はじめに
最近PyCaretを知った自分はその魅力に取りつかれているのでありました(今さら)。
↓前回記事
そんな時、前職の後輩からPyCaretをstreamlitに乗せたいがうまくいかないと連絡が来ました(その後輩は自分の残した糞めんどくさい仕事を見事に片づけてくれた優秀な男。後輩よ、ありがとう!)。そこで自分も遊び半分で手を出したら凝りだしてしまって、それなりの形になったので公開します。
本記事の先駆者たちは以下↓
機能
今回実装した機能は以下です。
・データ解析(動的な散布図、欠損値、データ型、統計値、ヒートマップ、ヒストグラム、ペアプロット)
・回帰モデル構築(構築、チューニング、可視化、検証用データの予測)
・分類モデル構築(構築、チューニング、可視化、検証用データの予測)
アプリ画面
実際のアプリ画面を見てみましょう。以下が立ち上げ画面です。データ解析と機械学習(分類、回帰)をそれぞれページで分けました。ユーザーがselectboxで選択して内部で分岐させることもできるでしょうが、(自分が)コードが分かりやすくなるのでページに分けてみました。

streamlitでのページの作り方は簡単で、メインとなるアプリ(本記事ではapp.py)と同じディレクトリに「peges」というフォルダを作成し、その中に.pyファイルを入れるだけです。簡単ですね。
データ解析画面
サイドバーのデータ解析ボタンを押すと以下のページに遷移します。ここに解析したいcsvファイルをアップロードすると自動で解析が始まります。
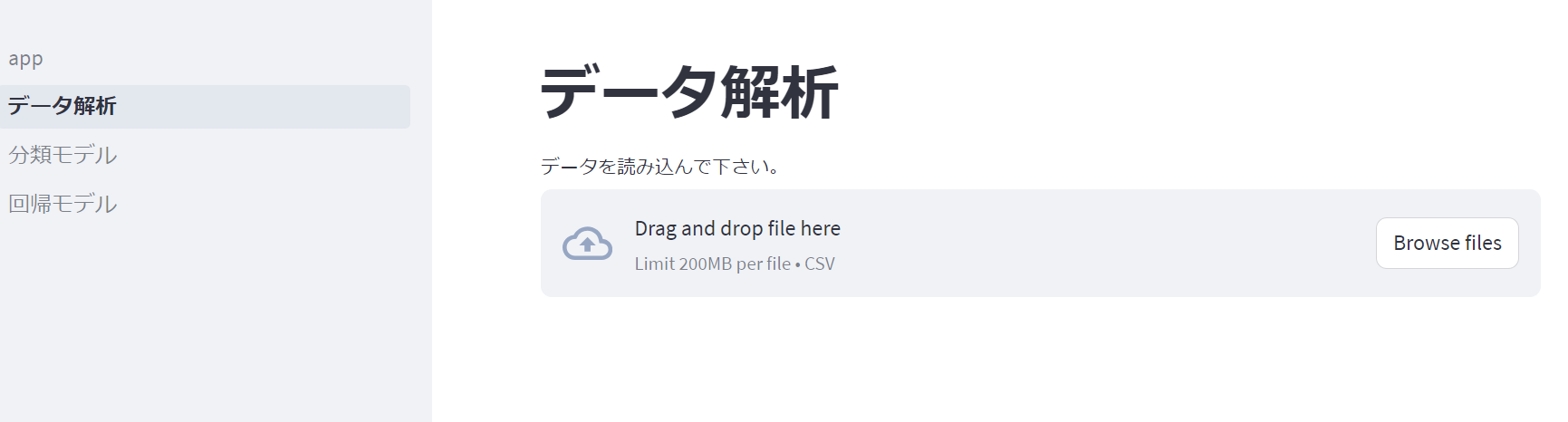
データの確認
本記事ではタイタニック号のデータを用いました。
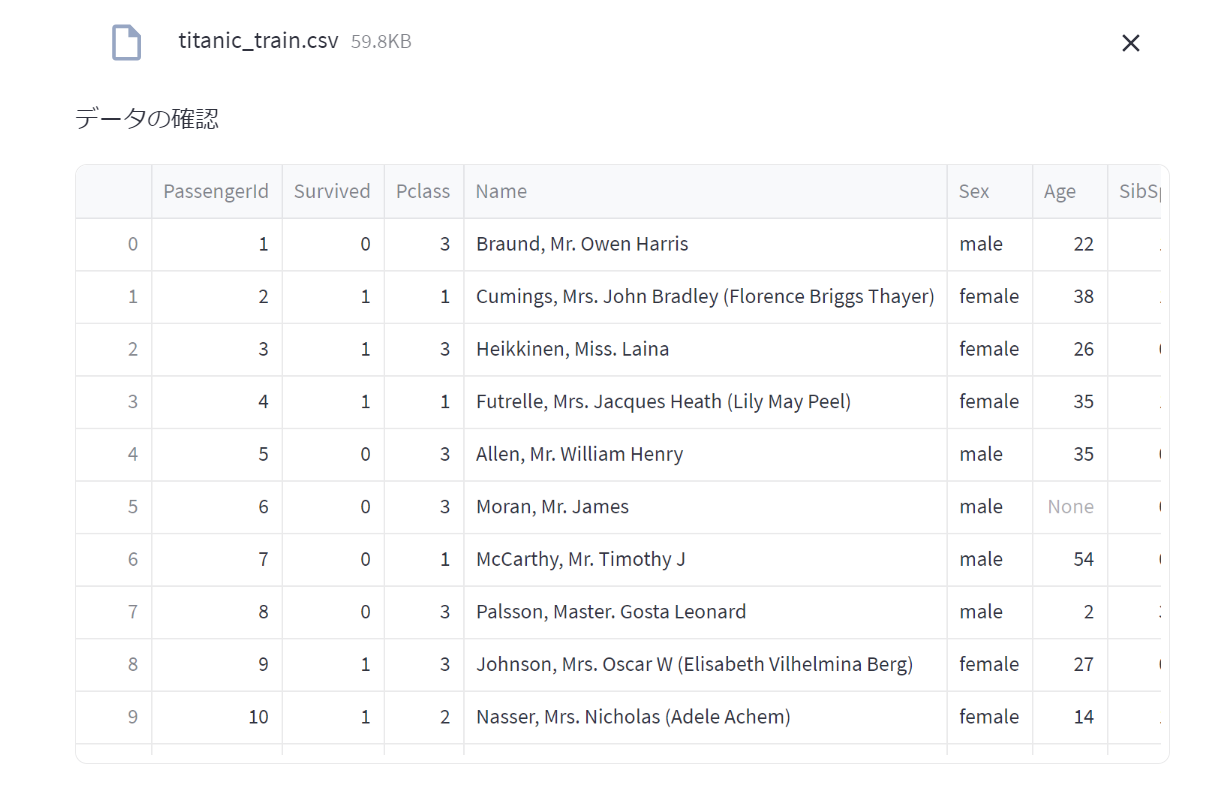
散布図の作成
ユーザーが軸を選択して簡易的に相関を見れるようになっています。
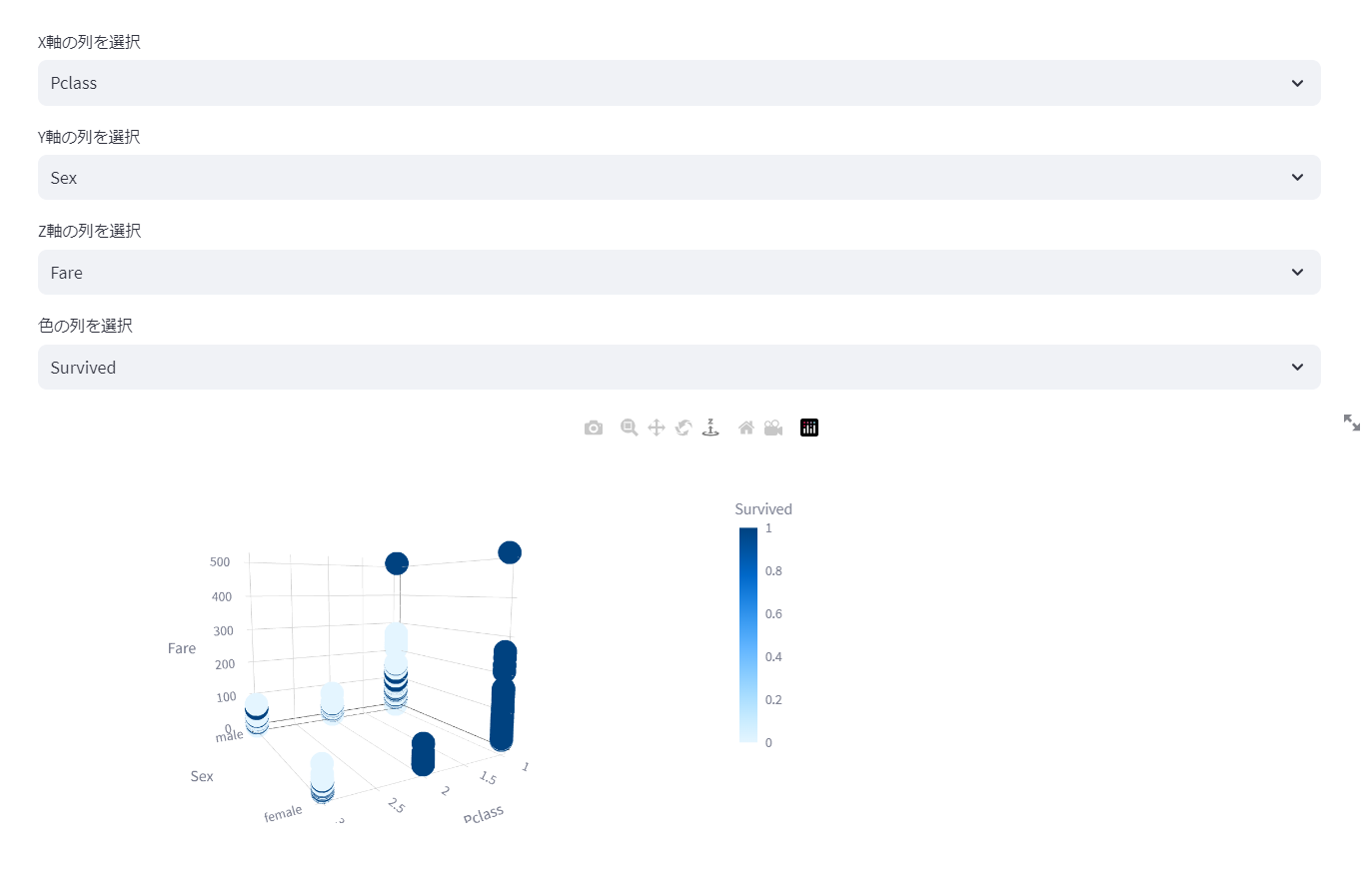
ターゲットの選択
読み込んだデータのカラム名からターゲットを選択します。「EDAの実行」ボタンを押すと解析が始まります。
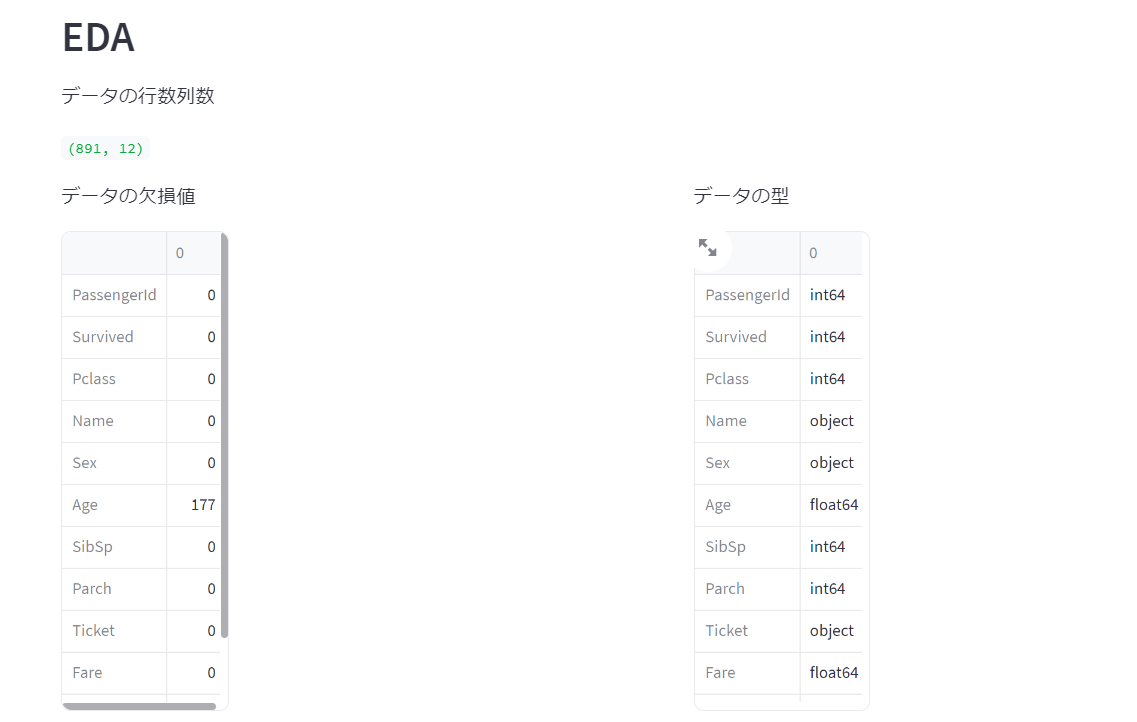
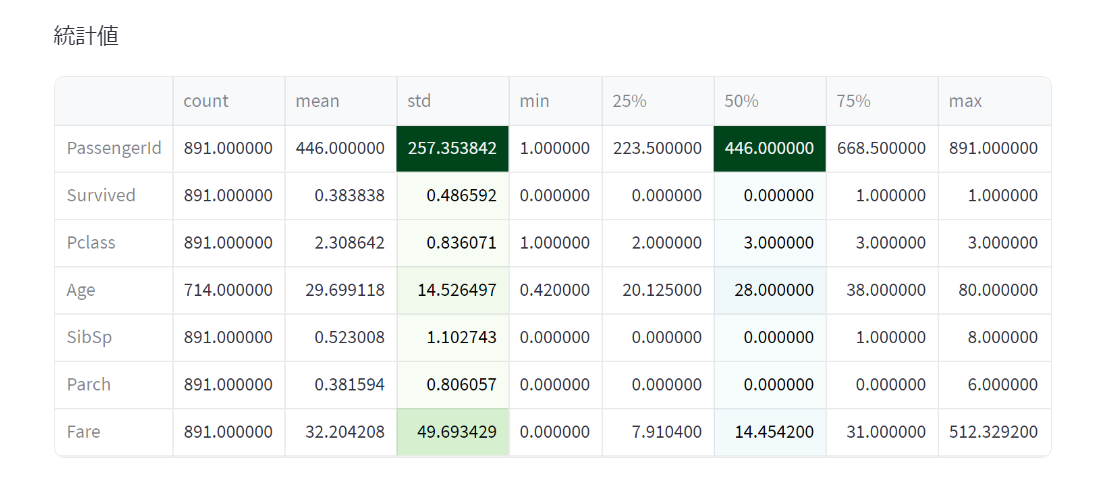
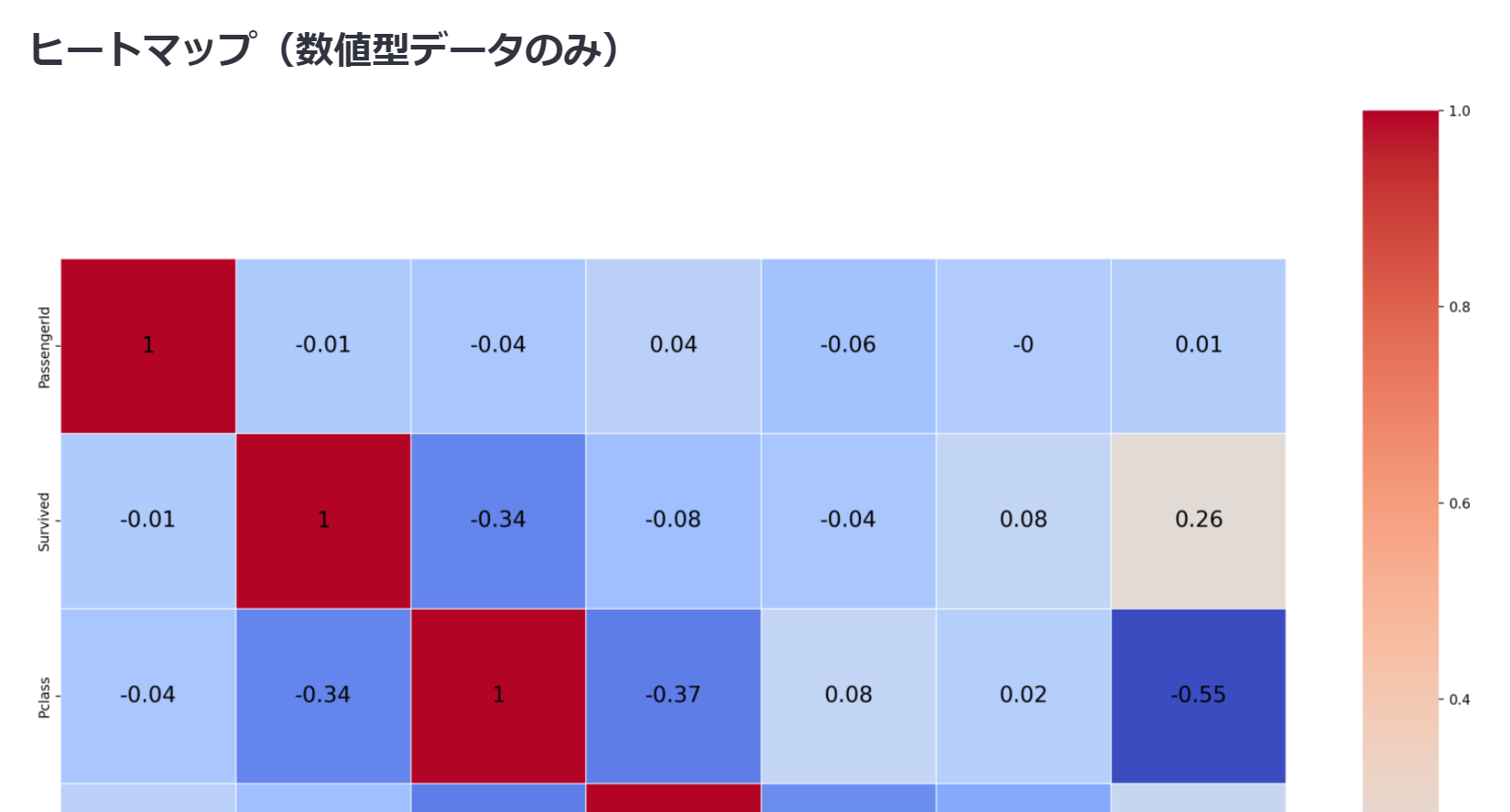
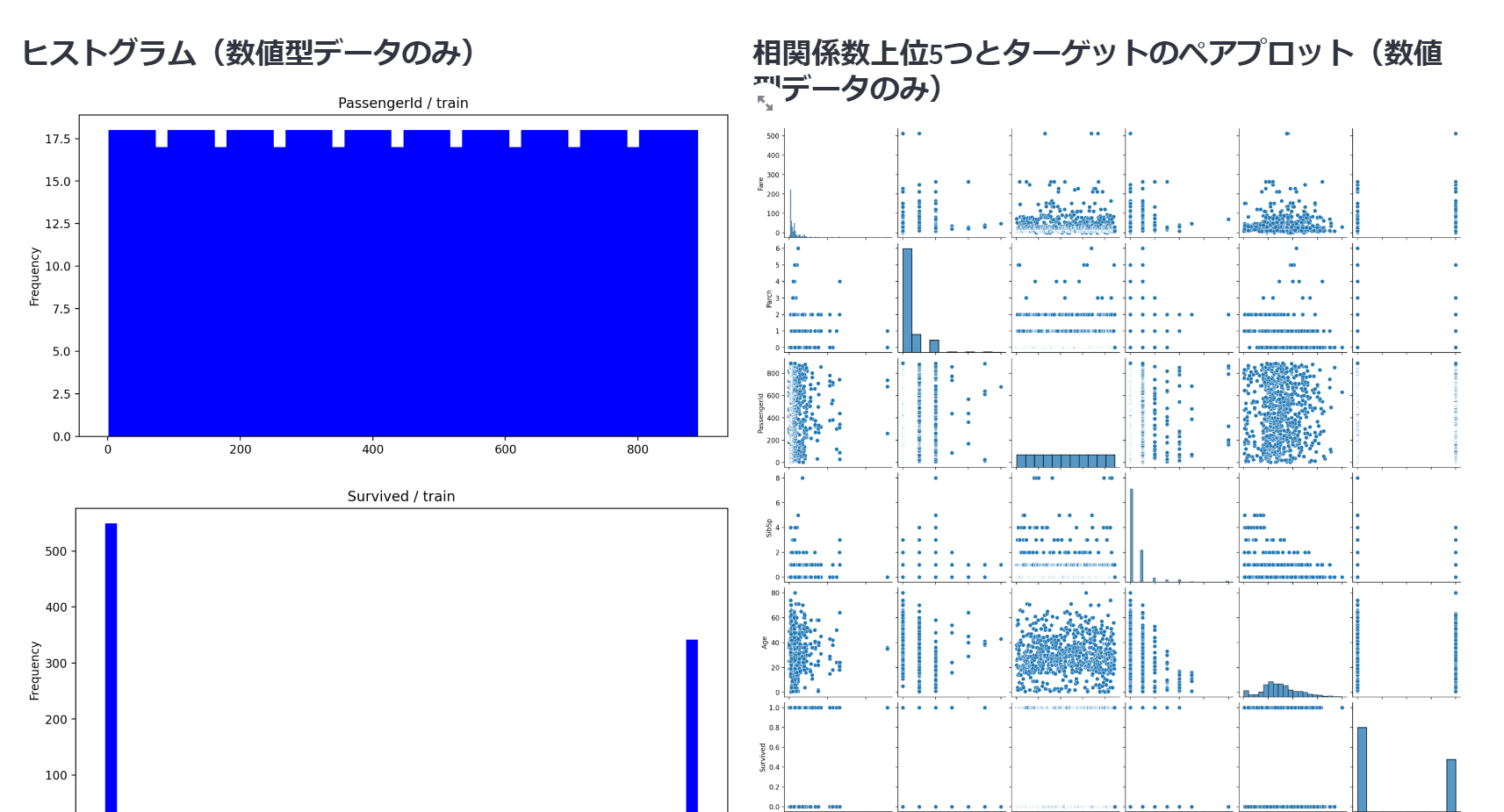
簡易的にデータを眺めることができました。
回帰モデル
サイドバーの「回帰モデル」ボタンを押すと以下のページに遷移します。ここに学習させたいcsvファイルをアップロードします。
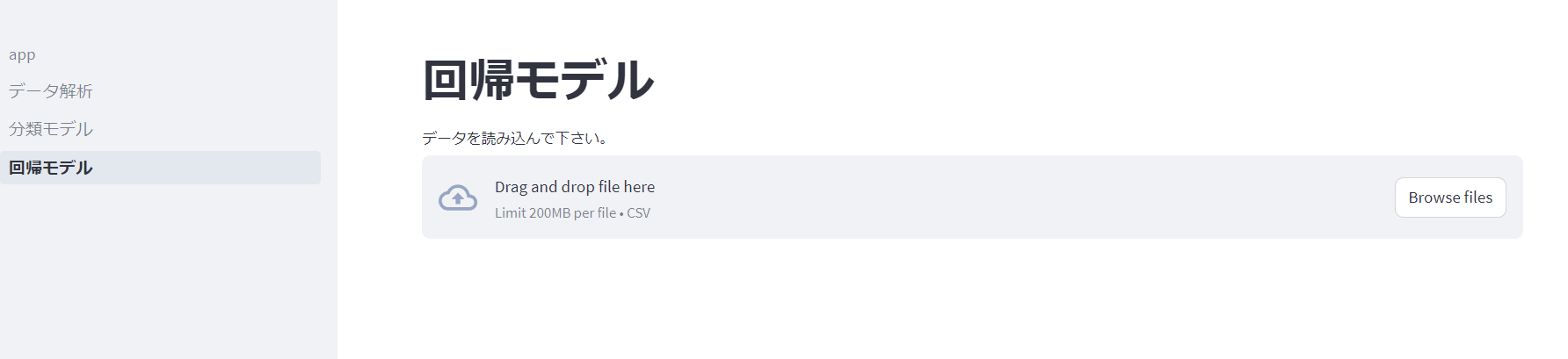
