Dockerはコンテナ化のための最も一般的なツールの1つであり、Dockerコンテナの内部で何か問題が起きていないかを監視するために、オープンソースコミュニティによっていくつかのツールが開発されています。 このガイドでは、そのうちの1つのツールであるcAdvisorに焦点を当てています。:cAdvisor

なぜDockerコンテナを監視する必要があるのか?
監視により、ソフトウェアの状態に関する重要な情報を収集できるため、開発チームは製品を改善する方法を見つけることができます。 各コンテナは自己完結型のシステムであるため、監視はさらに不可欠です。
コンテナの監視には、各コンテナの使用状況の測定値を記録して監視システムに報告することが含まれます。 このようにして、バグの検出とアプリケーションの改善を確実にし、総合的なパフォーマンスと堅牢性を向上させます。
コンテナの監視にcAdvisorを使用する方法
cAdvisor(Container Advisor)は、Googleが提供および管理するオープンソースのコンテナ監視ツールです。 Dockerコンテナおよび他のほぼすべてのコンテナをネイティブでサポートしています。 cAdvisorは、実行中のコンテナに関する情報を収集し、そのデータを処理してからエクスポートする単一のコンテナデーモンで構成されています。 この情報は、専用のWebインターフェイス、またはBig Query、ElasticSearch、InfluxDB、Kafka、Prometheus、Redis、StatsDなどのサードパーティアプリに送信できます。 -storage_driverフラグをstdoutに設定することで、標準出力に書き込むこともできます。
具体的には、cAdvisorは、マシン全体の各コンテナのリソース使用履歴、リソース分離パラメーター、およびネットワーク統計を記録します。
早速開始:cAdvisorの実行
cAdvisor自体は単一のDockerイメージであるため、cAdvisorのセットアップと実行は簡単です。 そのため、docker runコマンドを使用して起動および実行できます。 端末で次のコマンドを実行することにより、cAdvisorを実行してローカルマシンのコンテナーを監視できます。
sudo docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
google/cadvisor:latest
とても簡単です! cAdvisorがバックグラウンドで実行され始めました。 ローカルで実行されているDockerデーモンに接続し、コンテナの使用状況のメトリクスを収集して、http:// localhost:8080 /からアクセスできるWebユーザーインターフェイスに表示します。 ユーザーインターフェースでは、CPUとメモリの使用状況、実行中のすべてのプロセスの詳細な概要など、コンテナからのリアルタイムの使用状況メトリクスを確認できます。
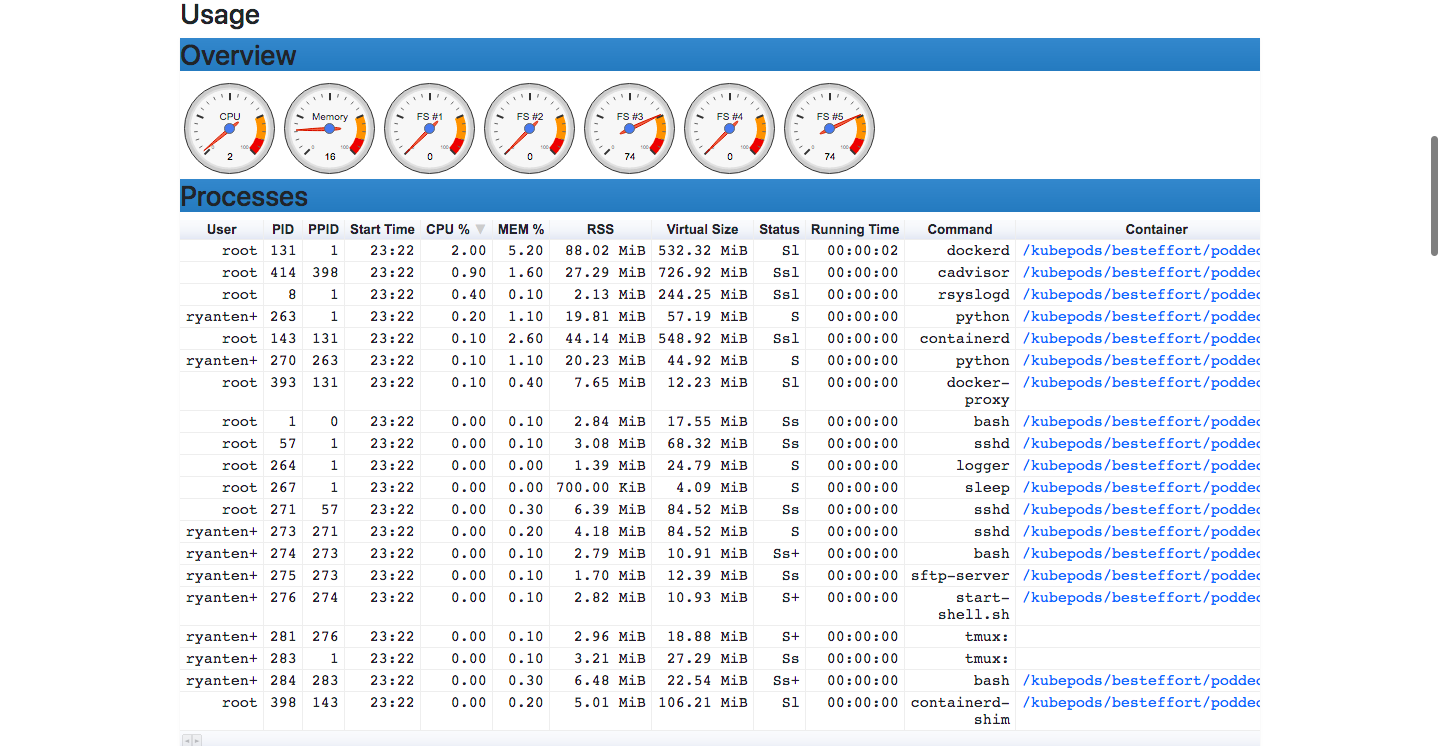
<注釈>
Dockerデーモンがユーザー名スペースを有効にして実行されている場合、-userns = hostオプションを追加して、cAdvisorがDockerコンテナを監視できるようにする必要があります。 そうしないと、cAdvisorがDockerデーモンに接続できなくなります。
CentOS、Fedora、またはRHELのいずれかで実行している場合、cAdvisorがDockerコンテナにアクセスして監視するために、コンテナを--privileged = trueおよび--volume = / cgroup:/ cgroup:ro \で実行する必要がある場合があります。 これは、コンテナへのアクセスに関しては、RHELとCentOSの方が難しいためです。 cAdvisorがソケットを介してDockerデーモンにアクセスする必要があるため、-privileged = trueを設定する必要があります。 また、RHELおよびCentOSの一部のバージョンでは、cgroup階層が/ cgroupディレクトリにマウントされているため、cAdvisorを実行するには、-volume = / cgroup:/ cgroup:ro \の追加のDockerオプションが必要になります。
