はじめに
AWSからAmazon S3 Vectorsのプレビューが発表されました。従来のベクトルデータベースと比較して大幅なコスト削減が期待できそうです。
今回、このS3 Vectorsを実際に触ってみてセマンティック検索システムを構築してみました。
セマンティック検索とは?簡単におさらい
キーワード検索とは違い、セマンティック検索は「意味」を理解して検索します。
従来のキーワード検索 vs セマンティック検索
【キーワード検索の場合】
検索: "犬"
結果: "犬"という文字が含まれる文書のみ
→ "ペット"や"動物"という文書は見つからない
【セマンティック検索の場合】
検索: "犬"
結果: "ペット"や"動物"、"愛犬家"なども関連文書として検出
→ 意味的に関連する内容も見つけられる
ベクトル埋め込みとコサイン類似度
セマンティック検索の核心は「ベクトル埋め込み」です。
文章 → 数値の配列(ベクトル)に変換
例:
"犬が好き" → [0.2, -0.1, 0.8, 0.3, ...] (1024個の数値)
"猫が好き" → [0.3, -0.2, 0.7, 0.4, ...] (1024個の数値)
似た意味の文章は、似た数値パターンを持ちます。この「似ている度合い」を測るのがコサイン類似度です。
# コサイン類似度の概念
# 値が1に近いほど似ている、0に近いほど似ていない
"犬が好き" と "猫が好き" → 類似度 0.85 (高い類似性)
"犬が好き" と "車の運転" → 類似度 0.12 (低い類似性)
この記事で作るもの
- マークダウン文書を自動分割してベクトル化
- Amazon S3 Vectorsに埋め込みベクトルを保存
- Streamlitでセマンティック検索UIを構築
- Amazon Titan Embeddings v2を使用した高精度な検索
完成イメージ
凝ったアプリではないです
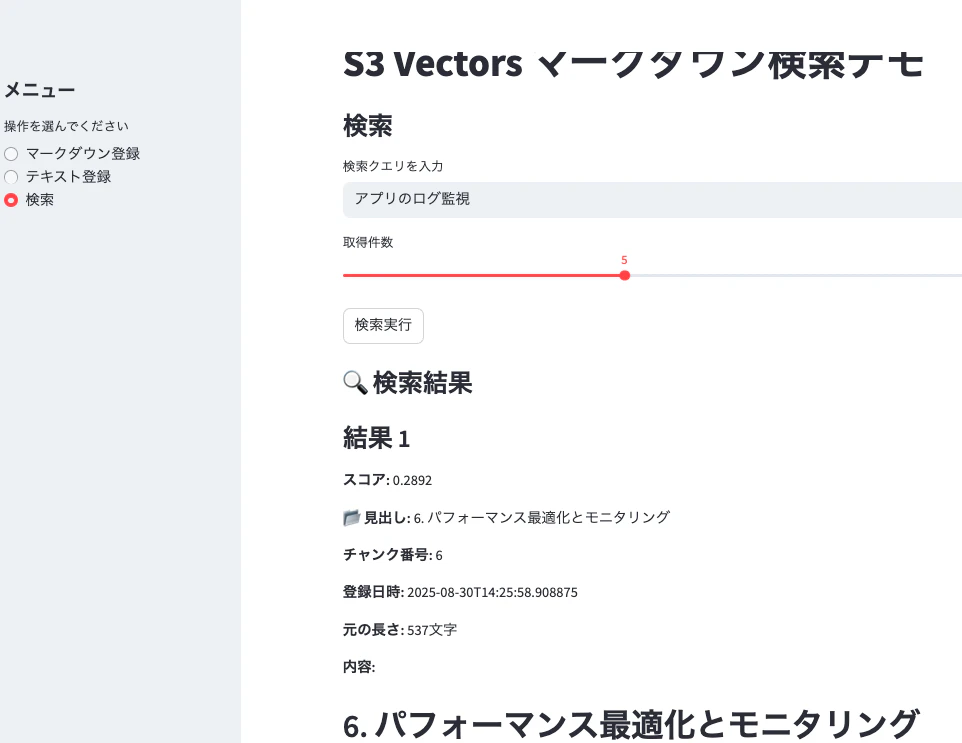
マークダウンファイルをアップロードするか、テキストを直接入力して登録。自然言語で検索クエリを入力すると、関連する文書セクションが類似度スコアと共に表示されます。
前提条件
- AWSアカウント(S3 Vectorsが利用可能なリージョン)
- AWS CLIの設定
- IAMユーザーまたはロール
セットアップ
1. 必要なライブラリをインストール
レポジトリ
git clone https://github.com/MaTTalv001/s3_vector.git
cd s3_vector
pip install -r requirements.txt
2. AWS認証情報の設定
事前に、IAMユーザーを作成しキー情報を取得しておき、aws configureでローカル環境に記録させておきます。
aws configure
# Access Key ID、Secret Access Key、リージョン(us-west-2推奨)を設定
東京リージョンは2025年8月時点では対応していません
3. IAMポリシーの設定
以下のポリシーをIAMユーザーにアタッチ:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3vectors:*",
"bedrock:InvokeModel"