まずはデータの確認とターゲットの選択です。今回は化学者らしく、化合物の沸点のデータセットを用意しました。サイドバーに「回帰モデルをトレーニング」ボタンが出てきますので、ターゲットを選択した後、ボタンを押します。
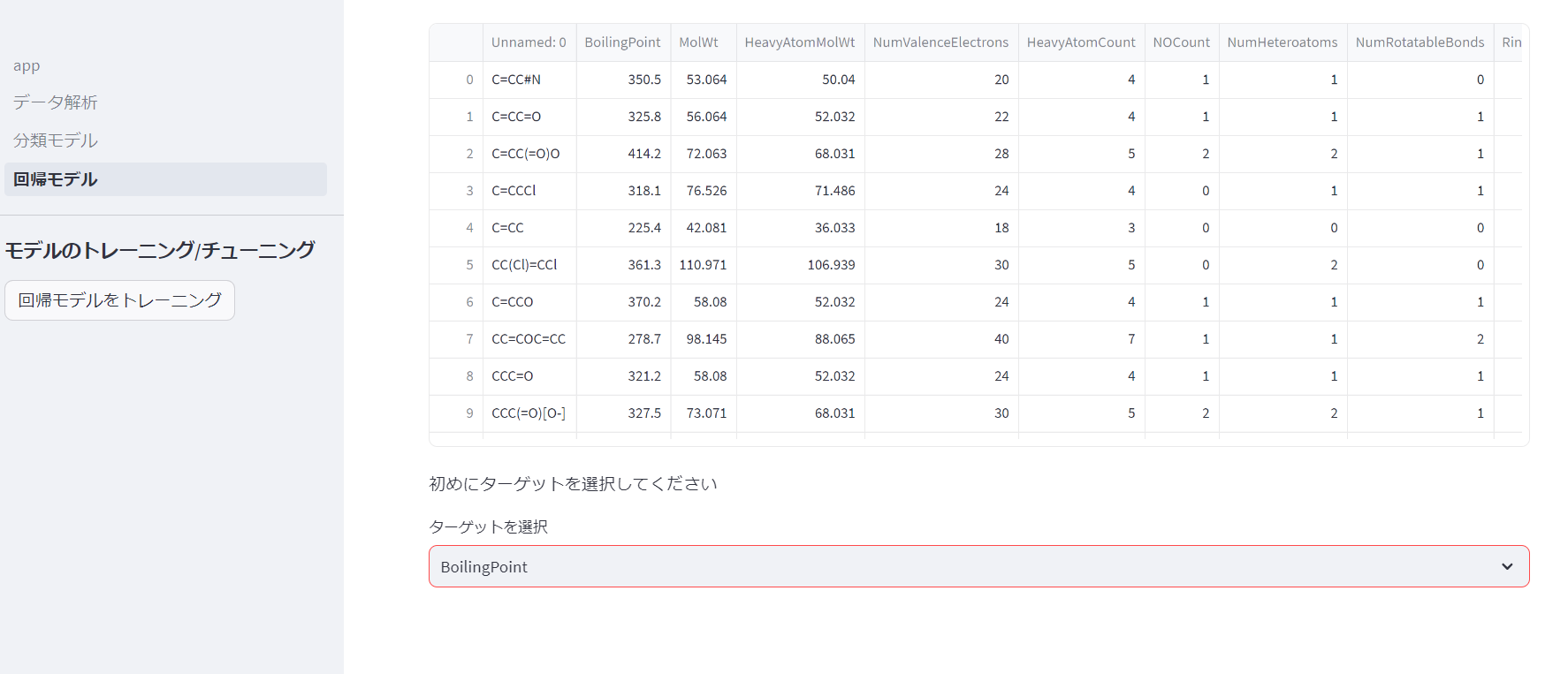
モデルの評価
内部でPyCaretが動作し、複数のモデルを評価してくれます。PyCaretはチューニングもできるので、良さそうなモデルを選んでサイドバーに出現した「モデルをチューニング」ボタンを押します。今回はHuber Regressorがよさそうです。
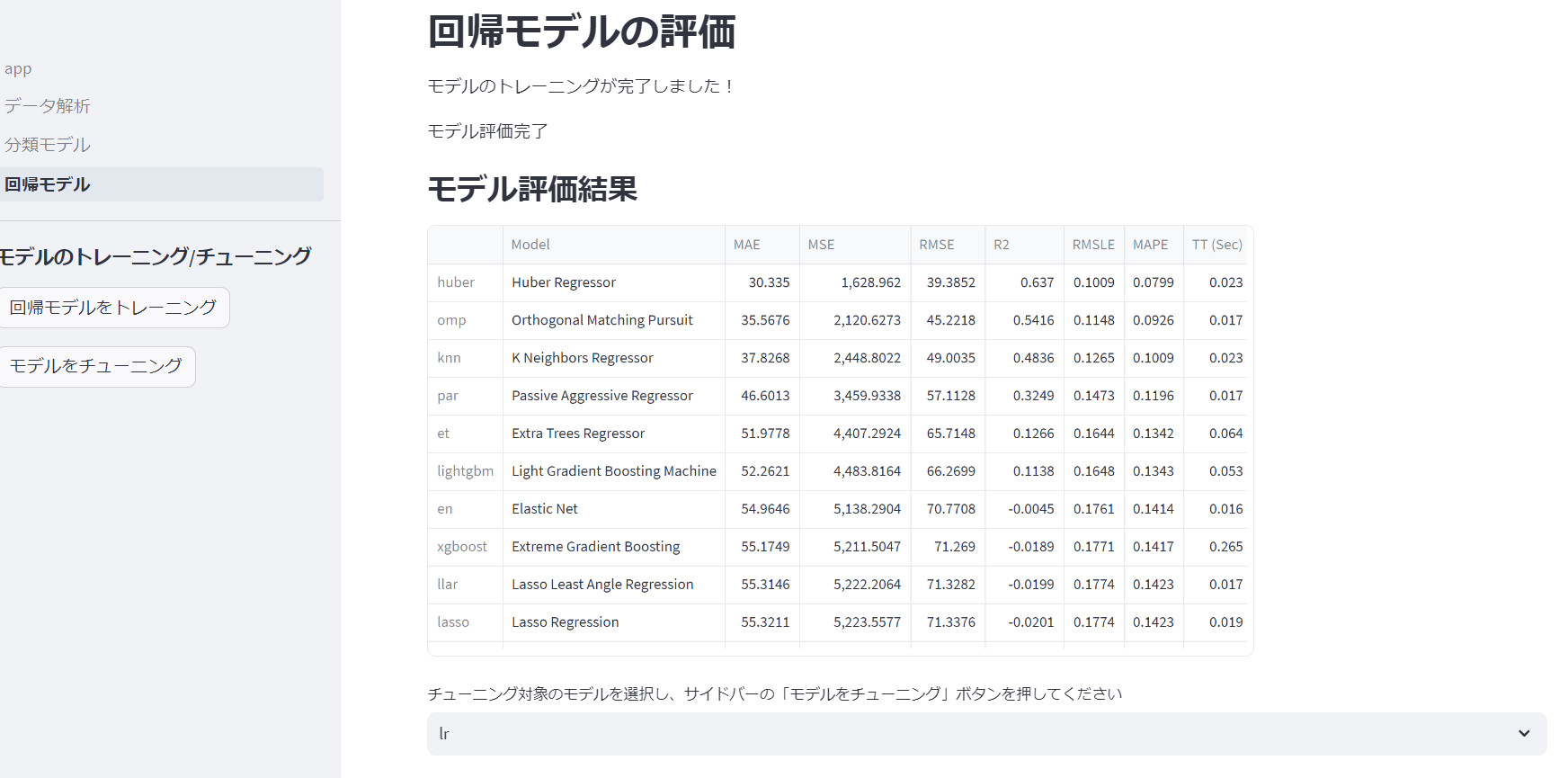
チューニング結果
チューニングした結果R^2値が0.637→0.6395に若干向上しました。その後モデルの可視化と検証用のデータの予測が行えます。モデルは元のモデルか、チューニング後のモデルを選べるようになっています。
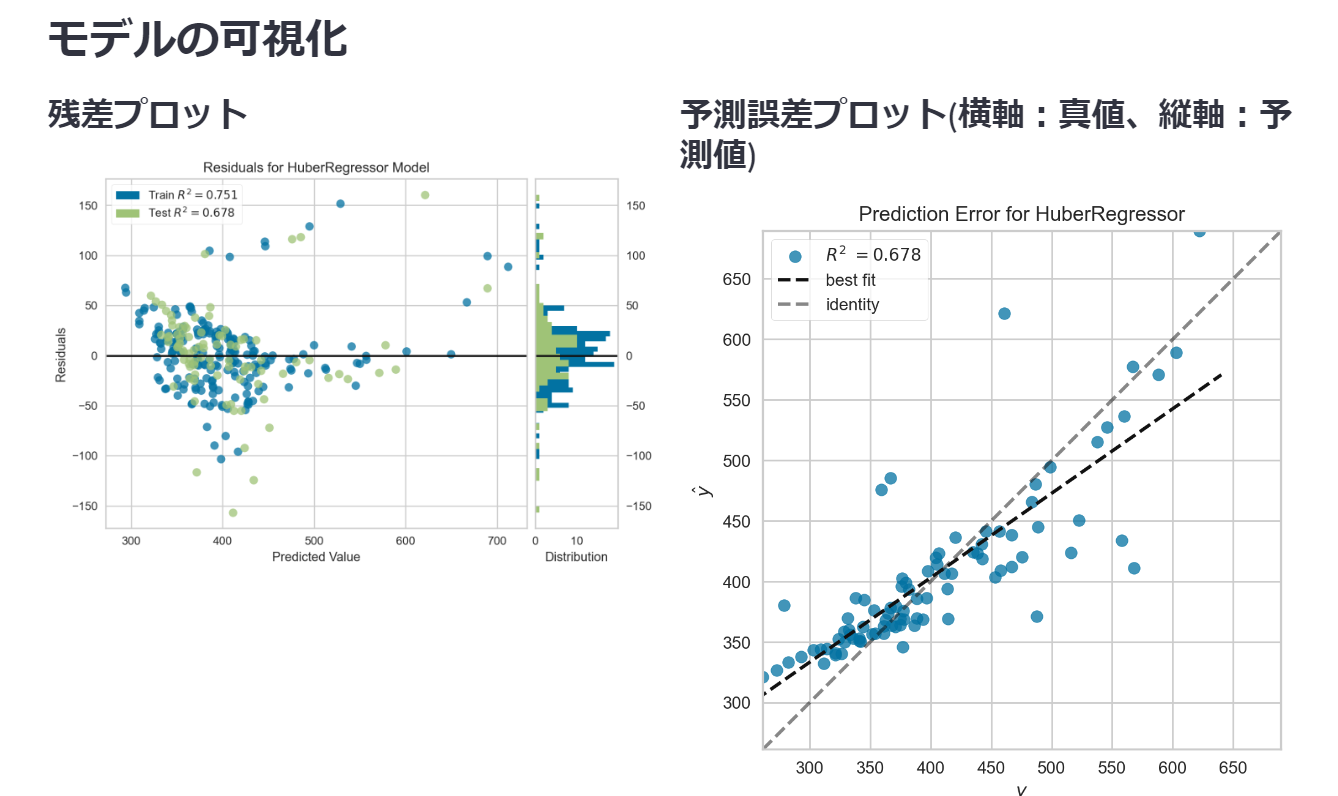
モデルの可視化
streamlit上で可視化できるグラフには制限があります。ここでは残渣プロットと予測誤差プロットを表示しています。
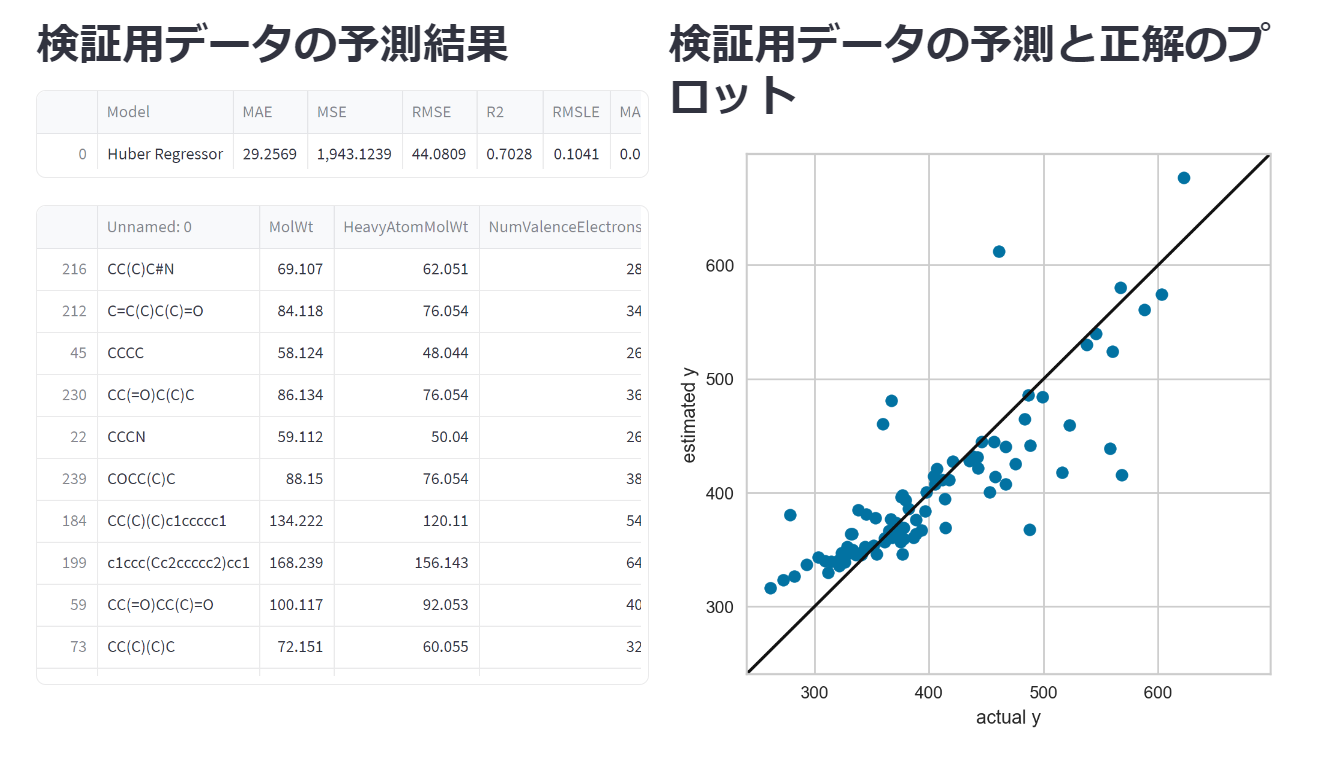
検証用データの予測
検証用データとはPyCaretでsetup関数を用いたときに自動で分割された検証用データです。なお、検証用データ自体はget_config()で取得できます。
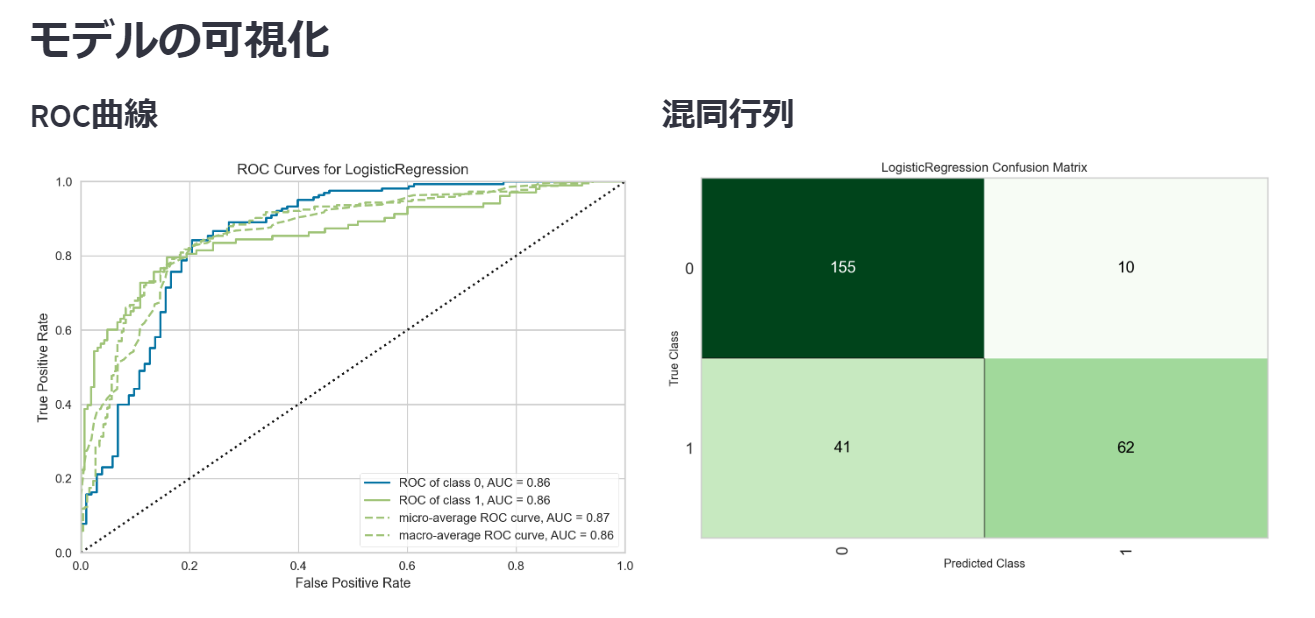
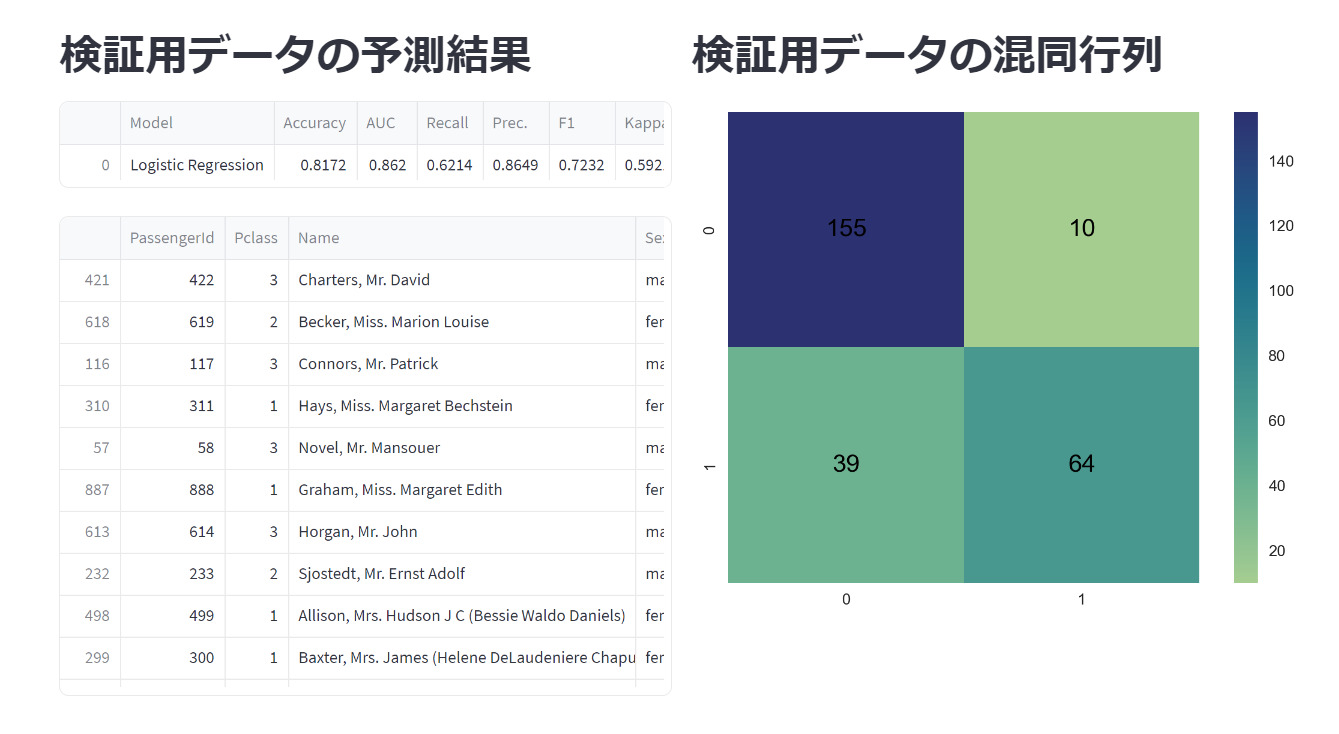
分類モデル
回帰と仕様は変わらないので、前半は割愛します(タイタニック号のデータを用いました)。可視化の部分をROC曲線と混同行列に変更しています。
実際のコード
# Streamlit
import streamlit as st
# EDA
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
@st.cache_data()
def load_data(uploaded_file):
return pd.read_csv(uploaded_file)
def load_and_explore_data():
uploaded_file = st.file_uploader('データを読み込んで下さい。', type=['csv'])
if uploaded_file:
# キャッシュからデータを取得し、存在しない場合は新たにデータをロードしてキャッシュに保存
if "data_cache" in st.session_state:
data = st.session_state.data_cache