cAdvisorを使用してアプリケーションメトリクスの収集
コンテナ使用状況メトリクスに加えて、cAdvisorは、アクティブ接続と読み取り接続の数、アプリケーションに適切なCPUとメモリの割り当てがあるかどうかなど、アプリケーションメトリクスを収集することも可能です。 (これを書いている時点では、cAdvisorによるアプリケーションメトリクスのサポートは開発のアルファ段階にあるため、留意してください。)コンテナは、ステータスページまたは統計用の別のAPIでアプリケーションメトリクスを公開できます。 cAdvisorは、これらのメトリクスを一般的な方法で収集する方法を提供します。
cAdvisorがアプリケーションメトリクスを収集できるようにするには、次の2つのことを行う必要があります。
- 設定ファイルを作成すること
- その設定ファイルをcAdvisorに渡すこと
設定ファイルの作成
アプリケーションメトリクスの設定ファイルで、cAdvisorにアプリケーションメトリクスを検索する場所を指示し、cAdvisorからユーザーインターフェースおよびバックエンドにメトリクスをエクスポートするための他のパラメーターを指定させることが必要です。 メトリクス構成には以下が含まれます。
エンドポイント(メトリックを収集する場所)
タイプ(ゲージ、カウンターなど)
メトリクスの名前
データ型(float、int)
ポーリング頻度
単位(秒、kbps、カウント)
正規表現(収集するメトリクスとそれらを解析および処理する方法を指定する正規表現)
以下は、構造化された情報を想定していない一般的なメトリクスコレクターの例です。
{
"endpoint" : "http://localhost:8000/nginx_status",
"metrics_config" : [
{
"name" : "activeConnections",
"metric_type" : "gauge",
"units" : "number of active connections",
"data_type" : "int",
"polling_frequency" : 10,
"regex" : "Active connections: ([0-9]+)"
},
{
"name" : "reading",
"metric_type" : "gauge",
"units" : "number of reading connections",
"data_type" : "int",
"polling_frequency" : 10,
"regex" : "Reading: ([0-9]+) .*"
}
]
}
たとえば、構造化メトリクスをPrometheusにエクスポートする場合、設定ファイルをエンドポイントのみに縮小できます(他の情報は設定ファイルから取得できます)。 以下は、エンドポイントからすべてのメトリクスを収集するサンプルのPrometheus構成です。
{
"endpoint" : "http://localhost:9100/metrics"
}
Here’s another sample configuration that collects only selected metrics:
{
"endpoint" : "http://localhost:8000/metrics",
"metrics_config" : [
"scheduler_binding_latency",
"scheduler_e2e_scheduling_latency",
"scheduling_algorithm_latency"
]
}
設定ファイルをcAdvisorに渡す
cAdvisorはDockerコンテナーのラベルを使用して、各Dockerコンテナの構成をフェッチします。 io.cadvisor.metricで始まるラベルは、cAdvisorアプリケーションメトリクスラベルとして解析されます。 cAdvisorは、そのラベルの値を、構成が見つかる場所のインディケータとして使用します。 たとえば、io.cadvisor.metric.prometheus-xyzという形式のラベルは、設定がPrometheusメトリックエンドポイントを指していることを示しています。
