はじめに
私が趣味でノベルゲームをプレイするとき、たまに意味を知らない単語や難読単語、実物を画像で調べたくなる単語(作中で話題に上がった料理など)が登場することがあります。
このようなとき、通常は手動でブラウザを開いて検索ワードを入力するのですが、本記事では、ゆずソフト作のノベルゲーム『千恋*万花』(Steam全年齢版リンク)を例に、この作業をある程度自動化してみます。1

具体的には、Pythonで以下を順に試してみます。
- OCR(光学文字認識)の導入
- メッセージウィンドウの切り抜き・OCRによるテキスト抽出
- 画像処理によるOCRの認識性能向上
- 簡単なGUIアプリの作成
OCRの環境構築
OCR(Optical Character Recognition / 光学文字認識)とは、活字や手書きの文章を画像として読み込み、これを文字コードの列に変換する技術を指します。
様々なOS上でOCRを実施するためのエンジンの一つとして Tesseract が挙げられ、これをPython用のOCRツール PyOCR と組み合わせることにより、PythonのプログラムでOCRの処理を実現できます。
Tesseractの導入
Tesseractの導入手順(Windows)を簡単に示すと、次の通りです。
- Tesseract公式ページ より、Tesseractのインストーラをダウンロードして実行する。
- License Agreementへの同意とユーザ選択を行う。
- Choose Componentにおいて、下記にチェックを入れる(誤ってJavanese「ジャワ語」を選ばないように注意)。
- Additional script data (download)の「Japanese script」と「Japanese vertical script」
- Additional language dataの「Japanese」と「Japanese(vertical)」
- インストール先を選択してインストールする。
詳しい導入手順を知りたい場合は、下記のリンク等を参照してください。
PyOCRの導入
PyOCRについては、NumPy等の一般的なPython用ライブラリと同様の方法で導入できます。例えば、
pip install pyocr
で導入できます。
OCRの動作確認
Tesseract・PyOCRの導入が完了したら、早速動作確認を行ってみましょう。
事前に画像処理ライブラリ Pillow のインストールが必要です。
pip install Pillow
サンプルとして次の画像(出典:太宰治『走れメロス』)を使用します。

from PIL import Image
import pyocr
# OCRエンジンのリストを取得してTesseractを指定
engines = pyocr.get_available_tools()
tesseract = engines[0]
# 対応言語のリストを取得
langs = tesseract.get_available_languages()
print("Available languages:", langs)
# 画像の文章を読み込む
txt = tesseract.image_to_string(Image.open("merosu.png"), lang="jpn")
print(txt)
まず、pyocr.get_available_tools() により、PyOCRで利用可能なOCRエンジンのリスト engines を取得できます。OCRエンジンとしてTesseractのみを導入した場合、engines[0] が tesseract に対応します。
続いて、tesseract.get_available_languages() により、導入したTesseractに対応している言語のリスト langs を取得できます。今回は日本語文章に対するOCRを行いたいので、jpn が含まれていればOKです。
最後に、先のサンプル画像 merosu.png を読み込み、tesseract.image_to_string() によって文字列に変換します。
環境によって細部は変化しますが、次のような出力が得られます。
対応言語: ['eng', 'jpn', 'jpn_vert', 'osd', 'script/Japanese', 'script/Japanese_vert']
メロスは激怒した。必ず、かの那智暴虐の王を除かなければならぬと決意し
た。メロスには政治がわからぬ。メロスは、村の牧人である。笛を吹き、羊
と遊んで暮して来た。けれども邪悪に対しては、人一倍に敏感であった。
「邪知暴虐」の「邪」が「那」と誤認識されていますが、これ以外の部分は正しく変換されていることが分かります。
OCRによるノベルゲームのテキスト抽出
では、実際にノベルゲームでテキストが表示されるメッセージウィンドウに対してOCRを適用し、テキストを抽出してみます。
メッセージウィンドウの切り抜き
まず、ノベルゲームにおいて文章が出力されるメッセージウィンドウの矩形領域を画像として切り抜きます。

事前にPythonのGUI自動化ライブラリ pyautogui のインストールが必要です。
pip install pyautogui
