はじめに
この夏にRNNと,経路計画,強化学習の基礎知識を一通り身に着けることを目標にしています!のでその一環です
参考にした本
- ゼロから作るDeep Learning ❷ ―自然言語処理編 斎藤 康毅 オライリージャパン
- ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装 斎藤 康毅 オライリージャパン
- 詳解 ディープラーニング ~TensorFlow・Kerasによる時系列データ処理~ 巣籠 悠輔 マイナビ出版
今回のプログラム
本記事の概要
RNNにおけるデータセットの作成方法についてまとめました
また,基本的なRNNを理解するために,よくあるsin波の予測を行うプログラムを書いてみました
ただ,フルスクラッチで書いてますのでそこはよくあるものとは違うかなと思います
結論
RNNにおけるデータセットの作成方法について知れます
RNN(Trun BPTT)で予測を行ったsin波の予測がでています
LSTMは次回行う予定です
ネットワーク構成と問題の分類
実際データの与え方やそれに伴って,決定するネットワークの形はいろんな本や文献を見るとたくさんあって何がなんやら...
自分が調べた限りの内容にはなりますが,まとめてみます
まずそもそも論,RNNを使用するときに考えることがあります
- 自然言語処理のように,推移から何かの確率を学習したいのか?
- 株式の予測といったように,過去の情報から回帰をして,実測値を学習したいのか?
ということです
確率を扱う場合は,SoftmaxとCross entropyを損失関数に用いますし
回帰の場合は,恒等関数と平均二乗誤差を用いるのが通常です
これは普通のNNでも変わりません
なので問題で何を予測したいのかを考える必要があります
また,予測したいものによっても,ネットワークの構造が変わってきます
言語モデルを扱っているゼロから作るDeep Learning ❷ では,$x(0-4)$の入力を用いて誤差を計算するときに,手前の出力も考えています
以下の図のように
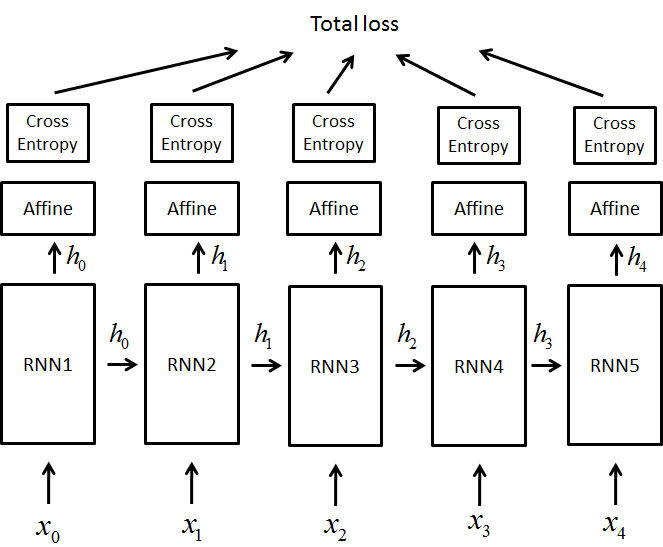
しかし,時系列データを実際に予測している詳解の方では,時系列データ$x(0-4)$を用いて,値を出力
最後の予測のみで損失関数を計算しています
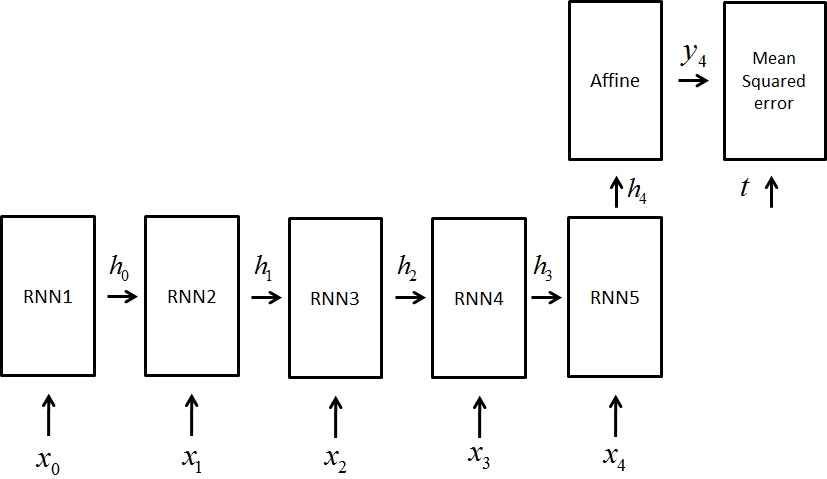
どっちだ...
