はじめに
こんにちは,(株)日立製作所 研究開発グループ サービスコンピューティング研究部の露木です。
機械学習モデルの開発・運用にはモデルのアルゴリズム,ハイパーパラメータや精度指標を記録し,後から再現できるように整理する「実験管理」が重要です。実験管理は従来,データサイエンティスト個々人のやり方でExcelやDB等を使って実施されてきましたが,近年はDatabricsやMicrosoftが開発に参加するオープンソースの実験管理ソフトMLflowが2018年に公開され,実用的になってきています。本記事ではサポートベクトル回帰の実験管理を例として,MLlfowの使い方をソースコードと共に示します。
特に開発者個人ではなく,開発チームや運用チームで実験結果を共有できるように,リモートにあるMLflow Trackingサーバを利用して実験結果の記録と参照をする方法を示します。
機械学習の実験管理
MLflowはDatabricsによるオープンソースの実験管理ソフトでです。特別な実行環境 (Kubernetesなど) や機械学習ライブラリに依存せずに手元のPC一つで簡単に利用できることが特徴です。2019年5月には,MLflowの開発コミュニティにMicrosoftが参加したこともあり,開発が加速しています。
MLflowは大きく分けて3つの構成要素からなります。
1つ目は,実験の情報を記録し,Webブラウザから参照するためのTrackingサーバです。Trackingサーバはお手元のPCで立ち上げるほか,MicrosoftのAzureでSaaSとして提供されているので,そちらも利用可能です。
2つ目は,MLfowのCLIコマンドです。CLIコマンドは前述のTrackingサーバを立ち上げたり,Trackingサーバに管理されている実験情報を取得するために利用します。また「MLflow Project」のフォーマットで作成した学習スクリプトがあれば,CLIコマンドで学習を実行して結果をTrackingサーバへ送信することもできます。
3つ目は,各種言語向けのライブラリです。MLflowをライブラリとして読み込めば,PythonやR,Javaのプログラムで,学習結果の送信や取得を容易に実装できます。
今回はSVR (サポートベクトル回帰) を例にとって,Python3向けのMLflowライブラリで実験管理する例を示します。
目指す構成
MLflow Trackingサーバを立ち上げるために docker-compose で環境を準備していきます。本記事で目指す構成は以下の図のとおりです。
具体的にはTrackingサーバとMinIO,MySQLの3つをdocker-composeで立ち上げ,Pythonスクリプトから学習結果を送信したり,ブラウザで学習結果を確認可能にします。
なお,単に個人でMLflowを使うするだけなら,MinIOやMySQLは必ずしも必要なコンポーネントではありません。
MinIOの役割は,CSVファイルやシリアライズした学習済みモデルなどのファイル(mlflow用語ではartifact) をリモートに保存することです。
また,MySQLは実行履歴やその他のメトリクスなどを保存します。
これらMinIOやMySQLはチームで一つのMLflow Trackingサーバを共同利用するために必要となります。
Webブラウザ Pythonスクリプト --+
↕ ↓ ↓
.....................................................................
. +---------------------+ +--------------------------------+ .
. |MLflow Trackingサーバ| ↔ | オブジェクトストレージ( MinIO) | .
. +---------------------+ +--------------------------------+ .
. ↕ .
. +-------+ .
. | MySQL | .
. +-------+ .
.......................docker-compose................................
環境を準備する
最初にMLflow Trackingサーバの Dockerfile を作成します。
FROM continuumio/miniconda
MAINTAINER Tsuyuki
ARG DEBIAN_FRONTEND="noninteractive"
RUN apt update && apt upgrade -y \
&& apt install -y python3-pip python3 python-dev \
&& apt install -y default-libmysqlclient-dev \
# clean up image
&& apt clean \
&& rm -rf /var/cache/apt/archives/* /var/lib/apt/lists/*
RUN pip3 install mlflow mysqlclient sqlalchemy boto3
RUN mkdir -p /mlflow
WORKDIR /mlflow
デフォルトの設定ではMLflow TrackingサーバからMySQLへの接続がタイムアウトすることがあります。
これを回避するために,MySQLの設定ファイル timeout.cnf を以下の内容で作成します。
[mysqld]
wait_timeout = 31536000
interactive_timeout = 31536000
docker-compose.yamlを以下の内容で作成します。
なお,ここではAWS S3互換のオブジェクトストレージ MinIOを使用するため,
環境変数名にAWSやS3の文字が含まれますがAWSへデータ送信されることはありません。
version: "3"
services:
# mlflow trackingサーバ
mlflow:
image: mlflow
build:
context: .