else:
data = pd.read_csv(uploaded_file)
st.session_state.data_cache = data
st.write('データの確認')
st.write(data)
st.subheader('散布図')
x_col = st.selectbox("X軸の列を選択", data.columns)
y_col = st.selectbox("Y軸の列を選択", data.columns)
z_col = st.selectbox("Z軸の列を選択", data.columns)
color_col = st.selectbox("色の列を選択", data.columns)
plot_scatter(data, x_col, y_col, z_col, color_col)
target = select_target(data)
if st.button('EDAの実行'):
explore_data(data, target)
def plot_scatter(data, x_col, y_col, z_col, color_col):
fig = px.scatter_3d(data, x=x_col, y=y_col, z=z_col, color=color_col)
st.plotly_chart(fig)
def select_target(data):
st.write("初めにターゲットを選択してください")
target = st.selectbox("ターゲットを選択", data.columns)
return target
def explore_data(data, target):
st.header('EDA')
st.write('データの行数列数')
st.write(data.shape)
column1, column2 = st.columns(2)
with column1:
st.write('データの欠損値')
st.write(data.isnull().sum())
with column2:
st.write('データの型')
st.write(data.dtypes)
st.write('統計値')
st.write(data.describe().T
.style.bar(subset=['mean'], color=px.colors.qualitative.G10[1])
.background_gradient(subset=['std'], cmap='Greens')
.background_gradient(subset='50%', cmap='BuGn')
)
cols = data.select_dtypes(include=['int', 'float']).columns
