
この記事では、Metricfireでのリモートストレージの構成を含む、PrometheusをKubernetesにデプロイする方法を説明していきます。 このチュートリアルでは、1つのノードを持つminikubeクラスターを使用しますが、これらの手順はどのKubernetesクラスターでも適用できるはずです。 以下に今回説明する全てのステップを紹介した動画がありますので、是非ご覧になってください。この記事でさらに詳しく解説していければと思います。この記事で学んだことをMetricFireの無料トライアルを使用して製品にアクセスし、早速、実践してみてください。
YAMLファイルを使用してリソースを作成します。これは、これまで行ったことの記録を保持し、変更が必要なときにいつでもファイルを編集できることを意味します。 自身ファイルのバージョンを以下のリンクで見つけることができます:
YAMLファイルに含まれる内容と、YAMLファイルが実行する内容について説明しますが、Kubernetesの動作についてはあまり詳しく説明しません。 ただし、自身で調べてから、今回の作業を行えば、より深く理解できるかとは思います。 これらの各YAMLファイルは、KubectlにリクエストをKubernetes APIサーバーに送信するように指示し、それらの指示に基づいてリソースを作成します。
Namespace
Kubernetesのすべてのリソースは名前空間で起動され、名前空間が指定されていない場合は、「デフォルト」の名前空間が使用されます。 監視設定をより細かく制御できるように、「monitoring」と呼ばれる別の名前空間を作成します。
