はじめに
この夏にRNNと,経路計画,強化学習の基礎知識を一通り身に着けることを目標にしています!のでその一環です
結果と結論
平均気温の予測はうまくいきませんでした
やはり予測は難しいですね
いろんな要素が複合的に絡んでいるので,まずは状況を根っこから理解することが大切だと思いました
事前検証:sin波予測
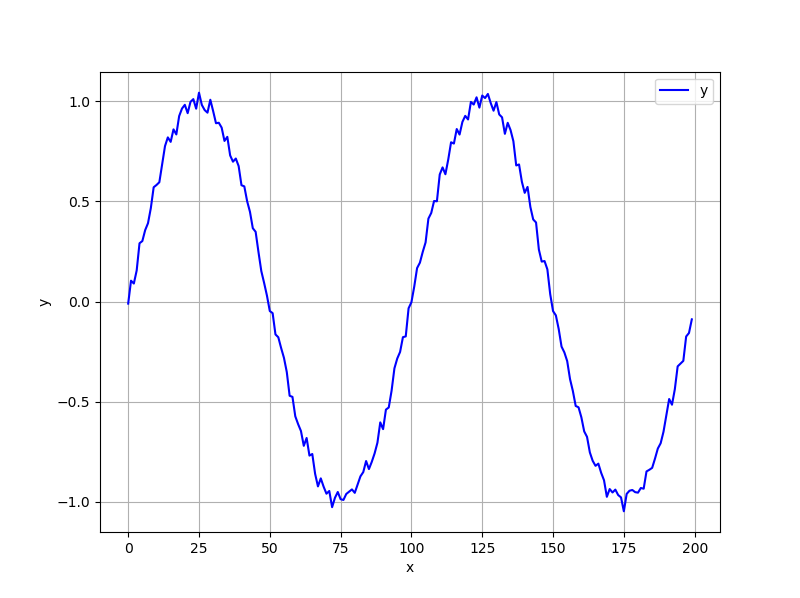
まず,自分のかいたプログラムがあっているのか間違っているのかを確認するためにsin波の学習をやらせてみました
学習するsin波にはノイズを載せてあります
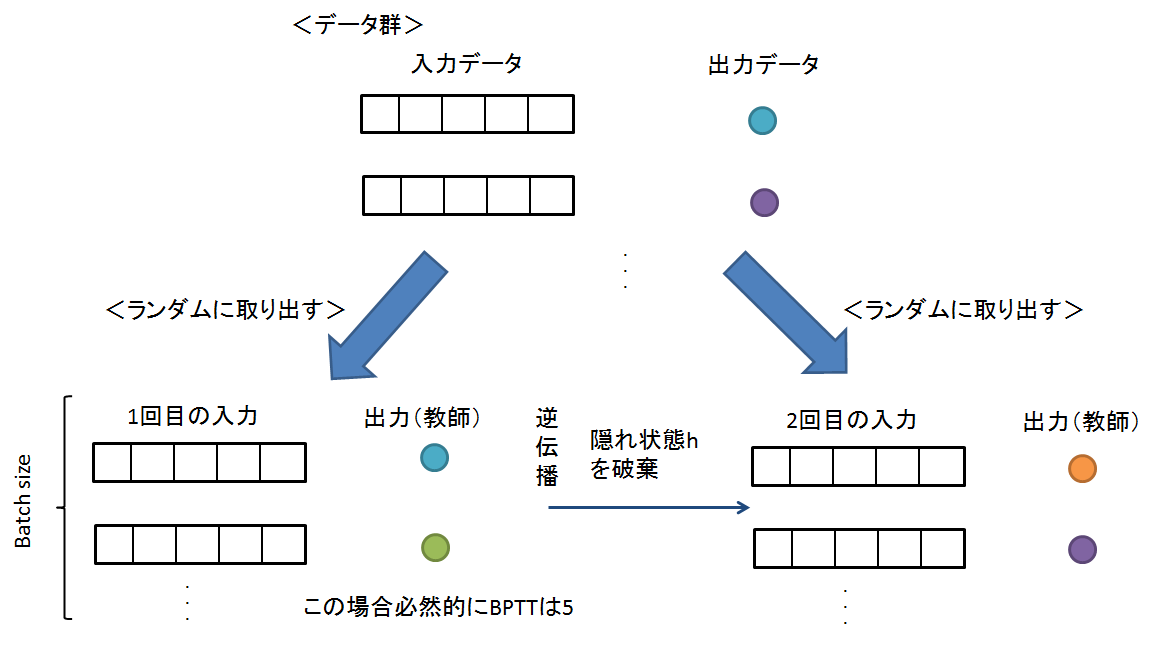
学習させ方はこんなん
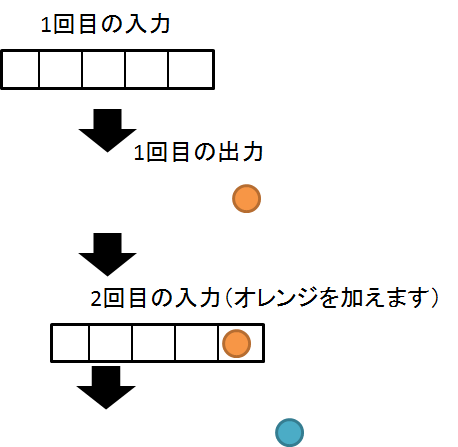
予測するときには,自分が予測したやつを次の入力にしてって感じでやらせてます
ハイパーパラメータ系は以下の感じ
詳細のプログラムについては最後に説明します