また、後ほど簡単なGUIアプリを作成するための準備として、PythonでGUIを組むためのツールキット Tkinter を使用します。
import pyautogui
import tkinter as tk
# 矩形領域の設定
RECT_BEGIN_X, RECT_BEGIN_Y = 360, 610
RECT_END_X, RECT_END_Y = 1120, 710
RECT_W, RECT_H = RECT_END_X - RECT_BEGIN_X, RECT_END_Y - RECT_BEGIN_Y
# GUIウィンドウの雛形を準備
root = tk.Tk()
def get_txt_image():
# 指定した矩形領域のスクリーンショットを取得・保存(300 msごとに再実行)
txt_image = pyautogui.screenshot(region=(RECT_BEGIN_X, RECT_BEGIN_Y, RECT_W, RECT_H))
txt_image.save("txt_image.png")
root.after(300, get_txt_image)
get_txt_image()
root.mainloop()
矩形領域の定数は環境に応じて適宜変更してください。
上記を実行すると、$300 \ \rm{ms}$ ごとに指定した矩形領域のスクリーンショットが txt_image.png として保存されます。

メッセージウィンドウに対するOCRの適用
先で得られた矩形領域の画像に対して、OCRを適用します。
import pyautogui
import tkinter as tk
import pyocr
# 矩形領域の設定
RECT_BEGIN_X, RECT_BEGIN_Y = 360, 610
RECT_END_X, RECT_END_Y = 1120, 710
RECT_W, RECT_H = RECT_END_X - RECT_BEGIN_X, RECT_END_Y - RECT_BEGIN_Y
# OCRエンジンを取得
engines = pyocr.get_available_tools()
tesseract = engines[0]
# GUIウィンドウの雛形を準備
root = tk.Tk()
def ocr_txt_image():
# 指定した矩形領域のスクリーンショットを取得・保存(300 msごとに再実行)
txt_image = pyautogui.screenshot(region=(RECT_BEGIN_X, RECT_BEGIN_Y, RECT_W, RECT_H))
txt_image.save("txt_image.png")
# OCRで画像の文章を読み込む
txt = tesseract.image_to_string(txt_image, lang="jpn")
print(txt)
root.after(300, ocr_txt_image)
ocr_txt_image()
root.mainloop()
- 矩形領域の画像(プレーン):
- 出力文字列(プレーン):
out_plain.txt
「関東だと求肥を使う3るが<くWe、 関西だと小却粉や山合ど かなんだうででさ1
出力された文字列のうち半分ほどが正しく認識されていないことが見て取れます。
一般に、文字列の背景にカラフルな模様などが描かれている場合、正確な変換が行われないことが多いです。
よって、OCRを行う前に、文字列の背景に存在する余計な模様などを取り除く必要があります。
画像処理によるOCRの認識性能向上
まず、矩形領域の画像をグレースケール画像に変換します。
- 矩形領域の画像(グレースケール):

- 出力文字列(グレースケール):
out_grayscale.txt
「関東だと求肥を使う志%2が少くWぐ、 関西だ厨小麦粉や山合 がかなんだうGきI
次に、グレースケール変換された矩形領域の画像における各ピクセルについて、画像における最大輝度からの差を一定の倍率に拡大します(変換後の輝度が $0$ 未満になる場合、変換後の輝度は $0$ とします)。2 3
例えば、画像における最大輝度が $230$ であり、拡大倍率を $5$ とするとき、輝度 $200$ のピクセルの輝度を $$ \max( 0, 230 + (200 - 230) \times 5 ) = 80 $$ に変換し、輝度 $100$ のピクセルの輝度を $$ \max( 0, 230 + (100 - 230) \times 5 ) = 0 $$ に変換します。
- 矩形領域の画像(輝度の差を拡大):

- 出力文字列(輝度の差を拡大):
out_highlight_white.txt
「関東だと求肥を使うことが多くて、関西だと小麦粉や山芋と かなんだってさ」
この時点で認識性能はかなり改善されていますが、ゲーム側の設定を変更することにより、さらに認識性能を高められる可能性があります。
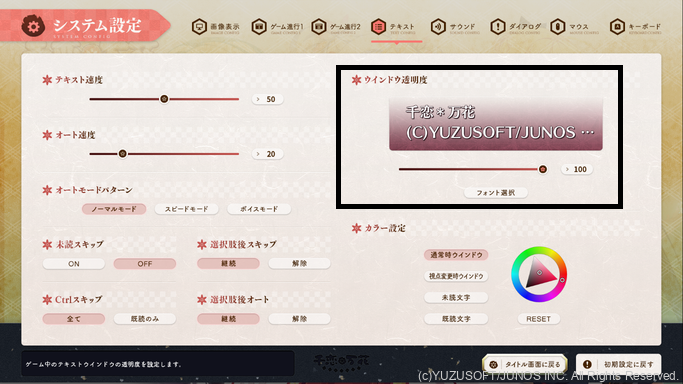
例えば、本記事で取り上げているノベルゲーム『千恋*万花』の場合、
- [システム設定] → [テキスト] → [ウィンドウ透明度] の順に選択し、ウィンドウ透明度の数値を $100$ に変更する
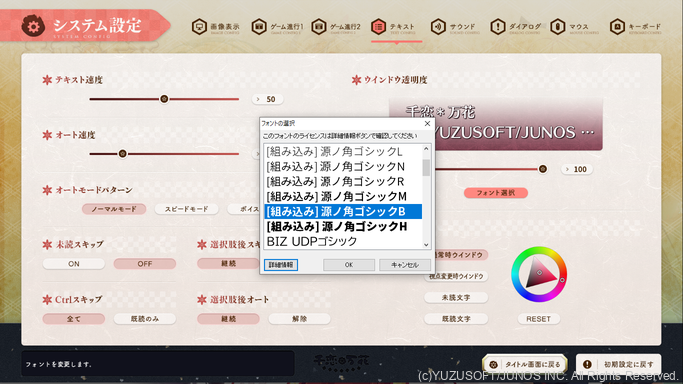