これは手動で実行する非常にシンプルなコマンドですが、後で速度、正確性、正確な再現のために代わりにファイルを使用することにします。 ファイルを見ると、v1という名前のAPIバージョンに送信されていることがわかります。これは、名前空間と呼ばれるkindのリソースであり、そのNameが監視しています。
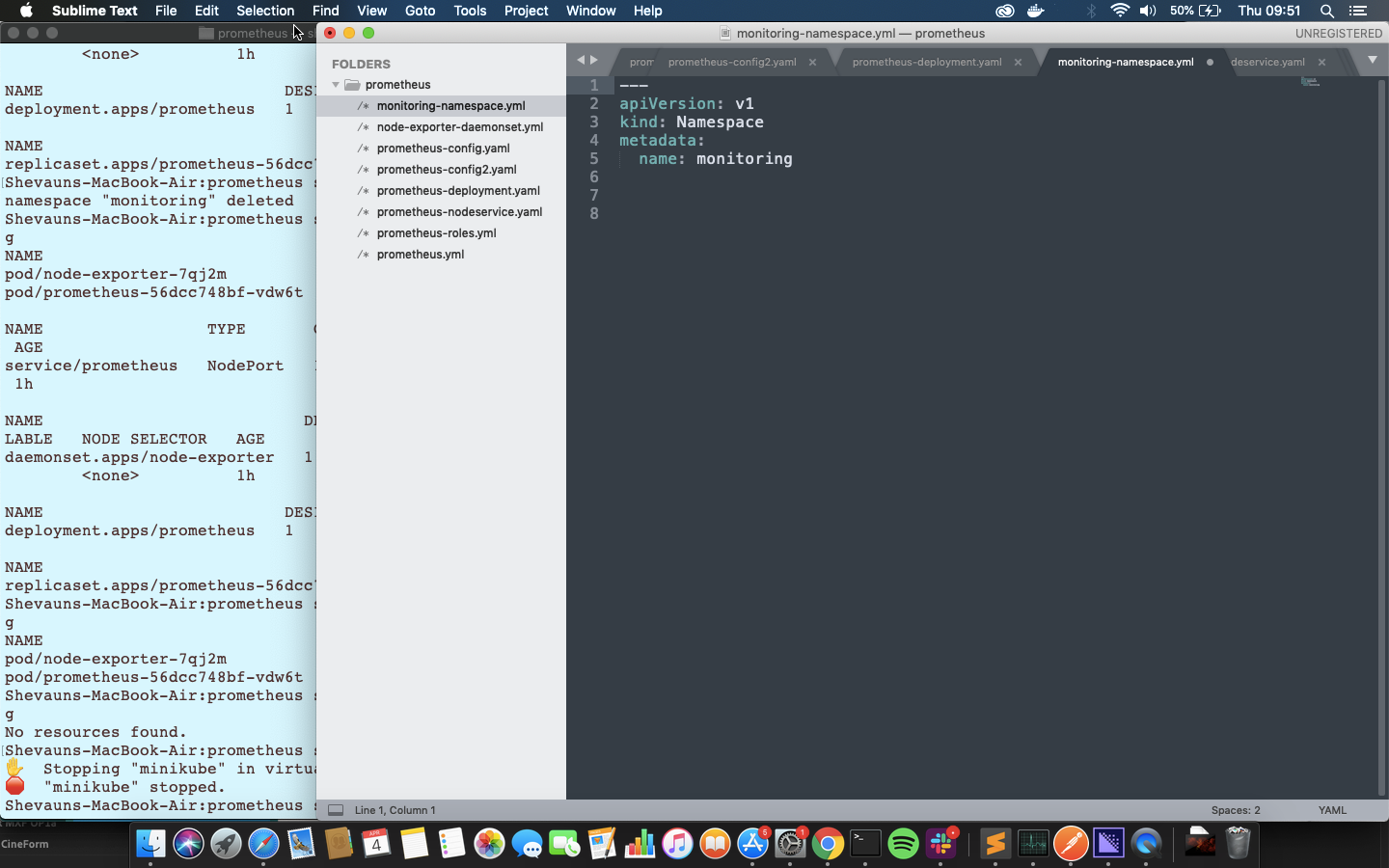
これを実行するために、
kubectl apply -f monitoring-namespace.yaml
これが適用されると、次のコマンドで使用可能な名前空間を表示できます
kubectl get namespaces
構成マップ
次のステップは、構成マップをセットアップすることです。 KubernetesのConfigMapは、デプロイ内のすべてのPodに構成データを提供します。
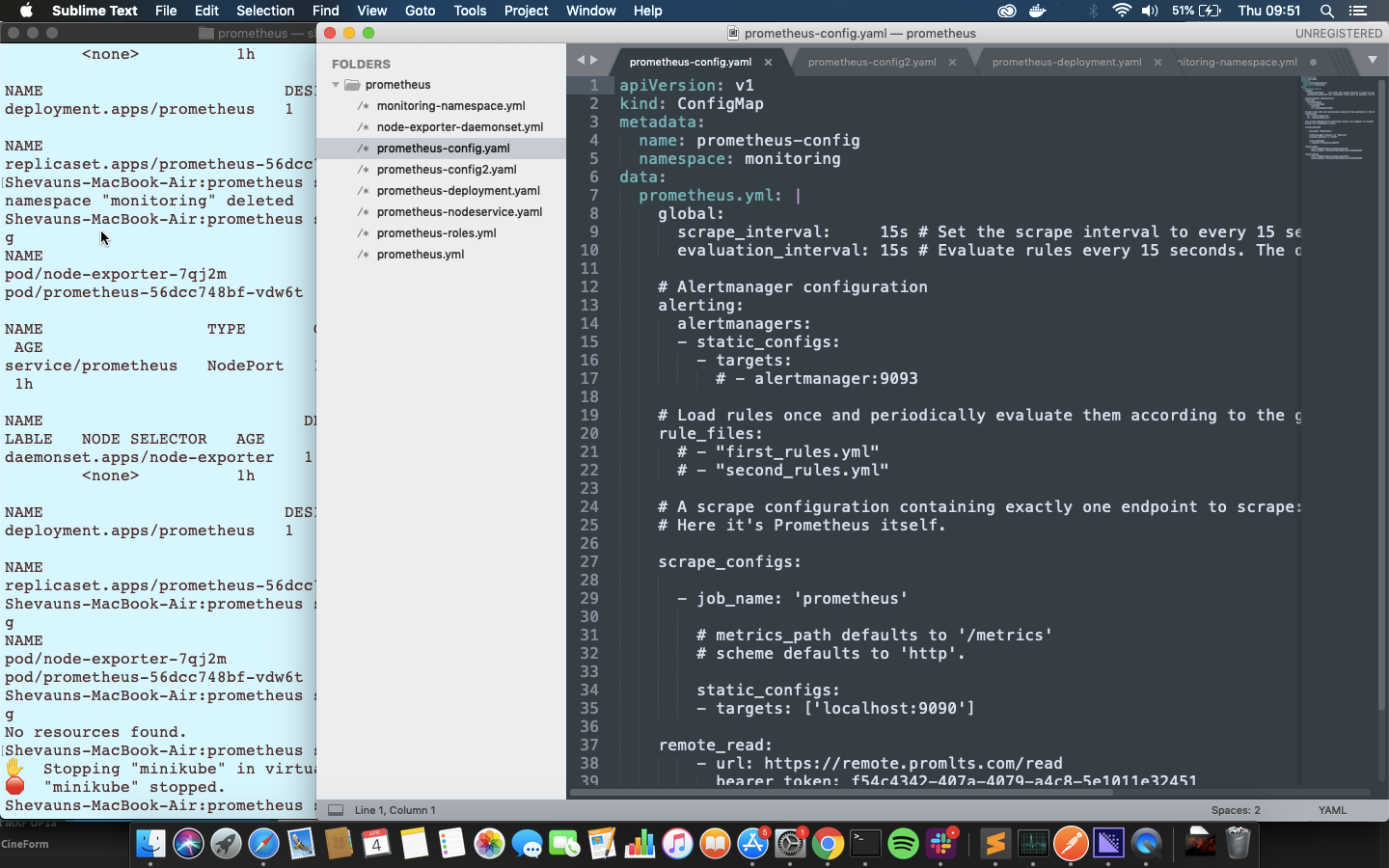
このファイルでは、apiversionがv1になり、KindはConfigMapであることが確認できます。metadataでは、名前が「prometheus-config」、およびこのConfigMapを配置するnamespaceの「monitoring」を確認できます。 これでConfigMapが「monitoring」名前空間に移動されました。
その下のdataセクションには、非常に単純なprometheus.ymlファイルがあります。 個別に見ると、単純な間隔設定が含まれており、アラートやルールには何も設定されておらず、Prometheusからメトリックスを取得するための1つのスクレイピングジョブのみが含まれていることがわかります。
