この記事は一休.com Advent Calendar 2023第5日目の記事です。
この記事でやること
先月、ついにStability AIさんからJapanese Stable CLIPが発表された。
日本語に対応したCLIPで、しかも商用利用可。実際に試してみて、その実力を調べることにする。
CLIPとは
CLIP (Contrastive Language-Image Pre-Training)は、OpenAIによって開発された深層学習モデルで、以下の論文で発表されました。
出典:Learning Transferable Visual Models From Natural Language Supervision - Figure 1
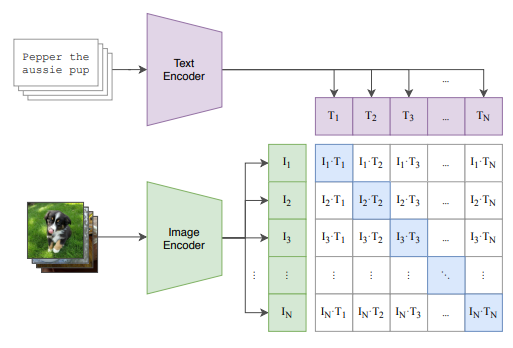
テキストと画像を同じ特徴空間上で表現するように設計されたモデルで、DALL-Eやstable diffusionなどの画像生成AIにも使われている。
↑で、「 テキストと画像を同じ特徴空間上で表現するように設計された」と、さらっと書いたがこれがめちゃくちゃ凄いことで、つまり今までは画像とテキストには何の関係もなかったのが、このCLIPによって同じ特徴空間で表現できるようになった。
今のAIはもう言葉と画像を等価的に扱うのだ。
Japanese Stable CLIP
先月、Stability AIさんから発表されたJapanese Stable CLIPは、日本語対応のCLIPである。多くのCLIPは英語で学習されているので、日本語だと十分な性能が出ないということがよくある。
しかし、このCLIPは現時点で、日本語CLIPの中で最も高い性能を出していて、そしてオープンソースで使えるようになっているのだ。これは自分のような趣味でAIをやっている人間にとって非常にありがたい。
今回、いい機会なので実際に使ってみて、業務にも応用できないか調査することにした。
実際に使ってみる
それではさっそくCLIPを使ってみよう。
以下にコードを示す。基本的にはJapanese Stable CLIPのページに書かれているUsageのコードをほぼそのまま使用している。ログインや画像読み込みの所を一部修正しているのと、わかりにくそうなところにコメントを追加した。
実行環境
- Google ColaboratoryのT4 GPU
- あらかじめ判定したい画像をアップロードしておく。
使用したコード
# 必要なものをインストール
!pip install ftfy pillow transformers torch sentencepiece protobuf
# CLIPを使うため、huggingfaceにログイン
!huggingface-cli login
from typing import Union, List
import ftfy, html, re
from PIL import Image
import torch
from transformers import AutoModel, AutoTokenizer, AutoImageProcessor, BatchFeature
# テキスト整形
def basic_clean(text):
text = ftfy.fix_text(text)
text = html.unescape(html.unescape(text))
return text.strip()
def whitespace_clean(text):
text = re.sub(r"\s+", " ", text)
text = text.strip()
return text
# トークナイザーを実行する関数
def tokenize(
tokenizer,
texts: Union[str, List[str]],
max_seq_len: int = 77,
):
"""
This is a function that have the original clip's code has.
https://github.com/openai/CLIP/blob/main/clip/clip.py#L195
"""
if isinstance(texts, str):
texts = [texts]
texts = [whitespace_clean(basic_clean(text)) for text in texts]
# トークナイザーでテキストをトークン化する
inputs = tokenizer(
texts,
max_length=max_seq_len - 1,
padding="max_length",
truncation=True,
add_special_tokens=False,
)
# BOSトークンを追加。attention maskもそのため修正
input_ids = [[tokenizer.bos_token_id] + ids for ids in inputs["input_ids"]]
attention_mask = [[1] + am for am in inputs["attention_mask"]]
position_ids = [list(range(0, len(input_ids[0])))] * len(texts)
return BatchFeature(
{
"input_ids": torch.tensor(input_ids, dtype=torch.long),
"attention_mask": torch.tensor(attention_mask, dtype=torch.long),
"position_ids": torch.tensor(position_ids, dtype=torch.long),
}
)
device = "cuda" if torch.cuda.is_available() else "cpu"
model_path = "stabilityai/japanese-stable-clip-vit-l-16"
# モデルとトークナイザーとプロセッサーを準備
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_path)
processor = AutoImageProcessor.from_pretrained(model_path)
# 画像を読み込む
image = Image.open("IMG_1853.jpg")
image = processor(images=image, return_tensors="pt").to(device)
text = tokenize(
tokenizer=tokenizer,
texts=[ "新幹線の窓から見える富士山","ヘリコプターの窓から見える富士山","扉越しに見える富士山"],
).to(device)
# 画像とテキストの特徴量を取得し、類似度を算出
with torch.no_grad():
image_features = model.get_image_features(**image)
text_features = model.get_text_features(**text)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs)
このコードでやりたいことは以下の最後の部分である。
image_features = model.get_image_features(**image)
text_features = model.get_text_features(**text)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
CLIP modelで画像とテキストの特徴を抽出して、類似度を求めてどのテキストが一番画像を表しているのかを算出している。
今回判定する画像は以下。

