エラーログには残らない「N+1問題」や「無駄な直列処理」に気づけていますか?New Relicの新機能「Performance Risks Inbox」なら、システムに潜む隠れたボトルネックを自動検知できます!本記事では、障害対応をプロアクティブに変える強力な新機能の概要と使い方を解説します。
この機能はプレビューとして公開されている機能でまだ開発中です。
はじめに:障害対応を「リアクティブ」から「プロアクティブ」へ
システム運用において、エラーや障害が発生してから対応する 「リアクティブ(事後対応)」 なアプローチは、ユーザー体験を大きく損なうリスクがあります。理想は、障害に発展する前にパフォーマンスの劣化要因を特定し、「プロアクティブ(事前対処)」 に改善することです。
しかし、以下のような課題はエラーログには残りません。
- じわじわとシステムリソースを食いつぶす非効率なコード
- 開発環境では気づきにくく、本番環境のデータ量で発覚するアンチパターン
これらはまさにシステムを蝕む 「隠れたボトルネック」 です。これらを見つけ出すのは容易ではありませんでしたが、今回 New Relic から発表された新機能 「Performance Risks Inbox」 は、この課題を解決するための強力な武器になります。
最新のアップデートの詳細はこちら
New Relic アップデート一覧
無料のアカウントで試してみよう!
New Relic フリープランで始めるオブザーバビリティ!
Performance Risks Inboxとは?
「Performance Risks Inbox」は、アプリケーションのコードに潜む「パフォーマンスのアンチパターン(非効率な処理)」を自動的に検知し、一元管理できる機能です。
これまで提供されていた「Errors Inbox」と比べると、その役割の違いがよくわかります。
- Errors Inbox: すでに起きてしまったエラーを管理・対応
- Performance Risks Inbox: 将来ボトルネックや障害になり得る「リスク」を事前検知
開発者はダッシュボードを自作したり、複雑な NRQL(New Relic Query Language)を書いたりすることなく、自動で抽出されたリスクリストを確認するだけで、優先的にリファクタリングすべきコードの目星をつけることができます。
従来のアプローチ(NRQLによる調査)との違い
これまで、New Relic を使用してデータベースのボトルネックや非効率なクエリを特定する場合、APM のデータをもとに 開発者自身が NRQL を書いてダッシュボードを作成したり、トランザクションを深く掘り下げたりする「能動的な調査」 が基本でした。
▼ 従来のNRQLを使用したDB改善のアプローチについては、以下の記事で詳しく解説しています。
