ローコード開発のリファクタリング Power Automate 編
- ローコード・ノーコード開発の需要と展望
- 【PowerPlatform】ローコード開発のリファクタリング Power Apps 編
- 【PowerPlatform】ローコード開発のリファクタリング Power Automate 編
🏗️ はじめに
Power Automate で作成されたフローは、構造がフローチャート的になっていることもあり、設計書などの詳細な文書化が省略されてしまうような背景があります。しかし、作成者以外が引き継ぐ際には、内部処理や設計意図を正確に把握するのが難しいです。誰もがスムーズに管理・修正できる状態を維持するためには、一般的なソフトウェア開発と同様に、ローコード開発でもリファクタリングが重要です。
👀 目的
本記事の目的は、Power Automate のフローをリファクタリングすることで、作成者以外の担当者も容易にフローの意図や処理内容を理解でき、適切に管理・修正できる環境を整えることにあります。こうした取り組みは、日々の運用におけるトラブルシューティングを迅速化し、チーム全体での開発効率向上にも寄与します。特に、リファクタリングの効果は「可読性の向上」と「メンテナンス性の強化」という二つの側面から実現されるため、以下で具体的な手法を詳しく解説していきます。
- 可読性の向上:アクション名の明確化やメモ機能の活用により、各アクションがどのような処理を実施しているかを一目で把握できる設計を目指します。
- メンテナンス性の強化:スコープの利用やトリガーの分割により、フロー全体の管理や後続の修正を容易にする工夫を解説します。
整理という名目でフローに高度な処理や複雑なロジックを詰め込みすぎると、引き継いだ担当者が同等の知識を持っていなければ修正が難しくなるリスクがあります。このため、シンプルさと拡張性のバランスを常に意識する必要があります。
また、フロー作成者は一人で頑張るのではなく、普段から周囲と学んだ技術や知見を共有し、チーム全体でフローの管理や改善に取り組んでいく体制を構築することが理想です。
🏷️ フロー名と説明の適切な設定
フローの管理性や保守性を高めるためには、命名規則の整備と説明文の記載が不可欠です。
自動生成された名前のままでは、後から目的や処理内容を把握しづらくなり、運用上のリスクにつながります。
📝 命名規則を決めておく
Power Automate では、フロー作成時に自動で名前が付けられます。しかしそのままでは処理内容が分かりづらく、後からの検索や保守が困難になります。
業務名・処理内容・対象システムなどを含めた命名ルールを事前に定めておくことで、以下のようなメリットがあります。
- 一覧画面で目的がすぐに分かる
- 他のメンバーが検索しやすくなる
- 保守・改修時の混乱を防げる
例:
請求書_月次送信処理_SharePoint、営業部_リード登録_Salesforce
🗒️ フローの説明文を活用する
フロー名だけでは処理の内容や目的が十分に伝わらないことがあります。
フローの「説明」欄に、処理の概要や設計意図を簡潔に記載しておくことで、他の利用者や保守担当者が内容を把握しやすくなります。
記載しておくとよい情報の例:
- フローの目的(何のための処理か)
- トリガー条件(いつ・どのように実行されるか)
- 外部サービスとの連携や依存関係
- 注意点や前提条件(例:特定のリストが存在すること)
💡 例:
「毎朝 8 時に SharePoint のリストを確認し、期限切れのタスクを Teams に通知する処理です」
🔍 可読性とメンテナンス性の向上
Power Automate のフローは視覚的に構築できるため、そのまま運用されることが多く、設計意図や処理内容が曖昧になりがちです。可読性が低いフローは処理の流れを把握しづらく、メンテナンス性が悪いと変更時の影響を予測するのが難しくなります。
この章では、フローの可読性を高め、後から見直しや修正をしやすくするためのリファクタリング手法を解説します。
📌 アクションの整理
Power Automate のアクションにはデフォルトで設定される名称がありますが、そのまま使用すると処理の内容が直感的に分かりづらくなります。特に、同じ種類のアクションが複数並んでいる場合、何をしているのかが明確でないと、フローの理解や引き継ぎが困難になります。そこで、フローの可読性を向上させるためにアクションを整理する例を以下に記します。
アクション名の変更
適切なアクション名を付けることで、処理の流れを明確にし、可読性を向上させることができます。
元のアクション名を残しつつ、処理の内容を要約する ことで、後から見直した際に意図をすぐに理解できるようになります。

- 「作成」 → 「作成:ユーザー名」
