はじめに
第2回に引き続き時系列データを勉強していきます。
第1回(データの前処理)
第2回(LightGBMモデルの構築、Pycaretによるアンサンブルモデルの構築)
第3回(Prophetによる時系列モデルの構築、アンサンブル学習)
Prophetモデル構築
時系列モデルとしてFacebookが開発したProphetを選択しました。なぜなら、実装が容易だからです←大事。
インスタンスを作ってfitするだけなので、まるでscikit-learnの様に使えます。
早速実装していきます。訓練データとテストデータは第2回でPycaretにより欠損値補完をしたデータを使用します。Pycaretでのデータの取り出しは、setupした後、get_config('dataset_transformed')で取り出すことができます。
まずはデータを少しいじります。Prophetは自動的に年、月、日等のデータを特徴量として作成しますので、重複しそうな特徴量は削除しておきます(もちろん精度と相談しながら)。
※Pycaretで欠損値補完を行ったので、カラム名がnum_imputer_hogehogeとなっています。
def crean_data(data):
data.drop(['num_imputer__year','num_imputer__month', 'num_imputer__day', 'num_imputer__day_of_week', 'num_imputer__quarter', 'num_imputer__is_holiday', 'num_imputer__is_wknd'], axis=1, inplace=True)
return data
train_data = crean_data(train_data)
test_data = crean_data(test_data)
では、実装していきます。ポイントは以下です。
・Prophetを実装する際の決まり事として、日付のカラム名を'ds'、目的変数を'y'とする必要があります。
・インスタンス化の際に、seasonality_mode='multiplicative'引数を渡しています。これにより「増加する周期性」に対応することができます(社会的に引っ越し数が伸びているだろうということ、一方、企業としても業績が伸びているので、年々受注件数が増えていることをモデルに組み込んでもらいます)。詳細は以下記事↓
・def crean_data()で削除した特徴量以外の特徴量はすべてモデルに組み込む
from prophet import Prophet
from prophet.plot import add_changepoints_to_plot, plot_components