一方、今回登場した「Performance Risks Inbox」は、New Relic 側が自動でリスク(N+1 などのアンチパターン)を抽出し、「受動的な発見」 を可能にします。
開発者はダッシュボードを自作したり、複雑な NRQL を書いたりすることなく、自動で抽出されたリスクリストを確認するだけで、優先的にリファクタリングすべきコードの目星をつけることができます。
自動検知可能な6つの具体的なリスク
現在、Performance Risks Inboxでは、開発者が陥りやすい6つの代表的なアンチパターンを自動検知してくれます。
データベース関連のリスク(4種類)
1. N+1問題(N+1 queries): 「ループ内で同じクエリを連発」
2. 過剰なDBクエリ (Excessive DB queries): 「1リクエスト内のクエリ総数が多すぎ」
3. 連続したDBクエリ(Sequential DB queries): 「独立したクエリの無駄な直列待ち」
4. 遅いSQL (Slow SQL queries): 「単一で重いボトルネッククエリ」
特に混同しやすい3つのリスクについて、その違いを整理してみましょう。
| リスクの種類 | 特徴 | 着眼点 | 解決のアプローチ(例) |
|---|---|---|---|
N+1問題(N+1 queries)
|
親データを取得後、関連する子データを取るために同じSQLがループ内で何度も繰り返される状態。 | クエリの発生パターン | Eager Loading(事前の一括読み込み)への変更 |
過剰なDBクエリ (Excessive DB queries)
|
1回のリクエスト内で発行されたクエリの総数が異常に多い状態(複雑なビジネスロジックなど)。 | クエリの合計回数 | ロジックの簡略化、キャッシュの活用、バルク処理への変更 |
連続したDBクエリ(Sequential DB queries)
|
独立した複数のクエリを、並列処理せずに一つずつ順番(直列)に待って実行している状態。 | クエリの実行順序 | 非同期・並列実行への変更 |
Performance Risks Inboxの素晴らしい点は、これらを単に「DBアクセスが遅い」とひと括りにするのではなく、原因レベルまで自動で切り分けて提示してくれる点です。これにより、インデックスを追加すべきか、コードを書き換えるべきかを即座に判断できます。
外部通信(HTTPリクエスト)関連のリスク(2種類)
マイクロサービスアーキテクチャや、外部サードパーティAPIを多用するモダンなシステムでよくあるアンチパターンもカバーしています。
5. 連続したHTTPリクエスト (Sequential HTTP requests):
「連続したDBクエリ」のHTTP版です。複数の外部APIを叩く際、並列リクエスト(例:Node.jsの Promise.all など)を行わず、1つずつ順番にレスポンスを待機している非効率な状態を検知します。