- 「変数を初期化する」 → 「変数を初期化する:検索条件」
- 「項目の取得」 → 「項目の取得:ユーザーデータ」
- 「メール送信」 → 「メール送信:通知用」
- 「アレイのフィルター処理」 → 「アレイのフィルター処理:特定条件の抽出」
このように、元のアクション名を保持しながら、そのアクションが何をするのかを記述することで、後からフローを見直した際の理解をスムーズにできます。
メモの追加
アクション名を変更しても、細かい処理の背景や実装意図は分かりにくい場合があります。そのため、[メモを追加する] 機能 を利用して、アクションごとに補足説明を記述することが有効です。

- 「この処理では、SharePoint リストから特定の条件に合致するデータを取得する」
- 「フィルターアレイでは、条件として「ステータス = 有効」を設定している」
- 「メール送信アクションでは、Cc に特定の管理者を追加している」
こうしたメモを残すことで、フローの設計意図を正確に伝えることができ、引き継ぎ時の負担を減らすことができます。
不要なアクションの削除
フローをコピーして作成する際、使用していないアクションが残ってしまうことがあります。これらを整理せずに放置すると、フローの可読性が低下し、引き継ぎ時の理解が難しくなります。
設計を見直し、不要なアクションを適切に削除することで、フローを簡潔に保ち、管理しやすくできます。コピー元のフローの残りや、現在の処理には不要なアクションを見極め、整理することが重要です。
💡 Tips:
フロー名・説明・アクション名などをきっちり整理しておくと、Power Automate の Copilot による処理の要約がより的確になります。Copilot に「このフローの内容を説明してください。」と尋ねると、構造が整ったフローほど分かりやすく説明してくれます。
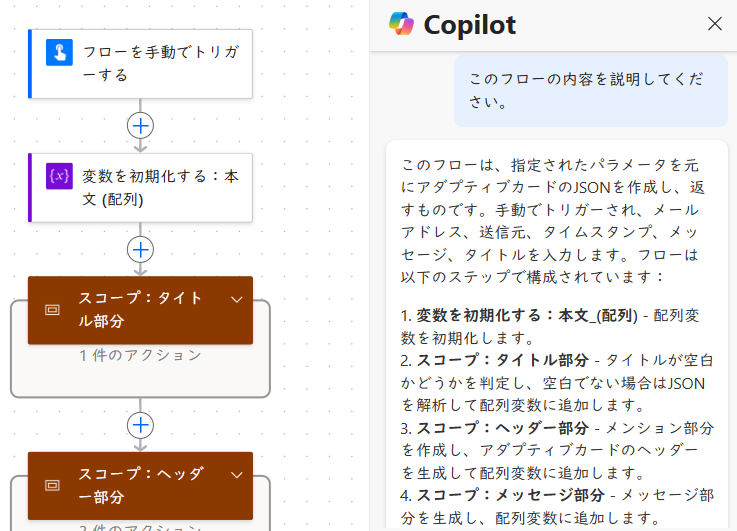
そのまま設計書に転記できるレベルの説明が得られるため、初期設計の段階から意識しておくと効果的です。
📌 スコープの活用
Power Automate のフローでは、多くのアクションを組み合わせて処理を実行しますが、何も整理せずにそのまま追加すると、フローが煩雑になり、管理や修正が困難になります。そこで、スコープを活用して関連するアクションをまとめる ことで、フローを整理し、可読性とメンテナンス性を向上させることが重要です。
スコープを活用するメリット
スコープは、関連するアクションをひとまとまりにするための Power Automate の機能です。適切に活用することで、以下のメリットがあります。
-
処理の塊を論理的に整理できる
例えば、「データ取得」「データ処理」「通知」などの処理単位でスコープを作成すると、フロー全体の構造が明確になります。

-
エラーハンドリングの適用範囲を明確にできる
スコープごとに「失敗時の処理」を設定することで、例外処理を簡潔に記述できます。
例:スコープ内の何れかのアクションでエラーが発生した際にメッセージ通知する

-
フローの視認性が向上する
関連する処理がまとまることで、フローの流れが分かりやすくなり、修正や変更が容易になります。
スコープの具体的な活用方法
スコープを導入する際には、以下のポイントを意識すると、整理がしやすくなります。
-
処理単位でスコープを分ける
例えば、「スコープ:データ取得」「スコープ:データ処理」「スコープ:通知」のように、機能ごとに整理すると管理がしやすくなります。 -
スコープの名称を明確にする
「スコープ:処理」などの曖昧な名前ではなく、「スコープ:注文データ取得」「スコープ:在庫情報更新」 のように、スコープの役割が明確になる名称を設定します。
スコープを適切に活用することで、フローの可読性が向上し、修正やメンテナンス作業の負担を軽減できます。
📌 条件文をネストしないようにする
条件分岐を深くネストすると、可読性が低下し、後から修正やトラブルシューティングが困難になります。
適切な構造を採用し、シンプルな条件分岐を心がけることで、フローを見直しやすくなります。
スイッチアクションを活用する
複数の条件を評価する場合、通常の「条件」アクションを使ってネストするのではなく、スイッチアクション を活用すると、個別の条件をスムーズに管理できます。
例えば、ユーザーのステータスに応じて処理を分岐する場合:
- 「新規ユーザー」には登録確認メールを送信
- 「アクティブユーザー」には定期通知を送信
- 「非アクティブユーザー」にはフォローアップ通知を送信
このように、スイッチアクションを活用することで、それぞれの分岐を独立した処理として管理しやすくなります。
条件文でフローを終了させる
