はじめに
AWS 上で環境を構築する際には、障害発生を想定した可用性のある構成を検討する必要があります。そして、AWS では設計・構築などのノウハウが纏められた AWS Well-Architected Framework が提供されています。これを元にしてベストプラクティスに沿った対応が可能となっています。しかし、設計者の経験値が高くない場合は、本当に要件に合わせた構成が作成できているか不安になる場面もあるかと思います。
もし、必要な RTO(目標復旧時間)とRPO(目標復旧時点)を指定することで、環境がその条件を満たしているか回答してくれる仕組みがあれば、その不安が解消できます。そこで今回は、AWS が評価サービスとして提供している AWS Resilience Hub について取り上げ、具体的にどのような評価や提案ができるのかという点を検証します。
この記事を読んで、なるほどと感じた方は是非サービスを活用してみてください。
RTO と RPO について
復旧戦略を検討する際に重要なキーワードが、RTO(目標復旧時間)とRPO(目標復旧時点)です。以下の通り、要求される内容によって冗長化構成やバックアップ頻度など、環境設計に大きく影響します。
| 項目 | タイトル |
|---|---|
| RTO (目標復旧時間) |
障害が発生してからシステムやサービスが復旧するまでの最大許容時間。例えばRTOが2日の場合、障害発生から2日以内にシステムを復旧させる必要があります。フェールオーバー計画などが影響します。 |
| RPO (目標復旧時点) |
障害が発生した時点からどれだけ過去のデータを復旧できるかの目標。例えばRPOが1日の場合、障害発生時点から1日前までのデータを復旧できる状態にしておく必要があります。バックアップ頻度などが影響します。 |
AWSでは、AWS Well-Architected Framework の「信頼性の柱」「ディザスタリカバリ (DR) を計画する」において、以下の5つの項目に対応が纏められています。その中で要求されるRTOやRPOに対する戦略が記載されています。
| 項目 | タイトル |
|---|---|
| REL13-BP01 | ダウンタイムやデータ損失に関する復旧目標を定義する |
| REL13-BP02 | 復旧目標を満たすため、定義された復旧戦略を使用する |
| REL13-BP03 | ディザスタリカバリの実装をテストし、実装を検証する |
| REL13-BP04 | DR サイトまたはリージョンでの設定ドリフトを管理する |
| REL13-BP05 | 復旧を自動化する |
AWS Resilience Hub サービスについて
AWS Resilience Hub は、AWS 上のアプリケーションの回復⼒の定義・検証・追跡を⼀元化したサービスです。AWS上に構築したアプリケーションを評価して、達成すると推定される値(推定ワークロード RTO/RPO)を算出します。問題を特定して対策を提案してくれます。
| # | 特徴 |
|---|---|
| 1 | 障害耐性の弱点を明らかにする。 |
| 2 | RTO (目標復旧時間) と RPO (目標復旧時点) を達成できるかどうかを見積もる。 |
| 3 | 本番環境にリリースされる前に問題を解決する。 |
事前の設計段階で評価できる AWS Well-Architected Framework のレビューとは異なり、作成済みの環境の評価を実施できることがポイントになります。
具体的な流れについて解説します。
手順1:アプリケーションを作成する
アプリケーションが稼働するAWS 環境を作成します。対象のリソースにタグ付けをしておき、マイアプリケーションとして登録します。

手順2:AWS Resilience Hub へのアプリケーション追加
AWS Resilience Hub に作成したアプリケーションを追加します。

この説明では myApplications のアプリケーションを追加していますが、AWS CloudFormation スタックや AWS Resource Groups、Terraform 状態ファイルなどを利用して登録することも可能です。
手順3:アプリケーションの発行
アプリケーションのリソースの発行を行います。その時点のリソース情報をもとにバージョン情報が登録されます。このバージョン時点でのリソースが評価されるので、その後リソースが追加されても評価対象にはなりません。
手順4:アプリケーションの評価
設定されている耐障害性ポリシーに基づいて、先ほど作成したバージョンに対してアプリケーションを評価します。耐障害性ポリシーは要求するRTOとRPOを定義した内容になります。

結果画面では耐障害性ポリシーに沿った評価結果がレポートされます。
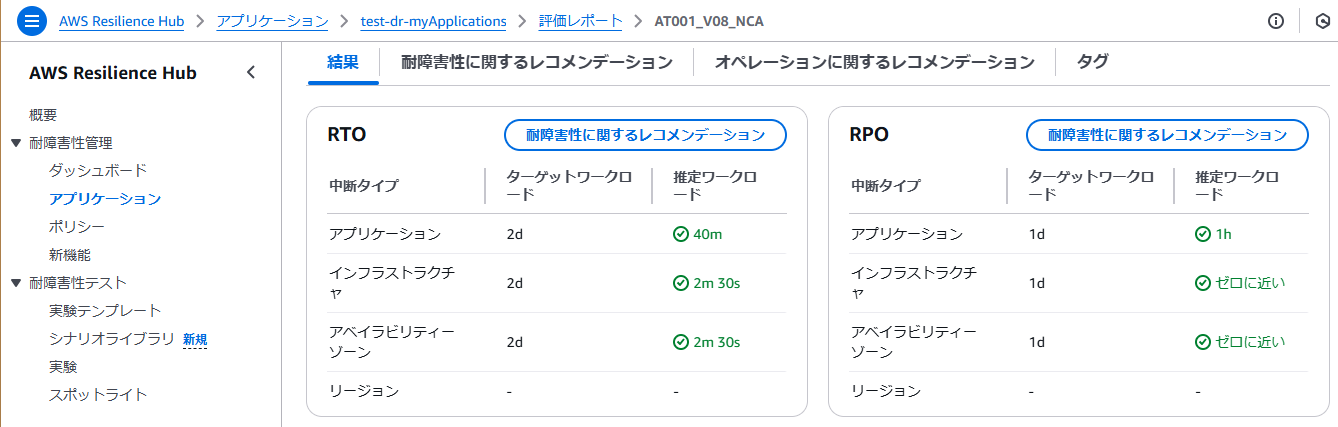
条件を満たしていない項目に対しては、対策の提案が実施されます。
この部分は日本語化されておらず英語で表示されます。
複数のオプションが提示されるため、その中から必要なオプションを選択して、対応を実施します。

