※ロジスティック回帰についてメモを残そうとして、結局ロジスティック分布の平均と分散を計算して力尽きただけの記事です。ごめんなさい。
ロジスティック回帰は仕事でもよく使うのですが、ちょっと気になることがある時になかなか欲しい情報にたどり着けないことが多いので、自分用のメモとしてロジスティック回帰についてまとめておこうと思います。
ロジスティック回帰は医療分野等でよく使われるらしいです。
もちろん他の分野でも解釈性の高さやモデルのシンプルさ、の割に高い精度を出してくれるなどの理由から頻繁に使われます。
さて、入力ベクトル $x$ が2つのクラス $C_0, C_1$ のどちら割り当てられるかを予測する問題を考えます。
$y∈ \{0,1\}$ を目的変数(出力)、$x ∈ R^d$ を説明変数(入力)とします。
ここで、$C_0$ に割り当てられる時は $y = 0$、$C_1$ に割り当てられる時は $y = 1$ としています。
線形判別
人口的に生成した20個のデータを用意しました(私が適当に作っただけです)。
今回はPythonを使います。
import matplotlib.pyplot as plt
x = [1.3, 2.5, 3.1, 4, 5.8, 6, 7.5, 8.4, 9.9, 10, 11.1, 12.2, 13.8, 14.4, 15.6, 16, 17.7, 18.1, 19.5, 20]
y = [0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
plt.scatter(x, y)
plt.xlabel("x")
plt.ylabel("y")
plt.show

※いつもわかんないんだけど、画像ってどうやって中央に配置できるの??
分類問題の最も単純なアプローチは線形判別だと思います。
線形モデルは、出力 $y$ が入力 $x$ に対して線形(このままだと、$y(x) = \beta_0 + \beta_1 x$)で、$y$ は実数値になってしまうため、分類問題に適応させるためにもう1ステップ手を加えてあげます。
例えば、線形関数を非線形関数 $f(・)$ によって変換してあげたりします。
y(x) = f(\beta_0 + \beta_1 x)
※機械学習の分野では $f(・)$ は活性化関数と呼ばれています。
例えば今回の場合、次のような活性化関数が考えられます。
f(z) = \left\{
\begin{array}{ll}
1 & (z \geq 0.5) \\
0 & (z \lt 0.5)
\end{array}
\right.
さて、今回はこの活性化関数を使って予測を行います。
まずは線形モデルの学習を行います。パラメータの推定には最小二乗法を使うことにします。
※今回のコードはPythonで書いていますが、基本的に機械学習のエッセンス(加藤)を参考にしています。
余談ではありますが、この本は機械学習を始める第一歩としてとてもお勧めです。
機械学習の勉強を始めるのに最低限必要な数学から説明されています。このタイプの本はちょっと類書を知らないですね。かなりの良書です。
また、コードがとても読みやすいです。実践ではライブラリを使うと思うのですが、勉強のために一から自分で書いてみるという面では最適かなと思います。
もともとのコードはサポートページに公開されています。
import matplotlib.pyplot as plt
import numpy as np
def reg(x,y):
n = len(x)
a = ((np.dot(x,y) - y.sum() * x.sum() / n) /
((x**2).sum() - x.sum()**2 / n))
b = (y.sum() - a * x.sum()) / n
return a,b
x = np.array(x)
y = np.array(y)
a, b = reg(x,y)
print('y =', b,'+', a, 'x')
fig = plt.scatter(x, y)
xmax = x.max()
plt.plot([0, xmax], [b, a * xmax + b])
plt.axhline(0.5, ls = "--", color = "r")
plt.axhline(0, linewidth = 1, ls = "--", color = "black")
plt.axhline(1, linewidth = 1, ls = "--", color = "black")
plt.xlabel("x")
plt.ylabel("y")
plt.show
推定されたモデルは
$\hat{y} = -0.206 + 0.07x$
となりました。
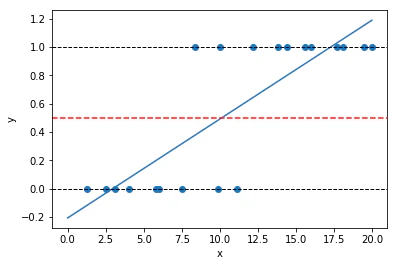
次にさっき定めた活性化関数によって変換することを考えると、境界線はだいたい $x=10$ ぐらいということになるようです。