特定の 条件を満たした場合に処理をする のではなく、条件を逆転させ、条件を満たしていない場合は後続の処理をせずにフローを終了させる という設計にします。

この方法により、フローの構成が明確になり、不要な処理を省略できるため、全体の可読性とメンテナンス性が向上します。
条件分岐が多岐にわたる場合はフロー自体を分ける
条件分岐が増えて処理が複雑になりすぎる場合、一つのフローにまとめるのではなく、それぞれの条件で起動する専用フローを設ける ことで、フローを分かりやすくできます。
例えば:
- 「注文処理フロー」
- 「在庫確認フロー」
- 「配送手配フロー」
このように個別フローに分けることで、全体の見通しが良くなり、変更が容易になります。
こうしたフローの整理の考え方は、一つのトリガーで長い処理を作らないようにする というアプローチにもつながります。
📌 フローを分ける
一つのトリガーで長い処理を作らない
例えば、「テーブルの値を更新したらメールで通知する」という処理を、以下のように分割できます。
- 「テーブルの値を更新する」フロー
- 「テーブルが更新されたことをトリガーにメールを送信する」フロー
このように、トリガーごとに処理を分割することで、影響範囲を限定し、メンテナンスをしやすくできます。
🚀 変数とデータ処理の最適化
Power Automate では、変数やデータ処理の設計が適切でないと、フローの管理が煩雑になります。
この章では、変数の適切な定義と活用、効率的なデータ処理の手法 について解説します。
📌 変数の定義に [作成] アクションを使う
Power Automate のフローで変数を扱う際、通常は [変数を初期化する] → [変数の設定] という手順で値を変更します。 ただし、[変数を初期化する] アクションは スコープや条件文、反復処理の中では使用できない という制約があります。そのため、スコープ外で事前に定義する必要があります。
「データ操作」の [作成] アクションを活用し、変数のように使用する と、事前の定義なしで値を設定 できるため、より柔軟な管理が可能になります。
[作成] アクションをローカル変数として使うメリット
-
スコープ、条件分岐やループ内で使用できる
[作成] アクションは制約が少ないため、ループ内や条件分岐の中でも使用でき、使用範囲を明確にすることで、不要な変数の管理を減らすことができます。※スコープの外でも参照することはできます。
使用時の注意点
-
型が厳密に指定できない
[作成] アクションはデータ型の指定がないため、文字列、数値、オブジェクトなど、意図しない値を保持する可能性があります。
厳密な型管理が必要な場合は、[変数を初期化する] アクションを使用する方が適切 です。
変数を使うべきケース
[作成] アクションはスコープ内でも使えますが、変数として管理する場合は、[変数を初期化する] アクションを使ったほうが適切なケースがあります。
-
データの型を厳密に管理する必要がある場合:
[作成] アクションでは型の指定ができず、文字列・数値・オブジェクトが混在する可能性があります。一方で、[変数を初期化する] アクションを使用すれば、明確な型を定義できるため、データの一貫性を保ちやすくなります。 -
反復処理の中で値を保持して更新したい場合:
反復処理の中で変数を更新したい場合 (インデックスのインクリメント等) は、[変数を初期化する] アクションで事前に定義して、反復処理内で [変数の設定] を使って値を更新します。 -
並列処理の中で値を設定・参照する場合:
並列処理では複数のアクションが同時に動作するため、[作成] アクションではデータの参照タイミングを制御できない可能性があります。このようなケースでは、[変数を初期化する] アクションを利用して、値の管理を一元化することで、安全な動作が保証されます。
📌 反復処理
自動で Apply to each が挿入されないようにアイテムを指定する
Power Automate のアクションでは、配列で値が取得できる可能性がある場合、たとえ配列のアイテムが1つであっても、ループ処理として扱われ、自動で Apply to each が挿入されてしまいます。
配列の中から 1つのアイテムしか使用しない 場合は、明示的にそのアイテムを取り出して後続の処理を行うことで、不要なループを回避できます。
「作成」アクションで配列の先頭のデータを抽出
「作成」アクションの [入力] パラメーターに以下のように設定することで、配列の先頭のアイテムのみを抽出できます。
first({配列を指定する})
例:承認者名の配列から1件目を取得する

条件を満たすまで繰り返す [Do Until] の活用