設定ファイルは、コンテナイメージの一部にすることも、ボリュームを使用して後で(実行時に)追加することもできます。 これにより、コンテナが実行されているホストとアプリケーションメトリック設定との間に接続がないことが保証されます。 コンテナのメトリック情報は自己完結型であるため、Redisの構成例は次のようになります。
Dockerfile (or runtime):
FROM redis
ADD redis_config.json /var/cadvisor/redis_config.json
LABEL io.cadvisor.metric.redis="/var/cadvisor/redis_config.json"
ここで、redis_config.jsonは、上記のjson構成を含む設定ファイルです。 次に、cAdvisorは実行時にコンテナイメージにアクセスし、設定ファイルを処理して、アプリケーションメトリクスの収集と公開を開始します。
知っておくべきこととして、cAdvisorは特にコンテナラベルを調べてこの情報を抽出することです。 Docker 1.8では、コンテナーはイメージからラベルを継承しないため、実行時にラベルを指定する必要があります。
アプリケーション特有のメトリクスへのAPIアクセス
次のエンドポイントを使用して、特定のコンテナのアプリケーションのメトリクスにアクセスできます。http:// localhost:8080 / api / v2.0 / appmetrics / containerName
収集される一連のアプリケーションメトリクスは、コンテナの仕様から検出できます。http:// localhost:8080 / api / v2.0 / spec / containerName
通常の統計APIには、アプリケーションメトリクスも追加されています。http:// localhost:8080 / api / v2.0 / stats / containerName
注釈:アプリケーションメトリクスは、リソースメトリクスの後のコンテナページにあります。
ただし、cAdvisorには制限があります。 ユーザーにアラートを送信して重要な情報を提供することはできません。 たとえば、測定されたメトリクスの1つがクリティカルレベルに達した場合、cAdvisorは通知しません。 使用する際はこの点を考慮してください。
いずれにせよ、cAdvisorは、非常に簡単なセットアップとシームレスなDockerサポートにより、依然としてコンテナ監視に優れたツールです。 アラートメカニズムを組み込む必要がある場合は、PrometheusやStatsDなど、さまざまなオプションを選択できます。 以下のPrometheusの簡単な例を紹介します。
Prometheusを使用したcAdvisorメトリックの監視とエクスポート
cAdvisorは、すぐにコンテナでの統計をPrometheusに公開できます。 デフォルトでは、これらのメトリクスは/ metrics HTTPエンドポイントの下で提供されます。 このエンドポイントは、-prometheus_endpointコマンドラインフラグを目的の値に設定することでカスタマイズできます。
PrometheusでcAdvisorを監視するには、そのメトリクスエンドポイントで関連するcAdvisorプロセスをスクレイピングする1つまたはそれ以上のジョブをPrometheusで構成する必要があります。
ただし、最初に、Prometheusを構成することが必要で、これは、prometheus.ymlファイルを使用して行います。 prometheus.ymlファイルを作成し、それに以下のコードを貼り付けます(コードはGitHubページにあります)。
global:
scrape_interval: 5s
evaluation_interval: 5s
scrape_timeout: 10s
rule_files:
- '/etc/prometeus/alert.rules'