# ハイパーパラメータの設定
batch_size = 10 # バッチサイズ
input_size = 1 # 入力の次元
hidden_size = 20 # 隠れ層の大きさ
output_size = 1 # 出力の次元
time_size = 50 # Truncated BPTTの展開する時間サイズ,RNNのステップ数
lr = 0.01 # 学習率 0.01
max_epoch = 5000 # 最大epoch
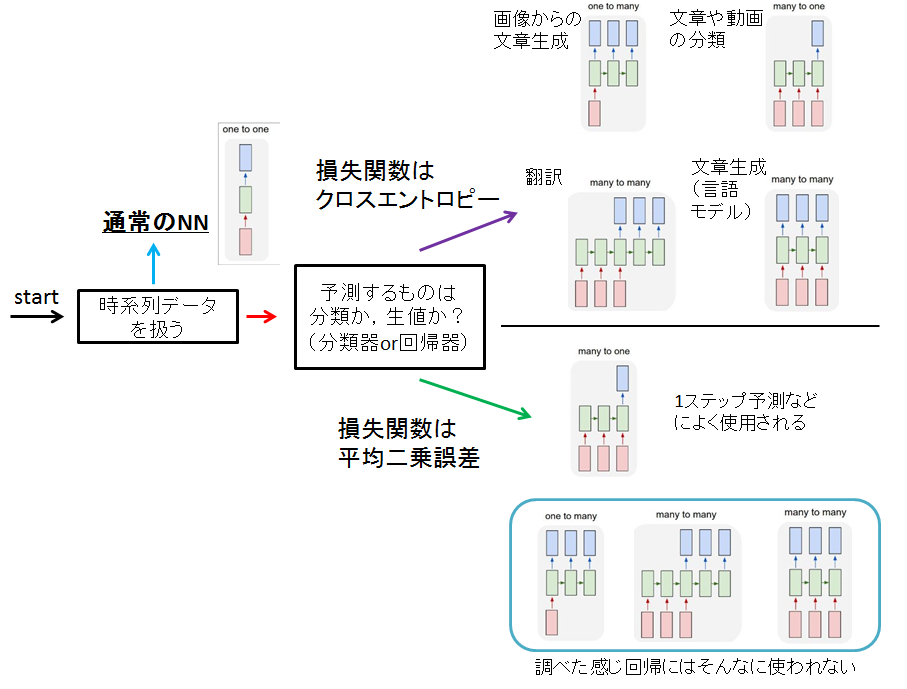
また,前回の投稿でもまとめましたが,今回使うネットワークはこんな形のもです
つまり,many-to-oneになります
図でいうと右下のやつ
回帰だし
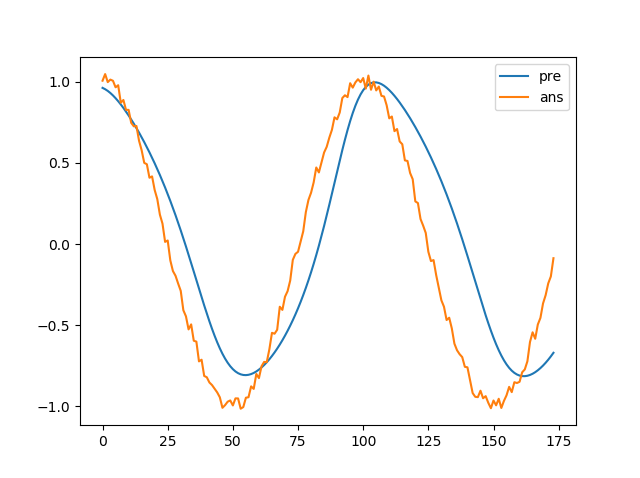
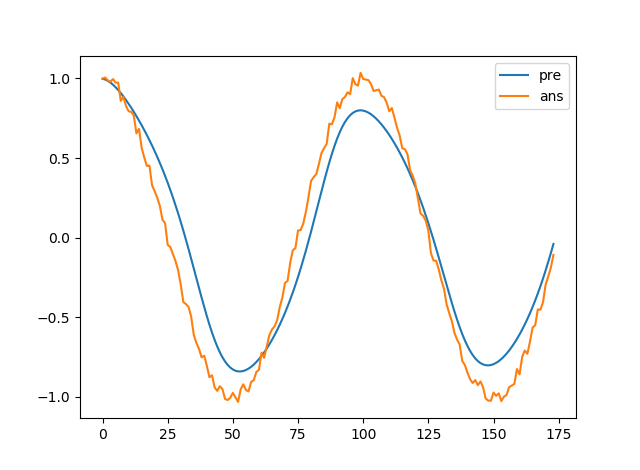
結果はこんな感じ
まぁだいたいほかの人も似たような結果になっている方が多いのであっているかと...
