はじめに
こんにちは!
突然ですが、みなさんはGitがどのようにコミット履歴を管理しているかご存知でしょうか。
以前、私は以下のようなGitについての会話をしていました。
~とある会話~
Aさん「へぇ~Gitって分散型で管理するんだねぇ~」
僕「そうなんす!そうなんす!」
Aさん「これって、ソースの管理どうしてるんかな?DBとか必要なの?」
僕「ん・・・?」
Aさん「ソースって言っても、プロジェクトの規模によっては、かなり容量が必要だと思うんだけど。」
僕「んんっ・・・???」
確かに自身のマシンでGitを利用する際は、利用のためにDBをインストールしたり、DBを起動したりなんてことはしていないです(みなさんもそうですよね?(圧))
また、少し混乱したのは、ちょうど自社のGitサーバ構築のために、私が構築作業していたことでした。
ホスティングサービス(GitLab/Giteaとか)はDBを使っています。
お前は何を保存してるんや!(いや、その時調べなさい。)
ということでこの記事では以下の内容を調べてみたので、まとめてみようと思います。
- GitのホスティングサービスはDBでどんな情報を管理しているのか
- Gitはどのようにソースの履歴管理を行っているのか
GitのホスティングサービスでのDBの役割
この内容は簡単に紹介します。
- ユーザー情報
- ユーザー名、メールアドレス、パスワードハッシュ
- アバターやプロフィール情報
- 権限やグループ所属情報
- リポジトリ情報(メタ情報)
- リポジトリ名、説明、作成日
- アクセス権限(公開/非公開、ユーザー・チームごとの権限)
- リポジトリの設定(ブランチ保護ルール、フック設定など)
- Issue / Pull Request / チケット管理
- チケット番号、タイトル、状態(Open/Closed)
- コメント、添付ファイル、担当者、ラベル
- マージリクエストやレビュー履歴
- 通知・アクティビティ
- ユーザーごとの通知設定
- アクションログ(誰がいつ何をしたかの履歴)
- CI/CD / ビルド関連の情報(ある場合)
- ビルドジョブの設定、履歴、結果
- デプロイ履歴やステータス
上記の各情報を管理していますが、今回の記事で知ってほしいポイントはソース管理(内容や履歴等)の情報は一切DBで管理していないということです。
あくまで、ホスティングサービスとして必要な機能の情報管理にしか利用をしていません。
色々な情報を管理していますが、今回は上記について理解してもらえれば十分なので、細かい説明は割愛します。
Gitはどのようにソースの履歴管理を行っているのか
こちらが本題です。
実際に簡単なリポジトリを用意してみました。
実際どのような履歴なのか見てもらってからの方が、スッと頭に入ってきやすいかと思いますので、どうぞ。
(とは言っても、ただ1つファイルを作成しているだけのコミットしかありません。)
Gitがソース管理している情報の格納場所
実際に、Gitに関する情報が入っているのは、プロジェクトリポジトリに入っている「.git」というディレクトリですね。
GitはこのディレクトリがあることでこのプロジェクトがGitによって管理されていることを判断します。
git initの実行で、.gitディレクトリが作成されますね。
以下、.gitディレクトリの構成です。
今回、特に注目してほしいのはobject配下になります。
.git/
├── HEAD # 現在チェックアウト中のブランチ参照
├── config # リポジトリごとの設定ファイル
├── description # GitWeb用のリポジトリ説明(通常は無視される)
├── hooks/ # フック(スクリプト)のディレクトリ
│ ├── pre-commit
│ ├── commit-msg
│ └── ...
├── info/ # 補助情報
│ └── exclude # .gitignore に似たローカル無視設定
├── objects/ # Gitオブジェクトを格納 ★★★
│ ├── info/
│ ├── pack/
│ └── <2文字>/<残り38文字のSHA1ハッシュファイル>
├── refs/ # ブランチ、タグ、リモート参照
│ ├── heads/ # ブランチの先端コミット
│ ├── tags/ # タグの先端コミット
│ └── remotes/ # リモートブランチ
├── logs/ # 操作ログ
│ ├── HEAD
│ └── refs/...
├── index # ステージングエリア(インデックス)情報
└── packed-refs # パックされたrefs情報
「.git/objects/」がGitの履歴・内容を格納しています。
他ディレクトリについても、Gitを触っていれば、こんな情報がここに入りそうだなっていうのはなんとなくわかってもらえるかなと思います。
.git/obejctの構成
.git/obejctの構成は以下のようになります。
.git/
└── objects/
├── info/ # 補助的情報
├── pack/ # パックファイル格納ディレクトリ
│ ├── *.pack # オブジェクトをまとめて格納したパックファイル
│ └── *.idx # packファイルの索引(オブジェクト検索用)
└── <2文字>/ # ハッシュ値の先頭2文字で分割されたディレクトリ
└── <残り38文字のSHA1ハッシュファイル>
# 単一オブジェクト(コミット、ツリー、ブロブ、タグ)を格納
説明する前の予備知識
Gitはコミット内容や修正内容などの情報をSHA1でハッシュ化した値として保持します。
このハッシュ化して管理する情報(コミットやファイル編集内容など)をオブジェクトと呼びます。
SHA1(Secure Hash Algorithm 1)はハッシュ関数の一種です。
入力データ(文字列やファイル)を固定長の 160ビット(20バイト) のハッシュ値に変換します。
Gitは、管理するオブジェクトをこのハッシュ化した値で管理します。
このあと説明する「objects/<2文字>/<残り38文字>」というのは、合計40文字でディレクトリが表現されています。
この40文字は20バイトにて表現しており、各ハッシュ値に対応する値となっています。
objects/<2文字>/<残り38文字>
「objects/<2文字>/<残り38文字>」というディレクトリはローカルにてコミットなどを行った際に作成されることが多いです。(一応、Gitが自動的に作成する場合や、コマンドで作成したりすることもできるようです。)
そのため、実際にローカルにてコミットなどの作業した人と、クローンを行った人ではGit自体の履歴の表示が同じだとしても、「.git/object」配下の内容が異なる可能性のあることに注意してください。
実際に、私の方でローカル作業したリポジトリの構成とクローンしたリポジトリの構成を以下に提示します。
■ローカルにて作業したリポジトリ