オプションの内容としては変更点や料金情報、対応後のRPO/RTOが提示されるので、重視する内容を元にオプションを選択することができます。

対策が完了したら、再度評価を実施して、改善していることを確認します。
これが一連の流れです。
なお、AWS Resilience Hub にはアプリケーションを評価する以外にも、評価した環境に対するアラームの設定や耐久テストを提案してくれなど、様々な機能が実装されています。ただし、今回のブログの内容は耐久性の評価の部分が中心となるため、それ以外の機能の詳細説明は割愛しています。
今回のブログ内で検証すること
今回のブログでは、AWS Resilience Hub が耐障害性ポリシーの設定ごとにどのような指摘と提案を実施してくるのかを確認します。
今回検証するAWS構成は以下となります。本来冗長化しておく一部の設定を、敢えて実施していません。

当初環境の設定に関するポイントは以下の通りです。
| サービス | 現状の問題点 |
|---|---|
| S3 bucket | ・バックアップが未設定。 |
| EFS | ・バックアップが未設定。 |
| NatGateway | ・2つ目のAZには未作成。 |
| RDS | ・バックアップが未設定。 ・片方のAZのみに作成。 |
| ELB | ・AutoScaling設定の対象AZを片方のみに設定。 |
上記の制限がある環境に対して、アプリケーションの評価と対策を実施します。耐障害性ポリシーはアプリケーション、インフラストラクテャ、アベイラビリティゾーン、リージョンの4つの階層で評価します。それぞれ以下の状況になった場合が前提となっています。
| 項目 | 内容 |
|---|---|
| アプリケーション | オペレーターのエラー、ソフトウェアの不具合等によるアプリケーションの停⽌。 |
| インフラストラクテャ | EC2 や RDS などのハードウェアの停⽌。 |
| アベイラビリティゾーン | 1 つ以上の AZ が利⽤できない。 |
| リージョン | 1つ以上のリージョンが利⽤できない。 |
次に耐障害性ポリシーの種類ですが、7つのレベルが定義されています。
| 区分 | 内容 | 評価対象 |
|---|---|---|
| Non Critical Application | 非クリティカル | AZまで |
| Important Application | 重要 | AZまで |
| Critical Application | クリティカル | AZまで |
| Mission Critical Application | ミッションクリティカル | AZまで |
| Global Critical Application | クリティカル | リージョンまで |
| Global Mission Critical Application | ミッションクリティカル | リージョンまで |
| Foundational Core Service | 基盤となる IT コアサービス | リージョンまで |
大きく2つに分かれており、アプリケーション、インフラストラクチャ、アベイラビリティゾーンまでの3段階を評価するのが以下の4つのポリシーです。ポリシーごとにRTOとRPOが異なっており、右側に行くほど厳しい基準値が求められます。

アプリケーション、インフラストラクチャ、アベイラビリティゾーンまでの3段階に加えてリージョンまで含めて評価するのが以下のポリシーです。

対象のアプリケーションがリージョン障害発生時の復旧対応を想定するかどうかで利用する耐障害性ポリシーが変わります。例えば東京リージョンが利用できなくなった時のために、大阪リージョンでの業務継続を視野に入れる場合は、リージョンレベルも含めた評価が必要になります。
検証1:Non Critical Application
それでは、1つ目の耐障害性ポリシーである Non Critical Application からはじめます。
Non Critical Applicationで求められる基準は以下の通りです。
2日以内に障害発生前1日以内の状態に復旧する必要があります。

前提は以下の通りです。
先ほど説明した当初構築環境に対して評価を実施します。
| 区分 | 内容 |
|---|---|
| 前提の環境 | 当初構築環境 |
| 評価するポリシー | Non Critical Application |
この基準のもとに評価すると、アプリケーション、インフラストラクチャ、アベイラビティゾーンのすべてで回復不能と評価されます。

アプリケーションでは、EFS、S3、RDS が回復不能と評価されています。バックアップが未取得のため回復できないことが指摘されています。
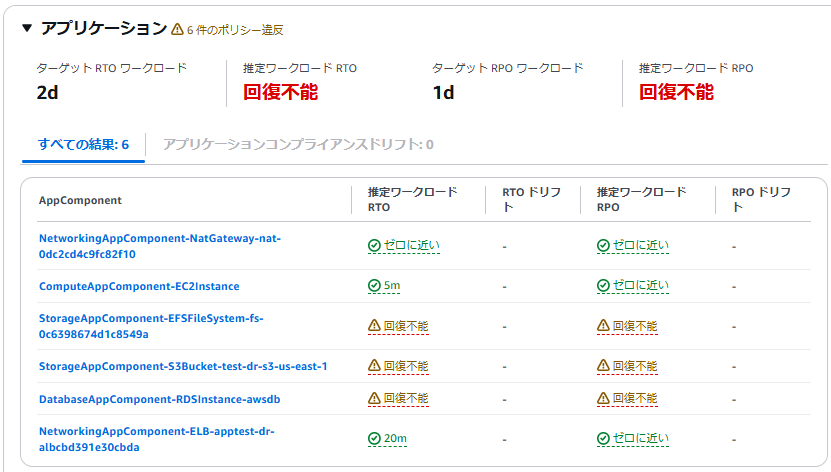
インフラストラクテャでは、RDS が回復不能と評価されています。S3 や EFS は内部的に冗長化されているサービスなので対象にはなっていません。ここではインスタンスに依存するサービスである RDS のみが指摘されています。