ってわけですが,どうやら考えている問題によってネットワークの形を切り替えるみたいです.
以下の図を見てください,下の図はRNNのネットワークの形を表したものです
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
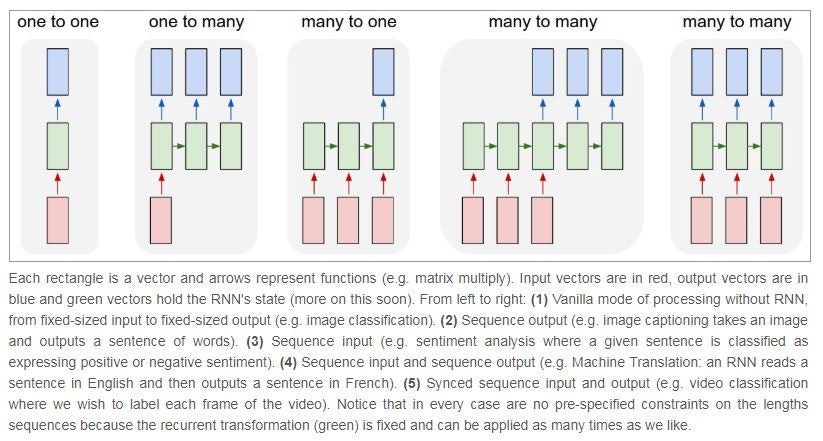
左から順に
-
one to one
これは通常のNNです(自己回帰ノードを持ちません) -
one to many
これは1つの情報から複数を出力するもの,
画像から文章を生成するなどの問題に使われます -
many to one
時系列データ群から1つを出力するもの
時系列データの予測(+1ステップ後など)や,文章のクラスタリングに使われます -
many to many(1)
時系列データから異なる時系列データを出力するもの
翻訳などですね,日本語から英語などに翻訳する際に使われます
seq2seqなどもこれです -
many to many(2)
これも上記と似ていますが,同時系列のものが並んでいます
ここでは,ビデオのクラスタリングなどに用いられると書いてあります
ただ,この形がよく取られるのは文章を生成するための言語モデルです
つまり
こちらも自分の扱う問題によって変わってくることになります
