はじめに
画像判定アプリを作成する過程でFlickrを使用することにしたので、APIキー取得から動作させるまでの備忘録です。
FlickrのAPIキーの取得
Flickr公式
今回は数百回、検索とファイルの保存を行います。
しかし、手動だと時間がかかるので、APIを使用して効率化します。
下記のアドレスにアクセスします。
※アカウントを作成していない方は作成してください。
こちらのページでは、ドキュメントの参照やキーの取得を行えます。
・画像アップロードのAPI
・検索のリクエストを発行するためのフォーマット
・取得したデータのフォーマット
などが記述されています。
ページ上部の「Create an App」をクリックし、キーを取得するページへ遷移します。
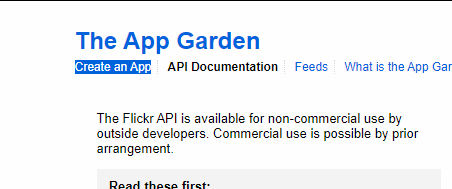
2つ手順が書かれたページへ遷移しました。
1 Get your API Keyの「Request an API Key」をクリックします。
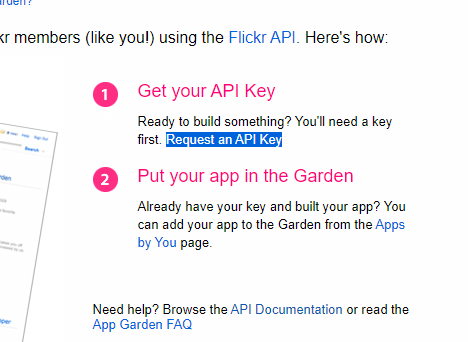
今回は非商用のキーをリクエストしたいので、Non-Commercialを選択します。
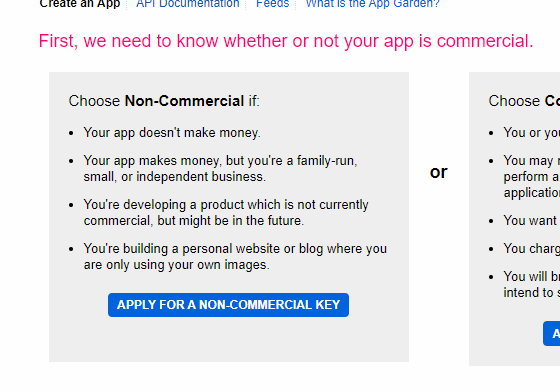
作成するアプリ名、どんしまうaプリなのかを入力します。
チェック欄(著作権の違反をしないか、使用許諾に合意するか)にチャックを入れ、SUBMITをクリックします。
公開鍵と秘密鍵が生成されます。
今後はこれを使用しながら、アプリの開発を進めていきます。
FlickrAPIパッケージのインストール
下記ページを開きます。
「Beej's Python Flickr API」を選択します。

「Beej's Python Flickr API」は画像検索や検索結果を扱うのに、便利な関数文が用意されています。
※「Beej's Python Flickr API」を使うにはPythonの実行環境の用意が必要となります。
Pythonの実行環境一覧を表示
conda info -e
実行環境の有効化
activate 環境名
Flickr APIのインストール
pip install flickrapi
PythonのプログラムからFlickrAPIへアクセス
プログラムや画像データを保存するフォルダを作成しておきます。
必要なライブラリやモジュールをインポートします。
from flickrapi import FlickrAPI
from urllib.request import urlretrieve
from pprint import pprint
import os, time, sys
ライブラリやモジュールの違いについては、以下の記事を書きました。
urllib.request
URLを開くためのライブラリです。
※現在サポートされていません。
複雑なアクセス環境(暗号化認証、Cookieなど)において、URLを開くための関数とクラスを定義します。
マニュアル
pprint
任意のデータをインタプリンタへの入力で使われる形式にしてpretty-printします。
インタプリンタ:プログラミング言語で書かれたソースコード、中間表現を逐次解釈しながら実行するプログラム。コードを実行する際に1行ずつ機械語に変換します。
スクリプト:言語の使用全般。
マニュアル
< printとpprintの違い >
print
リストや辞書の要素が改行されずに1行で出力されます。
pprint
リストや辞書の要素を改行し、見やすく表示します。
os、time、sys
こちらの3つについては以下の記事を書きました。
APIの情報を記述
key = "公開鍵"
secret = "秘密鍵"
# 連続してリクエストを送るとサーバーがパンクしたり、
# スパムとみなされる可能性があるので、それを防ぐため、1秒おきに送る。
wait_time = 1
保存フォルダの指定
# sys.argv[] コマンドラインに出力した情報の2番目のデータを取得
animalname = sys.argv[1]
savedir = "./" + animalname
FlickrAPIにアクセス
# 公開鍵、秘密鍵、フォーマットを指定
flickr = FlickrAPI(key, secret, format='parsed-json')
# 画像検索
result = flickr.photos.search(
text = animalname,
per_page = 400,
media = 'photos',
# 関連順に並べる
sort = 'relevance',
# 有害コンテンツは表示しない
safe_search = 1,
# 返り値に取得したいデータを含める
# 画像のアドレス、ライセンス情報
extras = 'url_q, licence'
)
photos = result['photos']
pprint(photos)