さて、この方法には多少の問題点があります。最小二乗法は条件付確率分布に正規分布を仮定した場合の最尤法と等価です。
一方、今回のような2値目的変数ベクトルは、明らかに正規分布からかけ離れているためいろいろな問題を起こします。詳細は"パターン認識と機械学習 上(Bishop)"を参照してほしいのですが、主に
・クラス事後確率ベクトルの近似精度が悪い。
・線形モデルの柔軟性が低い。
⇒ これら2つによって確率の値が $[0,1]$ を超えてしまう。
・正しすぎる予測にペナルティを課してしまう。
があげられます。そこで適切な確率モデルを採用し、最小二乗法よりも良い特性を持つ分類アルゴリズムを考えます。
ロジスティック分布
ロジスティック回帰に入る前に、ロジスティック分布について色々考えておきます。入力ベクトル $x$ が与えられた下でのクラス $C_1$ の条件付確率は
\begin{eqnarray}
P(y=1|x)&=&\frac{P(x|y=1)P(y=1)}{P(x|y=1)P(y=1)+P(x|y=0)P(y=0)}\\
\\
&=&\frac{1}{1+\frac{P(x|y=0)P(y=0)}{P(x|y=1)P(y=1)}}\\
\\
&=&\frac{1}{1+e^{-\log\frac{P(x|y=1)P(y=1)}{P(x|y=0)P(y=0)}}}\\
\end{eqnarray}
$\log\frac{P(x|y=1)P(y=1)}{P(x|y=0)P(y=0)}=a$ とおくと、
P(y=1|x)=\frac{1}{1+e^{-a}}\\
となる。これをロジスティック分布といい、$\sigma(a)$ で表すことにします。
分布関数の形は以下のようになります。
import numpy as np
from matplotlib import pyplot as plt
a = np.arange(-8., 8., 0.001)
y = 1 / (1+np.exp(-a))
plt.plot(a, y)
plt.axhline(0, linewidth = 1, ls = "--", color = "black")
plt.axhline(1, linewidth = 1, ls = "--", color = "black")
plt.xlabel("a")
plt.ylabel("σ (a)")
plt.show()

値域が$(0,1)$におさまっていることがわかります。
ロジスティック分布の平均と分散
上記のようにロジスティック分布の分布関数は、
\sigma(x)=\frac{1}{1+e^{-x}}
で表されます。確率密度関数 $f(x)$ は、$\sigma(x)$ を微分して、
\begin{eqnarray}
f(x)&=&\frac{d}{dx}\frac{1}{1+e^{-x}}\\
\\
&=&\frac{e^{-x}}{(1+e^{-x})^2}
\end{eqnarray}
となります。確率密度関数の形は以下のようになります。
import numpy as np
from matplotlib import pyplot as plt
x = np.arange(-8., 8., 0.001)
y = np.exp(-x) / ((1+np.exp(-x))**2)
plt.plot(x, y)
plt.xlabel("x")
plt.ylabel("f (x)")
plt.show()

分布が与えられたら平均と分散も知りたくなるのが人というもの。早速計算してみます。積率母関数$M(t)$は、
M(t) = \int_{-\infty}^{\infty}e^{tx}\frac{e^{-x}}{(1+e^{-x})^2}dx
$\frac{1}{(1+e^{-x})}=y$ と置換することで、
\begin{eqnarray}
M(t) &=& \int_{0}^{1}e^{-t\log(\frac{1}{y}-1)}dy\\
\\
&=& \int_{0}^{1}(\frac{1}{y}-1)^{-t}dy\\
\\
&=& \int_{0}^{1}(\frac{1-y}{y})^{-t}dy\\
\\
&=& \int_{0}^{1}(\frac{1}{y})^{-t}(1-y)^{-t}dy\\
\\
&=& \int_{0}^{1}y^t(1-y)^{-t}dy\\
\\
&=& \int_{0}^{1}y^{(t+1)-1}(1-y)^{(-t+1)-1}dy\\
\\
&=& Beta(t+1,1-t)\\
\\
&=& \frac{\Gamma(t+1)\Gamma(1-t)}{\Gamma((t+1)+(1-t))}\\
\\
&=& \frac{\Gamma(t+1)\Gamma(1-t)}{\Gamma(2)}=\Gamma(t+1)\Gamma(1-t)
\end{eqnarray}
(しんど...!)