dockerfile: Dockerfile
ports:
- 5000:5000
restart: always
depends_on:
- mysql
- minio
environment:
MLFLOW_S3_ENDPOINT_URL: http://minio:9000
AWS_ACCESS_KEY_ID: minio-access-key
AWS_SECRET_ACCESS_KEY: minio-secret-key
command: mlflow server --backend-store-uri 'mysql://mlflowuser:mlflowpassword@mysql:3306/mlflowdb' --default-artifact-root 's3://default/' --host 0.0.0.0 --port 5000
volumes:
- mlflow:/var/mlflow
networks:
- nginx_network
# artifact以外の情報記録用
mysql:
image: mysql:5.7
restart: always
environment:
MYSQL_ROOT_PASSWORD: root-password
MYSQL_DATABASE: mlflowdb
MYSQL_USER: mlflowuser
MYSQL_PASSWORD: mlflowpassword
volumes:
- mysql:/var/lib/mysql
- ./timeout.cnf:/etc/mysql/conf.d/timeout.cnf
networks:
- nginx_network
# artifact保存用のストレージ
minio:
image: minio/minio
ports:
- 9000:9000
restart: always
volumes:
- minio1:/export
environment:
MINIO_ACCESS_KEY: minio-access-key
MINIO_SECRET_KEY: minio-secret-key
command: server /export
networks:
- nginx_network
# minioコンテナ起動時にデフォルトのバケットを自動作成する
defaultbucket:
image: minio/mc
depends_on:
- minio
entrypoint: >
/bin/sh -c "