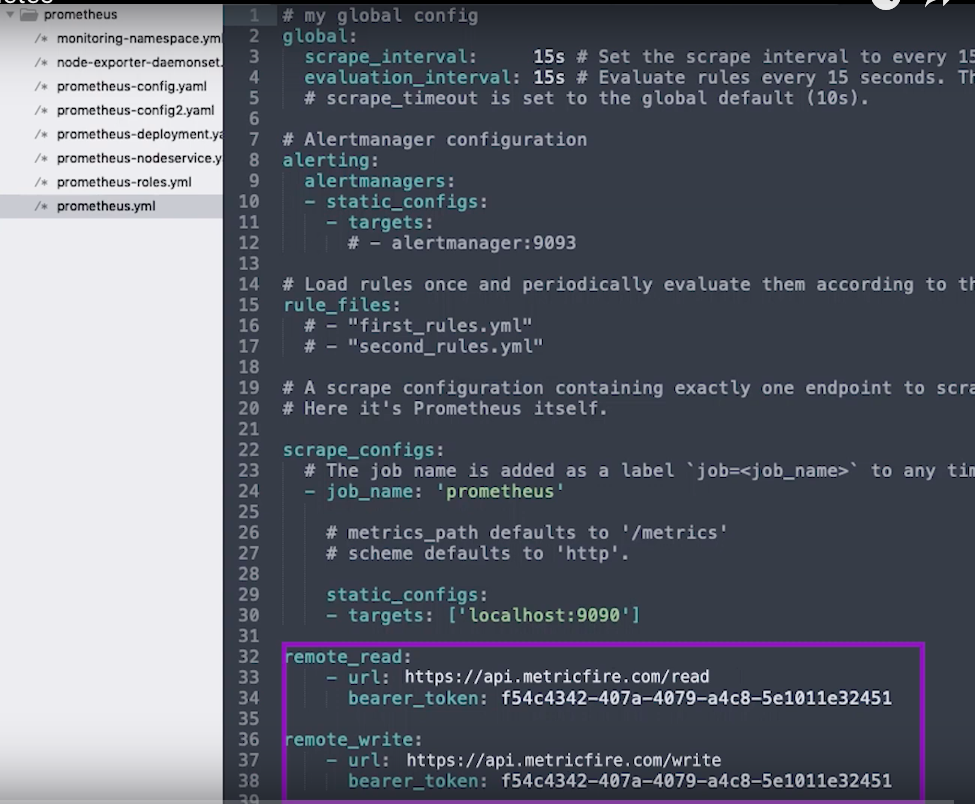
また、Metricfireのリモートストレージの詳細も含まれているため、このPrometheusインスタンスが起動して実行されると、リモート書き込み場所へのデータの送信が開始されます。 remote_readとremote_writeの両方にエンドポイントとAPIキーを提供しているだけです。
configMap自体は何もしませんが、チュートリアルの後半でprometheusをデプロイするときに使用できるように、それを適用しておきます。
kubectl apply -f prometheus-config.yaml
Roles
次に、両方のmonitoring名前空間で、すべてのKubernetesリソースへのアクセス権を付与する役割と、役割を適用するサービスアカウントを設定します。 具体的には、ClusterRoleを設定します。通常の役割では、同じ名前空間内のリソースにのみアクセスできます。Prometheusは、提供するすべてのメトリックを取得するために、クラスター全体からノードとPodにアクセスする必要があります。
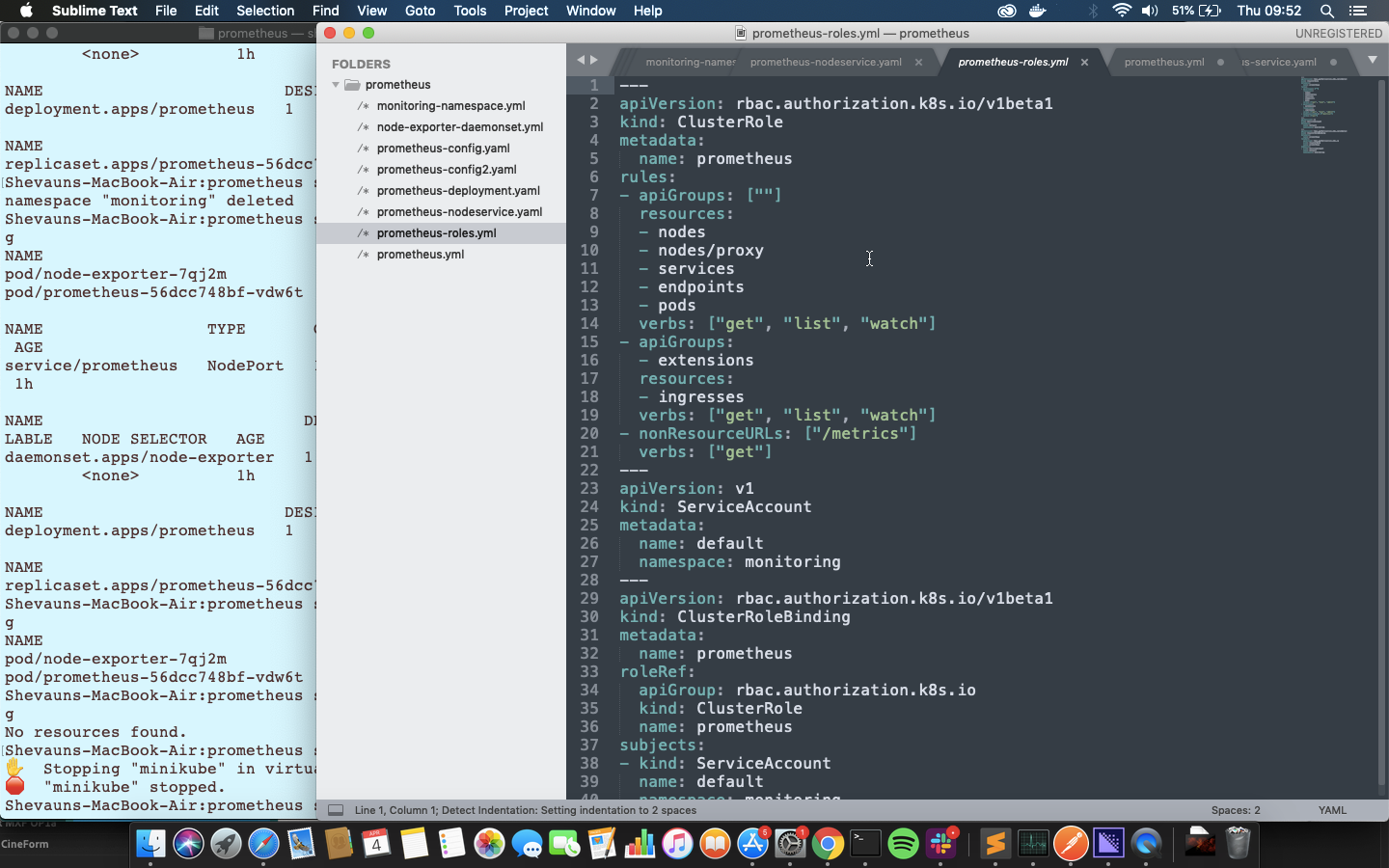