- [システム設定] → [テキスト] → [フォント選択] の順に選択し、メッセージウィンドウにおけるテキストのフォントを「源ノ角ゴシックB」等に変更する
という操作を行うことで、認識性能がさらに向上します。

- 矩形領域の画像(ゲーム側の設定を変更):

- 出力文字列(ゲーム側の設定を変更):
out_highlight_white2.txt
「関東だと求肥を使うことが多くて、関西だと小麦粉や山芋と かなんだってさ」
ここまでの処理をPythonのソースコードに記述します(事前に numpy のインストールが必要です)。
pip install numpy
import pyautogui
import tkinter as tk
import numpy as np
from PIL import Image
import pyocr
# OCRエンジンのリストを取得してTesseractを指定
engines = pyocr.get_available_tools()
tesseract = engines[0]
# 矩形領域の設定
RECT_BEGIN_X, RECT_BEGIN_Y = 360, 610
RECT_END_X, RECT_END_Y = 1120, 710
RECT_W, RECT_H = RECT_END_X - RECT_BEGIN_X, RECT_END_Y - RECT_BEGIN_Y
# GUIウィンドウの雛形を準備
root = tk.Tk()
def highlight_white(image, highlight_level):
# 画像をグレースケール変換して最も輝度の高い部分を強調
array = np.array(image.convert('L'))
base = np.full(array.shape, int(np.max(array)))
array = np.clip(base + (array - base) * highlight_level, 0, 255).astype(np.uint8)
enhanced_image = Image.fromarray(array, mode='L')
return enhanced_image
def ocr_txt_image():
# 指定した矩形領域のスクリーンショットを取得し、OCRを適用(300 msごとに再実行)
txt_image = pyautogui.screenshot(region=(RECT_BEGIN_X, RECT_BEGIN_Y, RECT_W, RECT_H))
enhanced_image = highlight_white(txt_image, 5)
enhanced_image.save("highlight_image.png")
# OCRで画像の文章を読み込む
txt = tesseract.image_to_string(enhanced_image, lang="jpn")
print(txt)
root.after(300, ocr_txt_image)
ocr_txt_image()
root.mainloop()
$300 \ \rm{ms}$ ごとに指定した矩形領域の画像を取得し、そこからOCRでテキストを抽出する流れは先程までと同様ですが、上記のプログラムでは、矩形領域の画像にOCRの認識性能を向上させるための処理を行う関数 highlight_white() を追加しています。
この関数は、グレースケール変換を行った矩形領域の画像における各ピクセルの輝度をNumPy配列に格納し、各要素について画像における最大輝度からの差を一定の倍率に拡大する処理を行った後、配列をグレースケール画像に変換したものを返します。
単語検索を効率化するGUIアプリの作成
ここまでの説明を踏まえ、冒頭で述べた目的(ノベルゲームのテキスト内に登場した単語の検索をある程度自動化すること)を達成するための簡単なGUIアプリを作成します。
先にアプリのソースコード全体を示します。
import numpy as np
import pyautogui
import tkinter as tk
from tkinter import scrolledtext
import pyocr
from PIL import Image
import webbrowser
# 矩形領域の設定
RECT_BEGIN_X, RECT_BEGIN_Y = 360, 610
RECT_END_X, RECT_END_Y = 1120, 710
RECT_W, RECT_H = RECT_END_X - RECT_BEGIN_X, RECT_END_Y - RECT_BEGIN_Y
# OCRエンジンを取得
engines = pyocr.get_available_tools()
tesseract = engines[0]
# GUIウィンドウを作成
root = tk.Tk()
root.geometry("540x220+10+10")
root.title("OCR Search")
enter_flag = False
# テキストエリアの作成
txtarea_label = tk.Label(root, text="【テキスト】")
txtarea_label.place(x=10, y=5)