],
"Resource": "*"
}
]
}
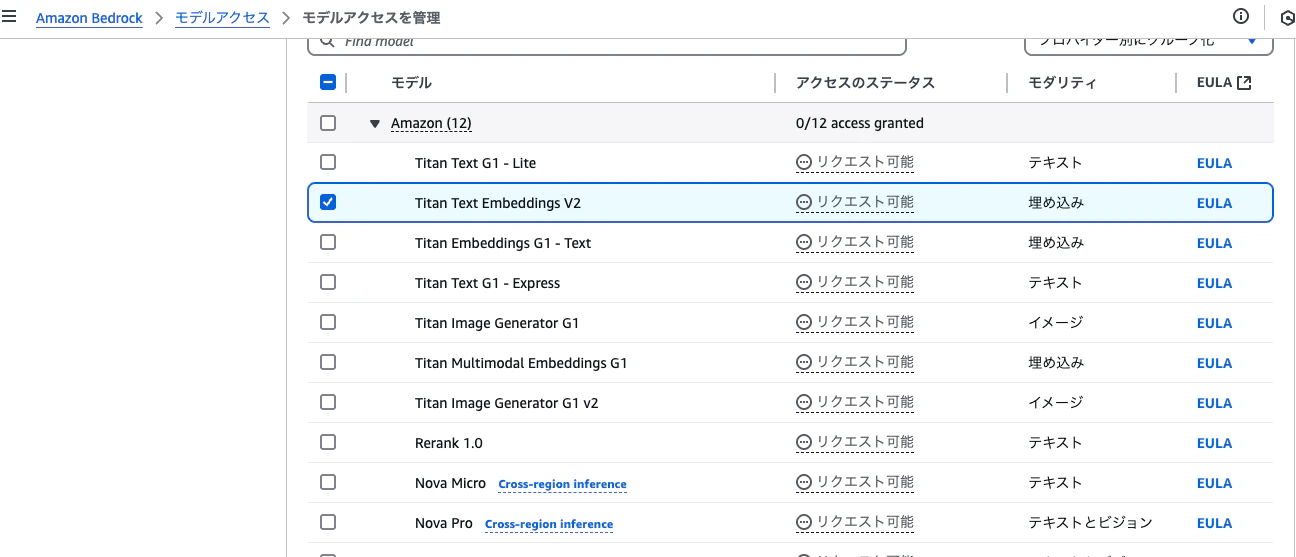
4. Amazon Bedrockモデルアクセス設定
- AWSマネジメントコンソールでAmazon Bedrockを開く
- 右上のリージョン選択からオレゴンリージョンを選択
- 左側メニューから「Model access」をクリック
- 「Request model access」をクリック
- Amazon Titan Text Embeddings V2にチェックを入れて有効化
5. S3 Vectorsバケットとインデックスの作成
マネジメントコンソールで作成するパターン:
- S3の左ペインからベクトルバケットを作成する
- ベクトルバケットを選択し、ベクトルインデックスを作成する
- ディメンションは1024とする
AWS CLIで作成するパターン:
# Vector Bucket作成
aws s3vectors create-vector-bucket \
--vector-bucket-name your-vector-bucket \
--region us-west-2
# Vector Index作成(1024次元 for Titan v2)
aws s3vectors create-index \
--vector-bucket-name your-vector-bucket \
--index-name your-vector-index \
--index-configuration '{
"algorithm": "COSINE",
"dimensions": 1024,
"metadataConfiguration": {
"metadataKeys": ["heading", "timestamp", "chunk_index", "full_length"]
}
}' \
--region us-west-2
プロジェクト構成
GitHubリポジトリから取得:
git clone https://github.com/MaTTalv001/s3_vector.git
cd s3_vector
s3_vector/
├── app.py # メインアプリケーション
├── delete_vector_bucket.py # データ削除ユーティリティ
├── vector_count.py # ベクトル数確認ユーティリティ
├── .streamlit/
│ └── secrets.toml # AWS認証・設定情報
└── secrets.toml.template # 設定テンプレート
設定ファイルの準備
.streamlit/secrets.toml を作成:
ベクトルバケット名とインデックス名をシークレットファイルに記入する
[aws]
region = "us-west-2"
bucket_name = "your-vector-bucket"
index_name = "your-vector-index"
[bedrock]
embedding_model_id = "amazon.titan-embed-text-v2:0"
機能
データの流れ:登録から検索まで
1. マークダウンチャンク分割
なぜチャンク分割が必要?