st.subheader('ヒートマップ(数値型データのみ)')
st.pyplot(heat(data, cols))
col1, col2 = st.columns(2)
with col1:
st.subheader('ヒストグラム(数値型データのみ)')
for col in cols:
st.pyplot(create_histogram(data, col))
with col2:
st.subheader('相関係数上位5つとターゲットのペアプロット(数値型データのみ)')
st.pyplot(pair_plot(data, target, cols))
def heat(data, cols):
corr = data[cols].corr().round(2)
plt.figure(figsize=(20, 20))
sns.heatmap(corr, linewidths=0.1, vmax=1, square=True, annot=True, cmap='coolwarm', linecolor='white', annot_kws={'fontsize': 16, 'color':'black'})
return plt
def create_histogram(data, col):
plt.figure(figsize=(10, 5))
data[col].plot(kind='hist', bins=50, color='blue')
plt.title(col + ' / train')
return plt
def pair_plot(data, target, cols):
correlation_matrix = data[cols].corr()
top_features = correlation_matrix[target].sort_values(ascending=False)[1:6]
selected_features = top_features.index.tolist() + [target]
sns.pairplot(data[selected_features])
# Streamlitアプリケーションの実行
st.set_page_config(page_title='データ解析', layout='wide')
st.set_option('deprecation.showPyplotGlobalUse', False)
st.title('データ解析')
load_and_explore_data()
# Streamlit
import streamlit as st
# EDA
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.figure as figure