さらに微分と積分の順序交換を認めれば(証明はしませんが順序交換可能です。)この積率母関数の1階微分は
\begin{eqnarray}
\frac{dM(t)}{dt}=\Gamma'(t+1)\Gamma(1-t)-\Gamma(t+1)\Gamma'(1-t)
\end{eqnarray}
であり、$t=0$ とすると、
\begin{eqnarray}
M'(0)=\Gamma'(1)\Gamma(1)-\Gamma(1)\Gamma'(1)=0
\end{eqnarray}
つまり、$E[X]=M'(0)=0$ です。次に $E[X^2]$ を求めます。
\begin{eqnarray}
\frac{d^2M(t)}{dt^2}&=&\Gamma''(t+1)\Gamma(1-t)-\Gamma'(t+1)\Gamma'(1-t)-\Gamma'(t+1)\Gamma'(1-t)+\Gamma'(t+1)\Gamma''(1-t)\\
\\
&=& \Gamma''(t+1)\Gamma(1-t)-2\Gamma'(t+1)\Gamma'(1-t)+\Gamma(t+1)\Gamma''(1-t)
\end{eqnarray}
$t=0$ とすると、
\begin{eqnarray}
M''(0)&=&\Gamma''(1)-2\Gamma'(1)^2+\Gamma''(1)\\
\\
&=& 2\Gamma''(1)-2\Gamma'(1)^2
\end{eqnarray}
ここで、$\psi(x)=\frac{d}{dx}\log\Gamma(x)=\frac{\Gamma'(x)}{\Gamma(x)}$ と置き、これを微分すると
\begin{eqnarray}
\frac{d}{dx}\psi(x)=\frac{\Gamma''(x)\Gamma(x)-\Gamma'(x)^2}{\Gamma(x)^2}
\end{eqnarray}
つまり、$\psi’(1)=\Gamma''(1)-\Gamma'(1)^2$ です。ところで、$\psi’(1)=\zeta(2)$ ということらしい1ので、$\psi’(1)=\frac{\pi^2}{6}$ と求まります。
従って、$M''(0)=2×\frac{\pi^2}{6}$ となり、$E[X^2]=M''(0)=\frac{\pi^2}{3}$と求めることができました。これより、
\begin{eqnarray}
V[X]&=&E[X^2]-E[X]^2\\
\\
&=& \frac{\pi^2}{3} - 0\\
\\
&=& \frac{\pi^2}{3}
\end{eqnarray}
となり、ロジスティック分布の期待値は $0$、分散は$\frac{\pi^2}{3}$ ということがわかりました。
ちなみにガンマ関数の対数をとったものの導関数をポリガンマ関数というらしいです。特に1階導関数のことはディガンマ関数というらしいです。
(しんどかったし、突然 $ζ$ 関数出てきてよくわからなかったから、計算できたとは言えないだろうな。。。)
ロジスティック回帰
さて、次にロジスティック分布のパラメータが線形結合であらわされる場合 $p = \sigma(\beta x)$ を考えます。これを $ \beta x$ について解くと、
\begin{eqnarray}
p &=& \frac{1}{1+e^{-\beta x}}\\
\\
(1+e^{-\beta x})p &=& 1\\
\\
p+e^{-\beta x}p &=& 1\\
\\
e^{-\beta x} &=& \frac{1-p}{p}\\
\\
-\beta x &=& \log\frac{1-p}{p}\\
\\
\beta x &=& \log\frac{p}{1-p}\\
\\
\end{eqnarray}
