こんにちは。Electric Blue Industries Ltd.のマッツです。
note: All works and figures in this captured image are copyrighted to NVIDIA
そろそろDeep Learning作業においてGPUをうまく安く効率的に使っていかなくてはと考え、先ほど(日本時間 3月8日 04:00-05:00)にNVIDIAさんのNGC(NVIDIA GPU CLOUD)の説明ウェビナーをに参加して、これを機会にして、自分はどのような作業環境でDeep Learning作業を行っていくのが効率が良い(作業と思考のシンプルさ・環境の安定度・コストパフォーマンス)のか考えたので、皆さんのご意見も聞きたく投稿します。雑記です。
私自身の会社は小規模事業者であり、Deep Learningにつき次々と変化・進歩が起きている現状では大企業のように大きな投資を先行して大きなリターンを期待するというアプローチをしたくはない状況であり、多くの皆さんが個人として持っている「初めから数十万円も使いたくない」かつ「従量課金で請求書を見て目ん玉飛び出たくもない」と同時に感じる微妙な状況です。できるだけコストを下げ、なおかつコストとリターンのタイミングを近づけたい。ちなみに、現状で私が日常的に使っている環境は下記の通り、
- 普段の作業: Mac Book Pro
- 仮想環境: virtualenv(DockerおよびAnacondaは使用しないことにした)
- Machine Learning ライブラリ: TensorFlow(CPU版)
- ラッパー: Keras等使わず
- 言語: Python (2.7)
- クラウド: 現状ではGCP(GCE)をメインに使っている(AWSは割高な気がしており)
- クラウドサーバーOS: 基本的にCentOS
- 方向性: Deep Learningを主にウェブサービスに適用したい
です。
1. 様子見の学習までは手元の固定コスト環境で
ディープラーニングの作業は概して
- 学習対象の選定
- 学習データの収集
- 学習データのベクトル表現化
- モデル定義
- 様子見の学習
- 評価とチューニング(状況により4または5へ戻る)
- 本学習
- デプロイ
の順序で行われるわけですが、ざっくりと「このモデルとこのパラメーターで学習をバンバンすれば有意なモデルができるな」と見切れて7.の本学習へ進めると判断するまでの「様子見の学習」はスピードが遅くとも手元にあるコストが見切れる環境で行って、本学習からはスピード優先の環境で行うのが落とし所だと思います。そこで、問うべきなのが「どれくらい様子見の学習をしたいか?」であり、先ほどウェビナーを受けた「NGC(NVIDIA GPU CLOUD)」は**「自分PCで稼働させる場合、GPU購入代金がイニシャルコストにかかるが様子見の学習で試行錯誤により発生するランニングコストが見切れるし一連の作業がそれなりには早く済む」という選択肢を提供するものだと認識しました**。ですので、基本的に様子見の学習まではMac Book ProのCPU/GPUで行い、もし、それで様子見の学習するのでは処理が遅すぎるというのであれば、Titan Vとは言わなくてもそこそこのNGC対応GPU(Pascal世代以降)を買って手元の自分PCに様子見学習用に用意するのが良さそうです。すなわち、自分のPCはノートとデスクトップの2台になるという。その後でスピード重視で本学習させるのはクラウドで、と切り分けると。
なお、AWSまたはAzureで様子見学習で稼働させる場合はイニシャルコストは低く抑えられる反面、従量課金での請求額が変動するのが私には嫌だなと思っています。
補足1:多くの方はまずは手持ちのNVIDIA GPUを使いたいと考えるでしょうが、「どのGPUがNGC対応なのか」がよくわからず。ウェビナーでもみなさんが個別に自分のGPUの型名をあげて質問し確認していた。NVIDIAさん、わかりやすいリストを作ってくれませんでしょうか?あるのかな?