6. 巨大なHTTPペイロード (Large HTTP payloads):
APIレスポンスのデータサイズが大きすぎる状態です。不要なフィールドまで取得している可能性が高く、ネットワーク帯域の圧迫や、プロセスのメモリ枯渇の原因になります。
始め方と使い方
Performance Risks Inbox を利用するために、追加のコード埋め込みや複雑な設定は不要です。既存の New Relic APM エージェントが収集しているデータから自動的に分析されます。
始め方
Previews & Trials の有効化手順
- New Relic UIにログインし、画面左下のユーザー名をクリックします。
- Administration > Previews & Trials を選択します。
-
Performance Risks Inbox の機能を「Opted in (有効)」に切り替えることで、すぐに利用が開始できます。

アクセス方法
以下のいずれかの導線から簡単にアクセスできます。
- New Relic 画面の左側メニュー [APM & Services] や [Browser] 内のメニューから

- 既存の [Errors Inbox] 画面の上部にあるタブ切り替えから

使い方
基本的な使い方は Errors Inbox と同じです。
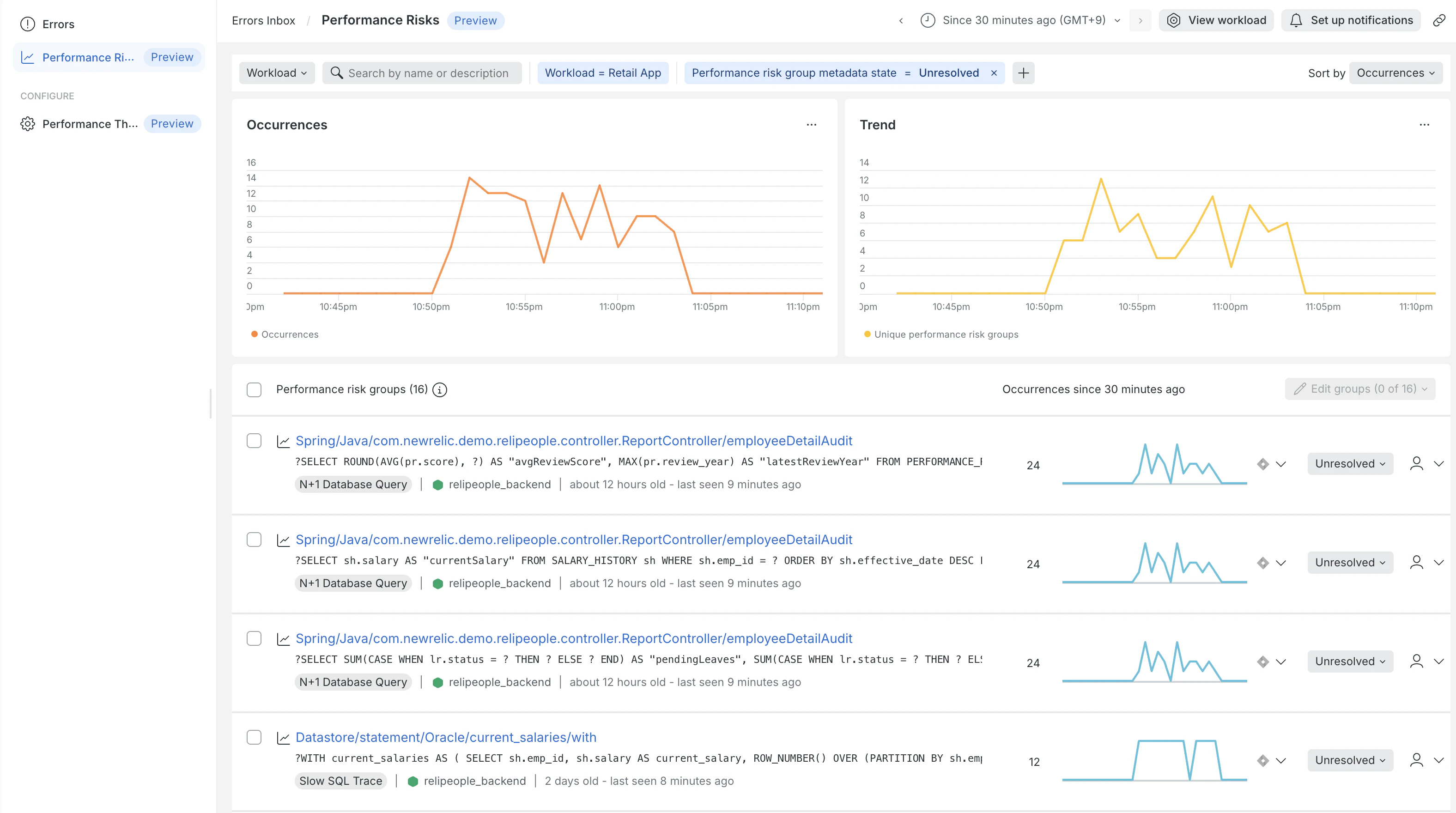
具体的には、以下のようなステップで「隠れたボトルネック」の特定と解消を進めていきます。
1. リスクのトリアージと優先順位付け
一覧画面には、検知されたリスクの種類(N+1、遅いSQLなど)ごとにグループ化されて表示されます。発生頻度や影響を受けているトランザクションなどを一目で確認できるため、「どのリスクから手をつけるべきか」の優先順位(トリアージ)をすぐに行うことができます。
リスクの種類でのフィルタリングにも対応しているため、リファクタリングの目的に合ったリスクだけに絞り込むこともできます。
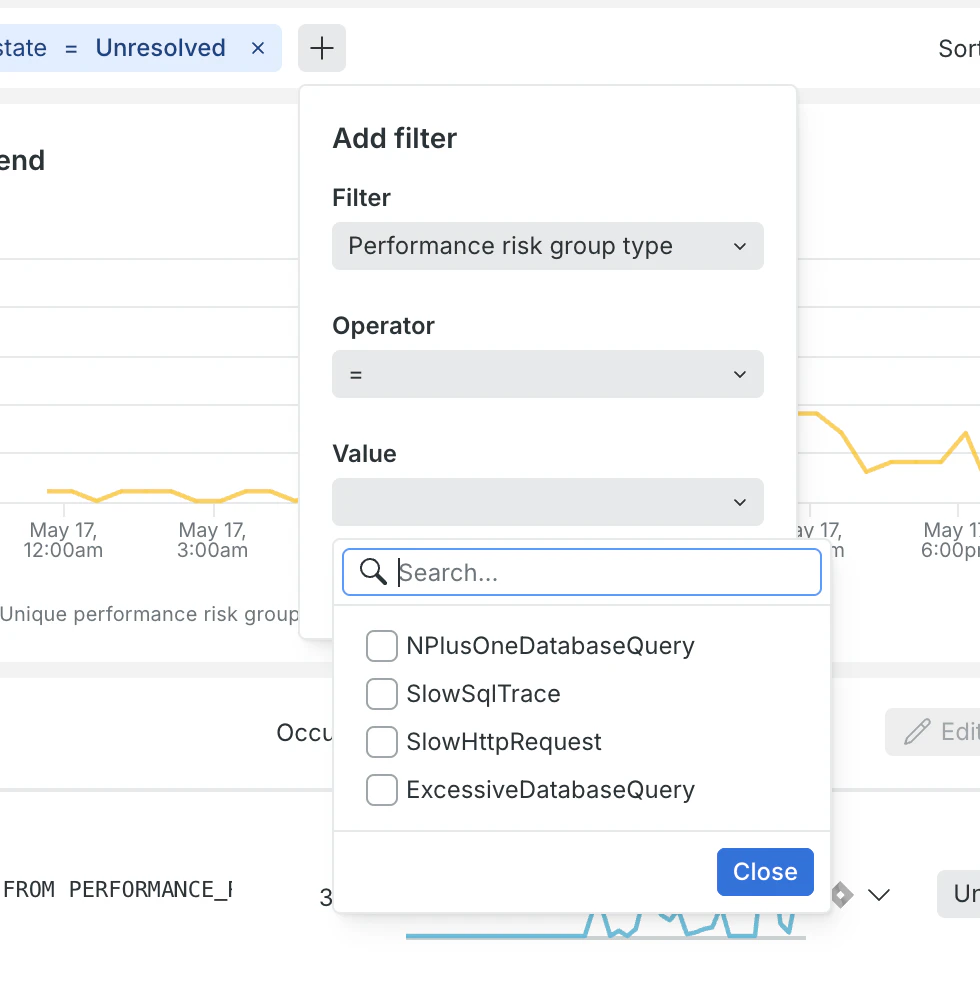
2. リスクの深掘り
気になるリスクをクリックすると、さらに詳細なデータを確認できます。
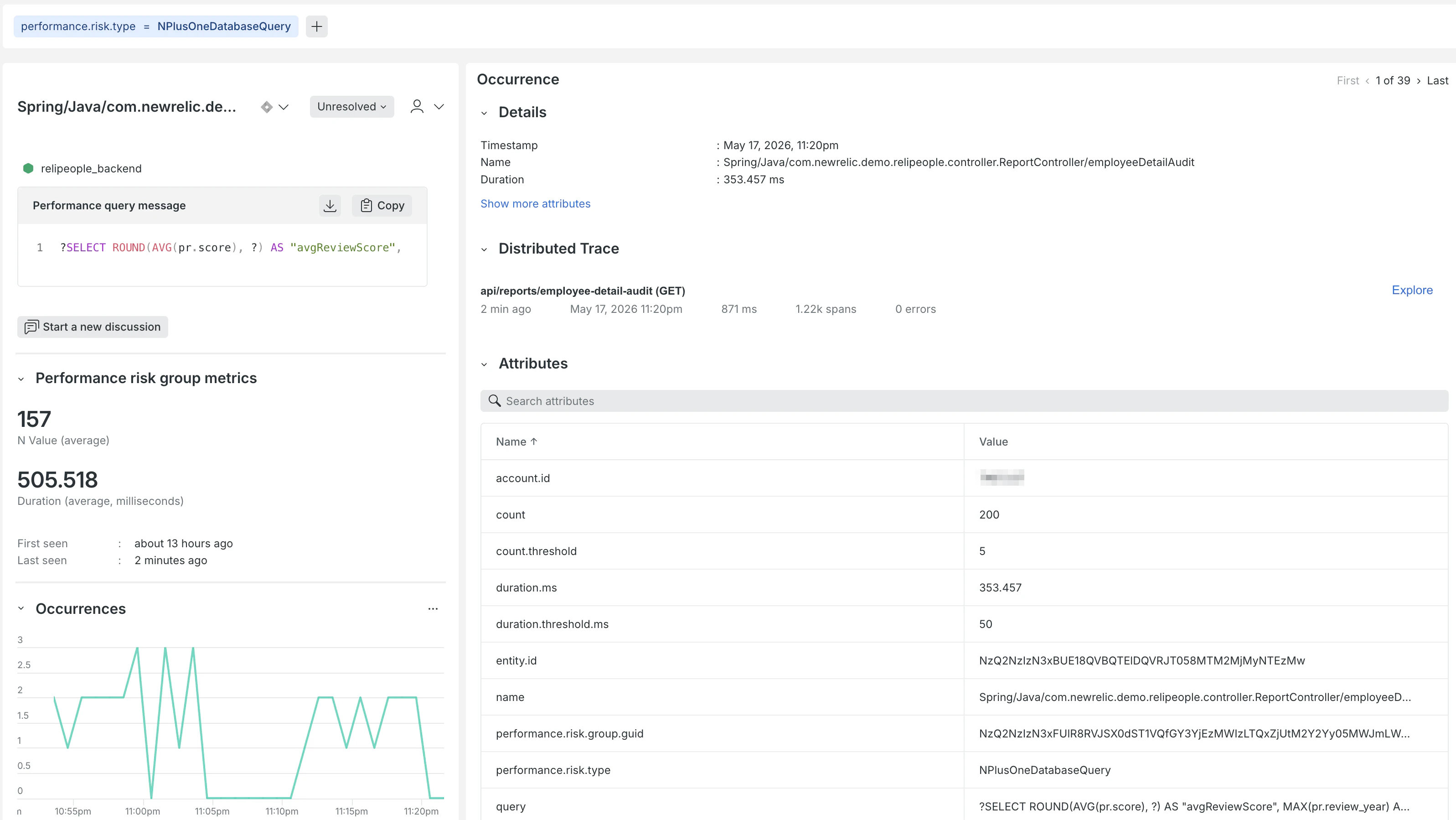
- どのエンドポイントの、どの処理で問題が起きているか
- 具体的にどんなSQLクエリが発行されているか
- 外部APIの呼び出しにかかっている時間やペイロードのサイズ
このように、コードのどの部分を修正すべきか(リファクタリングの「当たり」)を、ログを漁ることなくピンポイントで特定できます。
3. ステータス管理とチームへの共有