アベイラビリティーゾーンでは、NatGateway と RDS が回復不能であると判断されています。NatGateway は片方の AZ でしか作成されていないため指摘されています。RDS は先ほどのインフラストラクテャの際と同様の原因です。

耐障害性に関するレコメンデーションでは、複数の対応方法が提案されます。今回は以下の対応を実施しました。表の中で、RTO と RPO に 〇 が記載されているのは、その項目が満たす為の対策という意味です。また、ELBについては基準は満たしていましたが、改善の提案があったため対応しました。
| サービス | RTO | RPO | 対応内容 |
|---|---|---|---|
| S3 bucket | 〇 | 〇 | ・バケットのバージョニングをONにする。 ・AWS backupでバックアップ設定(日次)。 |
| EFS | 〇 | 〇 | ・AWS backupでバックアップ設定(日次)。 |
| NatGateway | 〇 | ・もう1つのAZにNatGateway作成。 | |
| RDS | 〇 | 〇 | ・RDSの自動バックアップを有効化。 |
| ELB | ・AutoScaling設定で2つ目のAZを追加。 ・ターゲットのEC2台数を2台に変更。 |
||
| EC2 | ・変更点特になし。 |
構成図では以下の部分で対応しています。

設定変更後の再測定結果は以下の通りで、全て基準を満たしていました。
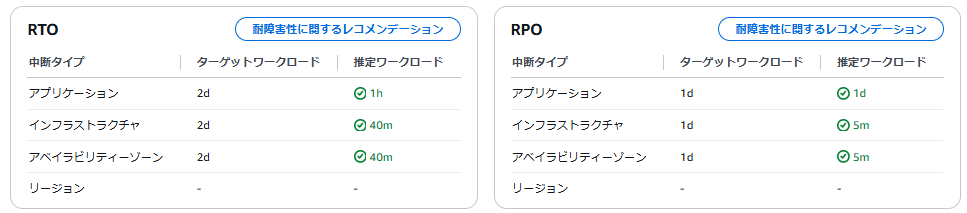
AWS Resilience Hub では、このような流れで、評価と対策が可能です。
検証2:Important Application
Important Application で求められる基準は以下の通りです。
2日以内に障害発生前4時間以内の状態に復旧する必要があります。

前提は以下の通りです。
検証1で対策済の環境に対して、評価を実施します。
| 区分 | 内容 |
|---|---|
| 前提の環境 | Non Critical Application の指摘事項対応済 |
| 評価するポリシー | Important Application |
この基準のもとに測定すると、アプリケーションの RPO が4時間以内の条件を満たしていないことが分かります。

アプリケーションでは、EFS、S3 が RPO を満たしていないことが指摘されています。これは、この2つのサービスの AWS backup バックアップ設定が、日時バックアップであるため、24時間に1回しか取得されていないためです。ここでは4時間以内の頻度でのバックアップが求められています。
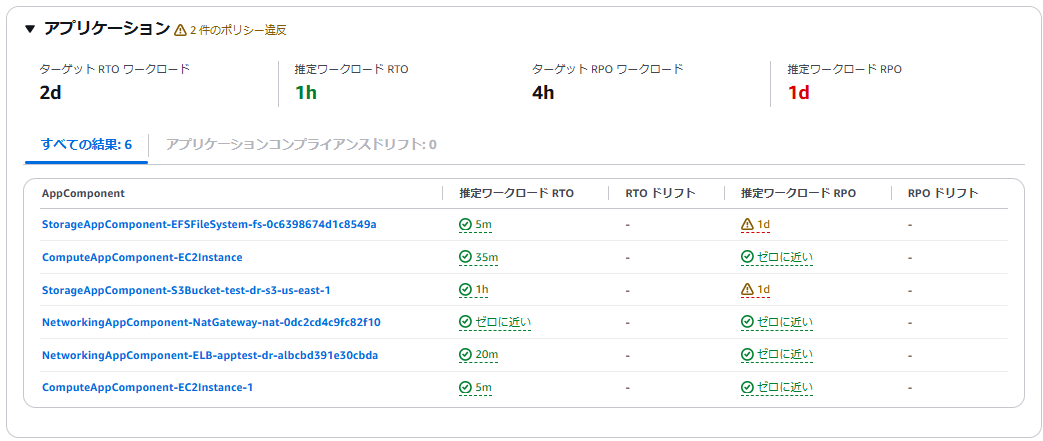
耐障害性に関するレコメンデーションでは、複数の対応方法が提案されます。
以下の対応を実施しました。
| サービス | RTO | RPO | 対応内容 |
|---|---|---|---|
| S3 bucket | 〇 | ・AWS backupでバックアップ設定変更(日次→1時間毎)。 | |
| EFS | 〇 | ・AWS backupでバックアップ設定変更(日次→1時間毎)。 | |
| NatGateway | ・変更点特になし。 | ||
| RDS | ・変更点特になし。 | ||
| ELB | ・変更点特になし。 | ||
| EC2 | ・変更点特になし。 |
構成図では以下の部分が影響します。