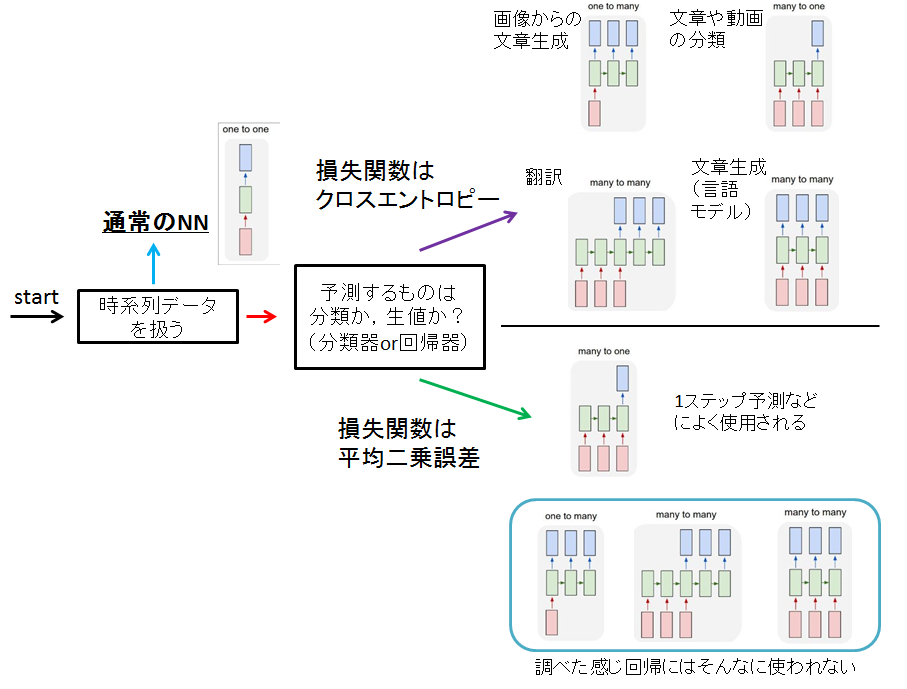
まとめると
以下の項目に注目してネットワークの構成を決めるとよいかもです
データセットの作成法と学習のさせ方について
では次に,データセットの作成方法と学習方法について考えてみます
分かりやすいように2つの例を考えます
- sin波を予測する場合
- その文章がどれだけもっともらしいかを学習する場合(言語モデル)
sin波の場合
sin波を時系列データととらえると(ノイズを載せてます)
この場合やりたいことは,
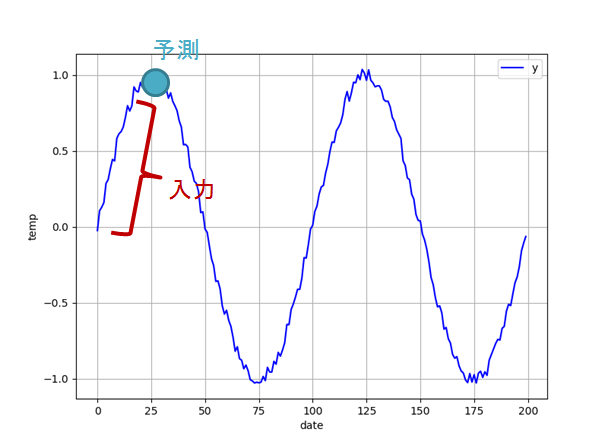
ということになります
つまり,過去Nステップ分のデータから,次のステップを予測するわけですね
上の図でいえば,回帰モデルのmany-to-oneに当たるわけです
この場合データセットは,教師信号と入力を以下のように与えることができます
回帰の場合はイメージがしやすいと思います
-
入力
Nステップのデータ(t-Nからtまで) -
出力
次時刻のデータ(t+1)
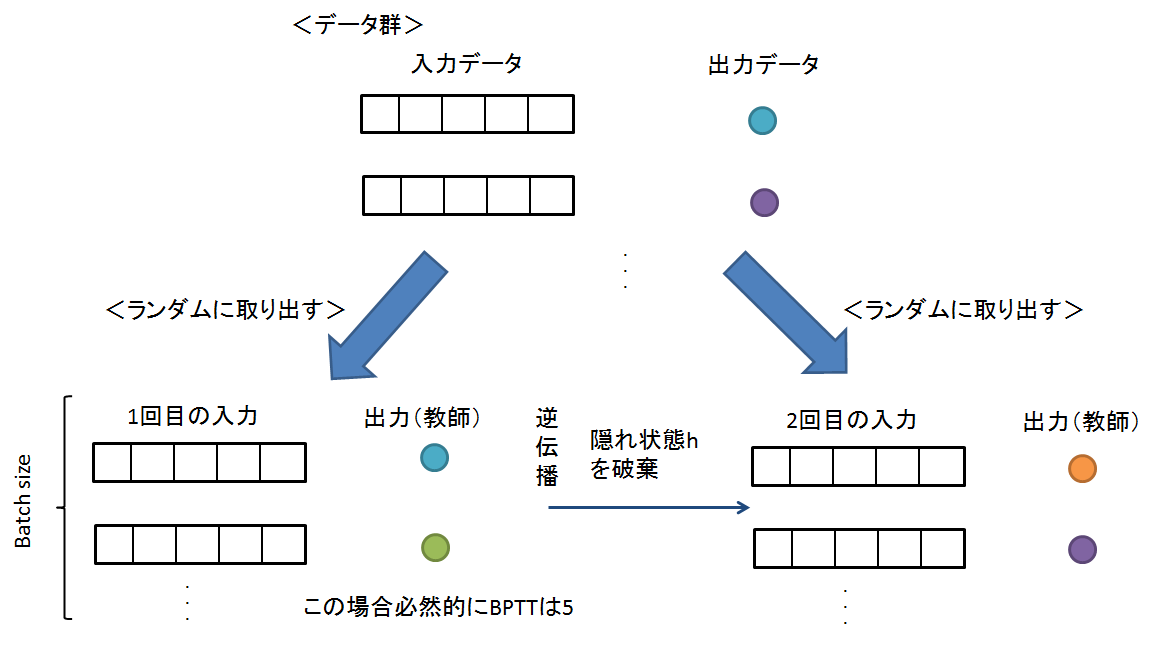
では,学習方法について考えます.ただ,そんなに難しいことはありません,以下の流れのようになります.