■クローンしたリポジトリ

ディレクトリの構成が異なりますね。しかし、エディターなどでソースを確認すると、同じ内容となっています。
Gitはこのハッシュ化された「/<2文字>/<残り38文字>」というディレクトリの中に履歴情報を保持していますが、このオブジェクトがある程度増えてきたタイミングで「.git/object/pack/」に整理した情報を移すような仕組みとなっているようです。
クローンした際は、もう既に整理されているため、「/<2文字>/<残り38文字>」が存在せず、「.git/object/pack/」に整理済の情報を保持しています。
実際に、「.git/object/pack/」を見てみましょう。
■ローカルにて作業したリポジトリ

■クローンしたリポジトリ

ローカル作業した方はまだ履歴情報がそこまで多くなく、整理されていないタイミングなので空です。
一方、クローンしたリポジトリは、最初から整理された状態なので、各種ファイルが存在します。
オブジェクトの整理
ちなみにオブジェクトの整理したい場合は、該当するリポジトリに移動し、以下コマンドを実行すればOKです。
git repack -a -d
オプションの詳細は以下です。
-a … すべてのオブジェクトを対象
-d … 古い個別オブジェクトを削除
上記を実行することで、「.git/object/pack/」配下に各種「.pack」と「.idx」ファイルが作成されます。
.git/object/pack/の内容
存在する*.packファイルと*.idxファイルについて説明します。
■pack ファイル
オブジェクトデータの圧縮格納をしています。
繰り返しになりますが、ここでのオブジェクトとは、ファイル履歴やコミット内容などです。
Git オブジェクトをまとめて一つのファイルにしてディスク節約とアクセス高速化を実現します。
圧縮形式はzlib圧縮です。
■idx ファイル
packファイル内オブジェクトへのインデックス情報を保持しています。
Git がオブジェクトを探すときにpackファイルを一から読む必要がないように、インデックス情報を持ちます。
BDなどのインデックスと同じような役割です。
以下のようなコマンドで中身を確認することが可能です。
git verify-pack -v pack-xxxx.idx
これだけでは理解がしづらいので、実際に履歴の中身を確認してみましょう。
実際に履歴情報を確認してみる
実際に利用するリポジトリはこちら
以下コマンドを実行し、インデックスの情報を確認してみます。
$ git verify-pack -v .git/objects/pack/pack-6b0cb53015509791abd628b1de26212478d6cd04.idx