補足2:NGCについてはNVIDIAの佐々木様が先月に解説の投稿をなさっておられます→(リンク)
2. 個別に最適化するか、全体で共通させるか、それが問題だ

NGC(NVIDIA GPU CLOUD)を導入できる環境条件は下記とのこと
- 環境: AWS または Azure または 自分PC
- OS: Ubuntu(CentOSでもいけそうな様子。WindowsとMacは現状非対応。)
- GPU: Pascal世代以降のNVIDIA GPU
- TensorFlow: 利用可能(Kerasは現状で非対応とのこと)
- 仮想環境: Docker + NVIDIA Docker (virtualenv非対応とのこと)
- その他: GPUドライバ(CUDA Toolkit不要)
であり、上記でセットアップしたコンテナに対して、最新のコンテナ状態にラクラクアップデートしてくれるので作業環境が安定することがメリットのようです。料金は無料のようで、NVIDIAのGPUの需要が増えるということが利益源になっている様子です。上記の環境条件を満たした場合のみで使えるとのことですが、気づかぬうちに従量課金されたくない私としてはできるだけクラウド環境での様子見の学習は控えたいし、NGCを使うのであれば自分PCにGPUを挿して使う前提で検討することになります。
さて、そうするとここで悩ましい問題が発生します。私はコードを書くとかデータを扱う作業をMac Book Proで行いたいので、Pythonコードを書いたり学習を実行する際に自分のMac Book ProからSSHで別にあるUbuntu 自分PCにログインするのはやぶさかではありませんが、GoogleがTensorFlowの実行仮想環境として(Dockerも可能ですが)vertualenvを推奨しており、Mac Book Proにはvirtualenvで仮想Python環境を持っているので、virtualenvもDockerも使うというようなバラバラな環境にしたくないです。NGCがvirtualenv非対応とのことなので、できればDockerを使わなくてもいい落とし所が「どっかー」にないだろうかと。
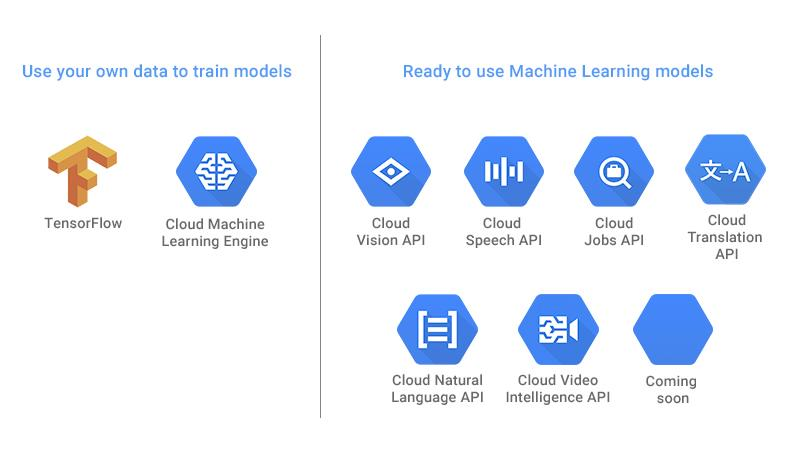
そこで、Googleが運用している「Cloud ML Engine」が候補にあがるわけです。私はウェビナーで「Google Cloud ML Engineに対するNGCのアドバンテージは何ですか?」とチャットで訪ねたのですが、時間的制約から回答はいただけなかった(これは仕方ないこと)。私の解釈だと「イニシャルコストはかかるが従量課金の変動が抑えられる」という「コストのバランス」が回答かと思っています。この数年GCPを利用してきましたし、Google Cloud Storageに一連のデータを置けばGPU/TPUでの高速学習も可能だと。GCEインスタンスへのデプロイも敷居が低そうだし、Dockerも使わずに済むし、Ubuntu PCも作らずに済むので環境の共通性は確保できる。Mac Book Proだけ持っていれば世界中どこでも仕事ができる。しかし、従量課金が怖い。
3. そもそも何がコストの不確定性を生んでいるのか?
正直、上記までの私は「あれもやだ、これもやだ」と駄々をこねているように自分でも見えます。そもそも、何がコストの不確定性を生んでいるのかと考えると、学習しても学習してもlossが低いところで収束しなかったりAccuracyが上がらないような学習データとモデル設計と学習時のパラメータ(誤差関数の歩幅など)にあるのであって、ここが改善されるべきところでしょう。と同時に、現時点ではNNMの最適なチューニングについてまだ十分な知見が共有されているとは言えない以上、無駄な計算は致し方ないと考えるべきなのかもしれません。
4. で、どうするの?
「当面はMac Book ProのCPU/GPUで様子見の学習までを行い、無駄な学習計算を極力避けるように予めの注意を払う。そして、本学習は時間が優先する場合にはGoogle Cloud ML Engineで行う。しかし、将来的にNGCが仮想環境にvirtualenvも使用可能になったり、Cloud MLでは費用の見通しがつかないというビジネス判断に至ったらNGCも使用する。」ということにしました。
ということで、皆さん実は迷っているであろう事案につき書き綴りました。「私はこうしてるよ」なんていうお話が聞ければ幸いです。そろそろもっと技術的なトピックもあげていくようにします。どうぞよろしくお願いします。
マッツ