例えば,1000組データがあったとしたらランダムにbatch数分抜き出して使います
- Batchサイズを決定
- 用意したデータ(入力と出力の組み合わせ)からBatchサイズ分,ランダムに抜き出す
- 順伝搬
- 逆伝播
- 勾配更新
- 隠れ状態を破棄(重みは保持)(隠れ状態については後でコメントします)
- 2-5を繰り返し
サンプルコードはこんな感じ
これは通常のNNに近いですね
data_size = len(x) # 行×列の行がでるイメージ
max_iters = data_size // batch_size # 1epoch分を計算
start_time = time.time()
for epoch in range(max_epoch):
# シャッフル,# 単純に混ぜただけ
idx = np.random.permutation(np.arange(data_size))
x = x[idx]
t = t[idx]
for iters in range(max_iters):
# 順番に取り出していく
batch_x = x[iters*batch_size:(iters+1)*batch_size]
batch_t = t[iters*batch_size:(iters+1)*batch_size]
# 勾配を求め、パラメータを更新
loss = model.forward(batch_x, batch_t)
# print(loss)
model.backward()
params, grads = remove_duplicate(model.params, model.grads) # 共有された重みを1つに集約,下参照
optimizer.update(params, grads) # 片方だけ更新すれば全部更新されます(共有された重みはアドレスを共有しているので)
total_loss += loss
loss_count += 1
隠れ状態については後で話します
言語モデルの場合
言語モデルの場合は,その文章がどれくらい自然かを学習する必要があるので,単語の同時確率を考える必要があります(この辺りは,0から作るdeep learning2で詳しく述べられています)
すると,最尤推定の考えを用いて,損失関数を先ほどのように隠れ状態からのすべての出力で考慮する必要があるので,ネットワークの構成はmany-to-manyになります
http://www.phontron.com/slides/alagin2014-lm.pdf
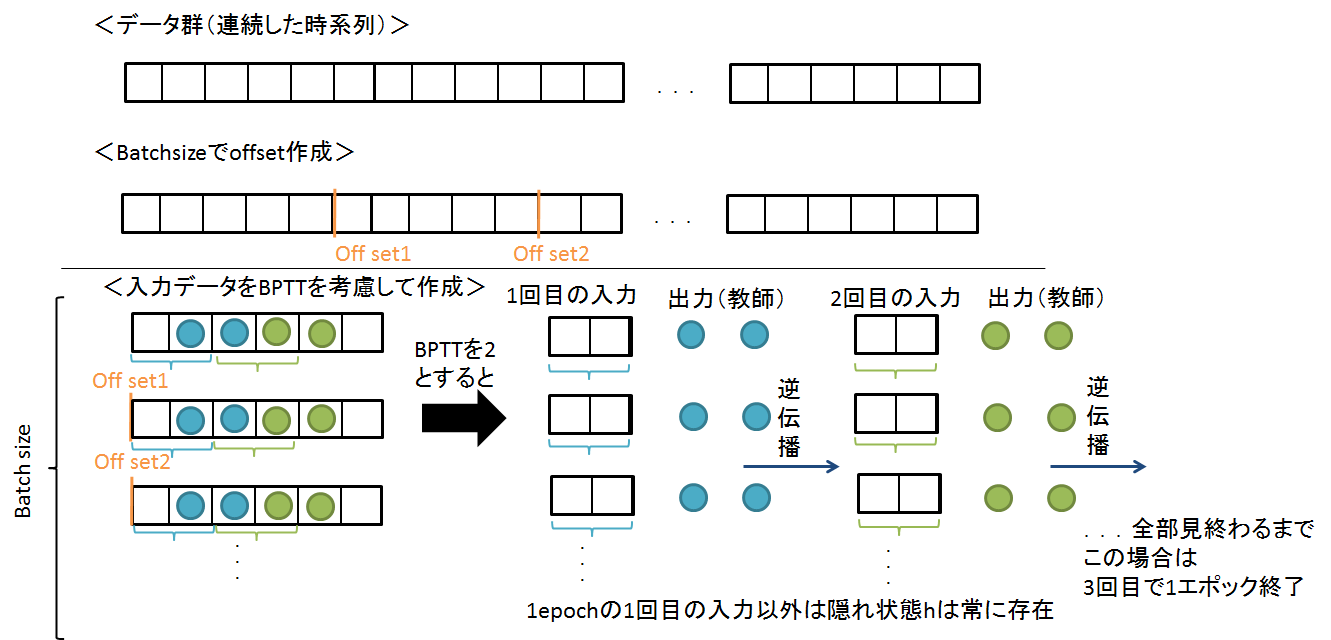
この場合,データセットの与え方は1つの長い文章を学習させることになるので,以下のようになります
例えば,100000とか200000とかのデータがあったとしましょう
これはいろいろな言葉が入った文章だとします
そうなった場合,過去のいくつまでみて予想してほしい!っていうのは無理ですね
どんなパターンがあるのかわかりません,ですので,明確に過去のデータを分離して学習させるのは,おかしいです
しかも,もし仮にLSTMを使っても勾配消失の可能性はあります.
