まだまだ処理のボトルネックがあるようです。無思慮にも数百件のデータテーブルのsortを数万件している箇所があるのですが、外すわけにもいかず、これもどの方法が最速なのか調べないとなりません。ついでにやっておきます。
参考リンク:
Sort a data.table fast by Ascending/Descending order@StackOverflow
データ構造による違い
data.frame(df)
普通にデータフレームでソートします。
a <- df[order(df$v),]
data.table with base(dtbase)
データテーブルのソートを標準ソート関数で行います。
a <- dt[base:::order(v),]
data.table(dt)
データテーブルのソートをdata.tableのソート関数で行います。
a <- dt[order(v),]
data.table with setorder (dtref)
データテーブルのソートをreferenceを利用した、高速なsetorder関数で行います。
a <- setorder(dt, v)
ベンチマーク
100万から1000万件のソートを1回ずつ行いました。
標準のソートはdata.tableのそれに比べて10倍も遅いので使わない方が良いです。
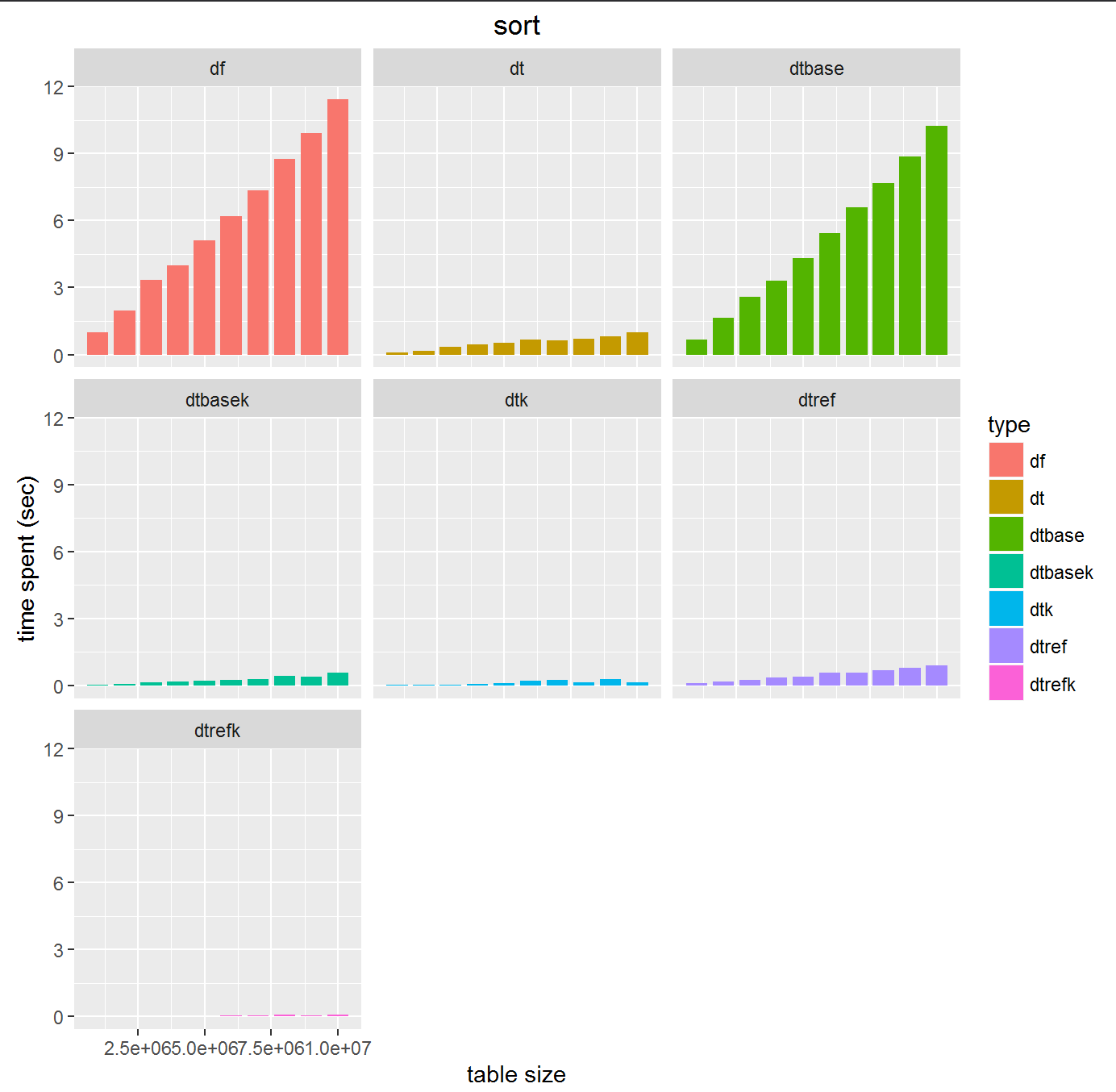
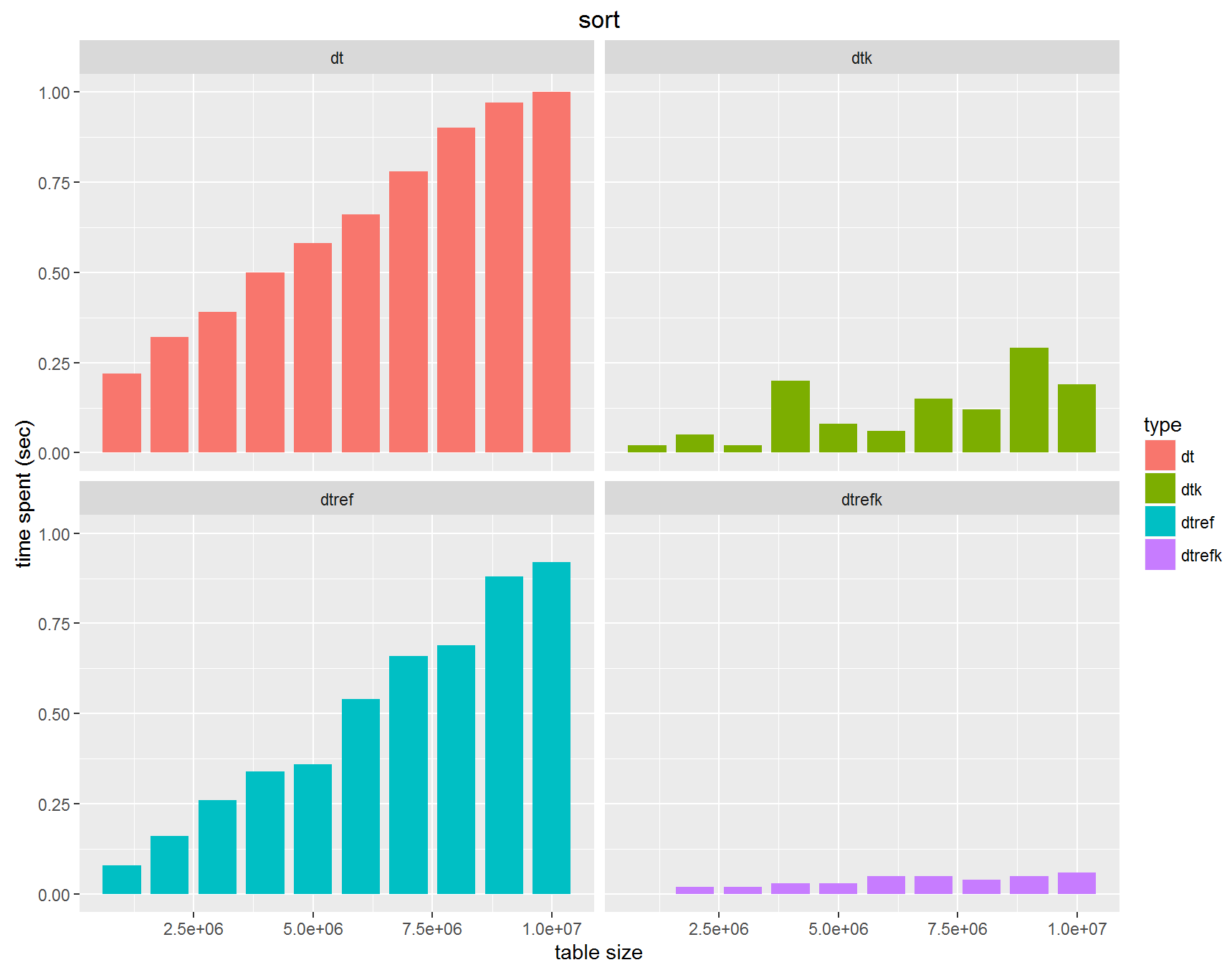
keyを設定する効果は大いにあるといえます。
reference を用いたソート方法はkeyを設定した場合さらに数倍のスピードをもたらします。
まとめ
結局今回もdata.tableを普通のソートを使っていたので、最速のsetorderを使うことで、10s -> 100msと、約100倍高速になることがわかりました。