Errors Inbox と同様に、各リスクに対してステータス(Unresolved、Ignored、Resolved など)を設定できます。
さらに、Jira といった外部ツールと連携することで、「このN+1問題の解消は次回のスプリントで行う」といった形で、そのままチームのタスクとしてチケット化・割り当てが可能です。
🚀 Public Preview で今すぐ試せます!
現在、Performance Risks Inboxは Public Preview として提供されており、対象のNew Relicユーザーであれば追加費用なしでご利用いただけます。
実践例:検知された「N+1問題」を解消し、時限爆弾を取り除く
Performance Risks Inbox で「N+1 queries」や「Excessive DB queries(過剰なDBクエリ)」が検知された場合、実際の現場ではどのように発見し、リファクタリングを行うのか。「従業員一覧と、それぞれの詳細情報」を返すAPIを例に見てみましょう。(※コードは Java の JdbcTemplate を想定した擬似コードです)
以下は、従業員一覧を取得した後に、従業員ごとに給与・休暇・レビュー情報を個別に取得してしまう典型的なN+1のアンチパターンです。
【本章のハイライト】
- 発見: Performance Risks Inbox が対象 API の N+1 問題を自動検知。ワンクリックで原因箇所を特定。
- 課題: ループ処理内で給与・休暇・レビューを個別に DB へ取りに行くアンチパターン(1リクエストで約450回のクエリが発生)。
- 解決: CTE(WITH句)を活用して DB 側で事前集計し、1つの SQL に統合(Eager Loading 的アプローチ)。
- 結果: DB へのネットワーク通信が 451回 → 1回 に激減し、レスポンスタイムが 1200ms → 35ms(97%改善) へ劇的改善!
発見:Performance Risks Inbox はこう知らせてくれる
ある日、Performance Risks Inbox に /employee-detail-audit というエンドポイント(Spring/Java/com.newrelic.demo.relipeople.controller.ReportController/employeeDetailAudit)がリスクとしてリストアップされました。
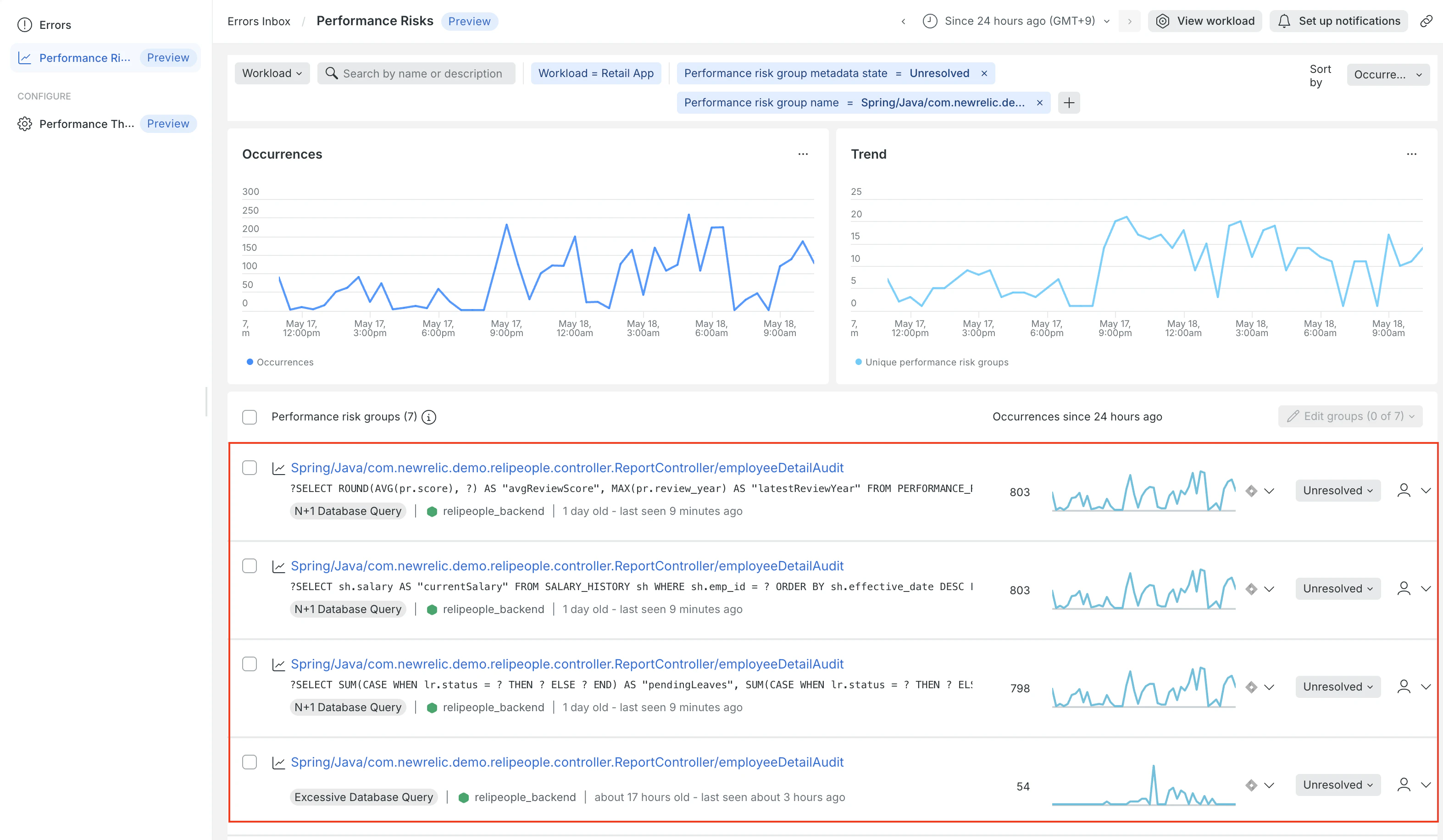
リストから該当のリスクを選択し、詳細画面を開いてみます。すると、「特定の SELECT 文が、1回のリクエスト内でそれぞれ平均 150 回ずつ連続して発行されている」 という事実が、グラフとともに可視化されています。

通常であれば、このような事象に気づくのは本番環境で障害が起きた後であり、原因特定のために膨大なログを grep したり、ソースコードをひたすら追いかけたりする苦労が待っています。