RNN
LSTM
月の平均気温予測
ではいよいよ本題
気象庁のサイトからダウンロードしてきます
本当に便利な世の中ですね
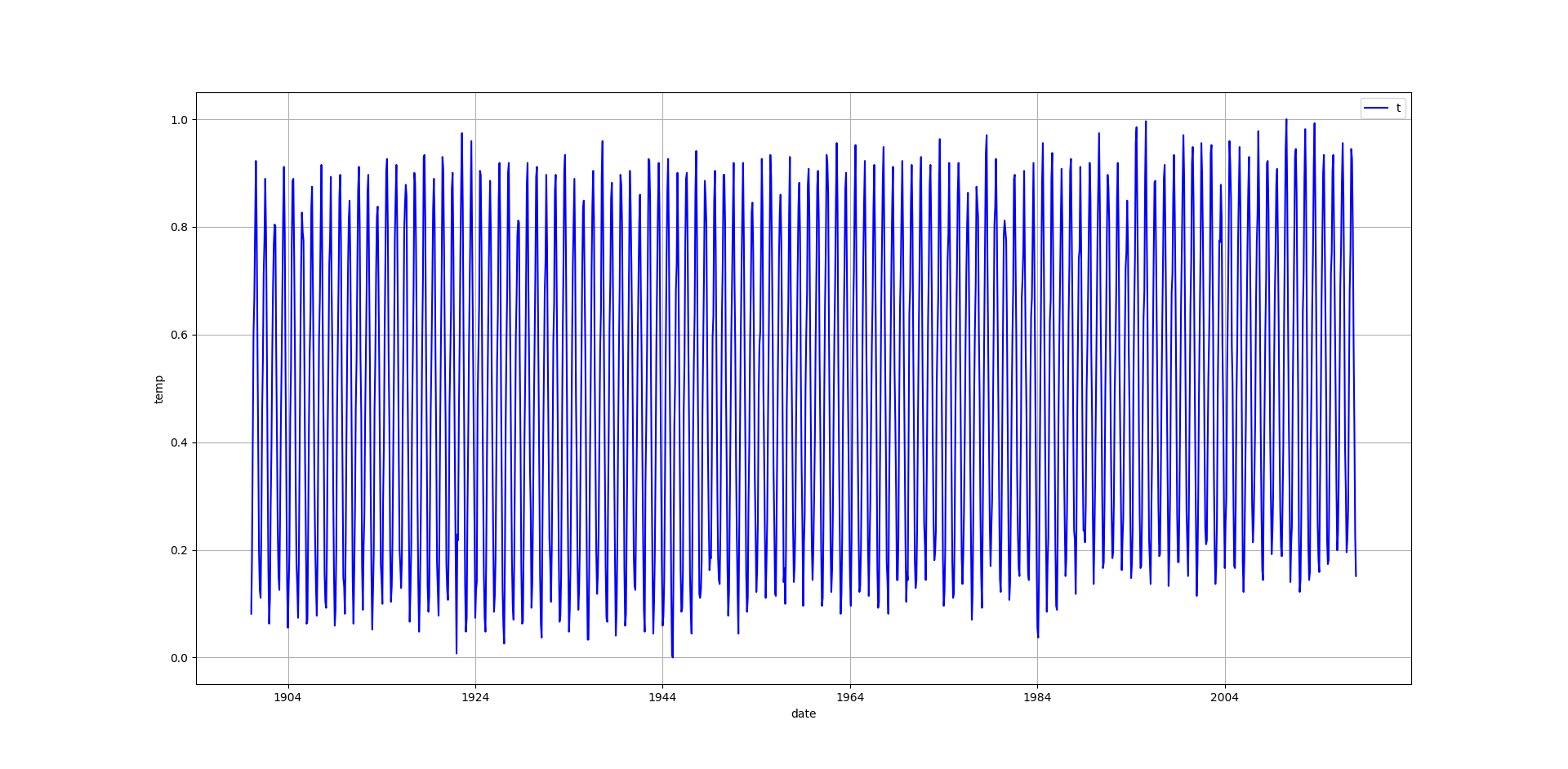
plotするとこんな感じ
月の平均気温です,正規化してあります
学習のさせ方
注意点です
今回は周期性がどうでているのか,分かりにくいので,学習させるときにすべてのながれを学習させるようにします
まぁ12周期なので12でもいいかもですが,
地球温暖化のこととか予測してくれそうだと信じてみる
なので,学習のさせ方は下図のイメージになります
詳しくは前回の話を参考にしてください
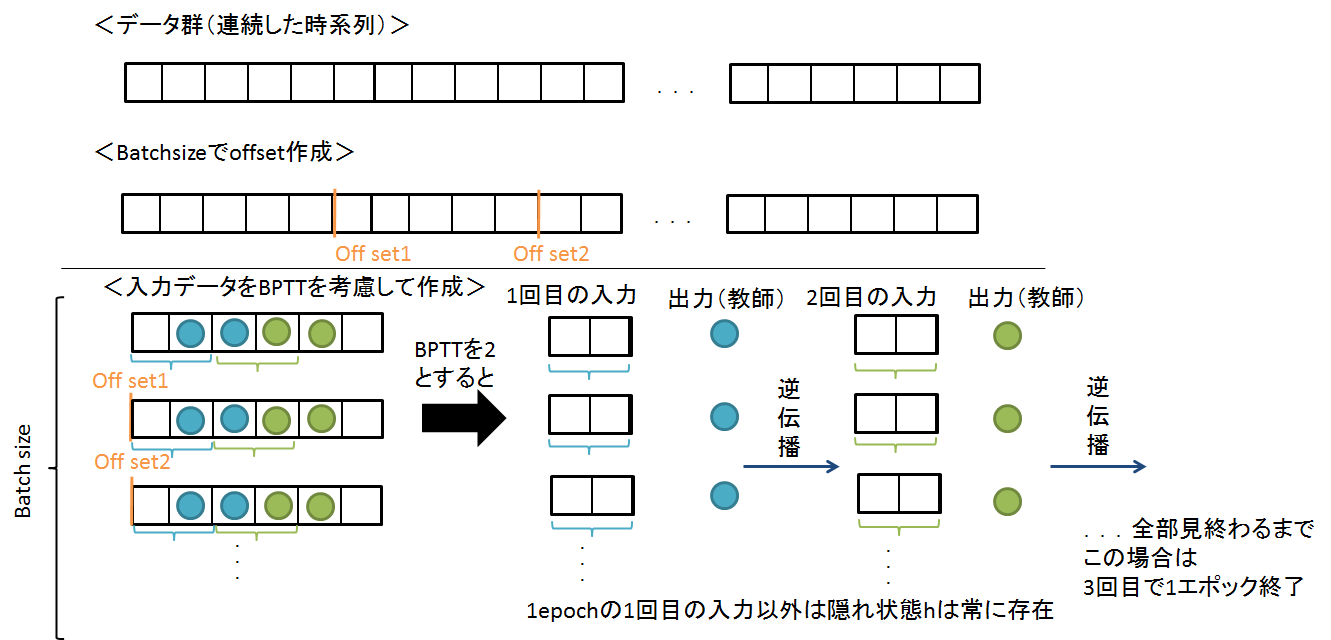
つまり,隠れ状態を保持して学習させるということです
ネットワーク構成
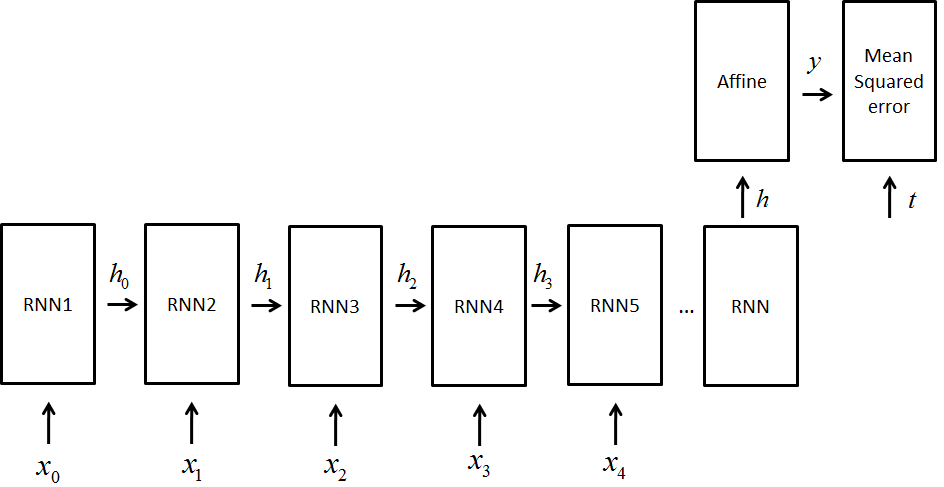