until (/usr/bin/mc config host add myminio http://minio:9000 minio-access-key minio-secret-key) do echo 'try to create buckets...' && sleep 1; done;
/usr/bin/mc mb myminio/default;
/usr/bin/mc policy download myminio/default;
exit 0;
"
networks:
- nginx_network
networks:
nginx_network:
driver: bridge
volumes:
mlflow:
minio1:
mysql:
最後にMLflowのTrackingサーバを起動します。
docker-compose up -d
実験管理をする
それでは立ち上げたTrackingサーバを利用して,機械学習の実験管理を行う方法を説明します。実験管理の題材としては昨日の記事で紹介したSVRのハイパーパラメータ選択を用い,ハイパーパラメータと学習結果の関係を比較します。
最初に,必要なライブラリをインストールします。未インストールの場合は次のコマンドを実行してください。
pip3 install numpy scikit-learn matplotlib mlflow
※ この節より先のコードはすべてPythonです。JupyterノートブックやPythonスクリプトとして実行してください。
Pythonのライブラリをインポートします。
# ライブラリを読み込む
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVR
from sklearn.model_selection import train_test_split
import mlflow
import mlflow.sklearn
import os
import tempfile
次に,MLflowのTrackingサーバとオブジェクトストレージの接続情報を設定します。
# mlflow trackingサーバのURLを指定
mlflow.set_tracking_uri("http://{先程立ち上げたTrackingサーバのIPアドレス}}:5000")
# 環境変数としてオブジェクトストレージへの接続情報を指定
os.environ["MLFLOW_S3_ENDPOINT_URL"] = "http://{先程立ち上げたTrackingサーバのIPアドレス}:9000"