詳細画面から対応する分散トレーシング(Distributed Tracing)のリンクをワンクリックで辿るだけで、 「実際にどんなSQLが、どのメソッドから呼ばれているのか」 というトランザクションの全貌を確認できます。
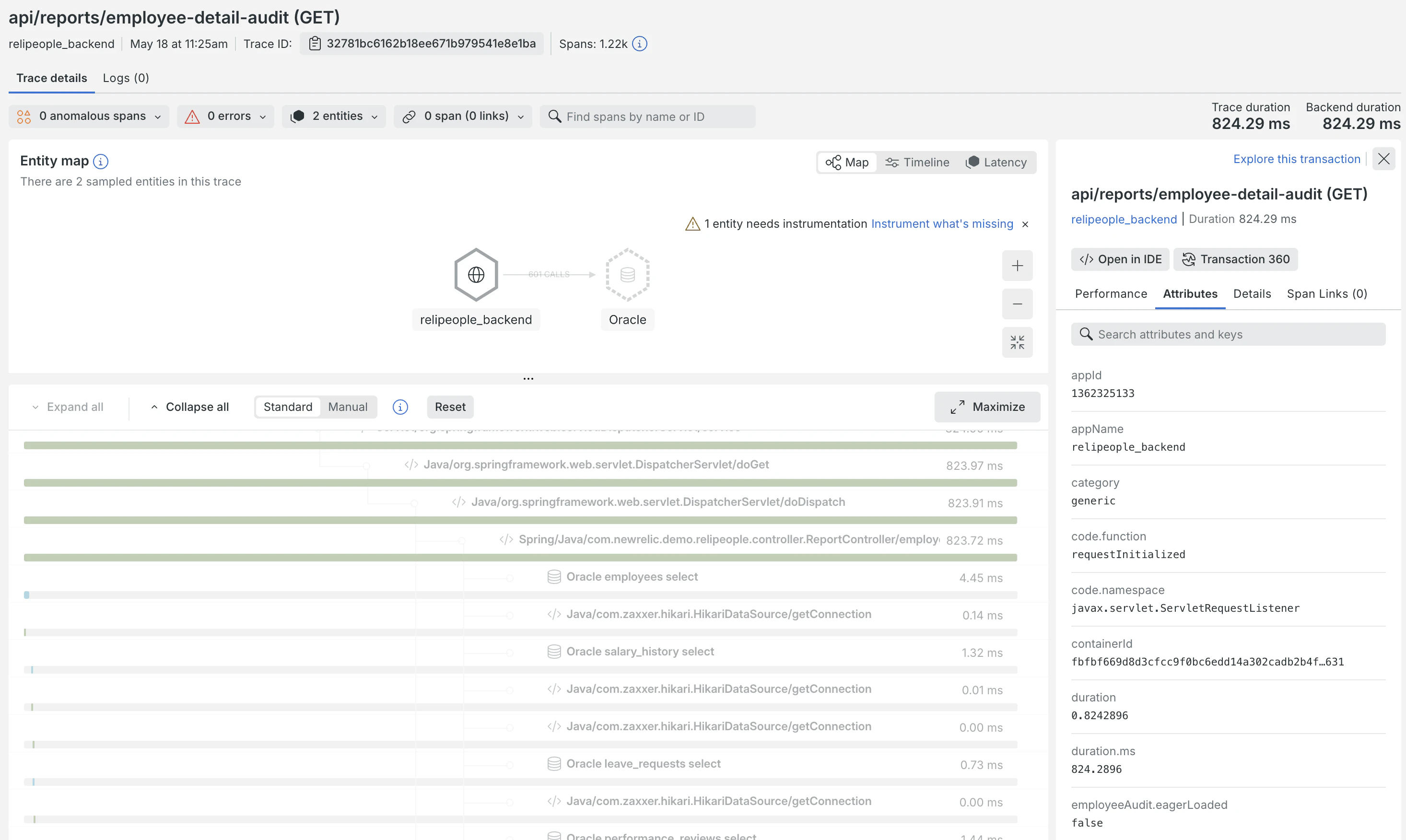
ログに頼ることなく、修正するべきメソッドの「当たり」をつけることができました。 原因箇所が特定できたので、いよいよ実際のコードを修正(リファクタリング)していきます。
❌ Before:N+1が発生しているコード(問題のある状態)
対象のコードを確認すると、従業員一覧を取得した後に、従業員ごとに給与・休暇・レビュー情報を個別に取得してしまう典型的なN+1のアンチパターンになっています。
N+1 が発生しているサンプルコード
@GetMapping("/employee-detail-audit")
public ResponseEntity<List<Map<String, Object>>> employeeDetailAudit(
@RequestParam(name = "limit", defaultValue = "75") int limit,
@RequestParam(name = "strategy", defaultValue = "nplus1") String strategy) {
int boundedLimit = Math.max(1, Math.min(limit, 200));
if ("eager".equals(strategy)) {
return ResponseEntity.ok(employeeDetailAuditEager(boundedLimit));
}
return ResponseEntity.ok(employeeDetailAuditNPlusOne(boundedLimit));
}
private List<Map<String, Object>> employeeDetailAuditNPlusOne(int boundedLimit) {
// 【1】まず、従業員の基本情報一覧を取得(ここで1回目のSQL発行)
String employeeSql = """
SELECT e.emp_id AS "empId",
e.first_name || ' ' || e.last_name AS "fullName",
d.dept_name AS "deptName",
jg.job_title AS "jobTitle"
FROM EMPLOYEES e
JOIN DEPARTMENTS d ON e.dept_id = d.dept_id
JOIN JOB_GRADES jg ON e.job_id = jg.job_id