左から順番に、オブジェクトハッシュ値、データの区分、圧縮前容量、圧縮後容量、delta圧縮の参照回数となります。
注目してほしいのは、2番目のデータ区分です。
区分には以下があります。
| オブジェクト種類 | 内容 | SHA1 の対象 | 特徴・用途 |
|---|---|---|---|
| blob | ファイルの中身 | ファイルのバイト列 + blob <サイズ>\0
|
実際のファイルデータを保存。ファイル名は含まれない。 |
| tree | ディレクトリ構造 | ディレクトリ内のエントリ情報 + tree <サイズ>\0
|
ディレクトリの中身(ファイル名、パーミッション、対応する blob/tree の SHA1)を管理。 |
| commit | コミット情報 |
commit <サイズ>\0 + (親コミットSHA1 + tree SHA1 + 作者情報 + 日時 + メッセージ) |
履歴管理の単位。どの tree を指しているか、親コミット、メタ情報を持つ。 |
| tag | タグ情報 |
tag <サイズ>\0 + (対象オブジェクトSHA1 + タグ名 + 作者情報 + メッセージ) |
ブランチやコミットなどの特定オブジェクトを指すためのラベル。注釈付きタグの場合は追加情報も含む。 |
今回、話をシンプルにするため、「tag」については取り扱いません。
履歴を追う際は、commit > tree > blobの順で追っていけば、履歴情報を得ることが可能です。
実際にcommitから見ていきましょう。
Commitの内容
実際にコミットの内容が確認したいので、以下のコマンドを実行します。
git cat-file -p e81ad8a2b2dbd9adfdf83ffda5e54f243483e5bf(←Commitのハッシュ値)
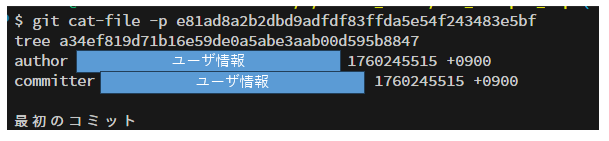
一回目のコミットコメントの内容が下部に表示されていることがわかります。
また、(非表示にしていますが)コミッターなどの情報も記載が確認できます。
ユーザ情報の後ろに記載がある数値は「Unixタイムスタンプ」です。
そのため、いつコミットしたのかなどの情報も残っているのがわかります。
Unixタイムスタンプについてはこちらを参考にしてください。
次は、Treeについて確認します。
このCommitに紐づくのはTreeの箇所に記載のある「a34ef819d71b16e59de0a5abe3aab00d595b8847」です
Treeの内容
以下のコマンドを実行します。
git cat-file -p a34ef819d71b16e59de0a5abe3aab00d595b8847(←Treeのハッシュ値)

リポジトリを確認してもらえれば、修正対象のファイルは「/dir/test.txt」でした。
最初に一番親となるディレクトリの情報の「dir」が出てきましたね。
引き続き、Treeの記載があるので、再度コマンド実行してみます。
git cat-file -p 4edc213b4e3fa2df79a630a729d0a8fbe5151a29(←Treeのハッシュ値)

test.txtが表示されました。
一つ前はデータの区分が「tree」でしたが、今回はファイルなので「blob」となっています。
履歴管理対象のファイルパスまで辿ることができたので、最後に修正内容について確認してみます。
Blobの内容
git cat-file -p a27b77a03a2e378c10ca262352882e3908be9f8d(←Blobのハッシュ値)

実際にファイルの中身を確認することができました。
このようにコミット情報、対象ファイルのパス、修正内容を保持しているんですね。
Gitのリビジョンの値がどのように決まっているのか?
よくGitの履歴を確認していて、出てくるリビジョンについてです。これは、commitのハッシュ値のことを指しています。
そのため、リポジトリ内で一意の値になるようになっているんですね。
こんなところでこやつ(リビジョン)のルーツを知れるとは・・・笑
まとめ
このようにGitは履歴に関する情報をハッシュ値をベースに管理することで、履歴管理の容量自体が少なくなります。
DBなどは利用せずにソースの管理を実現できます。
また、少し触れたdelta圧縮を利用し、差分しか保持しないようにし、できるだけ容量が増えないようにしています。
今回の記事はGitの履歴管理方法が知りたかったので、このあたりで終わりにします。
ここまで読んでいただき、ありがとうございました!
それでは✋️