txtarea = scrolledtext.ScrolledText(root,
wrap = tk.WORD,
width = 55,
height = 4,
font = ("Helvetica", 12)
)
txtarea.place(x=10, y=25)
# 検索ボックスの作成
txtbox_label = tk.Label(root, text="【検索ボックス】")
txtbox_label.place(x=10, y=110)
txtbox = tk.Entry(
width=55,
font = ("Helvetica", 12)
)
txtbox.place(x=10, y=130)
# 検索ボタンの作成
def search_txtbox(header):
word = txtbox.get()
url = ''.join([header, word])
root.iconify()
webbrowser.open(url, 1)
search_button_txts = [
"Google検索(すべて)",
"Weblio検索",
"Wikipedia検索",
"Google検索(画像)",
]
search_url_headers = [
"https://www.google.com/search?hl=ja&q=",
"https://www.weblio.jp/content/",
"https://ja.wikipedia.org/wiki/",
"https://www.google.com/search?hl=ja&tbm=isch&q=",
]
search_buttons_num = len(search_button_txts)
search_buttons = [None] * search_buttons_num
for i, (txt, header) in enumerate(zip(search_button_txts, search_url_headers)):
search_buttons[i] = tk.Button(root, text=txt, width=16,
command=lambda x=header : search_txtbox(x))
search_buttons[i].place(x=10 + 130 * i, y=160)
def highlight_white(image, highlight_level):
# 画像をグレースケール変換して最も輝度の高い部分を強調表示
array = np.array(image.convert('L'))
base = np.full(array.shape, int(np.max(array)))
array = np.clip(base + (array - base) * highlight_level, 0, 255).astype(np.uint8)
enhanced_image = Image.fromarray(array, mode='L')
return enhanced_image
# マウスカーソルがGUIウィンドウ内に存在するか判定
def on_enter(event):
global enter_flag; enter_flag = True
# print("enter")
def on_leave(event):
x, y = root.winfo_pointerxy()
if(root.winfo_containing(x, y) == root):
return
global enter_flag; enter_flag = False
# print("leave")
root.bind("<Enter>", on_enter)
root.bind("<Leave>", on_leave)
def ocr_txt_image():
# 指定した矩形領域のスクリーンショットを取得し、OCRを適用(300 msごとに再実行)
# ウィンドウ内にマウスカーソルがないときのみ有効
if not(enter_flag):
txt_image = pyautogui.screenshot(region=(RECT_BEGIN_X, RECT_BEGIN_Y, RECT_W, RECT_H))
image = highlight_white(txt_image, 5)
image.save("enhanced_image.png")
# OCRで画像の文章を読み込む
txt = tesseract.image_to_string(image, lang="jpn")
txtarea.delete(0., tk.END)
txtarea.insert(tk.END, txt)
root.after(300, ocr_txt_image)
ocr_txt_image()
def paste_txtbox():
# 選択範囲のテキストを検索ボックスに貼り付け(100 msごとに再実行)
if(txtarea.tag_ranges(tk.SEL)):
txt = txtarea.get(txtarea.index(tk.SEL_FIRST), txtarea.index(tk.SEL_LAST))
txtbox.delete(0, tk.END)