# ML
from pycaret.regression import *
def load_and_explore_data():
uploaded_file = st.file_uploader('データを読み込んで下さい。', type=['csv'])
if uploaded_file:
# キャッシュからデータを取得し、存在しない場合は新たにデータをロードしてキャッシュに保存
if "data_cache" in st.session_state:
data = st.session_state.data_cache
else:
data = pd.read_csv(uploaded_file)
st.session_state.data_cache = data
st.write('データの確認')
st.write(data)
target = select_target(data)
# if st.button('回帰モデルの構築'):
train_and_tune_regression_model(data, target)
def select_target(data):
st.write("初めにターゲットを選択してください")
target = st.selectbox("ターゲットを選択", data.columns)
return target
def train_and_tune_regression_model(data, target):
st.sidebar.subheader("モデルのトレーニング/チューニング")
if st.sidebar.button("回帰モデルをトレーニング"):
st.header("回帰モデルの評価")
# PyCaret Regression Setup
reg_setup = setup(data, target=target, session_id=0)
model_results = train_regression_model()
st.session_state.model_results = model_results
# session_stateにモデルの結果が保存されている場合、その結果を表示する
if "model_results" in st.session_state:
st.subheader("モデル評価結果")
st.write(st.session_state.model_results)
# 利用可能なモデルの略称とフルネームを定義
abbreviations = ["lr", "lasso", "ridge", "en", "lar", "llar", "omp", "br", "par", "huber", "knn", "dt", "rf", "et", "ada", "gbr", "lightgbm", "dummy"]