(イコールの位置を揃えてるのですが、なんかちょっと見にくいですね。。。)
右辺は統計学の分野で対数オッズと呼ばれています。
何が言いたいのかというと、逆に言えば対数オッズを線形回帰し、$p$ について解いてあげれば各クラスに割り当てられる確率の推定値が得られるということです。
ちなみに、$ p \in [0,1]$ に対して、オッズは $ \frac{p}{1-p} \in [0,\infty)$であり、対数オッズは $ \log\frac{p}{1-p} \in (-\infty,\infty)$ であるので、対数オッズの値域と線形関数の値域と同じということもわかります。
ロジスティック回帰のパラメータ推定
何が何だか分からなくなりそうなので、文字や記号を整理しておきます。
データ集合 $D = \{ X,Y \} ,$
Y = \left(
\begin{array}{c}
y_1\\
\vdots\\
y_n
\end{array}
\right),\quad y_i \in \{ 0,1 \},(i=1,...n)
$X$ については、パラメータに定数項も入れて考えたいのですが、表記を変えるのが面倒なので、
X = \left(
\begin{array}{cccc}
1 & x_{11} & \cdots & x_{1d}\\\
\vdots & \vdots & \ddots & \vdots \\\
1 & x_{n1} & \cdots & x_{nd}
\end{array}
\right)
ということにしたいと思います。また、$i = 1,...,n$ に対して、$ x_i = (1,x_{i1},...,x_{id})^T$とします(つまり $x_i$ は $X$ の行成分を転置したもの))。
パラメータベクトル $\beta = (\beta_0,\beta_1,...,\beta_d)$ に対して尤度関数は、
L(\beta) = P(Y | \beta)= \prod_{i=1}^{n} \sigma(\beta x_i)^{y_i}\{1-\sigma(\beta x_i)\}^{1-y_i}
と書くことができ、対数尤度関数は、
E(\beta)=-\log L(\beta)= -\sum_{i=1}^{n}\{y_i\log \sigma(\beta x_i)+(1-y_i)\log(1-\sigma(\beta x_i))\}
と書くことができます。この最小化問題を解くことによってパラメータ $\beta$ を求めます。
なのですが、これは $\sigma$ の非線形性により、最尤解を解析的に導出することができません。
しかし、 $E$ は凸関数なので唯一の最小解を持ちます。この最小解をニュートン法によって求めます。
ニュートン法
ニュートン法はニュートン・ラフソン法ともいいます。ニュートン法については、私がメモを作らなくてもGoogle先生に聞けばたくさん教えてくれるので説明はそちらに譲ります。早い話が方程式の解を数値計算によって求める方法です。
手元にある書籍では、
・機械学習のエッセンス(加藤)のP247
・パターン認識と機械学習 上(Bishop)のP207
・統計的学習の基礎(Hastie)のP140
・解いてわかるガロア理論(藤田)のP74
等に説明があります。
力尽きた。
ロジスティク分布の平均と分散を計算するだけでこんなにも苦労すると思わなかったです。力尽きました。
★参考文献★
[1]加藤:機械学習のエッセンス(2018)
[2]Hastie,Tibshirani,Friedman:統計的学習の基礎(2014)
[3]Bishop:パターン認識と機械学習 上(2006)
[4]藤田:解いてわかるガロア理論(2013)
-
調べると色々出てきますが、講義資料などpdf直リンクが多いのでwikipediaのリンクを張っています。 ↩