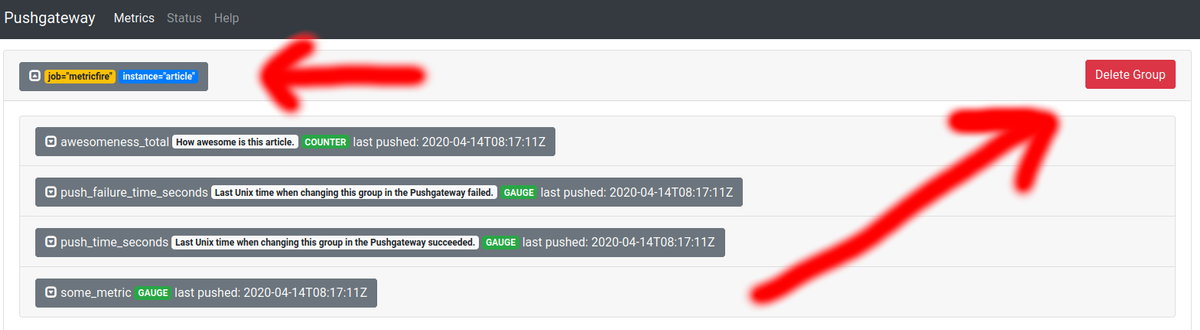
UIからの削除は簡単です。 Pushgatewayをローカルで実行している場合は、http:// localhost:9091 /にアクセスします。 次に、削除したいメトリックのグループを見つけて展開します。 削除する前にメトリックを展開することは、何かが何であるかを明確に確認するための優れた方法です。そのため、必要なものを削除しないことが確実になります。 最後に、[Delete Group]をクリックし、もう一度[Delete]をクリックしてアクションを確認します。 インターフェースでの表示は次のとおりです。
これでメトリックは消えました。
一方、管理APIは、すべてのメトリックを消去する方法のみを提供します。 動詞PUTを使用して/ api / v1 / admin / wipeに呼び出しを送信するだけです。 cURLの-Xパラメータを使用すると、使用する動詞を変更できます。 以下はcURLでどのように見えるかです。
curl -X PUT http://localhost:9091/api/v1/admin/wipe
これが成功すると、2xx HTTPステータスコードを含む応答が返されます。
これを有効にすると、UIに素敵なボタンが表示され、同じことができます。
したがって、APIを呼び出すか、このボタンを押すかは自由です。
最後に、以前に使用したグループ化ラベルを使用して、メトリックを削除できます。 これはn個のメトリックを送信することとまったく同じですが、動詞POSTの代わりにDELETEを使用する必要があります。 これは、cURLの-XまたはPowershellの-Methodで指定できます。 たとえば、job =” metricfire”およびinstance =” article”で識別されるいくつかのメトリックがある場合、リクエストを送信することにより、cURLでそれらを削除できます。
curl -X DELETE http://localhost:9091/metrics/job/metricfire/instance/article
これで以下のようにグループを削除します。

この呼び出しでは、特定のメトリックグループのみが削除されます。 つまり、インスタンスラベルをebookに設定して、ジョブラベル内にmetricfireグループとして別のメトリックグループがあった場合、次の呼び出しが行われます。
curl -X DELETE http://localhost:9091/metrics/job/metricfire
ラベルジョブがmetricfireに等しいすべてのメトリックグループは削除されません。 metricfireに等しい単一のラベルジョブによって識別されるメトリックグループのみを削除します。 この例では、上記のメトリクスグループや、ラベルインスタンスがarticleまたはebookと等しい他のメトリクスグループには触れません。
アラート
これらすべての準備が整ったら、上にアラートを追加して、問題がいつ発生するかを確認することをお勧めします。 Pushgatewayは、これに使用できるいくつかの有用なメトリックを事前に生成します。 通常、次の場合に通知を受け取るべきです。
-
誰かが一貫性のないメトリックをプッシュしようとした
-
Pushgatewayは、予想よりも長い時間メトリックをプッシュしていない
-
プッシュゲートウェイがダウンしている
groups:
- name: PushgatewayAlerts
rules:
- alert: PushgatewayDown
expr: up{job="pushgateway"} != 0
for: 10m
labels:
severity: page
annotations:
summary: A Pushgateway is down
- alert: PushesDelayed
expr: time() - push_time_seconds{job="pushgateway"} > 300
for: 5m
labels:
severity: critical
annotations:
summary: Pushgateway pushers are delayed
- alert: InconsistentMetrics
expr: rate(pushgateway_http_requests_total{code="400",handler="push",job="pushgateway"}[2m]) > 0