ClusterRoleのルールは、kubernetes APIのグループ(kubectlがこれらのyamlファイルを適用するために使用するものと同じAPI)または非リソースURL(この場合は「/ metrics」)に適用できます。これは、Prometheusメトリックをスクレイピングするためのエンドポイントです。 各ルールの動詞は、それらのAPIまたはURLで実行できるアクションを決定します。
ServiceAccountは、実行中のリソースとPodに適用できる識別子です。 ServiceAccountが指定されていない場合は、デフォルトのサービスアカウントが適用されるため、Monitoring名前空間のデフォルトのサービスアカウントを作成します。 つまり、Prometheusはデフォルトでこのサービスアカウントを使用します。
最後に、ClusterRoleBindingを適用して、役割をサービスアカウントにバインドします。
これら3つすべてを1つのファイルで作成します。必要に応じて、これらをデプロイメントにバンドルすることもできます。 わかりやすくするために、それらを別々に保持します。
kubectl apply -f prometheus-roles.yml
注:これを独自のKubernetesクラスターに適用すると、kubectlによって特定の方法ですでに作成されているリソースに対してkubectl applyのみを使用することに関するエラーメッセージがこの時点で表示されることがありますが、コマンドでは正常に機能します。
デプロイ
上記の作業で、すべてを入れる名前空間が作成し、構成があり、クラスターの役割がバインドされたデフォルトのサービスアカウントがあります。 これでPrometheus自体をデプロイする準備が整いました!