- 長い文書をそのままベクトル化すると、特定の話題が薄まってしまう
- 見出しごとに分割することで、より精密な検索が可能
def chunk_markdown_by_h2(text):
"""マークダウンテキストを ## 見出しごとにチャンク分割"""
# ## で始まる行を区切り文字として分割
chunks = re.split(r'\n(?=##\s)', text)
processed_chunks = []
for chunk in chunks:
chunk = chunk.strip()
if not chunk:
continue
# 1000文字を超える場合は段落単位でさらに分割
# 理由:メタデータの制限とベクトル精度の両立
max_chunk_size = 1000
if len(chunk) > max_chunk_size:
paragraphs = chunk.split('\n\n')
current_chunk = ""
for paragraph in paragraphs:
# 現在のチャンク + 次の段落が制限を超える場合
if len(current_chunk + paragraph) > max_chunk_size and current_chunk:
processed_chunks.append(current_chunk.strip())
current_chunk = paragraph
else:
current_chunk += "\n\n" + paragraph if current_chunk else paragraph
if current_chunk.strip():
processed_chunks.append(current_chunk.strip())
else:
processed_chunks.append(chunk)
return processed_chunks
2. Amazon Titan埋め込み生成
Amazon Titanの役割
- テキストを1024次元のベクトルに変換
- 意味的に似たテキストは似たベクトルになる
def generate_embedding(text: str):
"""Amazon Titan v2でテキストから埋め込み生成"""
response = bedrock.invoke_model(
modelId="amazon.titan-embed-text-v2:0",
body=json.dumps({"inputText": text}),
accept="application/json",
contentType="application/json"
)
# レスポンスから1024個の浮動小数点数の配列を取得
return json.loads(response["body"].read())["embedding"]
3. S3 Vectorsへのデータ保存
S3 Vectorsの構造
Vector Bucket
└── Vector Index
├── ベクトルデータ(1024次元の数値配列)
└── メタデータ(元のテキスト、見出し、タイムスタンプなど)
def upload_markdown_as_vectors(text: str):
"""マークダウンテキストを分割し、各チャンクをS3 Vectorsに登録"""
chunks = chunk_markdown_by_h2(text)
vectors = []
for i, chunk in enumerate(chunks):
# 1. テキストをベクトル化
embedding = generate_embedding(chunk)
heading = extract_heading(chunk)
# 2. メタデータ制限(2048バイト)を考慮
# AWS S3 Vectorsの制限により、メタデータは2048バイトまで
max_metadata_text = 400
truncated_text = chunk[:max_metadata_text]
if len(chunk) > max_metadata_text:
truncated_text += "..."
# 3. ベクトルデータを構築
vectors.append({
"key": f"{uuid.uuid4()}", # 一意なID
"data": {"float32": embedding}, # 1024次元のベクトル
"metadata": { # 検索結果表示用のメタデータ
"source_text": truncated_text,
"heading": heading,
"timestamp": datetime.now().isoformat(),
