前の話
Tensorflow 2.0.0rc0 + Tensorflow Probability 0.8.0rc0 -> RealNVP(1)
今回する話
RealNVP x MNIST
前回は二次元ベクトル $[2]$ に対してRealNVPを適用しましたが、今回は画像、つまり3次元 Tensor $[h, w, c]$ に適用します。
そして今回は Multi-Scale Architecture を実装します。多分機能的な実装はできていますが、本家の実装とはかけ離れた実装をしているので半分くらいオリジナルになると思います。(このライブラリを使う以上、こうするしかないと思いますが)
tl;dr
RealNVP x MNIST notebook
repository
Multi-Scale Architecture
Multi-Scale Architecture については 前の話 を参照して下さい。要するにこれは 効率的な変数変換 をしたい、というモチベーションに基づいたアーキテクチャです。
とにかく下の画像のように関数を一つ適用するたびに関数の適用範囲を半分にして、残りの半分を目的の分布(正規分布)に近づければ良い。ということになります。
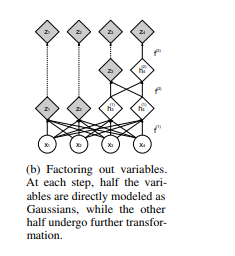
というわけで私は次のような構造を作ってこれを実装しました。
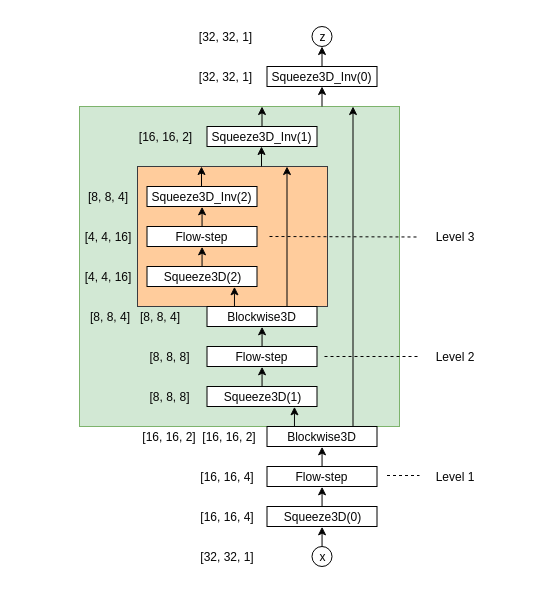
Blockwize3D Bijector は入力データを channel 軸方向に半分にして 、片方ずつ別の関数を適用できるようにしたものです。これによって、片方をそのまま 、 片方を flow-step にすることで同等の機能を達成できるようにしました。
またBlokwise3Dはそれぞれの処理が終わったらそれぞれを channel 軸方向に concat する 機構になっているため、結局すべての $z_i$ を まとめて 正規分布と対数尤度を取る、という形になっています。
こうすることで Flow-base Modelらしい $x \leftrightarrow z$ の対応が見やすいかな、と思いながら実装しました。
Blockwise3D Bijector
上参照
Squeeze3D Bijector
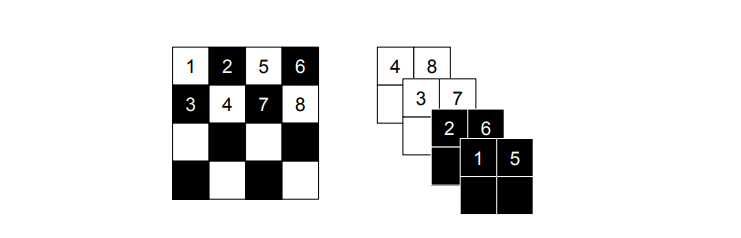
入力データ $[h, w, c]$ に対して、次のように処理を加えて、 $[h/2, w/2, 4c]$ のサイズに変形します。
- $h$ 軸方向に 2 分割、 $w$ 軸方向に 2 分割して、 $[h/2, 2, w/2, 2, c] = [h', d_1 , w', d_2, c]$ とする。
- $[h', d_1, w', d_2, c] \rightarrow [h', w', c, d_1, d_2]$ と軸を入れ替える。
- $[h', w', c * d_1 * d_2] = [h/2, w/2,4c]$ とする。
すると次のようにチェッカーボードを上手いこと分離したような形にできます。
難しいので、簡単に $[h, c]$ について考えましょう。
棒のようなものが想像できればOKです。
これを $[h/2,2, c]$ にすると、 $h_i$ と $c_i$ の組み合わせは一緒にして、2つずつグルーピングします。
$[h/2, c, 2]$ にしたときは、第2軸と第3軸が入れ替わっただけです。
$[h/2, 2c]$ にしたときは、棒をくっつける面が変わっただけです。
import numpy as np
x = np.array([[1, 2, 3, 4, 5, 6], ['a', 'b', 'c','d', 'e', 'f']]).transpose()
x.shape # => (6, 2) == (h, w)
x = x.reshape([3, 2, 2])
x[0] # => [['1', 'a'],
# ['2', 'b']]
x = x.transpose([0, 2, 1])
x[0] # => [['1', '2'],
# ['a', 'b']]
x = x.reshape([3, 4])
x[0] #=> ['1', 'a', '2', 'b']
x[1] #=> ['3', 'c', '4', 'd']
x[2] #=> ['5', 'e', '6', 'f']
channel 軸方向に見たとき、奇数番目が上、偶数番目が下、になっていることがわかります。
(Coupling Bijector や Blockwise3D Bijector はその機能の都合上、 channel 軸のサイズが $2n$ である必要があるため、この Bijector は必須です。)
Coupling Bijector
前回作ったものはベクトルに対して適用可能な Coupling Bijector でしたが、今回は画像です。次元数が違うんです。
このため、別の実装を用意する必要がありました。
記事中にソースコードが何もないとつまらないので、一応貼っておきます。
class RealNVP(tfb.Bijector):
