ありふれた内容をありふれた手段によって実現する初投稿です。
Colabを初めて使って、使いやすさに感動したのが動機となっています。
#Google Colaboratry とは
無料かつブラウザで使えるJupyter Notebookライクな開発環境?です。
名前の通りGoogleが提供しており、Google Driveをストレージ代わりに気軽なPythonプログラミングが楽しめます。無料。
Google Colabの使い方まとめ
5分で分かるGoogle Colaboratoryの使い方
Colabのファイルを作る

新しいファイル -> その他 -> Google Colaboratry からColabを起動します。
なければ**ここ**から直接起動します。

Colabのページに行けたら
ランタイム -> ランタイムのタイプを変更。
からハードウエアアクセラレータをGPUに変更します。

ちなみにColabのGPUってTesla K80らしいです。中古で30万。ひゃー。
メモリはなんと24GB!
自宅のGPUではout of memoryになってしまう大きなデータが扱えます。
お金はかからないのでお財布的にも安心。Google素敵!
ただし12時間を超えるとセッションの内容が全部消えるので長時間の学習には工夫が必要、らしいです。
環境をサクッと準備する
%tensorflow_version 2.x
!pip install -U keras
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Flatten, Dense, Reshape, Activation, BatchNormalization, Dropout
from keras.layers.convolutional import Conv2D
from keras.layers.pooling import MaxPooling2D, GlobalAveragePooling2D
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
from keras.callbacks import ReduceLROnPlateau, LearningRateScheduler
from keras.utils import np_utils
import numpy as np
import matplotlib.pyplot as plt
基本的なCNNを組むためのライブラリ群をimportします。
ColabはJupyter Notebook同様 "!"を文頭に置くことでマジックコマンドが使えるので、
足りないライブラリは適当にインストールしちゃいましょう。
tensorflow 2.0には元々kerasが入っていたような気もしますが、些細な問題です。
簡単なCNNを作る
今回は畳み込み10層、全結合3層、計13層のシンプルなCNNです。
# Sequential型モデル
model = Sequential()
# Block1
model.add(Conv2D(filters=64, kernel_size=(3,3), padding='same',
input_shape=(input_height, input_width, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(filters=64, kernel_size=(3,3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(filters=64, kernel_size=(3,3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2), padding='same')) # Size(14, 14)
# Block2
model.add(Conv2D(filters=128, kernel_size=(3,3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(filters=128, kernel_size=(3,3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(filters=128, kernel_size=(3,3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2), padding='same')) # Size(7, 7)
# Block3
model.add(Conv2D(filters=256, kernel_size=(3,3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(filters=256, kernel_size=(3,3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(filters=256, kernel_size=(3,3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(filters=256, kernel_size=(3,3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2), padding='same'))
# DenseLayer
model.add(GlobalAveragePooling2D())
model.add(Dense(512))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(512))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(units=class_num, activation = 'softmax'))
batch normalizationをどこに入れるかは色々考察の余地がありそうな気はしますが、
今回は原点に倣って 畳み込み -> BatchNorm -> Activation の順に入れています。
この程度の計算量ならあまり学習速度に影響は出ません。たぶん。
全結合層のノード数や畳み込み層のフィルター数もハイパーパラメータです。
いじってみると結構結果に影響したりします。
学習の準備
Datasetの用意
cifar-10をkeras経由で準備します。ついでに正規化してvalidation用データの退避。
正解ラベルはonehotにしておきます。