os.environ["AWS_ACCESS_KEY_ID"] = "minio-access-key"
os.environ["AWS_SECRET_ACCESS_KEY"] = "minio-secret-key"
MLflowは一つ一つの学習の実行結果を run と呼びます。runのグループとして experiment という単位があり,experiment に結果を蓄積していきます。今回は,例として "tutorial" という experiment 名を指定します。なお,存在しないexperiment名を指定した場合は自動的に作成されます。
mlflow.set_experiment("tutorial")
MLflowのartifactとして送信するため,データセットを一時的に保存するディレクトリをローカルマシンに作成します。
temp_dir = tempfile.TemporaryDirectory()
データ準備
学習データとして,sinc関数に右肩上がりな成分とノイズを加えたデータを生成します。
# サンプルデータ数
m = 200
# 乱数のシード値を指定することで,再現性を保つ
np.random.seed(seed=2018)
# 「-3」から「3」の間で等間隔にm個のデータを作成
X = np.linspace(-3, 3, m)
# 後のグラフ描画用途に,10倍細かいグリッドを準備しておく
X_plot = np.linspace(-3, 3, m*10)
# 周期的なsin関数(第一項)に右上がり成分(第二項)と乱数(第三項)を加えたデータを作る
y = np.sinc(X) + 0.2 * X + 0.3 * np.random.randn(m)
# グラフ表示するため,各数列を1列の行列に変換
X = X.reshape(-1, 1)
y = y.reshape(-1, 1)
X_plot = X_plot.reshape(-1,1)
# グラフを表示
plt.title("sample data")
plt.xlabel("$x$")
plt.ylabel("$y$")
plt.scatter(X, y, color="black")
plt.show()
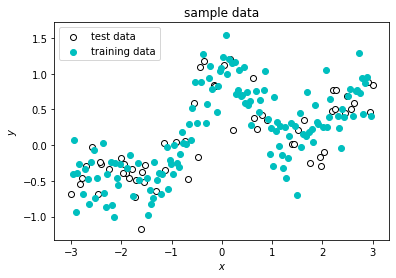