Apply to each のループ処理は、配列のアイテム数だけ処理が繰り返されますが、Do Until を使用すると、特定の条件を満たすまでループを継続することができます。 これにより、データの状態を監視しながら処理を進める ことが可能になり、不要な繰り返しを防げます。
🔄 反復処理内で変数を更新して活用
Do Until を使用する際、ループの進行状況を適切に管理するために、変数を更新しながら処理を進める ことが重要です。
例えば:
-
[変数を初期化する] アクション で初期値を設定 →
変数 = 0 -
[変数の設定] アクション で処理ごとに変数を更新 →
変数 = 変数 + 1 - [Do Until] の [ループ停止条件] に設定している変数の条件を満たしたらループを終了
このように、変数の状態を監視しながらループを制御 することで、意図したタイミングで処理を終了できます。
⏳ [遅延 (Wait)] アクションを使う
Do Until のループは、指定した条件を満たすまで継続されるため、重い処理が間隔なしに繰り返されるとシステムに負荷がかかる 可能性があります。
そのため、[遅延 (Wait)] アクションを組み合わせることで、適切な間隔を設けながら処理を進める ことで負荷を軽減できます。
Apply to each を使わないで配列を加工する
Select アクションを利用することで、配列を効率的に加工できます。
Select アクションの利用手順
-
入力配列の準備
- 配列データを用意します。例として、以下のような JSON 形式の配列を想定します。
[ {"name": "Alice", "age": 25}, {"name": "Bob", "age": 30} ]
- 配列データを用意します。例として、以下のような JSON 形式の配列を想定します。
-
Select アクションを追加
- Power Automate のフローに「選択 (Select)」アクションを追加します。
-
マッピング設定
- 「Map」セクションで、出力のキーと値を定義します。
-
Key:
fullName -
Value:
item()?['name']
-
Key:
- これにより、元の配列から新しい配列を以下の形式で生成できます。
[ {"fullName": "Alice"}, {"fullName": "Bob"} ]
- 「Map」セクションで、出力のキーと値を定義します。
このように Select アクションを活用することで、配列を一括変換 でき、不要なループ処理を回避することが可能になります。
📌 関数を使う
Power Automate のアクション内で利用できる関数を活用すると、数値や文字列の加工を簡潔に行うことができます。 関数は 「式 (Expression)」 を使用して設定でき、アクションの入力欄で $fx$ アイコンをクリックすると利用可能になります。

- アクションの入力欄を選択
- $fx$ アイコンをクリック
- 適切な関数を入力し、式を作成
- 作成した式を適用し、データ処理に組み込む
続けて、よく使われる関数をカテゴリ別に紹介します。
✂️文字列操作
文字列の加工や整形を行う際に役立つ関数です。
-
concat:文字列を結合するconcat('Hello', ' ', 'World') → "Hello World" -
substring:指定範囲の文字列を抽出するsubstring('abcdef', 2, 3) → "cde" -
replace:文字列の一部を置換するreplace('Power Automate', 'Power', 'Microsoft') → "Microsoft Automate"
🔢数値操作
数値の演算に役立つ関数です。
-
add:数値を加算するadd(5, 3) → 8 -
sub:数値を減算するsub(10, 4) → 6 -
mul:数値を乗算するmul(3, 5) → 15
📅日付操作
日付の計算やフォーマット変換に役立つ関数です。
-
addDays:指定した日数を日付に加算するaddDays('2024-01-01', 5, 'yyyy-MM-dd') → "2024-01-06" -
formatDateTime:日付のフォーマットを変更するformatDateTime('2024-01-01', 'dddd, MMMM dd, yyyy') → "Monday, January 01, 2024"
🔀条件分岐
条件を評価し、結果に応じた処理を行うための関数です。
-
if:条件に基づいて異なる値を返すif(equals(10, 10), '一致', '不一致') → "一致" -
equals:2つの値が等しいか確認するequals('A', 'A') → true
📊配列操作
配列データを効率的に処理するための関数です。
-