alerting:
alertmanagers:
- static_configs:
- targets:
# whatever you want
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['prometheus:9090']
labels:
alias: 'prometheus'
- job_name: 'cadvisor'
static_configs:
- targets: ['cadvisor:8080']
labels:
alias: 'cadvisor'
グローバル変数は以下で説明できます:
scrape_interval:メトリックのターゲットがスクレイピングされる頻度(デフォルトは1分)
scrape_timeout:スクレイピングリクエストがタイムアウトするまでの時間(デフォルトは10秒)
rule_files:ルールファイルへのパス、この場合は、アラートが発生したときにアラートを処理する方法を指定するアラートルールファイル
Evaluation_interval:ルールを評価する頻度(デフォルトは1分)
prometheus.ymlファイルを作成したのと同じフォルダーで、docker-compose.ymlファイルを作成し、それにDocker Compose構成を追加します。
version: '3.2'
services:
prometheus:
image: 'prom/prometheus:latest'
container_name: prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
commands:
- '--config.file=/etc/prometheus/prometheus.yml'
ports:
- '9090:9090'
cadvisor:
image: 'google/cadvisor:latest'
container_name: cadvisor
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk:/dev/disk/:ro
ports:
- '8080:8080'
次に、特定のアラートの処理方法を指定するalert.rulesファイルを作成します。 以下は、GitHubページで利用できる簡単なalert.rulesファイルの例です。
ALERT containerAlert
IF absent(((time() - container_last_seen{name="your-container-name"}) < 5)) FOR 5s
LABELS { severity="page" }
ANNOTATIONS {
SUMMARY = "Instance {{$labels.instance}} down",
DESCRIPTION = "Instance= {{$labels.instance}}, Service/Job ={{$labels.job}} is down for more than 2 sec."
}
このアラートは、特定のコンテナ(「コンテナ名」)が停止され、5秒以上存在しない場合を引き金と起こります。 PrometheusのアラートはPrometheus Alert Managerにが使用されます。PrometheusAlert Managerは非常に柔軟であり、アラートをメールやSlackワークスペースなど、選択したアプリケーションに即座に繋げることができます。 これを設定するには、アラートマネージャの設定ドキュメントをご覧ください。
そして、実はあなたはそれをすでに持っています! Dockerコンテナを正常に監視し、cAdvisorを使用してその使用状況とホストメトリクスを確認し、指定した条件が満たされたときにアラートを受信できます。
自分で試してみたい場合は、Hosted Prometheus by MetricFireの無料トライアルにサインアップしてください。 またはデモを予約して、最適な監視ツールについてお話しすることもできます。
それでは、またの記事でお会いしましょう!