txtbox.insert(tk.END, txt)
root.after(100, paste_txtbox)
paste_txtbox()
root.attributes("-topmost", True)
root.mainloop()
矩形領域の設定とGUIウィンドウの作成
まず、矩形領域の定数を設定してOCRエンジンを取得する過程は、先程までと同様です。
次に、先程はGUIウィンドウを最低限の部分のみ作成しましたが、今回は必要な分のウィンドウサイズ及びウィンドウのタイトルも設定します。また、GUIウィンドウ内にマウスカーソルが存在するかどうかを判定したいので、この状態を格納する変数 enter_flag の初期化を行います。
# GUIウィンドウを作成
root = tk.Tk()
root.geometry("540x220+10+10")
root.title("OCR Search")
enter_flag = False
テキストエリアと検索ボックスの作成
続いて、TkinterのWidgetの一種である ScrolledText を用いてテキストエリアを作成します。OCRによって抽出された文字列がこのエリア内に格納されます。
また、検索する単語を格納するための入力ボックスも作成します。こちらは Entry Widgetを用います。テキストエリア内の文字列をドラッグしたとき、選択範囲の文字列がそのまま格納されます。
# テキストエリアの作成
txtarea_label = tk.Label(root, text="【テキスト】")
txtarea_label.place(x=10, y=5)
txtarea = scrolledtext.ScrolledText(root,
wrap = tk.WORD,
width = 55,
height = 4,
font = ("Helvetica", 12)
)
txtarea.place(x=10, y=25)
# 検索ボックスの作成
txtbox_label = tk.Label(root, text="【検索ボックス】")
txtbox_label.place(x=10, y=110)
txtbox = tk.Entry(
width = 55,
font = ("Helvetica", 12)
)
txtbox.place(x=10, y=130)
検索ボタンの作成
次に、単語検索を実施するボタンを作成します。これらのボタンをクリックすると自動でWebブラウザが開かれ、入力ボックスに格納された単語の検索が行われます。4
今回は $4$ 種類のボタンを作成しており、それぞれ Google検索(すべて)、Weblio検索、Wikipedia検索、Google検索(画像) に対応しています。
# 検索ボタンの作成
def search_txtbox(header):
word = txtbox.get()
url = ''.join([header, word])
root.iconify()
webbrowser.open(url, 1)
search_button_txts = [
"Google検索(すべて)",
"Weblio検索",
"Wikipedia検索",
"Google検索(画像)",
]
search_url_headers = [
"https://www.google.com/search?hl=ja&q=",
"https://www.weblio.jp/content/",
"https://ja.wikipedia.org/wiki/",
"https://www.google.com/search?hl=ja&tbm=isch&q=",
]
search_buttons_num = len(search_button_txts)
search_buttons = [None] * search_buttons_num
for i, (txt, header) in enumerate(zip(search_button_txts, search_url_headers)):
search_buttons[i] = tk.Button(root, text=txt, width=16,
command=lambda x=header : search_txtbox(x))
search_buttons[i].place(x=10 + 130 * i, y=160)
マウスカーソルの存在判定
前述のマウスカーソルがGUIウィンドウ内に存在するかどうかの判定は、GUIウィンドウの参照 root に対して bind() を設定することで実現します。
# マウスカーソルがGUIウィンドウ内に存在するか判定
def on_enter(event):
global enter_flag; enter_flag = True
# print("enter")
def on_leave(event):
x, y = root.winfo_pointerxy()
if(root.winfo_containing(x, y) == root):
return
global enter_flag; enter_flag = False
# print("leave")
root.bind("<Enter>", on_enter)
root.bind("<Leave>", on_leave)