model_names = ["Linear Regression", "Lasso Regression", "Ridge Regression", "Elastic Net", "Least Angle Regression", "Lasso Least Angle Regression", "Orthogonal Matching Pursuit", "Bayesian Ridge", "Passive Aggressive Regressor", "Huber Regressor", "K Neighbors Regressor", "Decision Tree Regressor", "Random Forest Regressor", "Extra Trees Regressor", "AdaBoost Regressor", "Gradient Boosting Regressor", "Light Gradient Boosting Machine", "Dummy Regressor"]
# モデルの略称とフルネームを対応させる辞書を作成
model_dict = dict(zip(abbreviations, model_names))
selected_model_abbreviation = st.selectbox("チューニング対象のモデルを選択し、サイドバーの「モデルをチューニング」ボタンを押してください", abbreviations)
st.session_state.selected_model_abbreviation = selected_model_abbreviation
if st.sidebar.button("モデルをチューニング"):
st.session_state.selected_model = create_model(st.session_state.selected_model_abbreviation)
tuned_results = tune_regression_model(st.session_state.selected_model)
st.session_state.tuned_results = tuned_results
if "tuned_results" in st.session_state:
st.subheader("チューニング結果")
st.write(st.session_state.tuned_results)
selected_models = select_model()
st.session_state.final_regressioned_model = finalize_regression_model(selected_models)