LSTMの場合はRNNのところがLSTMになります
とりあえず予想してみる
この時,学習方法として
- 8割を学習用として使用
- テストデータを使って予測するとき,一番初めのタイミングでは,過去50日分(basicRNNの場合は25)のデータを使えるとするとします,そのあとは,自分の予測したデータを用いて未来を予想していきます
で,本当は検証用データとかと分けた方がいいんでしょうけど
少し手間がかかるので
とりあえずやってみます
正規化は戻してません
あと,水色のデータはトレーニングデータの一部を表示しています
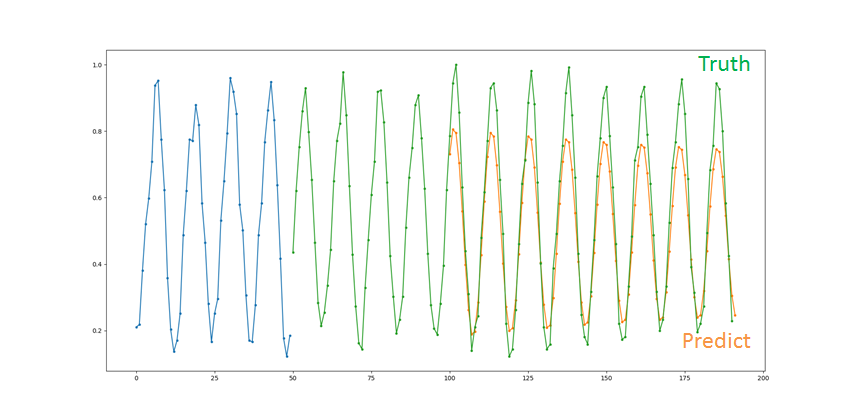
微妙笑
うまくいきません
ちなみにシンプルなRNNもうーん
LSTMがパラメータ調整してないこともあって意外とこっちの方がよかったり?