(x_train,y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train / 255
x_train, x_val = np.split(x_train, [int(x_train.shape[0]*0.8)])
x_test = x_test / 255
onehot_train = np_utils.to_categorical(y_train)
onehot_train, onehot_val = np.split(onehot_train, [int(onehot_train.shape[0]*0.8)])
onehot_test = np_utils.to_categorical(y_test)
学習時のパラメータ周り
epoch数やbatch sizeも決めておきます。
class_num = 10
input_height = 32
input_width = 32
epochs = 120
batch_size = 1000
steps_per_epoch = x_train.shape[0] // batch_size
val_steps = x_val.shape[0] // batch_size
epoch数は120、batch sizeは1000にしました。
batch sizeはデータサイズ*10を超えるとよくないらしいです。
Google Brainの論文「学習率を落とすな、バッチサイズを増やせ」を読む
今回使用するcifar-10は学習画像5万枚のデータセットなのでこれぐらいでも大丈夫でしょう。
Data Augmentation
kerasのImageDataGeneraterを使って適度にData Augmentationしておきます。
無いと今回の構成では過学習しそうな気がします。
train_gen = ImageDataGenerator(rotation_range = 20,
horizontal_flip = True,
height_shift_range = 4.0/32.0,
width_shift_range = 4.0/32.0,
zoom_range = 0.2,
).flow(x_train, onehot_train, batch_size)
val_gen = ImageDataGenerator().flow(x_val, onehot_val, batch_size)
回転20°、水平反転、上下左右4pixelシフト、20%拡大縮小等、至って普通のData Augmentationです。
学習率を下げるcallbackの準備
def lr_step_decay(epoch):
learning_rate = 0.001
if(epoch >= 80): learning_rate/=2
if(epoch>=100): learning_rate/=5
return learning_rate
decay_lr = LearningRateScheduler(lr_step_decay)
適当なepochの時に学習率を下げることでvalidation accuracyが安定します。
今回のケースだとこれの有無で5%ぐらい変わります。
CNNの学習
モデルコンパイル
model.compile(optimizer = 'Adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
Optimizerはadamにしておきます。
SDGでパラメータチューニングを上手くやるとacc90でるよ! みたいな話を聞いたことはありますが、adamで困ったことがないのでadamです。
学習
history = model.fit_generator(train_gen,
epochs=epochs,
steps_per_epoch = steps_per_epoch,
validation_data = val_gen,
validation_steps = val_steps,
verbose=1,
callbacks=[decay_lr])
ColabのGPUに任せて学習をぶんぶん回します。
だいたい1epochに50sec程度なので一時間半程度でしょうか。
自分のPCのリソースを使っているわけではないので、他の作業ができるのがColabのいいところです。
結果を見る
お楽しみの時間です。学習履歴からある程度検討はつきますが、本当の結果はテストデータを流してみるまでわかりません。
score = model.evaluate(x_test, onehot_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
わくわく。
Test loss: 0.35479568064771594
Test accuracy: 0.9192000031471252
やったぜ。
無事にacc90%を達成することができました。
学習曲線も見ておきます。
x = range(epochs)
plt.plot(x, history.history['accuracy'], label="acc")
plt.plot(x, history.history['val_accuracy'], label="val_acc")
plt.title("accuracy")
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.show()
plt.plot(x, history.history['loss'], label="loss")
plt.plot(x, history.history['val_loss'], label="val_loss")
plt.title("loss")
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.show()

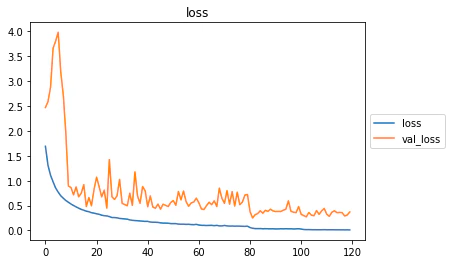
過学習も起こしていないようです。多分。
まとめ
気軽にColaboratryを使って画像分類を行うことができました。
まだまだチューニングできそうな雰囲気はありますが、気軽に行うことが目的なのでこれで十分でしょう。
やはりGPUが使えるPython環境をブラウザから無料で使うことができるのは便利です。
今回のソースコードはGitHub Gistにアップロードしてあります。
お読みいただきありがとうございました。
参考
CIFAR-10でaccuracy95%--CNNで精度を上げるテクニック--
データのお気持ちを考えながらData Augmentationする