デプロイメントファイルには、セット内のすべてのPodに適用するPodTemplateを含む、ReplicaSetの詳細が含まれています。 ReplicaSetデータは、ファイルの最初の「spec」セクションに含まれています。
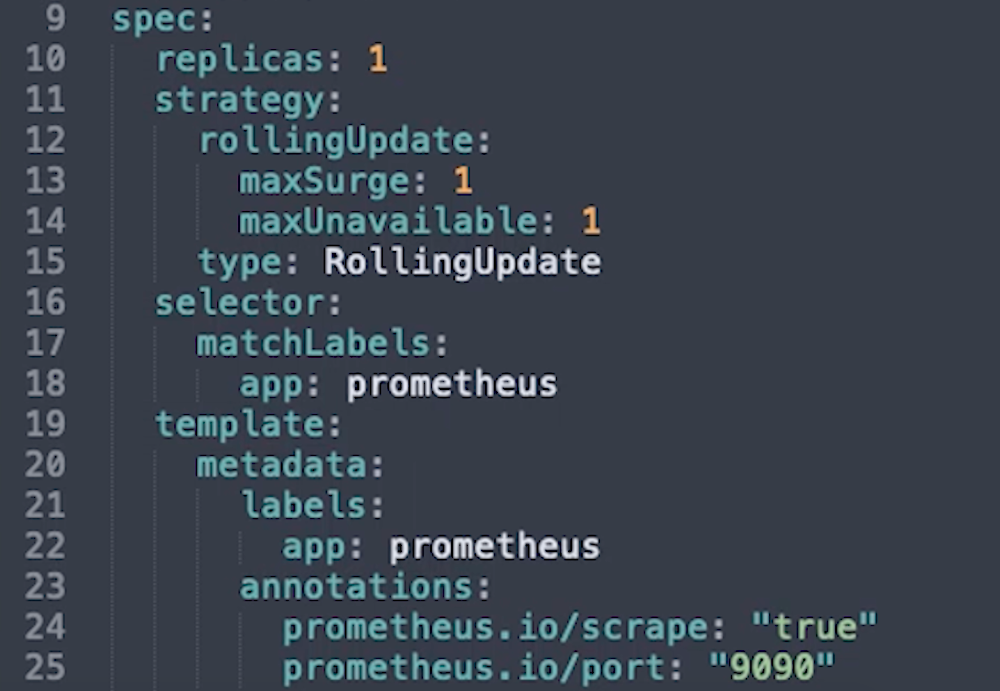
Replicaは、セット内の必要なレプリカの数です。この例では、1つだけを起動します。
Selectorは、ReplicaSetが制御しているPodをどのように認識するかを詳しく説明します。これは、あるリソースが別のリソースをターゲットにする一般的な方法です。
Strategyは、更新の実行方法です。
Templateセクションは、セット内の各Podに適用されるPodテンプレートです。
名前空間は、ReplicaSetによって決定されるため、今回は必要ありません。
上記のセレクタールールに従ってラベルが必要であり、適用するPodを見つけるために起動するすべてのサービスによって使用されます。
Annotationsの値は、Prometheusを設定してエンドポイントをスクレイピングするだけでなく、メトリックのPodをスクレイピングするときに非常に重要になります。これらはラベルに変換され、実行前にジョブの値を設定するために使用できます。たとえば、使用する代替ポートやメトリックをフィルターするための値などです。これはすぐには使用しませんが、Portに9090と注釈を付けたことがわかります。
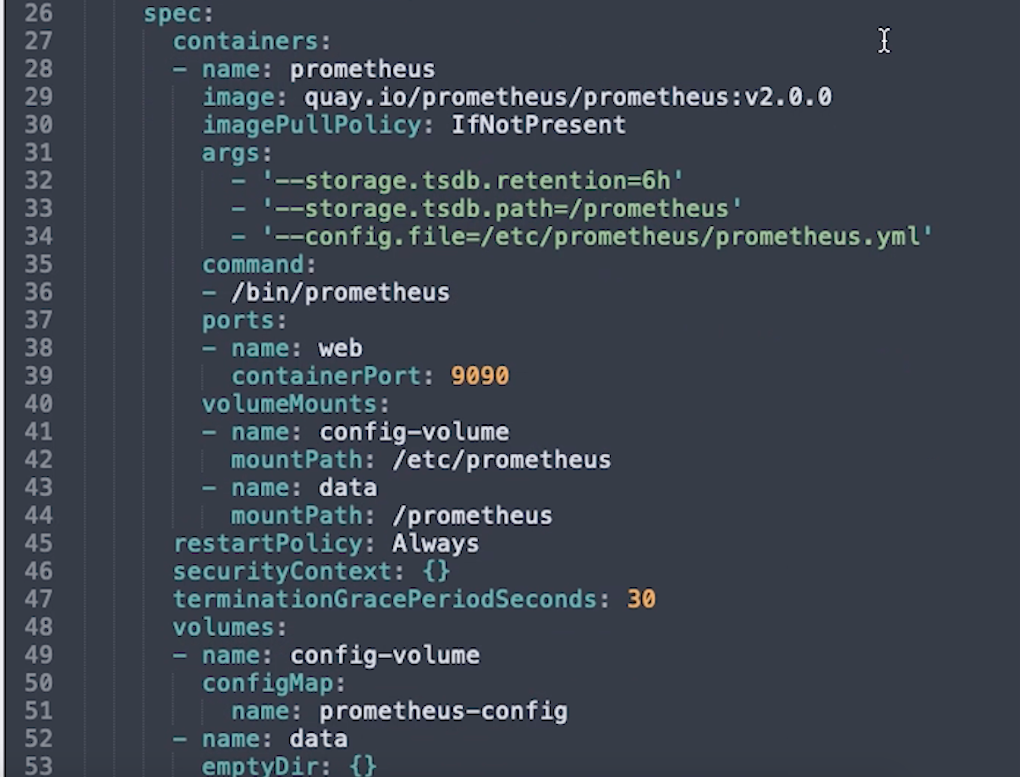
テンプレート内の2番目のSpecセクションには、各コンテナの実行方法の仕様が含まれています。 これは非常に複雑なので、Prometheusに固有のオプションについてのみ詳しく説明します。
Imageは、使用されるDockerイメージです。この場合は、quay.ioでホストされているprometheusイメージです。
Commandは、コンテナの起動時にコンテナで実行するコマンドです。
Argsは、そのコマンドに渡すArgumentsであり、以下で設定する構成ファイルの場所も含まれます。
Portは、ポート9090をWebトラフィック用に開くように指定する場所です。
volumeMountsは、外部ボリュームまたはディレクトリがコンテナにマウントされる場所です。 ここではNameとPathが指定されています。ここでは、起動時にprometheusに渡されるArgsで指定された場所に構成ボリュームがMountされていることがわかります。
VolumeとそのNameはコンテナに対して個別に設定され、ここで2つのボリュームが定義されています。
1つはConfigMapで、これはボリュームのタイプと見なされるため、コンテナー内のプロセスで参照できます。 2つ目は、Podが存在する限り存在するタイプのストレージであるemptyDirボリュームです。 コンテナを削除してもボリュームは残りますが、Pod全体が削除されると、このデータは失われます。
理想的には、データをより永続的な場所に保存する必要があります。 チュートリアルでは一時ストレージのみを使用していますが、remote_readとremote_writeの詳細を構成したので、Prometheusはオフサイトで受信したすべてのデータをMetricfireに送信します。