なんの変哲もない富士山の写真である。
しかし重要なポイントは、富士山は富士山でも新幹線の車内から撮っている ということだ。AI君はこの構造を理解することができるのか。
用意するテキストは次の3つ。
texts=[ "新幹線の窓から見える富士山","ヘリコプターの窓から見える富士山","扉から見える富士山"],
このテキストの中からどれが一番画像を表しているのか。それを判定するのがCLIPである。
そして実際にこれを実行して出て来た結果が以下となる。
[1., 0., 0.]
配列の順番がテキストの順番と対応している。よってこれは1つ目の"新幹線の窓から見える富士山"と判定されたということ。
ヘリコプターの窓と間違うかもしれないと思ったが、正しく選ばれてよかった。やはりヘリコプターからだと富士山の映り方が違うので選ばれていないのだろうか?とにかくこの結果はすごい。
他にもいろいろテキストを試してみたが、どれも正解しているのでちゃんと判定していると思われる。
texts=[ "扉","窓","すりガラス"],
→ [0., 1., 0.]
→ 窓
texts=[ "1台のトラック","たくさんの軽自動車","たくさんのトラック"]
→ [0., 0., 1.]
→ たくさんのトラック
#検証結果
この時点で、かなりの精度で判定できていることが分かっただろう。今にも何かに使えそうな実用性がある。
結論は出た。だが、このまま終わるのももったいないほどの面白さなので、業務にさらに近いことも試してみよう。
外観画像によるホテル検索
ユーザーが泊まりたいホテルをフリーワードで入力して、それっぽいものが出てくるということをやりたい。
普通、こういうことをする場合は、ホテルにキーワードをタグ付けして、それを検索で絞り込むということをやる必要がある。しかし、CLIPを使えばまた違ったアプローチでこれを実現することができるのだ。
つまり、ユーザーの検索したフリーワードに対して、どのホテル外観がそれを表しているのか、直接、判定するのだ。
実際にやるのが分かりやすい。
まず、ホテル外観の写真を用意する。実物の写真は権利の問題とかがあり手間がかかるので、今回はDALL-Eに作ってもらった。
用意したホテル
1.日本の山奥にある洋風のホテル

2.オーシャンビューのある洋風のホテル

3.日本の山奥にある和風のホテル

どれもいかにもそれっぽいだろう。それっぽいことをさせるのにAIはとてもやくにたつ。
そしてそれぞれの画像を以下のテキストで判定したところ、全て望み通りの結果が返って来た。
texts=[ "日本の山奥にある洋風のホテル","オーシャンビューのある洋風のホテル","日本の山奥にある和風のホテル"]
-
1の画像を判定した結果
→ 日本の山奥にある洋風のホテル -
2の画像を判定した結果
→ オーシャンビューのある洋風のホテル -
3の画像を判定した結果
→ 日本の山奥にある和風のホテル
このようにCLIPを使えば、ユーザーは外観の画像から行きたいホテルを選ぶことができるのだ。
もう少し難しいことも聞いてみよう。
先ほどの2の画像「オーシャンビューのある洋風のホテル」を使って、さらに細かく質問してみる。
以下に、実際にユーザーの興味がありそうなテキストを用意した。
texts=[ "海の見えるミニマルなリゾートホテル","海の見えるプール付きの高級ホテル","海の見える老舗のホテル"]
すると結果は、「海の見えるプール付きの高級ホテル」だった。
画像のホテルはプール付きだし、明らかにいい値段がするだろう。当然ミニマルでもないし、老舗の感じもない。
ついでなので、次の画像に切り替えて判定してみたところ、

結果は「海の見える老舗のホテル」となった。完璧だ。
また最後に、富士山の検証で、気になっていたのでDALL-Eにヘリから見た富士山を描いてもらって判定してみた。

すると結果は当たり前のように「ヘリコプターの窓から見える富士山」となった。
やっぱコイツ強ぇわ。もうダメだ。
おわり