みなさんも自然言語処理をやっていてTf-idfというパッケージを使ったことがあることでしょう。
Tf-idfはdoc2vec同様、自然言語を取り扱っていく上で重要なファクターの一つとなります。
今回はそのTf-idfの挙動に焦点を当て、ベクトル化した言語をどう学習していくかは次の機会にでも書いていきたいと思います。
なんでTf-idfを使うの?
自然言語を機械に学習させたいとき、人々はその慣れ親しんだ言語を自由自在に理解し取り扱うことができますが、機械は真面目なためその自然言語のままでは取り扱えません。
そこで、我々は言語を数値化して機械に読み込ませます。
かといって数値の基準は様々です。単純に頻度を数値にしてテキストマイニングしたり、または意味合いを数値化してメンヘラ度を測るなんてこともできます。
自然言語を取り扱う時、企業のマーケティングに使いたいなんて場合が多いかと思います。
そんな時、文章中に出てくる単語がどれくらい重要なのかを調べたいと考えるでしょう。
今回取り扱うTf-idfというパッケージでは、その文書内での重要度と一般的な希少度をベクトルとして数値化してくれます。
Tf-idfとは?
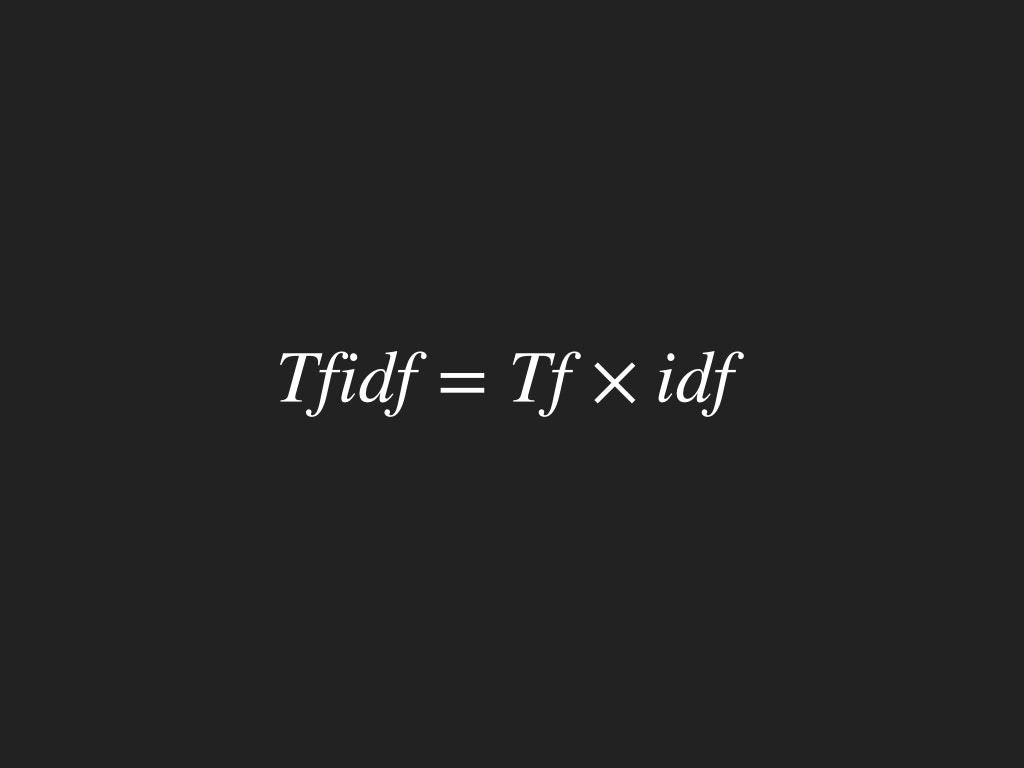
Tf-idfとは
- 文書内での単語の重要度tf(term frequency)
- 一般的な単語の希少度idf(inverse document frequency)
をかけ合わせたものです。
これを用いることで、複数の文章を比較し
- 任意の単語の傾向
- 任意の文章の傾向
を同時に探ることができます。とっても便利です。
それぞれの公式は
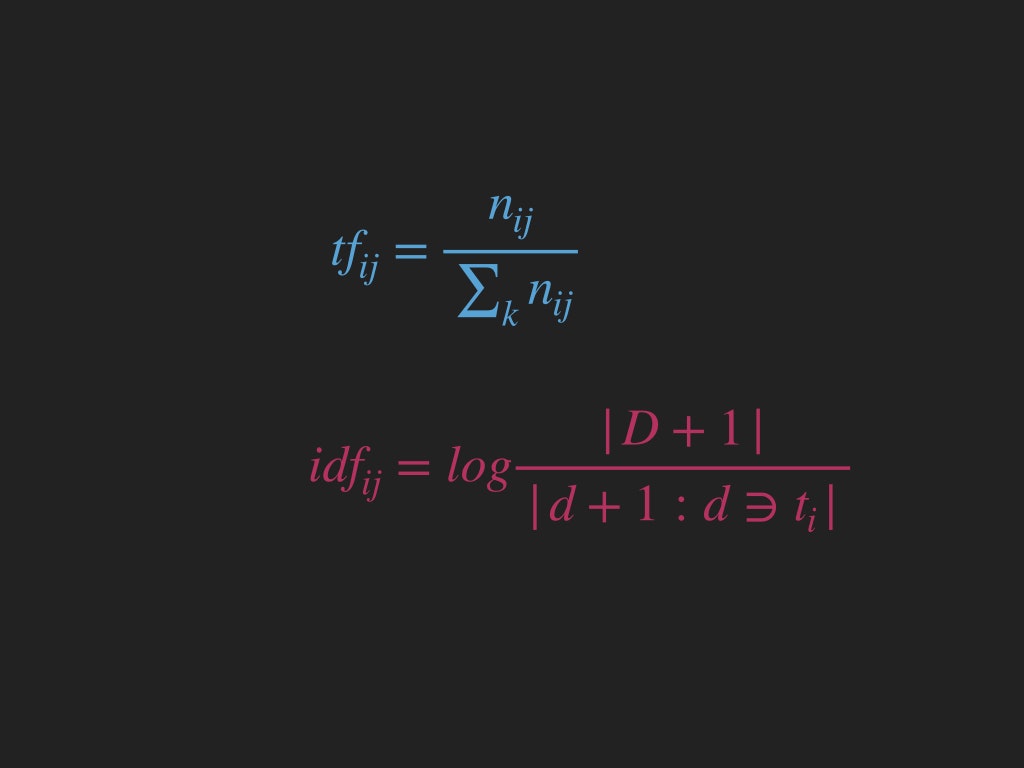
によって得ることができます。内容は説明したとおりです。それぞれの変数の意味がわからない人はウィキペディアをご参照ください。
このtfとidfを掛け合わせることによってどれだけ頻出かだけでなく、どれだけ希少かも同時に調べることができます。
頻出かどうかだけ調べた場合、「is」などのそれほど重要でない単語が一番重要だと判断されやすくなってしまいます。
idfには主にこういった単語の重要度を下げる働きがあり、そうすることで正しく重要単語を取り出すことができます。
Tf-idfを使って自然言語をベクトル化
さて、Tf-idfの仕組みもわかったところで、さっそく自然言語をベクトル化してみましょう。
実は、この記事を書いたきっかけは、Tf-idfには癖があるからなのです。
詳しくはインタプリタに聞いてみることにします。
Tf-idfで自然言語をベクトル化したい時、TfidfVectorizer()を用いて以下のようにします。
from sklearn.feature_extraction.text import TfidfVectorizer
# ベクトル化したい文書
corpus = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?"
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
たったこれだけでcorpusという文章の集合をベクトル化することに成功します。
ベクトル化したい文書が日本語である場合、先にMeCabなりjanomeなりを使って形態素解析して分かち書きに直してください。
さて、このXですが、実はこんな形をしています。