ORDER BY e.last_name, e.first_name
FETCH FIRST ? ROWS ONLY
""";
List<Map<String, Object>> employees =
jdbcTemplate.queryForList(employeeSql, boundedLimit);
// 【2】取得した従業員リスト(最大200件)をループして、個別に詳細データを取りに行く
return employees.stream().map(employee -> {
Object empId = employee.get("empId");
Map<String, Object> result = new LinkedHashMap<>(employee);
// ループ内SQL①:最新給与の取得(N回発行される)
List<Map<String, Object>> salaryRows =
jdbcTemplate.queryForList("""
SELECT sh.salary AS "currentSalary"
FROM SALARY_HISTORY sh
WHERE sh.emp_id = ?
ORDER BY sh.effective_date DESC
FETCH FIRST 1 ROW ONLY
""", empId);
// ループ内SQL②:休暇申請のステータス別集計(N回発行される)
Map<String, Object> leaveSummary =
jdbcTemplate.queryForMap("""
SELECT
SUM(CASE WHEN lr.status = 'PENDING' THEN 1 ELSE 0 END) AS "pendingLeaves",
SUM(CASE WHEN lr.status = 'APPROVED' THEN 1 ELSE 0 END) AS "approvedLeaves",
SUM(CASE WHEN lr.status = 'DENIED' THEN 1 ELSE 0 END) AS "deniedLeaves"
FROM LEAVE_REQUESTS lr
WHERE lr.emp_id = ?
""", empId);
// ループ内SQL③:レビュー情報の平均・最新年集計(N回発行される)
Map<String, Object> reviewSummary =
jdbcTemplate.queryForMap("""
SELECT ROUND(AVG(pr.score), 2) AS "avgReviewScore",
MAX(pr.review_year) AS "latestReviewYear"
FROM PERFORMANCE_REVIEWS pr
WHERE pr.emp_id = ?