import matplotlib.pyplot as plt
# Prophet用のデータフレームを準備
train_df_prophet = train_data.copy()
train_df_prophet['ds'] = pd.to_datetime(train_df_prophet['datetime'])
train_df_prophet = train_df_prophet.drop('datetime', axis=1)
# モデルのインスタンス化
model = Prophet(seasonality_mode='multiplicative')
# 追加のレグレッサ(特徴量)をモデルに追加(yとdsを除くすべての列)
for column in train_df_prophet.columns.drop(['ds', 'y']):
model.add_regressor(column)
# モデルの学習
model.fit(train_df_prophet)
# テストデータの準備
test_df = test_data.copy()
test_df['ds'] = pd.to_datetime(test_df['datetime'])
test_df = test_df.drop('datetime', axis=1)
future = pd.concat([train_df_prophet, test_df]) # テストデータとの結合
# 予測
forecast = model.predict(future)
# 変化点のプロット
fig = model.plot(forecast)
add_changepoints_to_plot(fig.gca(), model, forecast)
# コンポーネントのプロット
fig2 = plot_components(model, forecast)
plt.show()
実行結果:
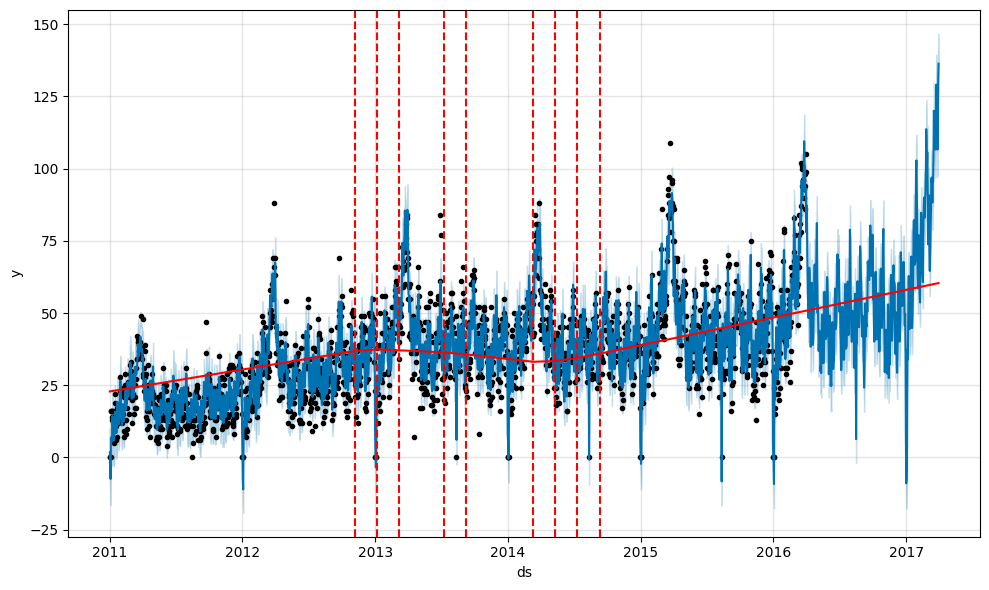
赤実線がトレンド、赤点線がトレンドの変化点となっています。テストデータの予測を見ると、上昇トレンド、及び「増加する周期性」もとらえられているように思えます。
続いて、fig2で各コンポーネントも確認しましょう。
実行結果:
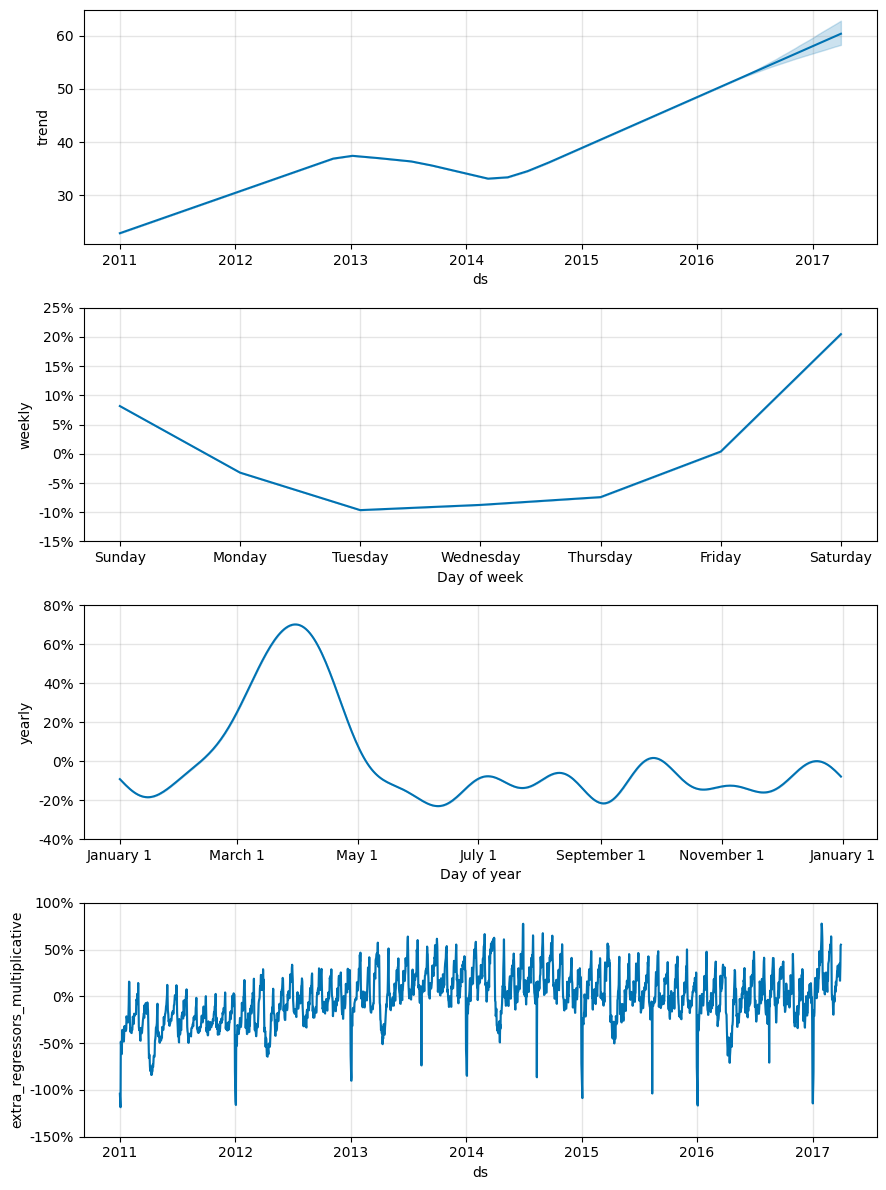
・trendでは、上昇傾向をとらえています
・weeklyでは、週末に引っ越し数が多いことをとらえています
・yealyでは、3月~5月にかけて引っ越し数が多いことをとらえています
簡単な実装でここまでのモデルができるとは、さすがFacebookですね!