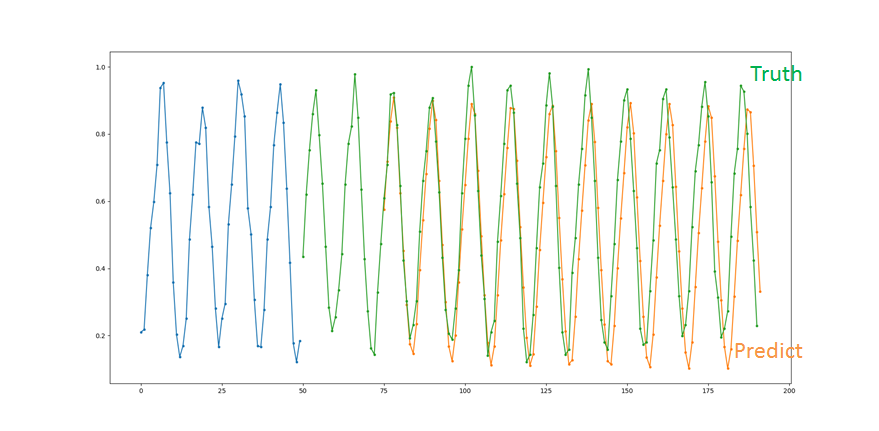
パラメータを調整してどうかってところでしょうか
さらに精度をあげるためには,いろいろ考える必要があります
影響を受けると考えられるもの
- 気団の発達具合
- 海水面の温度
- 二酸化炭素濃度
この値のデータをいれればもう少し精度あがったりしないかな?
また時間があったらやってみます
あと,そもそも論ですけど
こういう問題って,前の情報を記録しておく必要あるのかってことです
この場合,年間の気温情報を少し記録してくれてれば,温暖化を予測するなんて言うこともあったかもしれませんが,またそれも難しいですね
微小変化でしょうし
なので,前の情報が大切になる言語とかにはLSTMは改めて有効なんだなぁと感じました
物理現象は基本的には,運動方程式なので,LSTMみたいに記憶しておく必要ないですからね
マルコフ性仮定してるし...
という感想でした
勉強にはなりました!
github
twitter : https://twitter.com/ShunichiSekigu1
hatena : https://shunichi09.hatenablog.com/
プログラムについて
のせてしまうとぐちゃぐちゃになるので一部だけ下にのせました!
逆伝播のところですね
-
main_temp
mainです -
layers_temp
NNのレイヤーが入ってます -
NN_temp
ネットワーク構成をここで決めてます -
functions
良く使う関数 -
optimizer_trainer_temp
パラメータ更新や,トレーニングです
参考
layers_temp
# 標準ライブラリ系
import numpy as np
import matplotlib.pyplot as plt
import time
import sys
import copy
# 関数
from functions import sigmoid
class RNN():
'''
RNNの1ステップの処理を行うレイヤーの実装
'''
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b] # くくっているのは同じ理由
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev): # h_prevは1つ前の状態
Wx, Wh, b = self.params # 取り出す
t = np.dot(h_prev, Wh) + np.dot(x, Wx) + b
h_next = np.tanh(t) # tanh関数
self.cache = (x, h_prev, h_next) # 値を保存しておく
return h_next
def backward(self, dh_next): # 隠れ層の逆伝播の値が引数
Wx, Wh, b = self.params
x, h_prev, h_next = self.cache
dt = dh_next * (1 - h_next ** 2) # tanhの逆伝播(各要素に対してかかる)
db = np.sum(dt, axis=0) # いつものMatmulと同じ
dWh = np.dot(h_prev.T, dt) # いつものMatmulと同じ
dh_prev = np.dot(dt, Wh.T) # 上の式みて考えれば分かる
dWx = np.dot(x.T, dt)
dx = np.dot(dt, Wx.T)
self.grads[0][...] = dWx # 値をコピー
self.grads[1][...] = dWh
self.grads[2][...] = db
return dx, dh_prev
class TimeRNN:
'''
上のやつ全部まとめたやつBPTTさせる分
'''
def __init__(self, Wx, Wh, b, stateful=True):
self.params = [Wx, Wh, b] # くくっているのは同じ理由 hWh + xWx + b = h
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
self.h, self.dh = None, None
self.T = None
self.stateful = stateful
def set_state(self, h):
self.h = h
def reset_state(self):
self.h = None
def forward(self, xs):
Wx, Wh, b = self.params # パラメータの初期化
N, self.T, D = xs.shape # xsの形, Dは入力ベクトルの大きさ,このレイヤーはまとめてデータをもらうので!