設定変更後の再測定結果は以下の通りで、全ての基準を満たしました。

検証3:Critical Application
Critical Application で求められる基準は以下の通りです。
4時間以内に障害発生前1時間以内の状態に復旧する必要があります。

前提は以下の通りです。
検証2で対策済の環境に対して、評価を実施します。
| 区分 | 内容 |
|---|---|
| 前提の環境 | Important Application の指摘事項対応済 |
| 評価するポリシー | Critical Application |
この基準のもとに測定すると、すでにすべての条件が満たされています。
先ほど AWS backup のバックアップ間隔を1時間に短縮したため、このポリシーの基準も超えたためです。
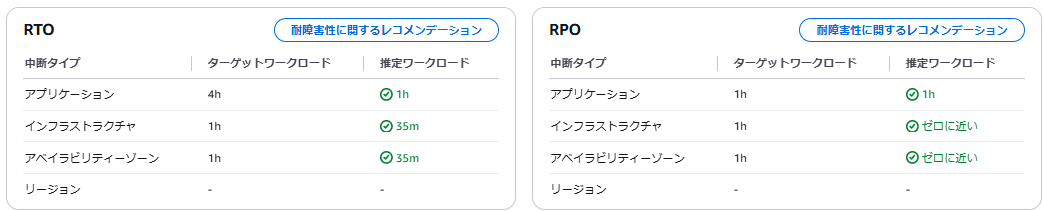
そのため、特段変更は発生しません。
| サービス | RTO | RPO | 対応内容 |
|---|---|---|---|
| S3 bucket | ・変更点特になし。 | ||
| EFS | ・変更点特になし。 | ||
| NatGateway | ・変更点特になし。 | ||
| RDS | ・変更点特になし。 | ||
| ELB | ・変更点特になし。 | ||
| EC2 | ・変更点特になし。 |
検証4:Mission Critical Application
Mission Critical Applicationで求められる基準は以下の通りです。
1時間以内に障害発生前15分以内の状態に復旧する必要があります。

前提は以下の通りです。
検証3で対策済の環境に対して、評価を実施します。
| 区分 | 内容 |
|---|---|
| 前提の環境 | Critical Application の指摘事項対応済 |
| 評価するポリシー | Mission Critical Application |
この基準のもとに測定すると、アプリケーションは RPO を、インフラストラクチャとアベイラビリティゾーンは RTO を満たしていないことが分かります。

アプリケーションでは、EFS、S3 が RPO を満たしていないと評価されています。現在の AWS backup は1時間毎の設定になっているため、15分の RPO が満たせないためです。
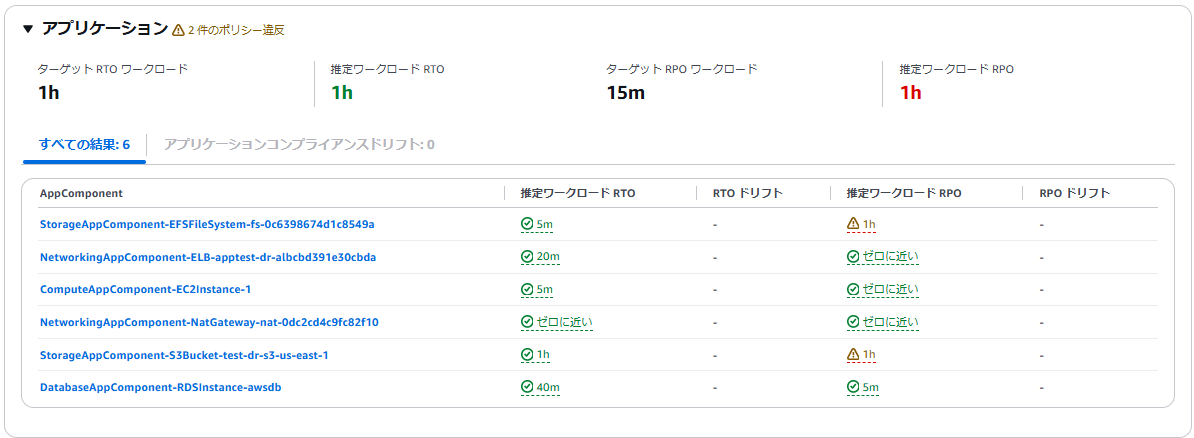
インフラストラクテャでは、RDS の RTO が基準を満たしていないと評価されています。RDS の自動バックアップからリストアする時間を40分と推定しており、5分の基準を満たしていません。

アベイラビリティーゾーンでは、RDS の RTO が基準を満たしていないと評価されています。RDS の自動バックアップからリストアする時間を40分と推定しており、5分の基準を満たしていません。これは、インフラストラクチャの項目を同じです。

耐障害性に関するレコメンデーションでは、複数の対応方法が提案されます。
以下の対応を実施しました。
| サービス | RTO | RPO | 対応内容 |
|---|---|---|---|
| S3 bucket | 〇 | ・AWS backup のバックアッププランでポイントインタイムリカバリオプションを有効化。 | |
| EFS | × | ・EFS は RPO の改善提案なし。 | |
| NatGateway | ・変更点特になし。 | ||
| RDS | 〇 | ・マルチ AZ インスタンスに移行。 | |
| ELB | ・変更点特になし。 | ||
| EC2 | ・変更点特になし。 |
構成図では以下の部分が影響します。

