ちょっと前のニュースになってしまいますが、AlphaGoが世界チャンピョンに3連勝したのはすごかったですよね。それに触発されて、今回は同じボードゲームのオセロのAIを作ってみました。
なぜオセロにしたかというと、コンピュータリソースが足りない!!からです。AlphaGoの開発では50GPUで3週間というとてつもないことをしていますが、そんなの個人では絶対不可能です。そこで碁盤が小さくルールも簡単なオセロを選びました。
AlphaGoを話題にあげましたが、AlphaGoとは使っている技術が違います。AlphaGoは教師あり深層学習と、深層強化学習と、モンテカルロ木探索の3つを組み合わせていますが、今回は教師あり深層学習のみを使っています。性能は出ませんが、逆に、アルゴリズムがとてもシンプルなので、今聞いた後半の2つを知らない方でも(私も深層強化学習は分かりますがモンテカルロ木探索はよく分かりません)、深層学習の知識のみで理解できちゃいます!以下の説明では深層学習に関するある程度の理解(ゼロから作るディープラーニングを読んだことがあるくらい=私)があるとします。
概要
オセロの譜面データとしてはフランスオセロ協会のサイトのデータを使いました。WTHORという謎のフォーマットを使っていたのでデータの加工が結構大変でした。
ニューラルネットワークは、入力データに譜面状態(0:なし,1:自分の石,2:相手の石)を、出力データに各手を打つ確率を使いました。教師データには自分が打った手の位置を使いました。言葉だけだと分かりにくいと思うので、図を示します。
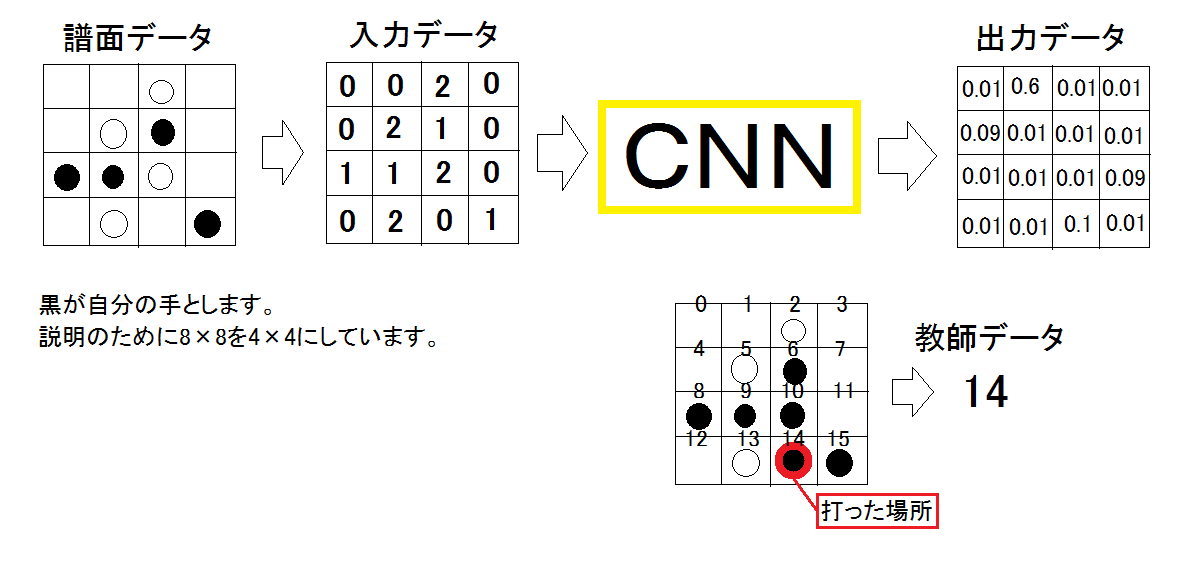
ニューラルネットワークの構造
AlphaGoと同じく畳み込み層のみを使い、全結合層は使いませんでした。出力が2次元データなのでCNNのままが良いと考えられるからです。出力層にはSoftmaxを使い、他の層ではConv->BN->ReLUとしました。Batch Normalization(BN)を導入すると学習が安定するのでおすすめです。
ニューラルネットワークの学習
損失関数にはオーソドックスに交差エントロピー誤差を使いました。
最適化アルゴリズムにはAdamを使いました。SGDに比べ、学習が早く進み、最終的な結果も良好です。
ソースコード
お待ちかねのソースコードはgithubにあげてあります。
細かいパラメータなどはソースコードを見てください。
学習結果
AIの性能は…
ルールはだいたい理解したみたいですが、残念ながらあまり強くはなりませんでした。
原因はおそらく教師あり深層学習のみを用いたことでしょう。
しかし、時間の都合上CPUだけのPCで2時間半くらいしか学習していないので、まだ強くなる可能性もあります。
ということで、GPUを持っている人求む!
GPUで1日ぐらい学習すれば強くなるかも?