生成したサンプルデータの70%はモデルの学習に使う「学習データ」とし,30%はモデルの精度評価に使う「テストデータ」とします。未知データに対するモデルの精度(汎化性能)を正しく評価するには,学習データに含まれないデータ(テストデータ)が必要です。
# 学習データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=2019)
# 学習データとテストデータのグラフを表示
plt.scatter(X_test, y_test, label="test data", edgecolor='k',facecolor='w')
plt.scatter(X_train, y_train, label="training data", color='c')
plt.title("sample data")
plt.xlabel("$x$")
plt.ylabel("$y$")
plt.legend()
plt.show()
# 作成したグラフをファイルに保存
filename = os.path.join(temp_dir.name, "train_and_test_data.png")
plt.savefig(filename)
作成した学習データとテストデータを記録に残すため,CSVファイルとして保存します。
# 分割前のデータセット
np.savetxt(os.path.join(temp_dir.name, "dataset_X.csv"), X, delimiter=',')
np.savetxt(os.path.join(temp_dir.name, "dataset_y.csv"), y, delimiter=',')
# 学習データとテストデータに分割後のデータセット
np.savetxt(os.path.join(temp_dir.name, "X_train.csv"), X_train, delimiter=',')
np.savetxt(os.path.join(temp_dir.name, "y_train.csv"), y_train, delimiter=',')
np.savetxt(os.path.join(temp_dir.name, "X_test.csv"), X_test, delimiter=',')
np.savetxt(os.path.join(temp_dir.name, "y_test.csv"), y_test, delimiter=',')
SVRモデルの学習
今回は,SVRのハイパーパラメータの一種,正則化係数$C$を変えながら精度を確認します。最初に,予測値をグラフ表示するための関数を準備しておきます。