for: 5m
labels:
severity: critical
annotations:
summary: Someone is continuously trying to push inconsistent metrics to the Pushgateway
もちろん、設定などに応じてしきい値などを調整する必要があります。 特に2番目のアラートは、すべてのプッシャーが常に新しいメトリックをPushgatewayにプッシュしていると想定しているためです。 それが当てはまらない場合は、追加のメトリックセレクタを追加して、本当に必要な時にのみ適用されるようにする必要があります。
集計
Pushgatewayは、受け取ったメトリックを集約しないように意図的に設計されています。つまり、いったん取得すると、Prometheusに永久に公開されます。ただし、これはすべてのユースケースに当てはまるとは限りません。たとえば、いくつかのジョブユニットを処理する小さなバッチジョブがあるとすると、一番はじめの値から増加し続けるカウンターが表示されることがあります。
したがって、通常のプッシュゲートウェイでは、同じジョブの再起動と複数のインスタンスの間でそれがわかるように、その値をどこかに保持する必要があります。ただこれは、同じカウンターへの同時アクセスなどを処理する追加のインフラストラクチャを維持する必要があるため、これにより複雑さが大幅に増大する可能性があります。この問題を解決するために、集約型プッシュゲートウェイが作成されました。
集約Pushgatewayは、存続期間中に受け取るさまざまな値を集約します。たとえば、同じラベル名と値を持つカウンターが一緒に追加されます。ここでソフトウェアを見つけることができます。通常のプッシュゲートウェイとの違いについては、こちらをご覧ください。したがって、この問題が発生した場合は、ドロップイン代替品として代わりに使用できます。これは、ここで与えられたすべてのアドバイスがそれに適用されることも意味します。
高可用性
残念ながら、Pushgatewayは強力な一貫性を保証しません。 前述のように、できることは、指定した期間ごとにメトリックをディスクに保存することです。 これらは、それぞれパラメータ--persistence.file =および--persistence.interval =によって制御されます。
つまり、1つのノード(トラフィックを処理するノード)によって書き込み可能なマウントされたストレージを用意し、他のノードは永続的なストレージを読み取り専用としてマウントすることをお勧めします。 Kubernetesの世界では、ReadWriteOnceモードの永続的なボリュームクレームでこれを実現できます。 こちらより利用可能なさまざまなオプションをすべて探索できます。
pushgatewayヘルムチャートは、persistentVolume.enabled:trueを介して既にこれをサポートしています。 このパラメータは次のように指定されます。
helm install --name metricfire-pushgateway --set
persistentVolume.enabled=true stable/prometheus-pushgateway
他のすべての利用可能なオプションをこちらから確認してみてください。
最後に
これで、Pushgatewayを起動して実行するために知っておくべきことはすべて確認できました。 メトリックの送信、メトリックのスクレイピング、メトリックの削除、およびメトリックに関するアラートの方法などを見てきました。 Prometheusによる高可用性モニタリングの詳細については、Prometheus + Thanosを使用したHA Kubernetes監視に関する記事をご覧ください。 同様に、Prometheusによるモニタリングに関する詳細については、他のQiita記事またはMetricFireブログをチェックしてください。
MetricFireの無料デモは、Prometheusの使用を検討するのに最適な方法です。 ユーザーがPrometheusモニタリングのスケーリングを開始し、長期的なストレージとデータの冗長性を構成する必要がある場合、MetricFireの強みが大いに発揮されます。 MetricFireの提供するHosted Prometheusを使用してPrometheusの悩みを解決してみてはいかがでしょうか?
それでは、またの記事で!