ここで、そのデプロイメントファイルを適用します。
kubectl apply -f prometheus-deployment.yaml
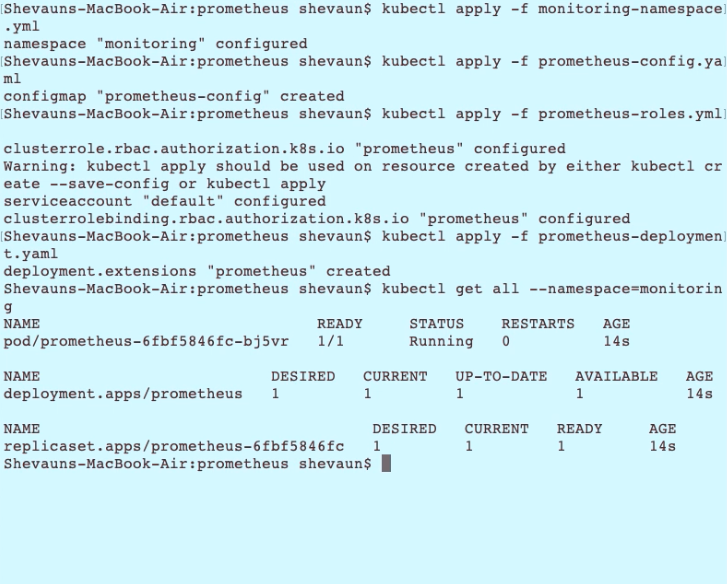
そして、Monitoring名前空間のリソースのステータスを見てみましょう。
Kubectl get all --namespace = monitoring
NodePort
Prometheusでメトリックの調査を開始する前に、やるべきことが1つ残っています。 現在のところ、Prometheusはクラスターで実行されているため、アクセスできません。 NodePortと呼ばれるサービスをセットアップして、ノードIPアドレスを介してprometheusにアクセスできるようにします。
このファイルは非常にシンプルで、名前空間、セレクターを記述しているため、正しいPodと使用するポートに適用できます。
kubectl apply -f prometheus-nodeservice.yaml
これを適用したら、任意のノードのポート30900で実行中のprometheusを確認できます。 ノードのIPアドレスの取得は、Kubernetesのセットアップごとに異なりますが、幸運なことに、MinikubeにはノードのURLを取得する簡単な方法があります。 以下を使用してすべてのサービスを確認できます。
minikube service list
または、次のコマンドを使用して、デフォルトのブラウザーでprometheusのURLを直接開くことができます。
minikube service--namespace = monitoring prometheus
使用可能なメトリックはすべて、構成内の1つのスクレイピングジョブを介してPrometheus自体から取得されます。 ラベル「job」を値「prometheus」{job =” prometheus”}で検索することで、そのジョブのすべてのメトリックを表示できます。
Node Exporterと新しいConfigMap
次に、クラスターに関するいくつかの有用なメトリックを取得する必要があります。 Node Exporterというアプリケーションを使用してクラスターノードに関するメトリックを取得し、Prometheus configmapを変更して、クラスター内のノードとPodのジョブを含めます。 Kubernetesサービスディスカバリを使用して、これらの新しいジョブのエンドポイントとmetadataを取得します。
Node Exporterは、DaemonSetと呼ばれる特別な種類のReplicaSetを使用してデプロイされます。 ReplicaSetが1つ以上のノードで実行されている任意の数のPodを制御する場合、DaemonSetはノードごとに正確に1つのPodを実行するためノード監視アプリケーションに最適です。
DaemonSetを作成するためのファイルは、通常のデプロイメント用のファイルとよく似ています。 ただし、DaemonSetによって修正されるため、レプリカの数はありませんが、以前のように、アノテーション付きのメタデータやコンテナの仕様を含むPodTemplateがあります。