# 予測結果のグラフを描画する関数を定義
def plot_result(model, X_train, y_train, score, filename=None):
# 予測値の計算
p = model.predict(np.sort(X_test))
# グラフの描画
plt.clf()
plt.scatter(X_test, y_test, label="test data", edgecolor='k',facecolor='w')
plt.scatter(X_train, y_train, label="Other training data", facecolor="r", marker='x')
plt.scatter(X_train[model.support_], y_train[model.support_], label="Support vectors", color='c')
plt.title("predicted results")
plt.xlabel("$x$")
plt.ylabel("$y$")
x = np.reshape(np.arange(-3,3,0.01), (-1, 1))
plt.plot(x, model.predict(x), label="model ($R^2=%1.3f$)" % (score), color='b')
plt.legend()
plt.show()
# グラフの保存
if filename is not None:
plt.savefig(filename)
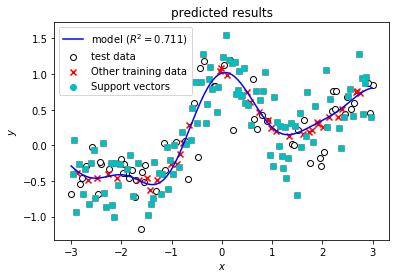
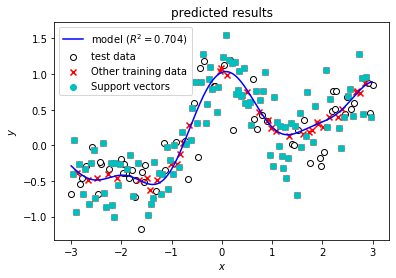
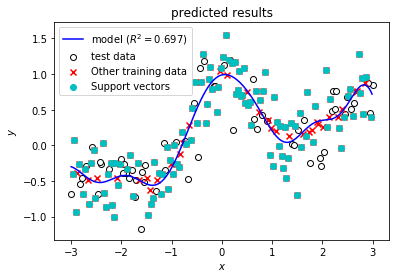
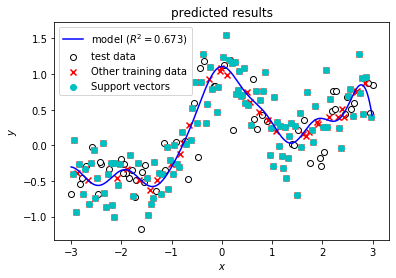
C = 0 から C = 1000 まで変えながらモデルを学習し,結果をMLflowに送信します。MLflowに送信する結果は,学習データ,パラメータ,精度指標,モデルに加えて下記コードの出力にあるような予測結果を示したグラフを含みます。
for C in (0.01, 1, 5, 10, 100, 1000):
# ここからの処理を一つのrunとしてmlflowに記録する
with mlflow.start_run(run_name="Search C"):