def __init__(
self,
input_shape,
# ??? this bijector do Tensor wise quantities. (I don't understand well...)
forward_min_event_ndims=3,
validate_args: bool = False,
name="real_nvp",
n_hidden=[512, 512],
**kargs,
):
"""
Args:
input_shape:
input_shape,
ex. [28, 28, 3] (image) [2] (x-y vector)
forward_min_event_ndims:
this bijector do
1. element-wize quantities => 0
2. vector-wize quantities => 1
3. matrix-wize quantities => 2
4. tensor-wize quantities => 3
n_hidden:
see. class NN
**kargs:
see. class NN
you can inuput NN's layers parameter here.
"""
super(RealNVP, self).__init__(
validate_args=validate_args,
forward_min_event_ndims=forward_min_event_ndims,
name=name,
)
assert input_shape[-1] % 2 == 0
self.input_shape = input_shape
nn_layer = NN(input_shape[-1] // 2, n_hidden)
nn_input_shape = input_shape.copy()
nn_input_shape[-1] = input_shape[-1] // 2
x = tf.keras.Input(nn_input_shape)
log_s, t = nn_layer(x)
self.nn = Model(x, [log_s, t], name=self.name + "/nn")
def _forward(self, x):
x_a, x_b = tf.split(x, 2, axis=-1)
y_b = x_b
log_s, t = self.nn(x_b)
s = tf.exp(log_s)
y_a = s * x_a + t
y = tf.concat([y_a, y_b], axis=-1)
return y
def _inverse(self, y):
y_a, y_b = tf.split(y, 2, axis=-1)
x_b = y_b
log_s, t = self.nn(y_b)
s = tf.exp(log_s)
x_a = (y_a - t) / s
x = tf.concat([x_a, x_b], axis=-1)
return x
def _forward_log_det_jacobian(self, x):
_, x_b = tf.split(x, 2, axis=-1)
log_s, t = self.nn(x_b)
return tf.reduce_sum(log_s)
ほとんど変わりませんが、対象がベクトルからTensorになったので、forward_min_event_ndims が 3 になっています。
同様に NN のレイヤーも全結合層から畳み込み層になっていますが、 notebook を見たほうが良いので割愛します。
Permutation
[Coupling Bijector][Coupling Bijector] のところを見ると、黒い部分と白い部分が固定位置にあるため、同じ関数を繰り返し適用しても同じ部分が同じ役割しかできなさそう、という直感が働くと思います。これのために、RealNVPでは、channel 軸に対して要素の順序を反転するという手法を用います。これが Permutation Bijector です。
これは channel 軸方向のみの操作なので forward_min_event_ndims=1 、そして行の入れ替えしかしていないので、log_det_jacobian = 0 となります。更にこれは固定値ですから、Bijector クラスの初期化子である is_constant_jacobian は True となります。
Transform Distribution
今回はTransform Distribution の定義が前回とやや異なります。
flow = tfd.TransformedDistribution(
event_shape =[32, 32, 1],
distribution=tfd.Normal(loc=0.0, scale=1.0),
bijector=flow_bijector
)
つまり正規分布 tfd.Normal から event_shape=[32, 32, 1] の形のデータを求める先のデータとして扱いますよ、ということになります。Multivariate Normal distribution の方が良いのではないか、と思ったのですが、実装上うまく行かなかったことと、正規分布の再生性を信じた結果、この形にしました。(scale=1.0 の部分がちょっと怪しいですが、おおよそうまく行きます)
訓練
前回と同様です。
推論
右上は無視して大丈夫です。
上側は元のテストデータ(入力)
下側は入って正規分布になって戻ってきたデータ( $f^{-1}(f(x))$ )
右下は2つのデータを正規分布上で混ぜたもの、となっています。

次の話
Tensorflow 2.0.0rc0 + Tensorflow Probability 0.8.0rc0 -> Glow