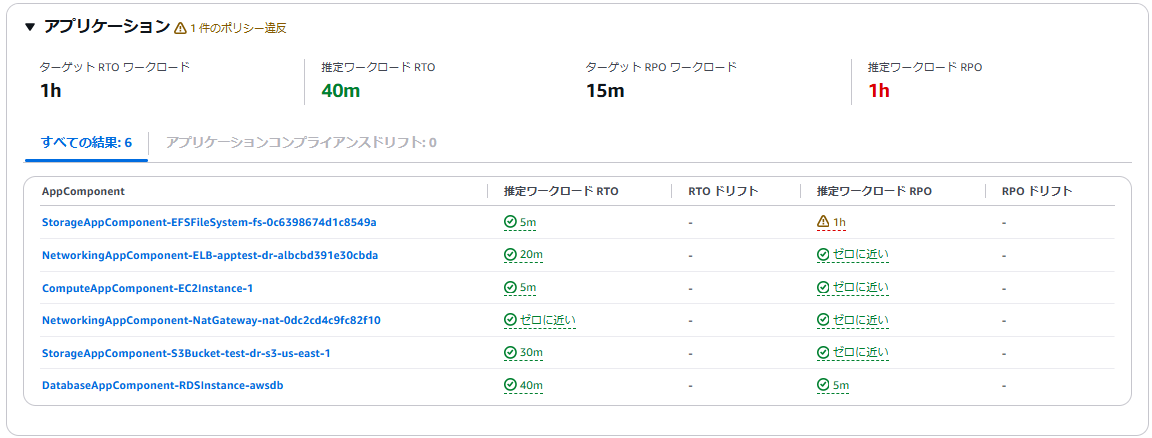
設定変更後の再測定結果は以下の通りです。
アプリケーションの RPO のみ条件を満たしていません。

これは、EFS が RPO 未達のため表示されたものですが、提案なしのため一旦このままとします。
検証5:Global Critical Application
Global Critical Applicationで求められる基準は以下の通りです。
4時間以内に障害発生前1時間以内の状態に復旧する必要があります。
また、このポリシーからはリージョンが評価項目に含まれます。

前提は以下の通りです。
検証4で対策済の環境に対して、評価を実施します。
| 区分 | 内容 |
|---|---|
| 前提の環境 | Mission Critical Application の指摘事項対応済 |
| 評価するポリシー | Global Critical Application |
この基準のもとに測定すると、リージョンの RTO、RPO を満たしてないことが分かります。

リージョンでは、S3、EFS、RDS がリージョンを跨いだレプリケーションやバックアップの設定ができていないので回復不能と表示されます。また、NatGateway も DR 環境のリージョン内に追加作成する必要がある旨を指摘されます。

耐障害性に関するレコメンデーションでは、複数の対応方法が提案されます。
以下の対応を実施しました。
| サービス | RTO | RPO | 対応内容 |
|---|---|---|---|
| S3 bucket | 〇 | 〇 | ・クロスリージョンレプリケーション (CRR) 設定を実施。 ・Amazon S3 レプリケーション時間制御 (S3 RTC) の有効化。 |
| EFS | 〇 | 〇 | ・AWS backupのリージョン間バックアップ オプションを有効。 |
| NatGateway | ・別リージョンのDR環境にNatGatewayを作成。 | ||
| RDS | 〇 | ・AWS backupのリージョン間バックアップ オプションを有効 | |
| ELB | ・変更点特になし。 | ||
| EC2 | ・変更点特になし。 |
構成図では以下の部分が影響します。

設定変更後の再測定結果は以下の通りです。
リージョンの RTO が満たしていません。

これは、別リージョンの NatGateway をリソースとして認識できていないため回復不能と表示されていますが、実際は作成済みのため、一旦このままとしています。この評価を実施するためには別リージョンリソースを手動追加する必要があります。

検証6:Global Mission Critical Application
Global Mission Critical Applicationで求められる基準は以下の通りです。
1時間以内に障害発生前15分以内の状態に復旧する必要があります。

前提は以下の通りです。
検証5で対策済の環境に対して、評価を実施します。
| 区分 | 内容 |
|---|---|
| 前提の環境 | Global Critical Application の指摘事項対応済 |
| 評価するポリシー | Global Mission Critical Application |
この基準のもとに測定すると、アプリケーションの RPO と、リージョンの RTO、RPO を満たしてないことが分かります。