ですのでBPTTを打ち切らねばなりません.そりゃ100000ステップいれるのはナンセンスですし,メモリも不足します.
なので,隠れ状態hを保存したまま学習を行います
つまり,こんな感じです
学習が回っているとき,初期のとき以外は隠れ状態hを保存しておきます
こうすることで,1つの長いデータを学習できます
実際,0から作るDeep Learning 2などを参考にすると,
データ入力と学習の流れは
- Batchサイズでデータ長さを割ります
- offset分ずらしてデータセットを作成
- BPTT打ち切りを考慮して順伝播
- 逆伝播
- 隠れ状態を保存h
- データを見終わるまで繰り返し
イメージとしては,学習データを分離させて,流れを平均的に(語弊があったらすいません)学習しています.
ランダム性はありません
隠れ状態を保持しているので
サンプルコードとしてはこんな感じです
# ミニバッチの各サンプルの読み込み開始位置を計算
time_size = 5 # BPTTをいくつで打ち切るのか
batch_size = 10 # バッチサイズ
data_size = 100000 # 時系列データの長さ
max_epoch = # 最大エポック数
max_iters = data_size // (batch_size * time_size) # 現実的に繰り返せる回数(データの数),ランダムに使うわけではない!!,今回は99
jump = (data_size - 1) // batch_size
offsets = [i * jump for i in range(batch_size)] # ずらす分
for epoch in range(max_epoch):
for iter in range(max_iters): # この回数繰り返すとデータをすべて見たことになる
# ミニバッチの取得
batch_x = np.empty((batch_size, time_size), dtype='i')
batch_t = np.empty((batch_size, time_size), dtype='i')
for t in range(time_size): # BPTTを考慮していれる
for i, offset in enumerate(offsets):
batch_x[i, t] = xs[(offset + time_idx) % data_size] #
batch_t[i, t] = ts[(offset+1 + time_idx) % data_size] # 1stepずらす(同じ時系列でxsとtsが構成されているとする)
time_idx += 1 # これによって足し算する
# 勾配を求め、パラメータを更新
loss = model.forward(batch_x, batch_t)
model.backward()
optimizer.update(model.params, model.grads)
total_loss += loss
loss_count += 1
隠れ状態について
さきほどのステップの中で隠れ状態の話をしましたが,これは扱うデータの長さを考える必要があります
BPTTは,RNNで学習を行うための優れたアルゴリズムですが,勾配が爆発や消失に繋がる可能性があります
なので,言語モデルのように長い長い時系列を学習する場合は途中でそれを打ち切らないといけません
しかし,順伝播については,そのまま進んでおいてほしいんですね
なので!以下の図のように隠れ状態を保存しながら学習をすすめて,途中で逆伝播を挟むみたいなことをします.