# モデルの学習を実行
model = SVR(kernel='rbf', C=C, epsilon=0.1, gamma='auto').fit(X_train, np.ravel(y_train))
# 保存しておいたデータセットをMLflowへ送信する
mlflow.log_artifacts(temp_dir.name, artifact_path="dataset")
# タグを指定
mlflow.set_tag("algorism", "SVR")
# ハイパーパラメータを記録する
mlflow.log_param("C", C)
# 精度指標を計算し,MLflowに送信する
score = model.score(X_test, y_test)
mlflow.log_metric("R2 score", score)
# モデルを記録したファイルをMLflowに送信する
mlflow.sklearn.log_model(model, "model", serialization_format='cloudpickle')
# 一時ディレクトリに予測結果のグラフを保存して,mlflowに送信する
with tempfile.TemporaryDirectory() as tmp:
filename = os.path.join(tmp, "predict_results.png")
plot_result(model, X_train, y_train, model.score(X_test, y_test), filename)
mlflow.log_artifact(filename, artifact_path="results")
MLflowに保存した結果の確認
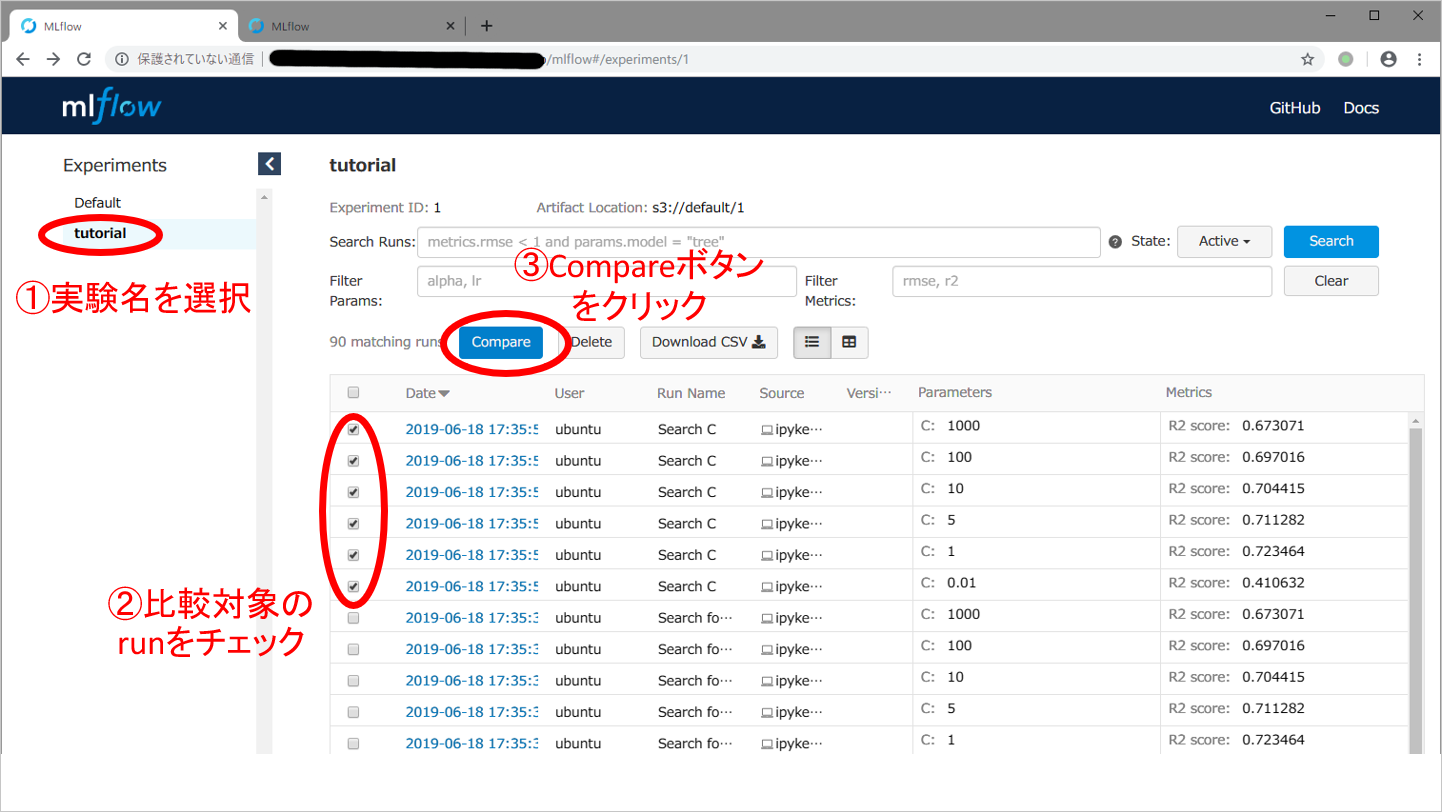
まず,精度指標である$R^2$スコアが最大になる,ハイパーパラメータCを探してみます。MLflow TrackingサーバのURL http://{先程立ち上げたTrackingサーバのIPアドレス}:5000 を開いてから,下記スクリーンショットのように ①指定したexperiment名を左側のExperimentsの一覧から選択し,②比較対象のrunにチェックといれ,③Compareボタンを押してください。比較対象のrunとしては,Date欄がほぼ同一の時刻で,Parameters欄のCが0.01~1000まで変化している一連のrunを選びます。