アプリケーションでは、EFS が RPO を満たしていないと評価されています。現在の AWS backup は1時間毎の設定になっているため、15分の RPO が満たせないためです。
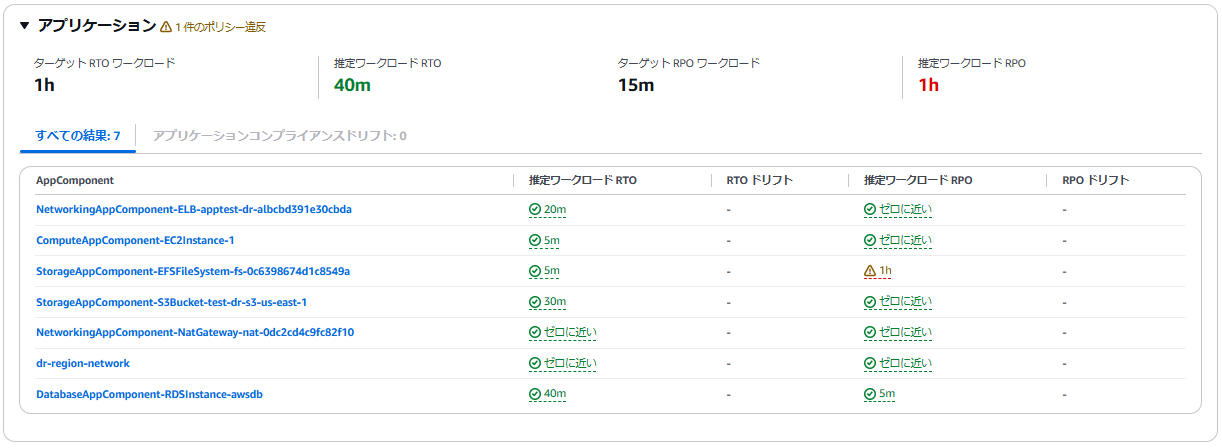
リージョンでは以下のとおり基準を満たしていないことが分かります。今のままだとRDSが別リージョンで復旧させるRTOが満たせないことを指摘されています。また、ELBのAutoScaling環境も障害時にDR環境で再構築する時間を想定するとRTOが満たせないという指摘を受けています。
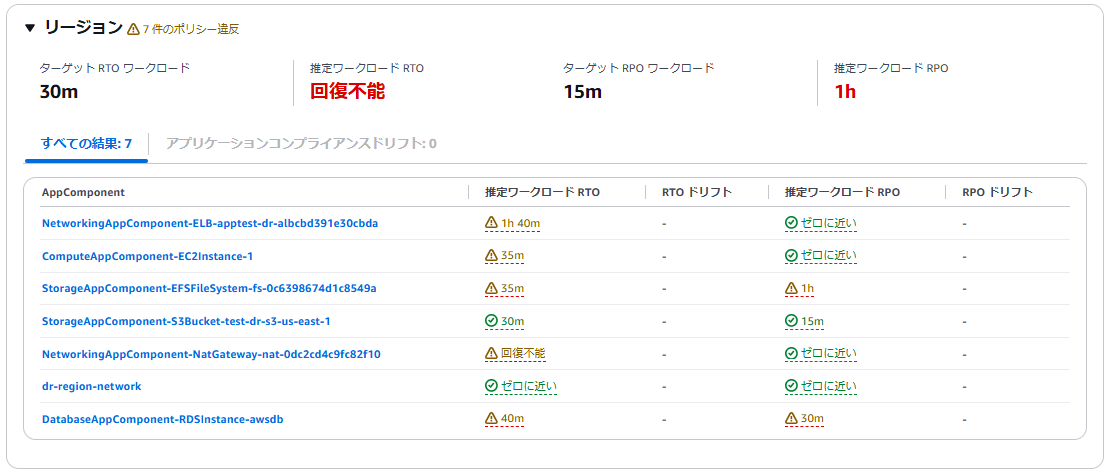
耐障害性に関するレコメンデーションでは、複数の対応方法が提案されます。
以下の対応を実施しました。
| サービス | RTO | RPO | 対応内容 |
|---|---|---|---|
| S3 bucket | ・変更点特になし。 | ||
| EFS | × | ・EFS は RPO の改善提案なし。 | |
| NatGateway | ・変更点特になし。 | ||
| RDS | 〇 | 〇 | ・別リージョンの DR 環境にリードレプリカとリージョン内 AWS バックアップ プランを備えた Amazon RDS マルチ AZ インスタンスを作成。 |
| ELB | 〇 | ・別リージョンのDR環境にELB環境を構築します。 ・Route53 で2つのリージョンの ELB のフェールオーバー設定を実施します。 |
|
| EC2 | ・変更点特になし。 |
構成図では以下の部分が影響します。
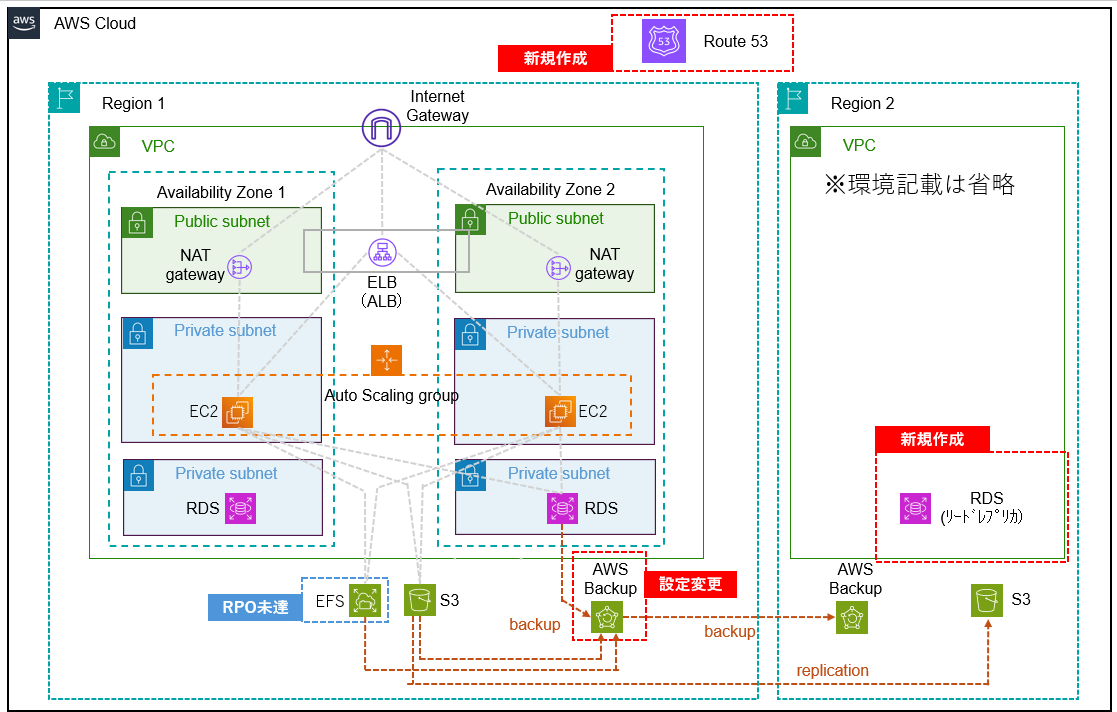
提案された内容を元に対策を実施することができます。
検証7:Foundational Core Service
Foundational Core Serviceで求められる基準は以下の通りです。
1時間以内に障害発生前15分以内の状態に復旧する必要があります。