これだけを見てみると混乱するのも無理ありません。私もめちゃくちゃ混乱しました。どこかベクトルなのか、それぞれの値が指す意味がぜんぜんわかりません。
実は、このXはscipy.sparse.csr.csr_matrix型というSciPy特有の型なのです。
せっかくなのでまずはこのcsr_matrixについてもう少し見ていきましょう。
ndarray型と同じようにX.shapeで取り出すことができますが、Xの要素数は(4, 9)です。
本当に意味がわかりません。
実は、この意味不明なscr_matrixとかいう型は、4×9行列への参照を表しているのです。
さて、型の正体を確かめたい時に調べるものはなんでしょう。
そう。メタデータです。
csr_matrix型には3つのメタデータがあります。それは
- indices…tf-idf値(ベクトル)
- data…idf値(スカラ)
- indptr...単語の合計(累積度数)
です。もちろんcsr_matrix型はtf-idfのベクトルのみを扱っているわけではありませんが今回の例でいうと上の注意書きで書いたようになります。
ではさっそくそれぞれのメタデータを取り出して見ましょう。
さっきのコードの続きです。
print(X.indices)
print(X.data)
print(X.indptr)
すると、
# indices
[8 3 6 2 1 8 3 6 1 5 8 3 6 0 7 4 8 3 6 2 1]
# data
[0.38408524 0.38408524 0.38408524 0.58028582 0.46979139 0.28108867
0.28108867 0.28108867 0.6876236 0.53864762 0.26710379 0.26710379
0.26710379 0.51184851 0.51184851 0.51184851 0.38408524 0.38408524
0.38408524 0.58028582 0.46979139]
# indptr
[ 0 5 10 16 21]
となります。
さて、これを見てindicesとdataはすぐ何を指しているのかわかるでしょう。