"chunk_index": i,
"full_length": len(chunk)
}
})
# 4. S3 Vectorsに一括保存
s3vectors.put_vectors(
vectorBucketName=BUCKET_NAME,
indexName=INDEX_NAME,
vectors=vectors
)
return len(vectors)
4. セマンティック検索の実行
検索処理の流れ
- 検索クエリをベクトル化
- 保存済みベクトルとの類似度計算(コサイン類似度)
- 類似度順でソート・結果返却
def semantic_search(query: str, top_k=5):
# 1. 検索クエリをベクトル化(登録時と同じモデルを使用)
query_embedding = generate_embedding(query)
query_vector = {"float32": query_embedding}
# 2. S3 Vectorsで類似ベクトルを検索
results = s3vectors.query_vectors(
vectorBucketName=BUCKET_NAME,
indexName=INDEX_NAME,
queryVector=query_vector,
topK=top_k,
returnDistance=True, # コサイン距離を返す
returnMetadata=True # メタデータも返す
)
# 3. 距離を類似度に変換(距離が小さいほど似ている)
for v in results["vectors"]:
v["similarity"] = 1.0 - v["distance"] # 0-1の範囲に正規化
return results["vectors"]
この実装により、「React 開発」と検索すると、「フロントエンド」や「TypeScript」を含む文書も意味的関連性で検出できるようになります。
アプリケーション実行
streamlit run app.py
ブラウザで http://localhost:8501 にアクセス。
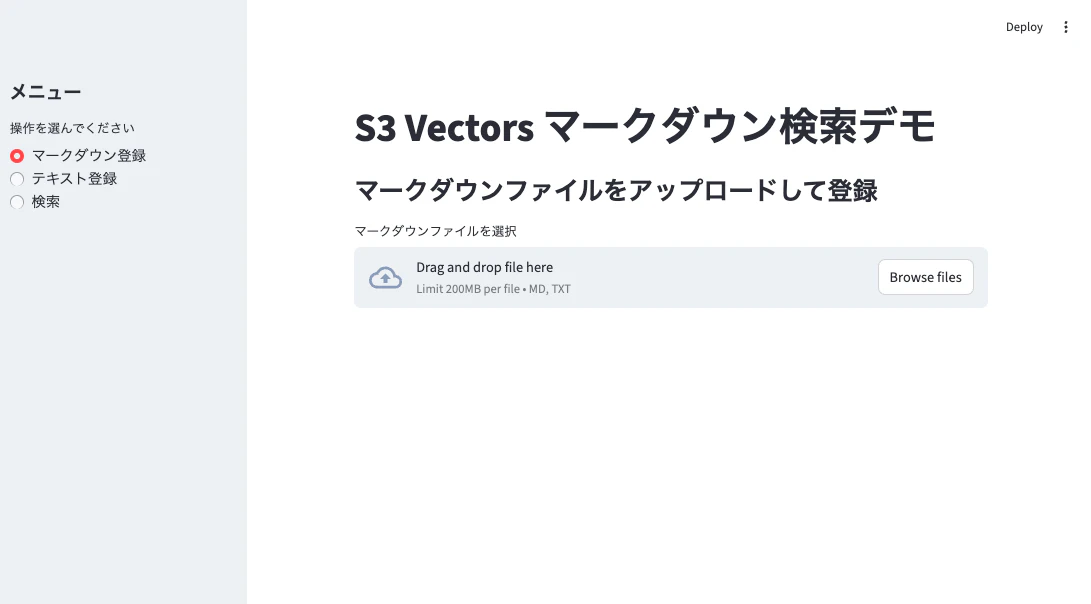
使用方法
1. マークダウン登録モード
- ファイルアップロードまたはテキスト直接入力
- 「内容をプレビュー」で分割結果を確認
- 「ベクトル登録」で埋め込み生成・保存
2. 検索モード
- 自然言語でクエリを入力
- 類似度スコア順で結果表示
- 見出し情報も含めて検索結果を表示
管理機能
ベクトル数確認
ベクトル化されている関係でデータの中身を簡単に覗けるような仕様になっていません。
OpenSearchへのExport機能があることを確認しましたが高額なので、とりあえず何個データが入っているかを確認できるようにはしました
python vector_count.py
データ完全削除
遊んだ後はバケットごと削除しておきます
python delete_vector_bucket.py
あなたの要素を反映して、より個人的な視点でのまとめに書き直します:
まとめ
Amazon S3 Vectorsを使ったセマンティック検索システムを構築してみました。実際に触ってみての感想をまとめます。
アプリケーションへの組み込み
APIの使い方は思っていた以上にシンプルで、既存のAWSサービスと同じような感覚で組み込めました。boto3でいつものようにクライアントを作成して、put_vectorsやquery_vectorsを呼ぶだけ。特に複雑な設定やライブラリは必要なく、AWSエコシステム内での統合の良さを実感できます。
S3 Vector Bucketの実態
「S3」という名前からいつものS3のように何でも気軽に放り込める感じを想像していましたが、実際は全く違いました。ベクトルデータ専用の構造化されたストレージで、次元数やメトリクス(コサイン類似度など)を事前に決める必要があり、使い方は割とガチガチに決まっていますし、基本的にはデータの中身を直接覗いたり編集したりするようなものでもないです。
コストとスケーラビリティの魅力
一番の魅力はやはりコスト面です。従来のベクトルデータベースと比較して、大量データでの運用コストが大幅に削減できる可能性が高いです。また、スケーラビリティについても心配する必要がありません。
特に企業レベルでの文書検索システムを構築する場合、このコストメリットは活きてくるのかなと思います。
現状の制約
プレビュー段階ということもあり、利用可能リージョンの制限など、実用上気になる制約もあります。GA版でこれらの制約がどの程度緩和されるかが今後の普及の鍵になりそうです。
今回のアプリのソースコードは GitHubリポジトリ で公開しています。