if st.sidebar.button("モデルの可視化"):
display_model(selected_models)
if st.sidebar.button("検証用データの予測"):
col1, col2 = st.columns(2)
with col1:
return_prediction_model = prediction_model(st.session_state.final_regressioned_model)
with col2:
st.pyplot(display_prediction(return_prediction_model))
def train_regression_model():
# モデルトレーニングと比較 (すべてのモデルを評価)
with st.spinner("モデルトレーニング中..."):
compare_model = compare_models()
st.write("モデルのトレーニングが完了しました!")
# モデルの評価と結果
model_results = pull()
st.write("モデル評価完了")
return model_results
def tune_regression_model(model):
with st.spinner("モデルチューニング中..."):
st.session_state.tuned_model = tune_model(model)
st.write("モデルのチューニングが完了しました!")
# チューニング結果を取得
tuned_results = pull()
return tuned_results
def select_model():
st.write("元のモデルか、チューニング後のモデルか選択してください。可視化をする場合はサイドバーの「モデルの可視化」ボタンを押してください。")
model_choices = ["元のモデル", "チューニング後のモデル"]
selected_choice = st.selectbox("モデルを選択", model_choices)
# 選択に応じてモデルを返す
if selected_choice == "元のモデル":
return st.session_state.selected_model
else:
return st.session_state.tuned_model
def finalize_regression_model(model):
with st.spinner("モデル構築中"):
st.session_state.final_regression_model = finalize_model(model)
st.write("モデルの構築が完了しました!")