ただし、Node Exporterのボリュームはかなり異なります。 configmapボリュームはありませんが、代わりにノードからのシステムディレクトリがボリュームとしてコンテナーにマッピングされていることがわかります。 これがnode-exporterがメトリック値にアクセスする方法です。 securityContext設定「privileged:true」により、Node Exporterにはこれらの値にアクセスする権限があります。
ここでそれを適用してから、DaemonSetが実行されていることを確認します。
kubectl apply -f node-exporter-daemonset.yml
kubectl get all --namespace = monitoring
新しいconfigMapファイルでは、別の方法でメトリックを取得するため、prometheusジョブはコメント化されています。 代わりに、kubernetes-nodesとkubernetes-podsの2つの新しいジョブが追加されました。
Kubernetes-podsは、クラスター内の各Pod(Node ExporterやPrometheusを含む)からメトリックを要求し、kubernetes-nodesはサービスディスカバリを使用してすべてのノードの名前を取得し、Kubernetes自体からそれらに関する情報を要求します。
ノードジョブでは、Kubernetesから提供された認証情報を使用した安全な接続の詳細を追加したことがわかります。 いくつかのラベル変更ルールもあります。 これらは、prometheusによって作成された標準ラベルとサービスディスカバリによって提供されるメタデータラベルで構成されるジョブのラベルセットに作用します。 これらのルールは、新しいラベルを作成したり、実行前にジョブ自体の設定を変更したりできます。
この場合、ルールは3つのことを行っています。
- 最初に、ノードに適用されたラベルに基づいてジョブのラベルを作成します。
- 次に、ジョブに使用されるアドレスを、サービスディスカバリによって提供されるアドレスから、ノードメトリックにアクセスするための特定のエンドポイントに変更します。
- 3番目に、メトリックパスを/ metricsから、ノード名を含む特定のAPIパスに変更します。
2番目のジョブでは、Podに設定された注釈にアクセスします。 メトリック用にスクレイピングする必要があるPodを明確にするために、prometheus.io / scrapeというアノテーションが使用されています。__address__タグとともにアノテーションprometheus.io/portが、各ポッドのスクレイプジョブのために使用されています。
configMapの置き換えは、Prometheusの2ステップのプロセスです。 まず、replaceコマンドを使用して、Kubernetesに置換マップを提供します。
kubectl replace -f prometheus-config2.yaml