矩形領域の画像取得とOCRによるテキスト抽出
矩形領域の画像取得と画像処理及びOCRは、基本的に先程までと同様ですが、マウスカーソルがGUIウィンドウ内に存在しない場合にのみ有効とし、抽出されたテキストを先のテキストエリア内に格納する処理を追加しています。
def ocr_txt_image():
# 指定した矩形領域のスクリーンショットを取得し、OCRを適用(300 msごとに再実行)
# ウィンドウ内にマウスカーソルがないときのみ有効
if not(enter_flag):
txt_image = pyautogui.screenshot(region=(RECT_BEGIN_X, RECT_BEGIN_Y, RECT_W, RECT_H))
image = highlight_white(txt_image, 5)
image.save("enhanced_image.png")
# OCRで画像の文章を読み込む
txt = tesseract.image_to_string(image, lang="jpn")
txtarea.delete(0., tk.END)
txtarea.insert(tk.END, txt)
root.after(300, ocr_txt_image)
ocr_txt_image()
選択範囲の貼り付け
前述のテキストエリア内における選択範囲の文字列を入力ボックスに格納する処理は、関数 paste_txtbox() によって実現されます。関数 get_txt_image() と並行して、$100 \ \rm{ms}$ ごとに繰り返し実行されます。
def paste_txtbox():
# 選択範囲のテキストを検索ボックスに貼り付け(100 msごとに再実行)
if(txtarea.tag_ranges(tk.SEL)):
txt = txtarea.get(txtarea.index(tk.SEL_FIRST), txtarea.index(tk.SEL_LAST))
txtbox.delete(0, tk.END)
txtbox.insert(tk.END, txt)
root.after(100, paste_txtbox)
paste_txtbox()
GUIアプリの実行
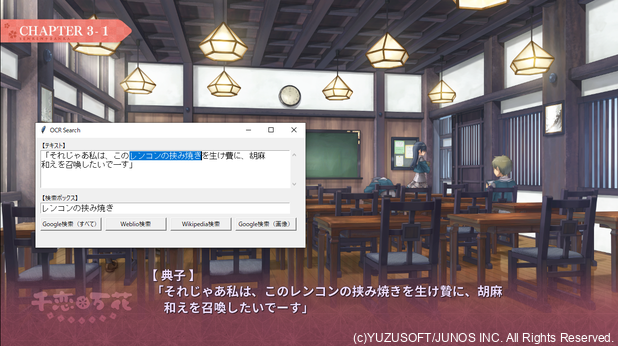
以上の実装を踏まえ、このアプリを実行したときの画面は、次のようになります。

メッセージウィンドウに表示されたテキストがOCRによって抽出された後、GUIウィンドウのテキストエリア内に格納されます。
この中の検索したい単語をドラッグで選択して $4$ 種類のボタンのうちいずれかをクリックすることにより、当該単語の検索が行われます。
画像検索を行う場合も同様に、検索した単語を範囲選択し、画像検索に対応するボタン(ここでは「Google検索(画像)」)をクリックすれば良いです。
まとめ
以下、本記事のまとめです。
- OCR(Optical Character Recognition / 光学文字認識)とは、活字や手書きの文章を画像として読み込み、これを文字コードの列に変換する技術を指す。
- OCRエンジンの一種であるTesseractと、PythonでOCRを行うためのツールPyOCRを導入することで、PythonでOCRを実施するプログラムを作成できる。
- ノベルゲームでテキストが表示されるメッセージウィンドウのスクリーンショットを取得し、これに対してOCRを適用することにより、テキストの抽出を行った。
- 先のスクリーンショットに対して、OCRをそのまま適用するだけでは正しく認識されない文字が多い。グレースケール画像に変換して各ピクセルについて最大輝度からの差を拡大する等、適切な画像処理を施すことによって認識性能を高められることを確認した。
- OCRによるテキスト抽出と、GUIツールキットTkinterを組み合わせることで、ノベルゲーム中で気になった単語の検索を効率化できるGUIアプリを作成した。
おまけ:GUIアプリのデモ動画
-
以下、本記事で当該ゲームにおける特定の場面を切り取った画像をいくつか使用しますが、これらはすべてゆずソフト様による「著作権に関するガイドライン」に従います。 ↩
-
このような処理は、グレースケール画像における文字列の輝度と背景の輝度の差が十分大きく、文字列の輝度が $255$(白色)に近い場合にのみ有効です。文字列の輝度が $0$(黒色)に近い場合は、画像における最小輝度を参照すると良いです。 ↩
-
このような処理とは別に、閾値としてある整数値 $k$ $(0 \leq k \leq 255)$ を定め、輝度が $k$ 以上のピクセルの輝度を $255$、そうでないピクセルの輝度を $0$ として二値化する方法も考えられます。筆者の環境では輝度の差を拡大する処理の方がOCRの認識性能が上だったため、二値化する方法は採用していません。 ↩
-
Tkinterでボタンを作成する関数
tkinter.Button()は、functools.partial()を用いて次のように設定しても良いです。
tk.Button(root, text=txt, width=16, command=functools.partial(search_txtbox, header)↩