D, H = Wx.shape
self.layers = [] # 各レイヤー(RNNの中の)
hs = np.empty((N, self.T, H), dtype='f') # Nはバッチ数,Tは時間数,HがHの次元
if not self.stateful or self.h is None: # statefulでなかったら,または,初期呼び出し時にhがなかったら(前の状態を保持しなかったら)
self.h = np.zeros((N, H), dtype='f') # Nはバッチ数
for t in range(self.T): # 時間分(backpropする分)だけ繰り返し
layer = RNN(*self.params) # 可変長引数らしい ばらばらで渡される今回のケースでいえば,Wx, Wh, bとしても同義
self.h = layer.forward(xs[:, t, :], self.h) # その時刻のxを渡す
hs[:, t, :] = self.h # 保存しておく
self.layers.append(layer) # RNNの各状態の保存
# 出力はhsの最後のものだけ
hs = hs[:, -1, :]
# print('hs= {0}'.format(hs))
# a = input()
return hs
def backward(self, dhs):
Wx, Wh, b = self.params # パラメータの初期化
N, H = dhs.shape # xsの形, Dは入力ベクトルの大きさ,このレイヤーはまとめてデータをもらうので!
D, H = Wx.shape
dxs = np.empty((N, self.T, D), dtype='f')
grads = [0, 0, 0]
for t in reversed(range(self.T)):
layer = self.layers[t] # 一つずつ保存しておいたlayerを呼び出す
dx, dhs = layer.backward(dhs)
dxs[:, t ,:] = dx
for i, grad in enumerate(layer.grads): # 各重み(3つ,Wx, Wb, b)を取り出す,同じ重みを使っているので,勾配はすべて足し算
grads[i] += grad
# print(len(grads))
for i, grad in enumerate(grads): # 時系列順に並んでいるやつをコピー
self.grads[i][...] = grad #
self.dh = dhs
return None# dxs # 後ろに逆伝播させる用(N, T, D)になっている
class LSTM:
def __init__(self, Wx, Wh, b):
'''
Wx: 入力`x`用の重みパラーメタ(4つ分の重みをまとめる)
Wh: 隠れ状態`h`用の重みパラメータ(4つ分の重みをまとめる)
b: バイアス(4つ分のバイアスをまとめる)
'''
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev, c_prev):
Wx, Wh, b = self.params # パラメータ抽出
N, H = h_prev.shape # 隠れ状態のサイズ,batch×大きさ
A = np.dot(x, Wx) + np.dot(h_prev, Wh) + b # 内部状態を算出
f = A[:, :H] # それぞれを挿入する,3列目
g = A[:, H:2*H] # 2列目
i = A[:, 2*H:3*H] # 3列目
o = A[:, 3*H:] # 4列目
f = sigmoid(f) # forget gate
g = np.tanh(g) # memorizeする情報
i = sigmoid(i) # input gate
o = sigmoid(o) # output gate
c_next = f * c_prev + g * i # 出力を計算
h_next = o * np.tanh(c_next) # 次の状態を保持
self.cache = (x, h_prev, c_prev, i, f, g, o, c_next)
return h_next, c_next
def backward(self, dh_next, dc_next):
Wx, Wh, b = self.params
x, h_prev, c_prev, i, f, g, o, c_next = self.cache # パラメータ取り出し
tanh_c_next = np.tanh(c_next) # p246の右端のところ,tanhが必要,掛け算
ds = dc_next + (dh_next * o) * (1 - tanh_c_next ** 2) # 右端のところがちょっと難しいけど,追っていけばできる
dc_prev = ds * f # 掛け算ノードの逆伝播
di = ds * g # 同じ
df = ds * c_prev # 追っていけばできる
do = dh_next * tanh_c_next # p246の右端のところ,tanhが必要,掛け算
dg = ds * i # 掛け算のところ
di *= i * (1 - i)
df *= f * (1 - f)
do *= o * (1 - o)
dg *= (1 - g ** 2) # 自分のところに戻るようの逆伝播
dA = np.hstack((df, dg, di, do)) # 結合
dWh = np.dot(h_prev.T, dA) # 左端の逆伝播
dWx = np.dot(x.T, dA)
db = dA.sum(axis=0)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
dx = np.dot(dA, Wx.T)
dh_prev = np.dot(dA, Wh.T)
return dx, dh_prev, dc_prev # 3つ!,簡単です
class TimeLSTM:
'''
Time分出力できるやつ
'''
def __init__(self, Wx, Wh, b, stateful=True):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
self.h, self.c = None, None
self.T = None
self.dh = None
self.stateful = stateful
def forward(self, xs):
Wx, Wh, b = self.params
N, self.T, D = xs.shape
H = Wh.shape[0]
self.layers = []
hs = np.empty((N, self.T, H), dtype='f')
if not self.stateful or self.h is None: # statefulがFalseなら0にする
self.h = np.zeros((N, H), dtype='f')
if not self.stateful or self.c is None: # statefulがFalseなら0にする
self.c = np.zeros((N, H), dtype='f')
for t in range(self.T): # 時間サイズをTへ
layer = LSTM(*self.params) # 同じ重みを共有する
self.h, self.c = layer.forward(xs[:, t, :], self.h, self.c)
hs[:, t, :] = self.h # RNNの各状態の保存
self.layers.append(layer)
# 出力はhsの最後のものだけ
hs = hs[:, -1, :]