union:2つの配列を結合し、重複を削除するunion(['a', 'b'], ['b', 'c']) → ['a', 'b', 'c'] -
intersection:2つの配列の共通部分を取得するintersection(['a', 'b'], ['b', 'c']) → ['b']
⚠️ エラーを検知しやすいようにする
Power Automate の実行履歴を確認する際、エラーの原因を特定するためにフロー内部の処理を細かく追うのは大変です。
特に、エラーが発生する可能性が事前に分かっている箇所では、例外処理を行い、明示的に「失敗」や「キャンセル」として終了アクションを呼び出す ことで、フローを確認する際に原因をすぐに把握できるようになります。
📌 例外処理の実装
失敗を明示的に設定する
予期されるエラーが発生した際に、フロー全体のエラーではなく、特定のアクションを失敗として終了させる よう設定することで、問題箇所を特定しやすくなります。
スコープを活用した例外処理
エラーが発生する可能性のある処理を 「Try スコープ」 にまとめ、エラー発生時に 「Catch スコープ」 で失敗アクションを明示的に呼び出すことで、フローの管理がしやすくなります。
このような設計を取り入れることで、フローの実行履歴を確認した際に、どこでエラーが発生したのかをすぐに特定できる ようになります。
📂 データソースの管理
SharePoint リストの内部名を分かりやすくする
SharePoint リストをデータソースとして扱う際、列名を日本語で作成するとエンコードされ、識別が困難になります。
そのため、まず英語で列を作成して内部名を確定させ、後から日本語にリネームする 方法が推奨されます。
この手順を徹底することで、フローの設定時に適切な列名を選択しやすくなり、管理を簡素化できます。
⚙️ ソリューションを活用する
ソリューションを活用すると、フローは Dataverse で管理されるようになり、環境間での移行が容易 になり、より汎用性のあるフローを構築できます。
また、個別のフローでは難しかった 環境変数の利用や共通処理の子フロー化 が可能になります。
📌 環境変数を利用する
環境変数を利用すると、フローを別の環境にインポートしても、中の処理を直接編集せずに運用が可能 になります。
例えば、設定値を環境変数として管理すれば、フローの動作を環境ごとに適したものへ変更しやすくなります。
📌 子フローを利用して共通処理を抜き出す
ソリューション内にフローを配置すると、フローの中で別のフローを子フローとして呼び出し できるようになります。
同じ処理が複数回登場する場合、共通部分を子フローに分離することで、修正やメンテナンスを簡潔にし、単体テストを容易にする というメリットがあります。
📝 データの受け渡しに JSON を活用
子フローを活用すると、フロー間でデータを受け渡す必要があります。通常、パラメーターはトリガーで個別に追加することもできますが、この方法ではパラメーターの増減時にトリガーの設定を変更する必要があります。
JSON 形式を使うと、パラメーターの変更に柔軟に対応できるため、フローの設計をより簡潔に管理できます。
📌 JSON 形式のメリット
-
パラメーターの増減に対応しやすい
個別のパラメーター追加ではトリガーの設定を変更しなければなりませんが、JSON にまとめることで、データ構造を変更するだけで済みます。 -
データの整理が容易
JSON を活用することで、受け渡し時に一つのオブジェクトとして管理できるため、フローの設計がシンプルになります。 -
拡張性が高い
JSON に含めるデータを後から追加・変更することが可能で、フローの修正を最小限に抑えられます。
🏁 まとめ
この記事では、Power Automate のフローを引き継ぎやすく整理するためのリファクタリング手法 を解説しました。
フローの可読性を向上させ、メンテナンスしやすい構造にすることで、運用時の負担を軽減し、スムーズな引き継ぎ が可能になります。
この記事で整理したポイント
- アクションの整理(不要なアクションの削除、適切なアクション名の設定)
- データソースの管理(SharePoint の内部名を分かりやすくする)
- ソリューションの活用(環境変数の利用、子フローの活用)
- データの受け渡しの最適化(トリガーのパラメーター追加と JSON の活用)
これらを実践することで、フローの構造を明確にし、修正や拡張がしやすい設計 を実現できます。
今後のフロー作成・改善に活かしていきましょう!
🔗 参考サイト
- 【Power Automate】「式」を使えば値の計算や変換も簡単! 式の作成手順と実行結果の確認方法
- PowerAutomate: トリガー(Trigger) と アクション(Action) 関数のまとめ
📚 書籍