前提は以下の通りです。
検証6ではなく検証5で対策済の環境に対して、評価を実施します。
| 区分 | 内容 |
|---|---|
| 前提の環境 | Global Mission Critical Application の指摘事項対応済 |
| 評価するポリシー | Foundational Core Service |
この基準のもとに測定すると、アプリケーションのRPOと、リージョンの RTO、RPO を満たしてないことが分かります。

アプリケーションでは、EFS が RPO を満たしていないと評価されています。現在の AWS backup は1時間毎の設定になっているため、15分の RPO が満たせないためです。
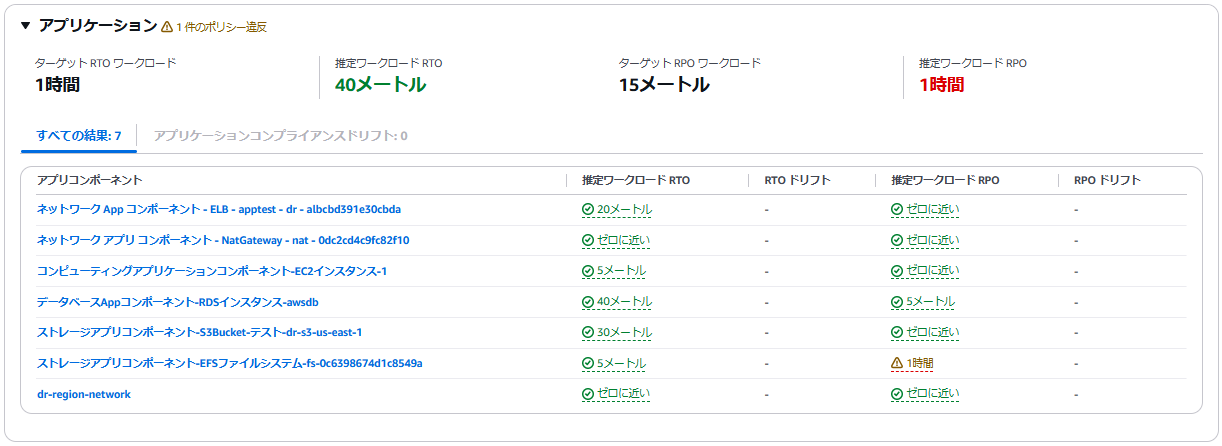
インフラストラクテャでは以下のとおり基準を満たしていないことが分かります。ELBはヘルスチェックによる切替の時間、RDSはマルチAZの切り替えの時間が、RTOを満たしていません。