return hs
def backward(self, dhs):
Wx, Wh, b = self.params
N, H = dhs.shape # 時刻にして1つ分しか返ってこないはず
D = Wx.shape[0]
dxs = np.empty((N, self.T, D), dtype='f')
dh, dc = 0, 0
grads = [0, 0, 0]
for t in reversed(range(self.T)):
layer = self.layers[t]
dx, dhs, dc = layer.backward(dhs, dc)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h, c=None): # stateを消去
self.h, self.c = h, c
def reset_state(self): # 記憶セルもすべて消去
self.h, self.c = None, None
class TimeAffine:
'''
AffineがT個分ある(行列演算レベルでくっつけてある)
'''
def __init__(self, W, b):
self.params = [W, b]
self.grads = [np.zeros_like(W), np.zeros_like(b)]
self.x = None
def forward(self, x):
N, D = x.shape
W, b = self.params
rx = x
out = np.dot(rx, W) + b
self.x = x
return out # 時系列データが出力される
def backward(self, dout):
x = self.x
N, D = x.shape
W, b = self.params
rx = x
db = np.sum(dout, axis=0)
dW = np.dot(rx.T, dout) # こうすれば,横向きになっているから全部勾配が勝手に足される(forで回す必要がない)行×列でいける(D * N*T) * (N*H * H)かな
dx = np.dot(dout, W.T) # こっちもおなじ原理
self.grads[0][...] = dW
self.grads[1][...] = db
# print('dx= {0}'.format(dx))
# a = input()
return dx
class TimeIdentifyWithLoss:
'''
時系列データをまとめて受け付ける損失関数
'''
def __init__(self):
self.params, self.grads = [], []
self.cache = None
self.counter = 0
def forward(self, xs, ts):
N, D = xs.shape # ここでDは1
ys = copy.deepcopy(xs) # 恒等関数
# print('ts = {0}'.format(ts))
loss = 0.5 * np.sum((ys - ts)**2)
loss /= N # 1データ分での誤差
# print('Y = {0}, T = {1}'.format(np.round(ys, 3), np.round(ts, 3)))
# print('N * T = {0}'.format(N*T))
# print('loss = {0}'.format(loss))
# if self.counter % 1 == 0:
# plt.plot(range(len(ys.flatten())) , ys.flatten())
# plt.plot(range(len(ys.flatten())) , ts.flatten())
# plt.show()
# a = input()
self.cache = (ts, ys, (N, D))
self.counter += 1
return loss
def backward(self, dout=1):
ts, ys, (N, D) = self.cache
dx = ys - ts # 出力をこっちにいれとく
dx /= N
return dx
NN_temp
# 標準ライブラリ系
import sys
import numpy as np
import pickle
import os
import matplotlib.pyplot as plt
# レイヤー
from layers_temp import TimeRNN, TimeAffine, TimeLSTM, TimeIdentifyWithLoss
class BaseModel:
'''
基本のネットワーク動作
'''
def __init__(self):
self.params, self.grads = None, None
def forward(self, *args):
raise NotImplementedError
def backward(self, *args):
raise NotImplementedError
def save_params(self, file_name=None):
'''
保存用
'''
if file_name is None:
file_name = self.__class__.__name__ + '.pkl'
params = [np.array(p, dtype='f2') for p in self.params]
'''
if GPU:
params = [to_cpu(p) for p in params]
'''
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name=None):
'''
loadする
'''
if file_name is None:
file_name = self.__class__.__name__ + '.pkl'
if '/' in file_name:
file_name = file_name.replace('/', os.sep)
if not os.path.exists(file_name):
raise IOError('No file: ' + file_name)
with open(file_name, 'rb') as f:
params = pickle.load(f)
params = [p.astype('f') for p in params]
'''
if GPU:
params = [to_gpu(p) for p in params]
'''
for i, param in enumerate(self.params):
param[...] = params[i] # loadしたやつをself.paramsに入れている
class SimpleRnn(BaseModel):
'''
NN構成:simple RNN ⇒ Affine ⇒ identify with loss
'''
def __init__(self, input_size, hidden_size, output_size):
D, H, O = input_size, hidden_size, output_size # 入力の次元,隠れ層の次元,出力の次元
rn = np.random.randn
# 重みの初期化
rnn_Wx = (rn(D, H) / 10).astype('f')
rnn_Wh = (rn(H, H) / 10).astype('f')
rnn_b = np.zeros(H).astype('f')
affine_W = (rn(H, O) / 10).astype('f')
affine_b = np.zeros(O).astype('f')
