言語処理100本ノック 2015の「第4章 形態素解析 (30〜39)」を解いた記録です。
環境
- OS X El Capitan Version 10.11.4
- Python 3.5.1
準備
使用するライブラリ
import MeCab
import ngram
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
形態素解析済み文章のファイル保存
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
なお,問題37, 38, 39はmatplotlibもしくはGnuplotを用いるとよい.
make_analyzed_fileという関数を作って形態素解析を行いファイルに保存する。なお、neko.txtは予めダウンロードして、実行ファイルと同一フォルダに保存しているものとする。
def make_analyzed_file(input_file_name: str, output_file_name: str) -> None:
"""
プレーンな日本語の文章ファイルを形態素解析してファイルに保存する.
:param input_file_name プレーンな日本語の文章ファイル名
:param output_file_name 形態素解析済みの文章ファイル名
"""
_m = MeCab.Tagger("-Ochasen")
with open(input_file_name, encoding='utf-8') as input_file:
with open(output_file_name, mode='w', encoding='utf-8') as output_file:
output_file.write(_m.parse(input_file.read()))
make_analyzed_file('neko.txt', 'neko.txt.mecab')
30. 形態素解析結果の読み込み
形態素解析結果(neko.txt.mecab)を読み込むプログラムを実装せよ.ただし,各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をキーとするマッピング型に格納し,1文を形態素(マッピング型)のリストとして表現せよ.第4章の残りの問題では,ここで作ったプログラムを活用せよ.
単純に形態素解析結果をタブ区切り文字列から辞書型に変換したものをmorphemesに、1文毎にまとめたものをsentencesに保存する。
def tabbed_str_to_dict(tabbed_str: str) -> dict:
"""
例えば「次第に シダイニ 次第に 副詞-一般 」のようなタブ区切りで形態素を表す文字列をDict型に変換する.
:param tabbed_str タブ区切りで形態素を表す文字列
:return Dict型で表された形態素
"""
elements = tabbed_str.split()
if 0 < len(elements) < 4:
return {'surface': elements[0], 'base': '', 'pos': '', 'pos1': ''}
else:
return {'surface': elements[0], 'base': elements[1], 'pos': elements[2], 'pos1': elements[3]}
def morphemes_to_sentence(morphemes: list) -> list:
"""
Dict型で表された形態素のリストを句点毎にグルーピングし、リスト化する.
:param morphemes Dict型で表された形態素のリスト
:return 文章のリスト
"""
sentences = []
sentence = []
for morpheme in morphemes:
sentence.append(morpheme)
if morpheme['pos1'] == '記号-句点':
sentences.append(sentence)
sentence = []
return sentences
with open('neko.txt.mecab', encoding='utf-8') as file_wrapper:
morphemes = [tabbed_str_to_dict(line) for line in file_wrapper]
sentences = morphemes_to_sentence(morphemes)
# 結果の確認
print(morphemes[::100])
print(sentences[::100])
31. 動詞 / 32. 動詞の原形 / 33. サ変名詞
動詞の表層形をすべて抽出せよ.
動詞の原形をすべて抽出せよ.
サ変接続の名詞をすべて抽出せよ.
「30. 形態素解析結果の読み込み」で作ったmorphemesを使えば簡単です。
verbs_surface = [morpheme['surface'] for morpheme in morphemes if morpheme['pos1'].find('動詞') == 0]
verbs_base = [morpheme['base'] for morpheme in morphemes if morpheme['pos1'].find('動詞') == 0]
nouns_suru = [morpheme['surface'] for morpheme in morphemes if morpheme['pos1'] == '名詞-サ変接続']
# 結果の確認
print(verbs_surface[::100])
print(verbs_base[::100])
print(nouns_suru[::100])
34. 「AのB」
2つの名詞が「の」で連結されている名詞句を抽出せよ.
def ngramed_list(lst: list, n: int = 3) -> list:
"""
listをNグラム化する.
:param lst Nグラム化対象のリスト
:param n N (デフォルトは N = 3)
:return Nグラム化済みのリスト
"""
index = ngram.NGram(N=n)
return [term for term in index.ngrams(lst)]
def is_noun_no_noun(words: list) -> bool:
"""
3つの単語から成るリストが「名詞-の-名詞」という構成になっているかを判定する.
:param words 3つの単語から成るリスト
:return bool (True:「名詞-の-名詞」という構成になっている / False:「名詞-の-名詞」という構成になっていない)
"""
return (type(words) == list) and (len(words) == 3) and \
(words[0]['pos1'].find('名詞') == 0) and \
(words[1]['surface'] == 'の') and \
(words[2]['pos1'].find('名詞') == 0)
# 「名詞-の-名詞」を含むNグラムのみを抽出
noun_no_noun = [ngrams for ngrams in ngramed_list(morphemes) if is_noun_no_noun(ngrams)]
# 表層を取り出して結合する
noun_no_noun = [''.join([word['surface'] for word in ngram]) for ngram in noun_no_noun]
# 結果の確認
print(noun_no_noun[::100])
35. 名詞の連接
名詞の連接(連続して出現する名詞)を最長一致で抽出せよ.
def morphemes_to_noun_array(morphemes: list) -> list:
"""
辞書型で表された形態素のリストを句点もしくは名詞以外の形態素で区切ってグルーピングし、リスト化する.