""", empId);
// 取得した各種データをMapに詰め込んで返す
result.put("currentSalary",
salaryRows.isEmpty() ? null : salaryRows.get(0).get("currentSalary"));
result.put("pendingLeaves", leaveSummary.get("pendingLeaves"));
result.put("approvedLeaves", leaveSummary.get("approvedLeaves"));
result.put("deniedLeaves", leaveSummary.get("deniedLeaves"));
result.put("avgReviewScore", reviewSummary.get("avgReviewScore"));
result.put("latestReviewYear", reviewSummary.get("latestReviewYear"));
return result;
}).toList();
}
なぜこのコードが危険なのか?
この実装では、従業員1件ごとに3つのSQLが実行されます。そのため、limit=200(従業員200名を表示)の場合は次のようになります。
従業員一覧の取得: 1 query
詳細取得のループ: 200 employees × 3 queries
合計: 601 queries
一つ一つのクエリが数ミリ秒で返ってきたとしても、「アプリケーション〜DB間の通信(ネットワーク・ラウンドトリップ)が600回発生する」という事実は変わりません。
今は動いていても、 アクセスが集中した瞬間にDBのコネクションプールを枯渇させ、システム全体を巻き込んでダウンさせる「パフォーマンスの時限爆弾」 になり得ます。
⭕️ After:クエリを統合して通信回数を激減させる(改善後)
この問題を解決するには、アプリケーション側でループを回してデータを組み立てるのではなく、必要な関連データを DB 側で先に集計・結合してから取得する(Eager Loading 的アプローチ)のが鉄則です。
今回は WITH 句を使って1つの SQL にまとめます。
N+1 を解消したサンプルコード
private List<Map<String, Object>> employeeDetailAuditEager(int boundedLimit) {
// 【改善】必要なデータをDB側でCTE(WITH句)を使って一括集計し、アプリケーションからの通信を1回に減らす
String sql = """
WITH
-- ① ベースとなる従業員一覧を先に取得し、順番(employee_order)をつけておく
target_employees AS (
SELECT emp_id, full_name, dept_name, job_title, employee_order
FROM (
SELECT e.emp_id,
e.first_name || ' ' || e.last_name AS full_name,
d.dept_name,
jg.job_title,
ROW_NUMBER() OVER (
ORDER BY e.last_name, e.first_name
) AS employee_order
FROM EMPLOYEES e
JOIN DEPARTMENTS d ON e.dept_id = d.dept_id
JOIN JOB_GRADES jg ON e.job_id = jg.job_id
)
WHERE employee_order <= ?
),
-- ② 対象従業員の給与履歴から、最新の給与を特定するための準備
ranked_salaries AS (
SELECT sh.emp_id,
sh.salary,
ROW_NUMBER() OVER (
PARTITION BY sh.emp_id
ORDER BY sh.effective_date DESC
) AS rn
FROM SALARY_HISTORY sh
JOIN target_employees te ON te.emp_id = sh.emp_id
),
-- ③ 対象従業員の休暇申請をステータスごとにGROUP BYで事前集計
leave_summary AS (
SELECT lr.emp_id,
SUM(CASE WHEN lr.status = 'PENDING' THEN 1 ELSE 0 END) AS pending_leaves,
SUM(CASE WHEN lr.status = 'APPROVED' THEN 1 ELSE 0 END) AS approved_leaves,
SUM(CASE WHEN lr.status = 'DENIED' THEN 1 ELSE 0 END) AS denied_leaves
FROM LEAVE_REQUESTS lr
JOIN target_employees te ON te.emp_id = lr.emp_id
GROUP BY lr.emp_id
),
-- ④ 対象従業員のレビュー情報をGROUP BYで事前集計
review_summary AS (
SELECT pr.emp_id,
ROUND(AVG(pr.score), 2) AS avg_review_score,
MAX(pr.review_year) AS latest_review_year
FROM PERFORMANCE_REVIEWS pr
JOIN target_employees te ON te.emp_id = pr.emp_id
GROUP BY pr.emp_id
)
-- ⑤ 最後に、ベースの従業員一覧(①)に対して、事前集計したデータ(②〜④)をLEFT JOINして一括取得する
SELECT te.emp_id AS "empId",
te.full_name AS "fullName",
te.dept_name AS "deptName",
te.job_title AS "jobTitle",
rs.salary AS "currentSalary",
NVL(ls.pending_leaves, 0) AS "pendingLeaves",
NVL(ls.approved_leaves, 0) AS "approvedLeaves",
NVL(ls.denied_leaves, 0) AS "deniedLeaves",
rv.avg_review_score AS "avgReviewScore",
rv.latest_review_year AS "latestReviewYear"
FROM target_employees te
LEFT JOIN ranked_salaries rs
ON rs.emp_id = te.emp_id AND rs.rn = 1
LEFT JOIN leave_summary ls
ON ls.emp_id = te.emp_id
LEFT JOIN review_summary rv
ON rv.emp_id = te.emp_id
ORDER BY te.employee_order
""";
// アプリケーションからDBへのアクセスは、この1回のみ!