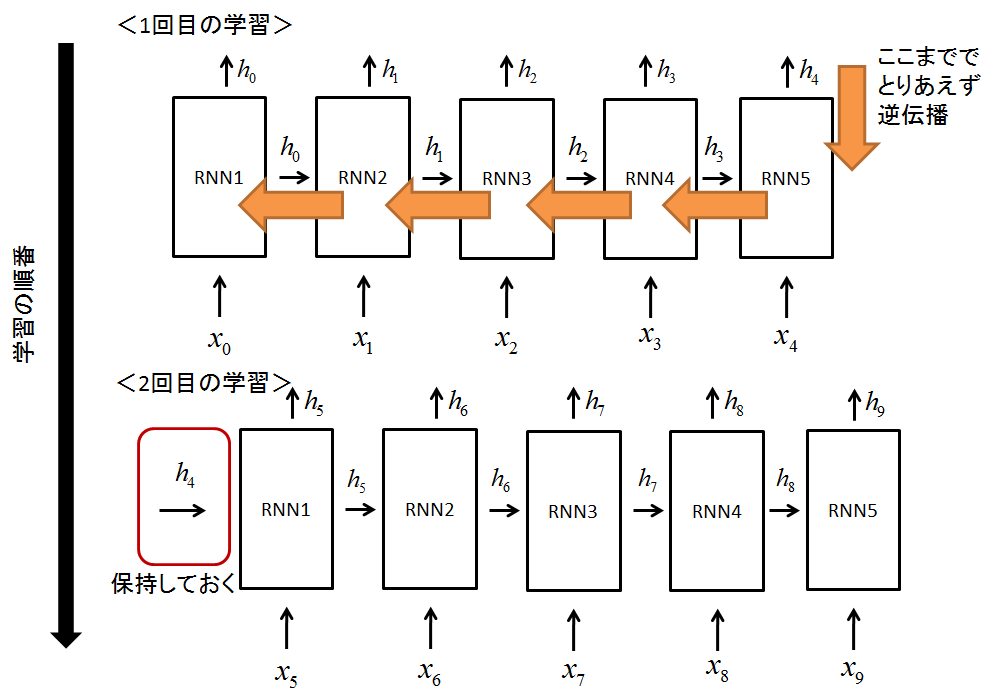
なんとなく,言語モデルの場合は長さが長いので,隠れ状態を保持することに対しての疑問はないかと思います
ただ,注意点としては,状態を保持する場合は,データセットはランダムに与えることはできません
時系列的に与える必要があるので!上の図のようにしてください
ランダムに与えると保持している意味はありませんもんね
逆に,短い文章をクラスタリングする問題は,学習データはそれぞれが独立しているので,状態を保存しておく必要はありません
では,今回のsin波は隠れ状態を保存しなくてよいのでしょうか?
調べてみても結果があまりなかったのですが,たぶんデータに周期性があまり見られない時だと思います
今回のsinは周期性が存在するのでいいのかな~というわけですが...
つまり,自分が今回みた範囲内に特徴が表れる場合は,保存しなくてよいわけです(例えば過去25ステップで十分なら)保存しません
逆に,特徴が現れない場合保存しないといけなくなりますたぶん
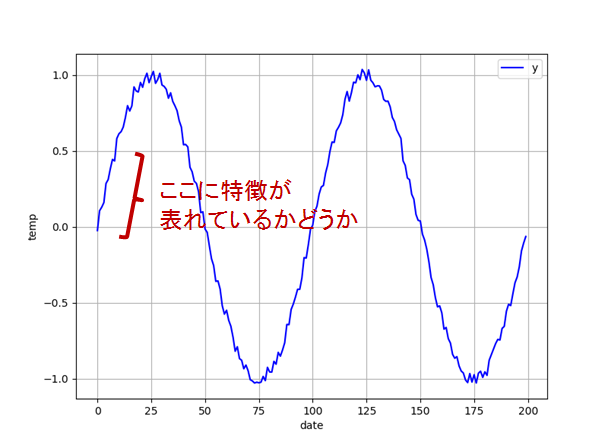
ただ,ときと場合によると思います(知識がある方がいればコメントをお願いしたいです...)
つまり,過去1000ステップをみないといけないデータがあって,1001ステップを予測したいみたいな問題のとき
BPTTを30で打ち切るのであれば,30ステップ伝播を行って,31ステップの教師との誤差を逆伝播をします
この次は状態を保存しておいて次の伝播を順々に行えばよさそうです
ただいずれにしても,状態を保存する場合はデータの与え方を時系列的に与える必要がありますので!
結論
RNNでのネットワークの作成方法とデータセット作成・学習方法をまとめました
参考github
- 言語モデル
- https://github.com/oreilly-japan/deep-learning-from-scratch-2
- https://github.com/oreilly-japan/deep-learning-from-scratch