return st.session_state.final_regression_model
def prediction_model(model):
st.header('検証用データの予測結果')
prediction = predict_model(model)
model_evaluation = pull()
st.write(model_evaluation)
st.write(prediction)
return prediction
def display_model(model):
st.header('モデルの可視化')
col1, col2 = st.columns(2)
with col1:
st.subheader('残差プロット')
plot_model(model, scale = 1, display_format="streamlit")
with col2:
st.subheader('予測誤差プロット(横軸:真値、縦軸:予測値)')
plot_model(model, plot='error', display_format="streamlit")
plot_model(model, plot='feature', display_format="streamlit")
def display_prediction(prediction):
st.header('検証用データの予測と正解のプロット')
y_test = get_config('y_test')
plt.rcParams['font.size'] = 5
plt.figure(figsize=figure.figaspect(1))
plt.scatter(y_test, prediction.iloc[:, -1])
y_max = max(y_test.max(), prediction.iloc[:, -1].max())
y_min = min(y_test.min(), prediction.iloc[:, -1].min())
y_upper = y_max + 0.05 * (y_max - y_min)
y_lower = y_min - 0.05 * (y_max - y_min)
plt.plot([y_lower, y_upper], [y_lower, y_upper], 'k-')
plt.ylim(y_lower, y_upper)
plt.xlim(y_lower, y_upper)
plt.xlabel('actual y')
plt.ylabel('estimated y')
return plt
def estimate_model(model, test_data):
estimate_target = predict_model(model, test_data)
return estimate_target
# Streamlitアプリケーションの実行
st.set_page_config(page_title='回帰モデル', layout='wide')
st.set_option('deprecation.showPyplotGlobalUse', False)
st.title('回帰モデル')
load_and_explore_data()
# Streamlit
import streamlit as st
# EDA
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import metrics
# ML
from pycaret.classification import *
@st.cache_data()
def load_data(uploaded_file):
return pd.read_csv(uploaded_file)
def load_and_explore_data():
uploaded_file = st.file_uploader('データを読み込んで下さい。', type=['csv'])
if uploaded_file:
# キャッシュからデータを取得し、存在しない場合は新たにデータをロードしてキャッシュに保存
if "data_cache" in st.session_state:
data = st.session_state.data_cache
else:
data = pd.read_csv(uploaded_file)
st.session_state.data_cache = data
st.write('データの確認')
st.write(data)
target = select_target(data)
# if st.button('分類モデルの構築'):
train_and_tune_classification_model(data, target)
def select_target(data):
st.write("初めにターゲットを選択してください")
target = st.selectbox("ターゲットを選択", data.columns)
return target
def train_and_tune_classification_model(data, target):
st.sidebar.subheader("モデルのトレーニング/チューニング")
if st.sidebar.button("分類モデルをトレーニング"):
st.header("分類モデルの評価")
# PyCaret classification Setup
reg_setup = setup(data, target=target, session_id=0)
model_results = train_classification_model()
st.session_state.model_results = model_results
# session_stateにモデルの結果が保存されている場合、その結果を表示する
if "model_results" in st.session_state:
st.subheader("モデル評価結果")
st.write(st.session_state.model_results)
# 利用可能なモデルの略称とフルネームを定義
abbreviations = ["ridge", "lda", "gbc", "ada", "lightgbm", "rf", "et", "lr", "knn", "dt", "sym", "qda", "nb", "dummy", "xgboost"]
model_names = ["Ridge Classifier", "Linear Discriminant Analysis", "Gradient Boosting Classifier", "Ada Boosting Classifier", "Light Gradient Boosting Machine", "Random Forest Classifier", "Extra Trees Classifier", "Logistic Regression", "K Neighbors Classifier", "Decision Tree Classifier", "SVM - Liniear Kernel", "Quadratic Discriminant Analysis", "Naive Bayes", "Dummy Regressor", "Extreme Gradient Boosting"]
# モデルの略称とフルネームを対応させる辞書を作成
model_dict = dict(zip(abbreviations, model_names))
selected_model_abbreviation = st.selectbox("チューニング対象のモデルを選択し、サイドバーの「モデルをチューニング」ボタンを押してください", abbreviations)
st.session_state.selected_model_abbreviation = selected_model_abbreviation
if st.sidebar.button("モデルをチューニング"):
st.session_state.selected_model = create_model(st.session_state.selected_model_abbreviation)
tuned_results = tune_classification_model(st.session_state.selected_model)
st.session_state.tuned_results = tuned_results
if "tuned_results" in st.session_state:
st.subheader("チューニング結果")
st.write(st.session_state.tuned_results)
selected_models = select_model()
final_classification_model = finalize_classification_model(selected_models)
if st.sidebar.button("モデルの可視化"):
display_model(selected_models)
if st.sidebar.button("検証用データの予測"):
col1, col2 = st.columns(2)
with col1:
return_prediction_model = prediction_model(final_classification_model)
with col2:
st.pyplot(display_prediction(return_prediction_model, target))
def train_classification_model():
# モデルトレーニングと比較 (すべてのモデルを評価)
with st.spinner("モデルトレーニング中..."):
compare_model = compare_models()
st.write("モデルのトレーニングが完了しました!")
# モデルの評価と結果
model_results = pull()
st.write("モデル評価完了")
return model_results
def tune_classification_model(model):
with st.spinner("モデルチューニング中..."):
st.session_state.tuned_model = tune_model(model)
st.write("モデルのチューニングが完了しました!")
# チューニング結果を取得
tuned_results = pull()
return tuned_results
def select_model():
st.write("元のモデルか、チューニング後のモデルか選択してください。可視化をする場合はサイドバーの「モデルの可視化」ボタンを押してください。※選択したモデルによっては可視化に対応していません。")
model_choices = ["元のモデル", "チューニング後のモデル"]
selected_choice = st.selectbox("モデルを選択", model_choices)
# 選択に応じてモデルを返す
if selected_choice == "元のモデル":
return st.session_state.selected_model
else:
return st.session_state.tuned_model
def finalize_classification_model(model):
with st.spinner("モデル構築中"):
st.session_state.final_classification_model = finalize_model(model)
st.write("モデルの構築が完了しました!")
return st.session_state.final_classification_model
def prediction_model(model):
st.header('検証用データの予測結果')
prediction = predict_model(model)
model_evaluation = pull()
st.write(model_evaluation)
st.write(prediction)
return prediction
def display_model(model):
st.header('モデルの可視化')
col1, col2 = st.columns(2)
with col1:
st.subheader('ROC曲線')
plot_model(model, scale = 1, display_format="streamlit")
with col2:
st.subheader('混同行列')
plot_model(model, plot='confusion_matrix', display_format="streamlit")
def display_prediction(prediction, target):
st.header('検証用データの混同行列')
y_test = get_config('y_test')
class_types = list(set(y_test))
class_types.sort()
confusion_matrix_val = pd.DataFrame(metrics.confusion_matrix(y_test, prediction.iloc[:, -2], labels=class_types))
confusion_matrix_val.index = class_types
confusion_matrix_val.columns = class_types
sns.heatmap(confusion_matrix_val, square=True, fmt=".0f",annot=True, cmap='crest', annot_kws={'fontsize': 16, 'color':'black'})
return plt
# Streamlitアプリケーションの実行
st.set_page_config(page_title='分類モデル', layout='wide')
st.set_option('deprecation.showPyplotGlobalUse', False)
st.title('分類モデル')
load_and_explore_data()
ポイントはstreamlitの仕様上、ユーザーがボタン操作やセレクトボックスの操作を行うと、リロードされてしまう点です。st.session_stateで対応しました(一番苦労しました・・・過剰に使いすぎている感は否めません)。
そして全体的に粗い・・・まだまだ整理が必要ですね。
おわりに
最後までご覧いただきありがとうございます!!streamlitでPyCaretを動かしているだけなので、コードはご自由にお使いください(でもこの記事を引用して下さいね☆)
EDAに関してはPyCaretでもできるようですが、streamlitへ乗せるには苦労しそうなので、今回はmatplotlib、seaborn、plotlyで対応しました。おそらくHTMLに吐き出して、streamlitに埋め込む形にすればできそうなので(知らんけど)、時間があればやってみます。
あとはデータ解析のグラフを増やしたり、テストデータの予測機能を付けたり、ハイパーパラメータを選択できるようにしたり、UIももっと凝りたいetc...(そんな時間は無い)。
PyCaretをstreamlitで動かしたい男②はいつになることやら。
それでは次の記事でお会いしましょう~。