return jdbcTemplate.queryForList(sql, boundedLimit);
}
改善の効果と確認
この実装では、給与・休暇・レビューの集計をリレーショナルデータベースが得意とする JOIN と GROUP BY に任せています。
- Before (N+1 版): 601 queries (ネットワーク通信601回)
- After (Eager 版): 1 query (ネットワーク通信1回)
limit=200 の場合でも、アプリケーションからDBへの問い合わせはわずか1回に激減しました。不要なループ処理がなくなったことで、アプリケーション側のメモリ消費やCPU負荷も劇的に改善されます。
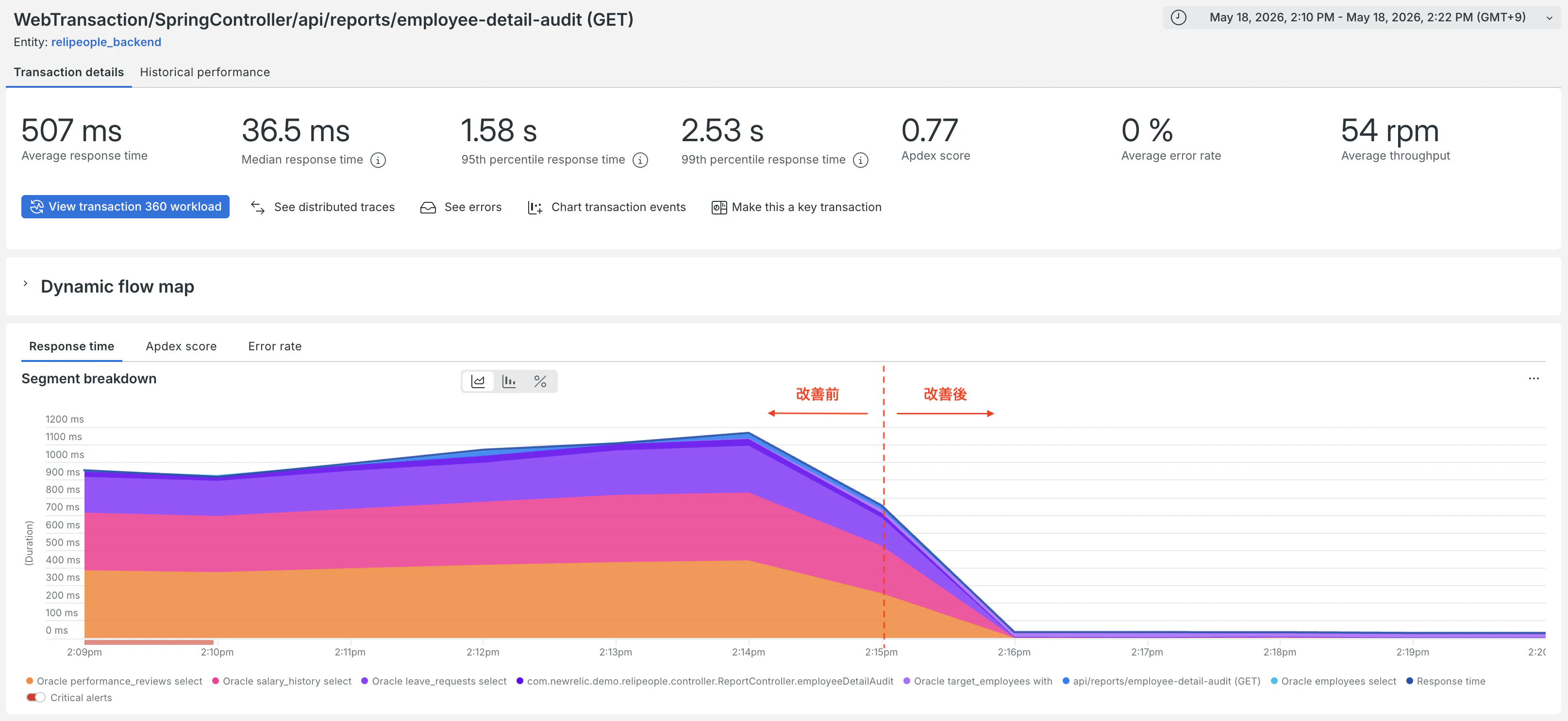
N+1 問題を解消することでレスポンスが大きく改善しています。
- 改善前: 平均 1200ms
- 改善後: 平均 35ms
修正をデプロイした後、New Relic の APM で対象エンドポイントの平均レスポンスタイムが大きく下がっていることを確認し、Performance Risks Inbox 上で該当リスクのステータスを Resolved(解決済み) に更新しましょう。
このように本番環境で障害を起こす前に「プロアクティブ」に技術的負債を返済することが可能です!
まとめ
システムが大規模化・複雑化するにつれて、エラーとして表面化しない「非効率なコード」をログやメトリクスから人力で見つけ出すことはますます困難になっています。
New Relic の新機能「Performance Risks Inbox」は、こうした隠れたパフォーマンスリスクを自動で可視化し、リファクタリングへの具体的なアクションへとスムーズに繋げてくれる強力な機能です。
- 「なんとなく最近システム全体が重い気がする」
- 「技術的負債(非効率なコード)を可視化して、チーム内でリファクタリングの説得材料にしたい」
といった課題をお持ちの開発チームや SRE の方は、ぜひ今日から Performance Risks Inbox を開いてみてください。あなたのコードに潜む「隠れたボトルネック」が、すでに見つかっているかもしれません。
障害が起きる前の「プロアクティブ」なパフォーマンス改善で、より快適なユーザー体験と健全なシステム運用を実現していきましょう!
New Relicでは、新しい機能やその活用方法について、QiitaやXで発信しています!
無料でアカウント作成も可能なのでぜひお試しください!
New Relic株式会社のX(旧Twitter) や Qiita Organizationでは、
新機能を含む活用方法を公開していますので、ぜひフォローをお願いします。
無料のアカウントで試してみよう!
New Relic フリープランで始めるオブザーバビリティ!