:param morphemes 辞書型で表された形態素のリスト
:return 名詞の連接のリスト
"""
nouns_list = []
nouns = []
for morpheme in morphemes:
if morpheme['pos1'].find('名詞') >= 0:
nouns.append(morpheme)
elif (morpheme['pos1'] == '記号-句点') | (morpheme['pos1'].find('名詞') < 0):
nouns_list.append(nouns)
nouns = []
return [nouns for nouns in nouns_list if len(nouns) > 1]
noun_array = [''.join([noun['surface'] for noun in nouns]) for nouns in morphemes_to_noun_array(morphemes)]
# 結果の確認
print(noun_array[::100])
36. 単語の出現頻度
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
def get_frequency(words: list) -> dict:
"""
単語のリストを受け取って、単語をキーとして、頻度をバリューとする辞書を返す.
:param words 単語のリスト
:return dict 単語をキーとして、頻度をバリューとする辞書
"""
frequency = {}
for word in words:
if frequency.get(word):
frequency[word] += 1
else:
frequency[word] = 1
return frequency
frequency = get_frequency([morpheme['surface'] for morpheme in morphemes])
# ソート
frequency = [(k, v) for k, v in sorted(frequency.items(), key=lambda x: x[1], reverse=True)]
# 結果の確認
print(frequency[0:20])
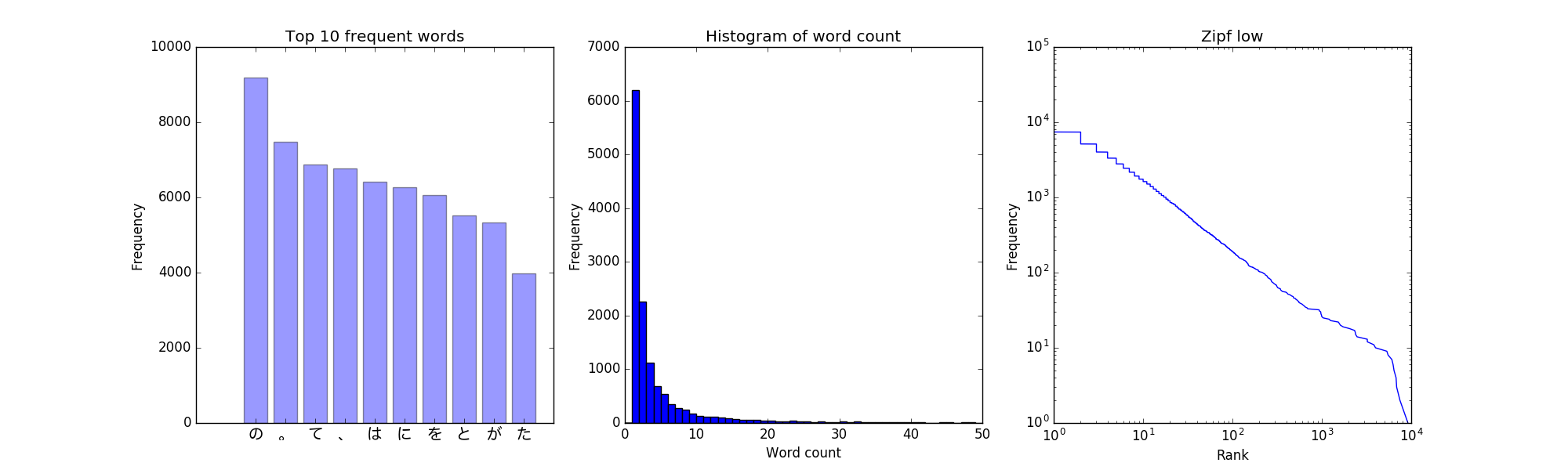
37. 頻度上位10語 / 38. ヒストグラム / 39. Zipfの法則
出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
単語の出現頻度のヒストグラム(横軸に出現頻度,縦軸に出現頻度をとる単語の種類数を棒グラフで表したもの)を描け.
単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
グラフ系はまとめて出してしまいます。
fig = plt.figure(figsize=(20, 6))
# 37. 出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
words = [f[0] for f in frequency[0:10]]
x_pos = np.arange(len(words))
fp = FontProperties(fname=r'/Library/Fonts/ヒラギノ丸ゴ ProN W4.ttc', size=14)
ax1 = fig.add_subplot(131)
ax1.bar(x_pos, [f[1] for f in frequency[0:10]], align='center', alpha=0.4)
ax1.set_xticks(x_pos)
ax1.set_xticklabels(words, fontproperties=fp)
ax1.set_ylabel('Frequency')
ax1.set_title('Top 10 frequent words')
# 38. 単語の出現頻度のヒストグラム(横軸に出現頻度,縦軸に出現頻度をとる単語の種類数を棒グラフで表したもの)を描け.
freq = list(dict(frequency).values())
freq.sort(reverse=True)
ax2 = fig.add_subplot(132)
ax2.hist(freq, bins=50, range=(0, 50))
ax2.set_title('Histogram of word count')
ax2.set_xlabel('Word count')
ax2.set_ylabel('Frequency')
# 39. 単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
rank = list(range(1, len(freq) + 1))
ax3 = fig.add_subplot(133)
ax3.plot(freq, rank)
ax3.set_xlabel('Rank')
ax3.set_ylabel('Frequency')
ax3.set_title('Zipf low')
ax3.set_xscale('log')
ax3.set_yscale('log')
fig.savefig('morphological_analysis.png')