そう、これです。
では、この0とはなんでしょう。先程の画像をもう一度見てみてください。
0
0
0
0
0
1
1
.
.
.
3
3
3
と並んでいます。そう、この番号は文章のインデックスを指しています。
でもまだわからないことがあります。
indicesの値の意味です。
indicesを理解するには、さっきさらっと言ったXの要素数が(4, 9)であることの意味を理解せねばなりません。
4は言うまでもなく文章の数を指していますが、さて9とはなんでしょう。
これも、先程言った
これを用いることで、複数の文章を比較することで
- 任意の単語の傾向
- 任意の文章の傾向
を同時に探ることができます。
これを思い出してください。
この2つの要素を同時に探るために、行要素が文章であるとするならば列要素は単語であると推測がつくでしょう。
TfidfVectorizer()には単語を取りだすget_feature_names()というメソッドがあります。
print(vectorizer.get_feature_names())
すると
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
と、corpusにある全ての単語がアルファベット順で格納されていることがわかります。
そして、indicesはこの単語のインデックスを参照しています。
つまり、Tf-idfのscr_matrix型は

となっています。これは、まさに参照って感じがしますね。
さて、csr_matrix型の要素の正体がわかった上で、まだ注意したいことがあります。
こちらの縦要素は、実は単純に単語を指していません。なぜならインデックス1の単語数は6であるのに対して、こちらは5しかないからです。
実はこれ、単に一つ一つの単語のcsr_matrix値を指しているのではなく、その文章の中で重複している単語が見つかった場合スキップしています。
つまり、インデックス1の文章This document is the second document.にはdocumentという単語が2回出てきているので2回目を飛ばしているのです。(賢い)
最後に、indptrは文章ごとの単語の種類の累計を指しています。まず0が入り、インデックス0の単語数5が足され、インデックス1の単語数5が足され...
という風になされていきます。このようにデータの総数がわかることでメモリがわかりますね。これはメタデータ上とても大事なことですので実用性はないかもしれませんが気に留めておきましょう。
はい。これでとうとうTf-idfを扱うcsr_matrix型の正体がわかりましたね。
ですが、このcsr_matrix型は要はndarray型のメタデータであり、人間が取り扱うには多少、いや大分難易度が高いですよね。
人類のみなさん。安心してください。ここでndarray型の出番です。
実はcsr_matrix型にはその強力な参照性を生かしてndarray型へと変換するtoarray()関数が備わっています。
print(X.toarray())
とすることでまんまとndarray型の配列が取り出せます。
[[0. 0.46979139 0.58028582 0.38408524 0. 0.
0.38408524 0. 0.38408524]
[0. 0.6876236 0. 0.28108867 0. 0.53864762
0.28108867 0. 0.28108867]
[0.51184851 0. 0. 0.26710379 0.51184851 0.
0.26710379 0.51184851 0.26710379]
[0. 0.46979139 0.58028582 0.38408524 0. 0.
0.38408524 0. 0.38408524]]
そして、このndarray型の配列こそが4×9の行列なのです。実はcsr_matrix型のshapeが参照していたのはこのndarray型なのです。
shapeはもともとndarray型のメタデータですからね。
薄々気づいたかもしれませんが、各単語のベクトルを並べたものこそがこの行列の正体です。

この表記がパっとこない方は線形代数を勉強しましょう。
この行列は機械学習を嗜んでいるみなさんにも馴染み深いと思うのでここまでくればみなさんにもこの行列の意味することがわかるでしょう。

そう、言ったとおり、行成分で文章の、列成分で単語のベクトルを測ることができます。
いろいろできそうなことが見えてきましたね?それではあとはみなさんの力でがんばってください。