アベイラビリティゾーンでは以下のとおり基準を満たしていないことが分かります。インフラストラクチャと同様の理由です。

リージョンでは以下のとおり基準を満たしていないことが分かります。今のままだとRDSが別リージョンで復旧させるRTOが満たせないことを指摘されています。また、ELBのAutoScaling環境も障害時にDR環境で再構築する時間を想定するとRTOが満たせないという指摘を受けています。また、S3もリージョン間のレプリケーションの時間がRTOを満たさないと指摘されています。
耐障害性に関するレコメンデーションでは、複数の対応方法が提案されます。
以下の対応を実施しました。
| サービス | RTO | RPO | 対応内容 |
|---|---|---|---|
| S3 bucket | × | × | ・S3 は RPO の改善提案なし。 |
| EFS | × | × | ・EFS は RPO の改善提案なし。 |
| NatGateway | ・変更点特になし。 | ||
| RDS | 〇 | 〇 | ・別リージョンの DR 環境にリードレプリカとリージョン内 AWS バックアップ プランを備えた Amazon RDS マルチ AZ インスタンスを作成。 ・Amazon RDS インスタンス用の RDS プロキシを作成して設定する。 |
| ELB | 〇 | ・別リージョンのDR環境にELB環境を構築します。 ・Route53 で2つのリージョンの ELB のフェールオーバー設定を実施する。 |
|
| EC2 | ・変更点特になし。 |
提案された内容を元に対策を実施することができます。
検証に関するまとめ
検証1~7の通り、各段階で要求される RTO、RPO に基づいて改善提案が実施されています。AWS 環境を構築した上で、要求している可用性が確保できているかをチェックする機能としては活用できると感じました。
以下は耐障害性ポリシーごとに S3 で提案されて実践した内容です。AWS backup のバックアップポリシーの設定時間などもチェックして、バックアップ間隔を短くする提案をしてくれるなど、細かい対応ができていると感じました。
| 区分 | 提案内容と対応 |
|---|---|
| Non Critical Application | ・バケットのバージョニングをONにする。 ・AWS backupでバックアップ設定(日次)。 |
| Important Application | ・AWS backupでバックアップ設定変更(日次→1時間毎)。 |
| Critical Application | ※Important Application での設定で条件を持たしている。 |
| Mission Critical Application | ・AWS backup のバックアッププランでポイントインタイムリカバリオプションを有効化。 |
| Global Critical Application | ・クロスリージョンレプリケーション (CRR) 設定を実施。 ・Amazon S3 レプリケーション時間制御 (S3 RTC) の有効化。 |
| Global Mission Critical Application | ※Global Critical Application での設定で条件を持たしている。 |
| Foundational Core Service | ・S3 は RPO は改善提案なし。 |
AWS Resilience Hub を利用するに当たっての注意点
AWS Resilience Hub の対象サービスに関する注意点
AWS Resilience Hub で評価できるサービスは限られているので、全ての問題を解決してくれるわけではないことは認識しておく必要があります。対象のサービスは「AWS サービスの耐障害性チェック」に掲載されています。そして、それぞれのサービスの中でチェックできる項目も決まっています。例えば S3 で評価できる内容は以下となります。
| 区分 | 内容 |
|---|---|
| バージョニング | S3 バケットでバージョニングが有効になっているかどうかを確認します。 |
| スケジュールされたバックアップ | デプロイされた S3 バケットに対して AWS Backup プランが定義されているかどうかを確認します。 |
| ポイントインタイムリカバリ | 障害耐性ポリシーの RPO ターゲットでpoint-in-timeリカバリ (PITR) が必要かどうかを確認します。 |
| データレプリケーション | デプロイされた S3 バケットに同じリージョンレプリケーション (SRR) とクロスリージョンレプリケーション (CRR) が定義されているかどうかを確認します。 |
AWS Resilience Hub の対象サービス一覧に掲載されていないサービスは当然チェックができません。
1つ例を挙げるとインタフェース型 VPC エンドポイントが該当します。このサービスは VPC 内のリソースと AWSサービスをプライベートな通信で接続するために利用します。特徴として各 AZ 単位でサブネットを指定してエンドポイントを作成することにより、そのエンドポイント経由で通信が可能です。
以下は SystemsManager とインタフェース型 VPC エンドポイント経由で接続した場合の構成図です。2つの AZ が異なるサブネットにエンドポイントを作成しています。
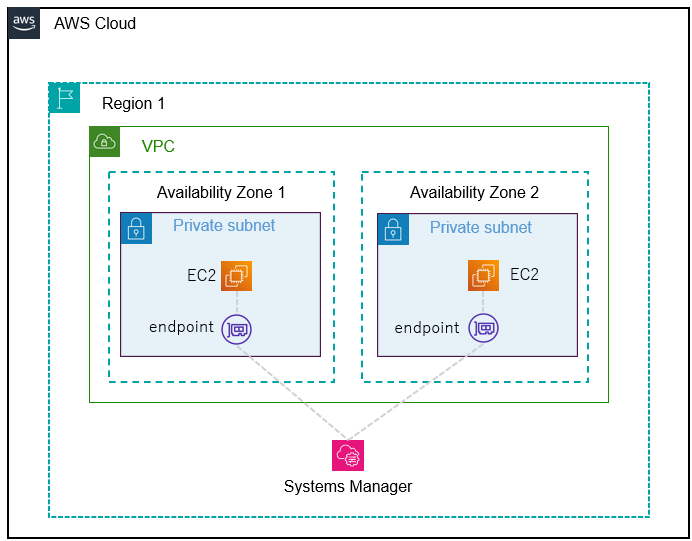
では、以下のように1つのエンドポイントで設定した場合はどうなるか。当然ながらエンドポイントが存在する アベイラビリティゾーン で障害発生すると通信ができなくなります。これは、AWS Resilience Hub ではチェックができません。

このように、AWS Resilience Hub にサービスが対応しているは、意識する必要があります。
リージョンレベルの評価のリソース設定の注意点
AWS Resilience Hub 自体がリージョンに依存するサービスのため、そのチェック対象は基本的にはリージョンに依存します。ただし、リージョンレベルでの評価の場合、2つのリージョンで冗長化できていることがチェック条件になる場合があります。例えば、以下のような例です。
| 区分 | 内容 |
|---|---|
| NatGateway | リージョンの中断が発生した場合に回復できるように、AWS NAT ゲートウェイを別のリージョンにデプロイします。 |
| ELB | 複数のアベイラビリティーゾーンにまたがってデプロイされ、リージョンの中断が発生した場合に ELB が回復できるように複数のターゲットを持つ別のリージョンに追加の Amazon Elastic Load Balancer (ELB) を作成します。 |
こういう場合は、AWS Resilience Hub の対象アプリケーションに対して手動でリソース追加して対応します。以下のようにユーザ定義として登録して、グループ化した上で、評価を実施します。

リージョンレベルでの評価の場合は、このようにひと手間必要になる評価項目があります。
まとめ
AWS Resilience Hub を利用すれば、指定した RTO と RPO のポリシーに従って、現状AWS環境の評価と、その条件を満たす為の提案を簡単に受けることが可能となっています。AWS Well-Architected Framework を元に検討しなければならない項目が自動的に評価できるのがメリットだと感じます。AWS 環境構築の際の助けになると思うので、興味のある方は是非ご活用ください。
最後までお読みいただき、ありがとうございました。