この予測結果を投稿したところ、
暫定評価(MAE):8.7118209
でした。随分と精度が上がり、この時点で60位くらいまで上がりました。
やはり、上昇トレンド、及び「増加する周期性」をとらえられるかがキモなのかもしれません。
さらに精度を上げるにはハイパーパラメータのチューニングが必要なのでしょうが、そこまで手を出せていないのが現状です。
どうやらoptunaでもハイパーパラメータのチューニングができるみたいなので、今後の課題です。
アンサンブル学習
最後にアンサンブル学習をして汎化性能を上げてみます。
まずは、LightGBM、Pycaret(Extra Trees + Gradient Boosting + Random Forest)、Prophetのテストデータの予測を比較してみます。
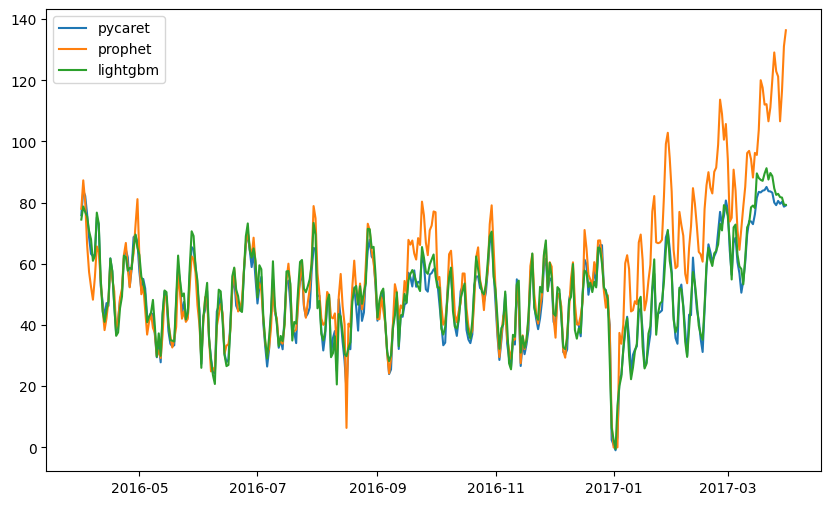
比較してみるとより明らかですが、1月~3月末にかけての上昇トレンドをProphetはとらえているようです(過剰評価の可能性も)。
というわけで、以下の作戦でテキトーに重みづけしました(ちょっとスタッキングはうまくいかなかったので、重みを手動調整)。
ここは精度を見ながら微調整です・・・(;'∀')
①LightGBMは精度が低いので除外
②Pycaretがとらえきれないトレンド(1月~4月あたり)はProphetに多く重みづけ
③その他の期間はProphetにやや重みづけ
hogeにテキトーな小数点、fugaにテキトーな月を入れて手当たり次第に試しました。
start_date = pd.to_datetime('2016-04-01')
end_date = pd.to_datetime('2017-03-31')
prophet_weight_periods = [
(pd.to_datetime('2016-04-01'), pd.to_datetime('2016-fuga-30')),
(pd.to_datetime('2017-fuga-01'), end_date)
]
# 重み付けパラメータを日付ごとに設定
date_range = pd.date_range(start_date, end_date)
weights = pd.Series(hoge, index=date_range)
for start, end in prophet_weight_periods:
weights.loc[start:end] = hoge
# ブレンド後の予測値を計算
blended_preds = weights * prophet_prediction['prediction_prophet'] + (1 - weights) * pycaret_prediction['prediction_pycaret']
blended_preds = blended_preds.reindex(date_range, fill_value=pd.NA)
blended_preds = pd.DataFrame(blended_preds)
blended_preds.columns = ['prediction_blended']
ブレンドした結果が以下の通りです。
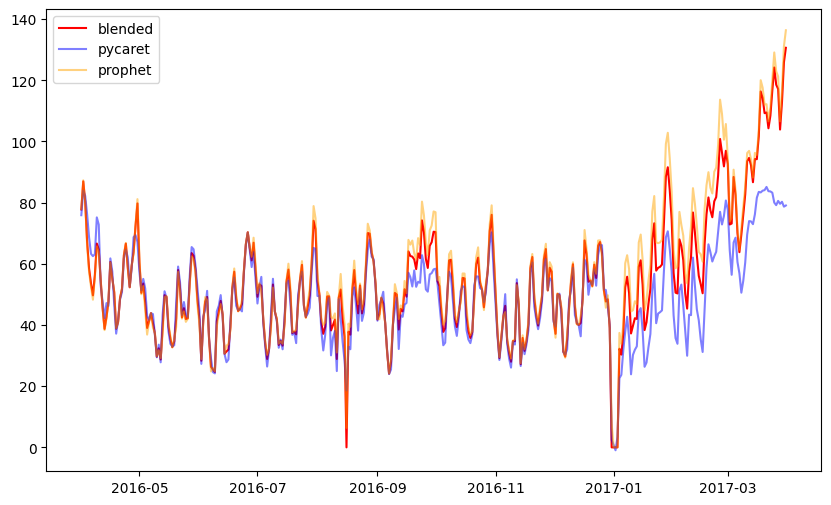
微調整を繰り返した結果、
暫定評価(MAE):7.9224279
まで精度が上がりました!これで17位です。
おわりに
いかがでしたでしょうか。最後のアンサンブルは美しくない方法でしたが、時系列素人ながら上位の成績を収めることができました。
ただ、Prophetはポテンシャルをまだまだ引き出せていないし、解析も甘い・・・。今後もたくさんいじってProphetと親友になれるよう精進します。
この記事がどなたかの参考になれば幸いです!
それでは次の記事でお会いしましょう('ω')ノ