configMapは、それを使用しているすべてのコンテナーにロールアウトされます。 ただし、Prometheusは新しい構成を自動的にロードしません。PrometheusUIを見ると、古い構成とジョブが表示されます-prometheus:30900 / config
新しい構成をロードする最も速い方法は、レプリカの数を0に減らしてから1に戻し、新しいPodを作成することです。 これにより既存のデータは失われますが、もちろんすべてがMetricfireに送信されるので、グラフ化もされます。
構成ページを更新すると、新しいジョブが表示されます。ターゲットページを確認すると、ターゲットとmetadataも表示されます。 メトリックはkubernetes-podsジョブの下にあり、ノードのプレフィックスが付いています。
[Metricfire](https://try.metricfire.com/japan/?utm_source=blog&utm_medium=Qiita&utm_campaign=Japan&utm_content=How%20to%20deploy%20Prometheus%20on%20Kubernetes0に切り替えれば、ノードエクスポートメトリックのダッシュボードがすでに設定されています。 ダッシュボードを更新すると、これらの新しいメトリックがMetricfireデータソースを介して表示されるようになります。
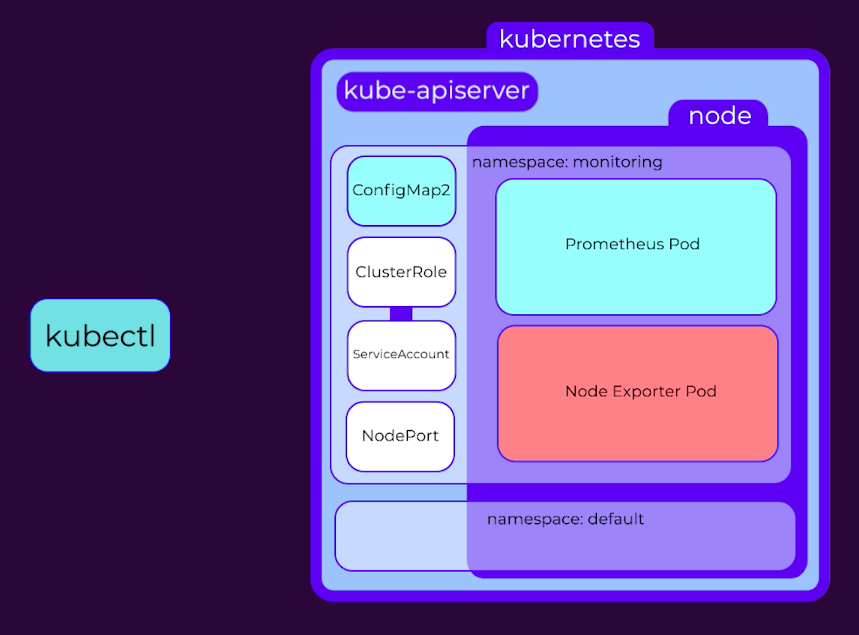
まとめると、次のようになります。
- 名前空間を作成
- configMapを作成
- デフォルトのServiceAccountであるClusterRoleを作成し、それらをバインド
- Prometheusをデプロイ
- Prometheus UIを公開するノードポートサービスを作成
- node-exporterデーモンセットをデプロイ
- ノードエクスポーターの新しいジョブでconfigMapを更新
- Prometheusを0にスケーリングして再ロードし、1に戻す
この設定に慣れたら、コンテナーを監視するためのcAdvisorのような他のサービスや、Kubernetesの他の部分に関するメトリックを取得するためのジョブを追加できます。 新しいサービスごとに、新しいスクレイプジョブを構成し、configMapを更新して、Prometheusに構成を再ロードするだけです。
最後に、環境をクリーンアップする方法を説明することで終了します。 今回の場合はかなり簡単で、名前空間を削除すると、その中のすべてが削除されます! 以下を実行するだけです。
kubectl delete namespace monitoring
そして、すべてがなくなったか、シャットダウンしていることを確認します。
kubectl get all --namespace = monitoring
しばらくすると、すべてがクリーンアップされました。
いかがでしたでしょうか?
Hosted Prometheusを試す準備はできましたか? 是非、14日間の無料トライアルを開始してみてください。
また、ご相談や質問等がございましたら、こちらからデモを予約して、電話でお問い合わせください。
それでは、また次の記事で!