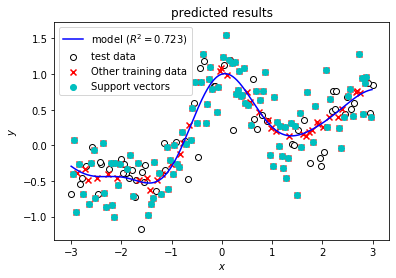
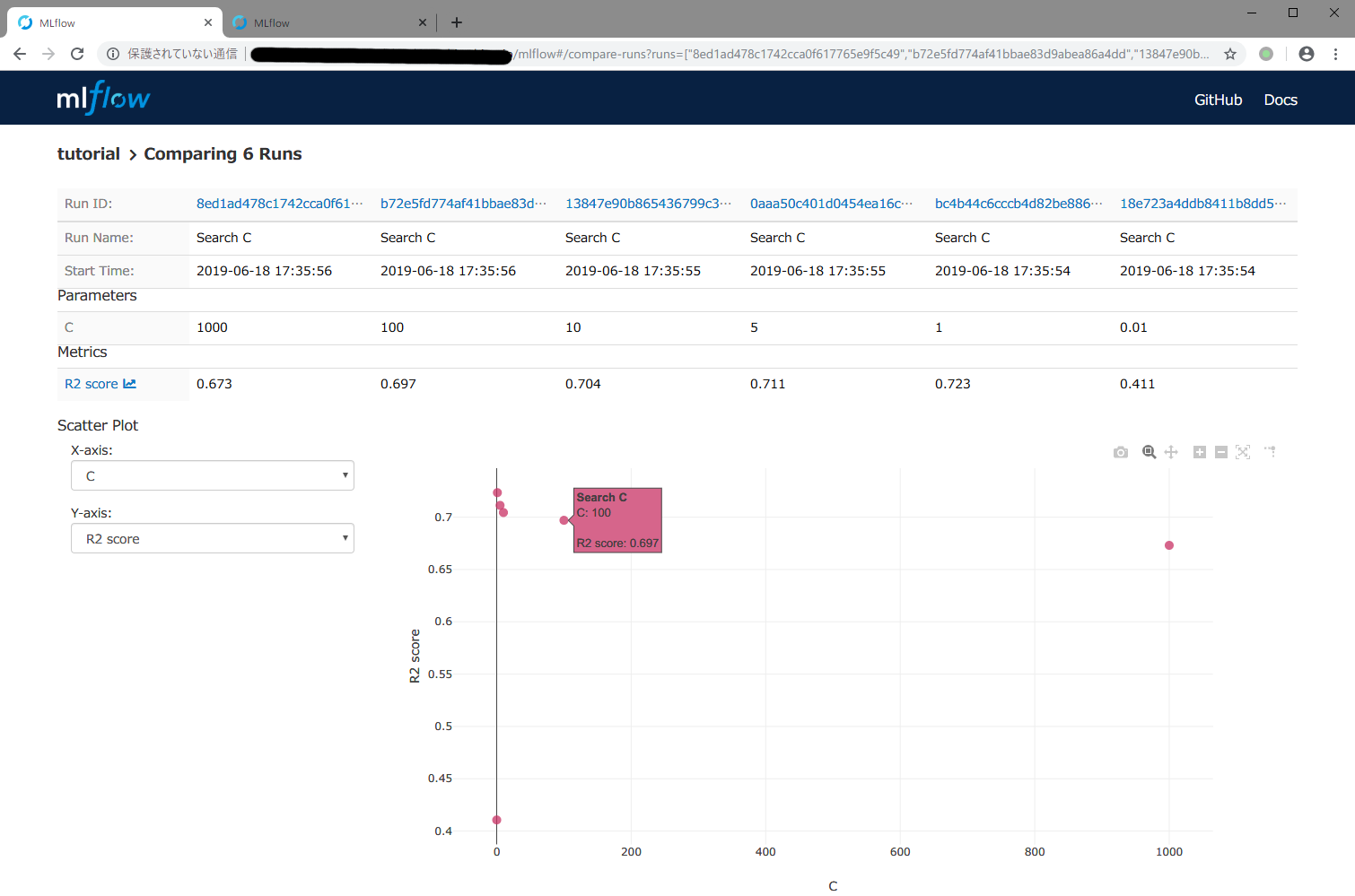
Compareボタンを押すと,下記スクリーンショットのように横軸がCで,縦軸が$R^2$スコアのグラフが表示されます。ここで,グラフ上のプロット点にマウスカーソルを合わせると,スクリーンショットのように縦軸と横軸の値が表示されます。$R^2$スコアは,1に近いほど良くデータを近似できていることを示します。グラフを見ると,C = 1 のときに$R^2$スコアが最大となり,もっとも精度が良いモデルができたといえます。
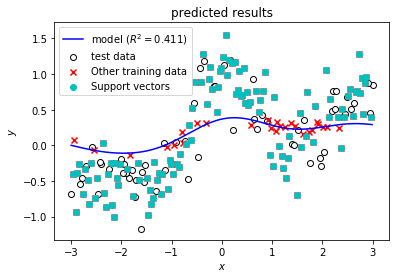
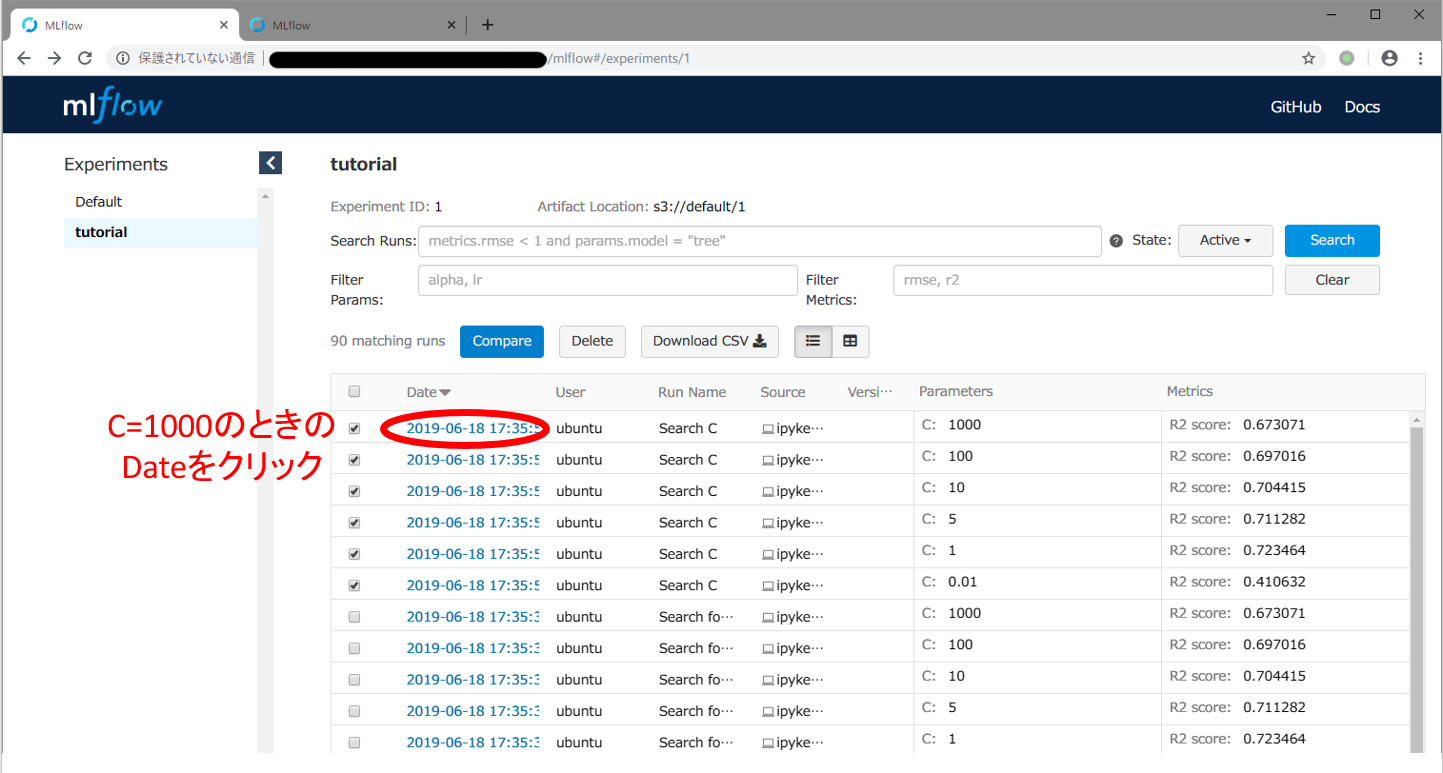
最後に,精度指標だけではどのようなモデルを得られたのか不明であるので,予測値を可視化したグラフを調べてみます。まず,C = 1000 のときにどのような予測結果となっているか確認してみます。下記スクリーンショットのように,ブラウザの「戻る」ボタンで一覧画面に戻ってから,C = 1000のときのDate欄をクリックしてrunの詳細画面へ移動してください。
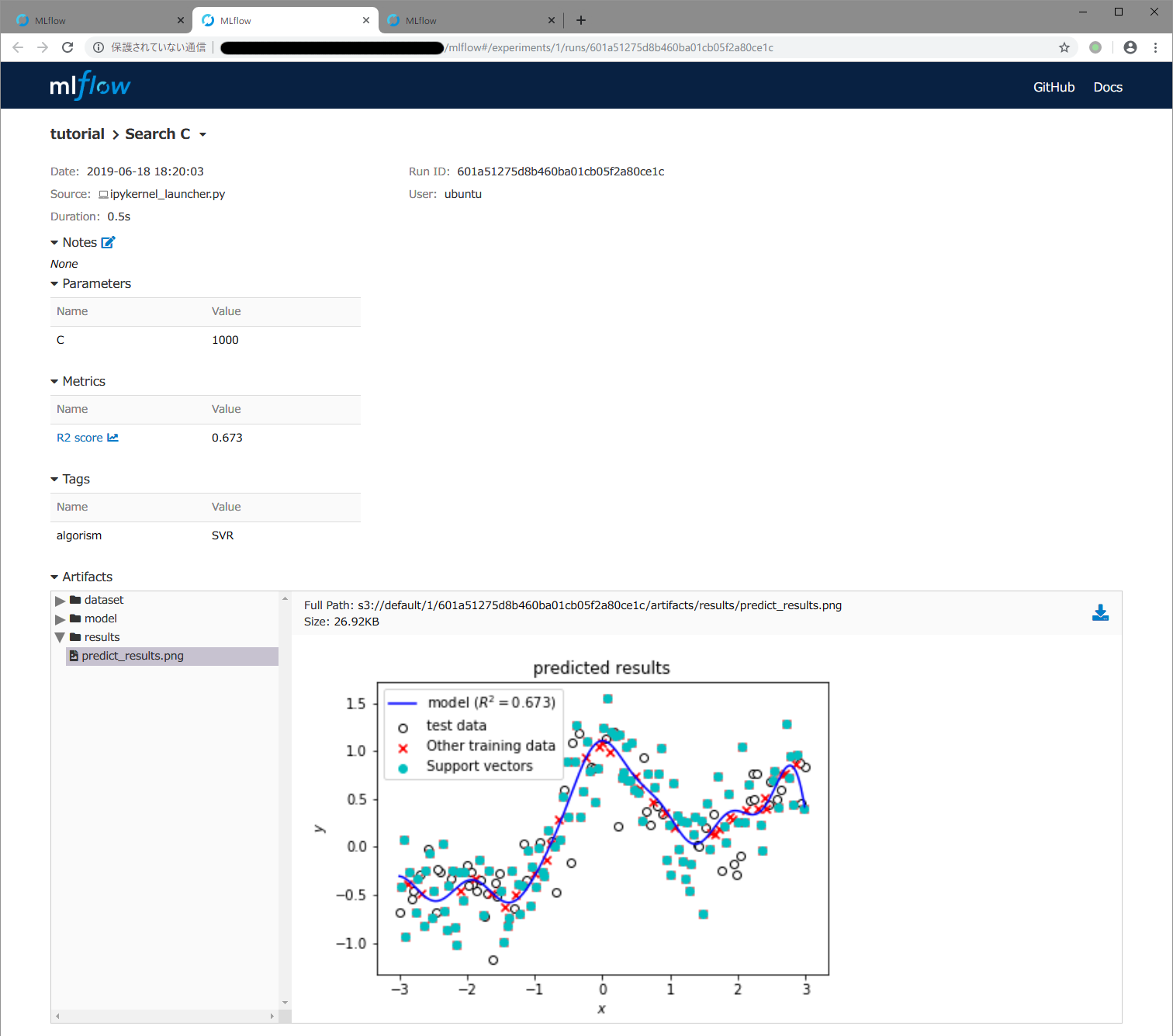
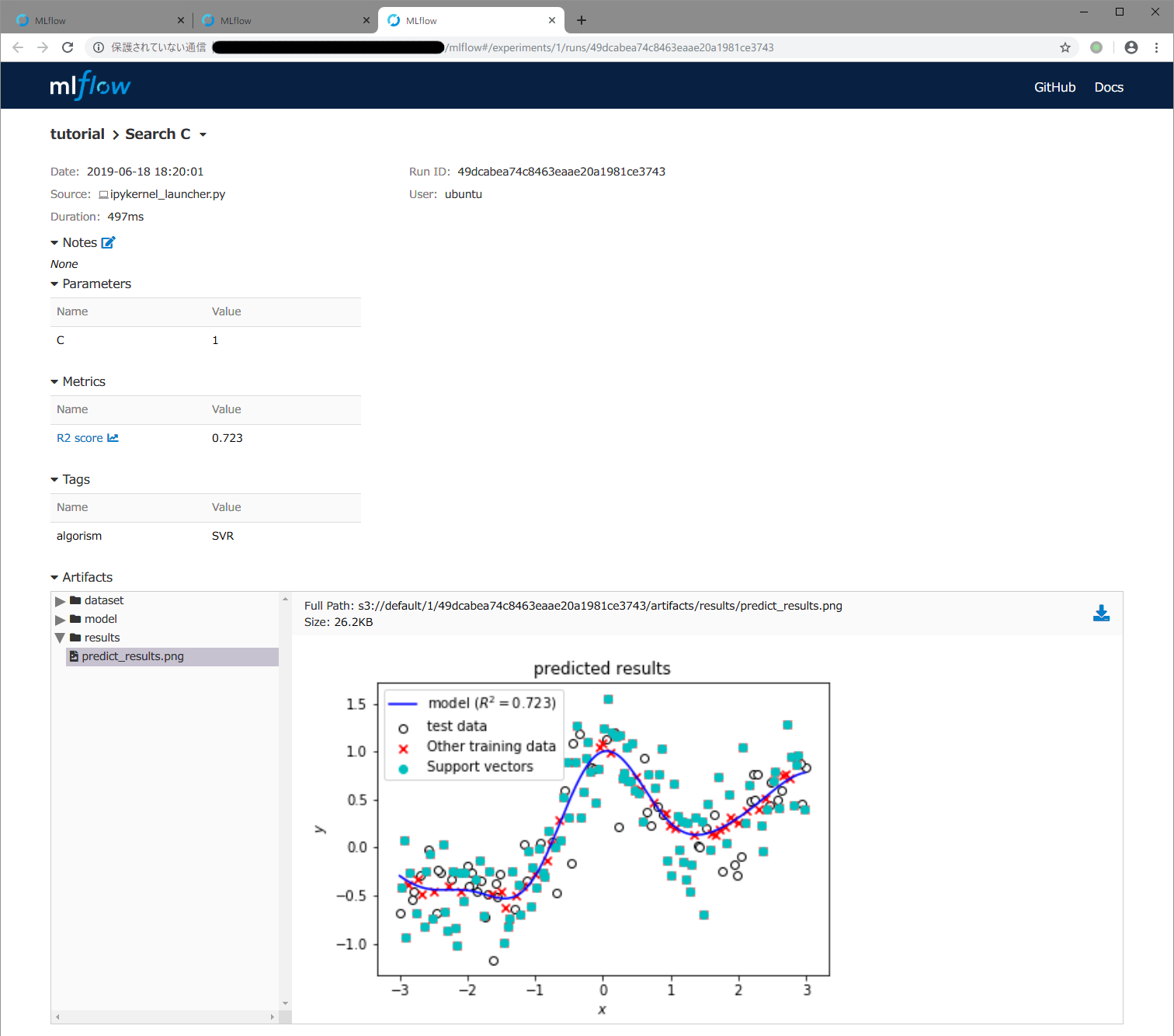
runの詳細画面で,下記スクリーンショットのように画面最下部のArtifatcs欄でresultsをクリックすると出てくるpredict_results.pngのファイル名をクリックするとMLflowに記録しておいたモデルの予測結果を示すグラフが表示されます。Cが1000と大きい場合は,モデルの予測結果を示す青い曲線が滑らかではなく,学習データに対して過剰適合しているためにテストデータに対する精度が低いことがわかります。
一方,最も精度の高かった C = 1 のときの詳細画面で,同様にグラフを表示すると青色の予測曲線は滑らかになっており,過剰適合していない (汎化性能が高い) 良いモデルが得られていることがわかります。
最後に
本記事で説明したように,MLflowを使うとモデルの学習結果を記録して,後から参照する「実験管理」を容易に実現できます。今回紹介した機能の他にも,MLflowには多数の機能があります。公式ドキュメントのチュートリアル などを参照しながら,ぜひ調べてみてください。