# レイヤの生成
self.layers = [
TimeRNN(rnn_Wx, rnn_Wh, rnn_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeIdentifyWithLoss()
self.rnn_layer = self.layers[0]
# すべての重みと勾配をリストにまとめる
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
# サイズ保存しておく
self.input_size = input_size
self.output_size = output_size
self.hidden_size = hidden_size
def predict(self, xs):
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts): # 教師,入力ともに三次元
for layer in self.layers:
xs = layer.forward(xs)
loss = self.loss_layer.forward(xs, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
self.rnn_layer.reset_state()
class RnnLSTM(BaseModel):
'''
NN構成:LSTMs ⇒ Affine ⇒ identify with loss
'''
def __init__(self, input_size, hidden_size, output_size):
D, H, O = input_size, hidden_size, output_size # 入力の次元,隠れ層の次元,出力の次元
rn = np.random.randn
# 重みの初期化
# 基本はこの式
# x(バッチ×時系列×次元) --> x * Wx(Embedding) --> hWh + xWx + b = h --> h(バッチ×時系列×次元)* Wx(Affine) --> 出力
lstm_Wx = (rn(D, 4 * H) / 10).astype('f') # LSTMは複雑そうに見えて重みはこれだけ!後は内部で保存されてる
lstm_Wh = (rn(H, 4 * H) / 10).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, O) / 10).astype('f')
affine_b = np.zeros(O).astype('f')
# レイヤの生成
self.layers = [
TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeIdentifyWithLoss()
self.lstm_layer = self.layers[0]
# すべての重みと勾配をリストにまとめる
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
# サイズ保存しておく
self.input_size = input_size
self.output_size = output_size
self.hidden_size = hidden_size
def predict(self, xs):
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts):
score = self.predict(xs)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self): # the reset!!
self.lstm_layer.reset_state()
class RnnLSTMgen(RnnLSTM):
'''
予測用のクラス
'''
def generate(self, start_data, ans_data, skip_ids=None, sample_size=100, reset_flag=True):
# 状態はリセットしておく
if reset_flag == True:
self.reset_state()
N, time_size, input_size = start_data.shape
input_x = start_data
t_test = ans_data
predict_y = []
ans_t = []
count = 0
while len(predict_y) < sample_size:
# 形整える
next_x = self.predict(input_x) # 次のものを予測
# リスト化
next_x = list(next_x.flatten())
input_x = list(input_x.flatten())
# 要素を削除して追加
input_x.pop(0)
input_x.append(next_x[-1])
predict_y.append(next_x[-1])
ans_t.append(t_test[count])
# 形整える(バッチサイズは1)
input_x = np.array(input_x).reshape(1, time_size, input_size)
count += 1
# plt.plot(range(len(t_test)), predict_y, label='pre')
# plt.plot(range(len(t_test)), ans_t, label='ans')
# plt.legend()
# plt.show()
return predict_y, ans_t
def get_state(self):
return self.lstm_layer.h, self.lstm_layer.c
def set_state(self, state):
self.lstm_layer.set_state(*state)
class SimpleRnngen(SimpleRnn):
'''
予測用のクラス
'''
def generate(self, start_data, ans_data, skip_ids=None, sample_size=100, reset_flag=True):
# 状態はリセットしておく
if reset_flag == True:
self.reset_state()
N, time_size, input_size = start_data.shape
input_x = start_data
t_test = ans_data
predict_y = []
ans_t = []
count = 0
while len(predict_y) < sample_size:
# 形整える
next_x = self.predict(input_x) # 次のものを予測
# リスト化
next_x = list(next_x.flatten())
input_x = list(input_x.flatten())
# 要素を削除して追加
input_x.pop(0)
input_x.append(next_x[-1])
predict_y.append(next_x[-1])
ans_t.append(t_test[count])
# 形整える(バッチサイズは1)
input_x = np.array(input_x).reshape(1, time_size, input_size)
count += 1
return predict_y, ans_t
def get_state(self):
return self.rnn_layer.h
def set_state(self, state):
self.rnn_layer.set_state(*state)