はじめに
今回は希少カテゴリについて取り扱っていきたいと思います。図解をメインに説明をしていくためコードは今回付属させていません。今回の記事を参照し、やりたいことを毎回調べていくと自然と書けるようになると思います。そもそも希少カテゴリとはなんじゃという方もいらっしゃると思うので今回は希少カテゴリについても説明していきますが、「訓練データ」「評価データ」とは何かをわかっている前提で進ませていただきます。もしわからない方はこちらを参照してください。
では初めていきましょう!!
希少カテゴリとは
希少カテゴリとはそもそもカテゴリデータにおいてのみ起こり得ます。カテゴリデータとは例えば「性別」になります。カテゴリデータに関して詳細な記述はしませんが、まあ「性別」を意識して貰えばokです。
では希少カテゴリとはなんでしょうか。これは訓練データには存在しないカテゴリが評価データに存在しているという状況によって生まれるものです。これの何が問題なのかという話ですが、例えば学習データには「女性」のカテゴリしかなかった場合、評価データ内にある「男性」のカテゴリを含むデータ(行部分)は学習できていないことと同じです。学習できないことがまずいことはなんとなくわかるでしょう。つまり、この場合は特殊な操作が必要になります。では、その操作法について見ていこうと思います。
操作1:希少カテゴリ部分を他カラムから予測
希少カテゴリができる可能性として考えられるのは主に二パターンになります。ひとつ目は本当に稀に現れる部分が希少カテゴリになってしまった場合です。
例えば3行の学習データしか与えられず1000行の評価データを予測しろと言われても無理ですよね。この場合はそんなイメージです。ただ、もう一パターンとしてはヒューマンエラーがありえます。これは本来あったはずのカテゴリを予測すれば良いのでこちらだったら僕たちの手で対処できます。本来あったはずのカテゴリを予測するのは欠損値予測と全く同じ流れです。まあ、一応見ていきましょう。
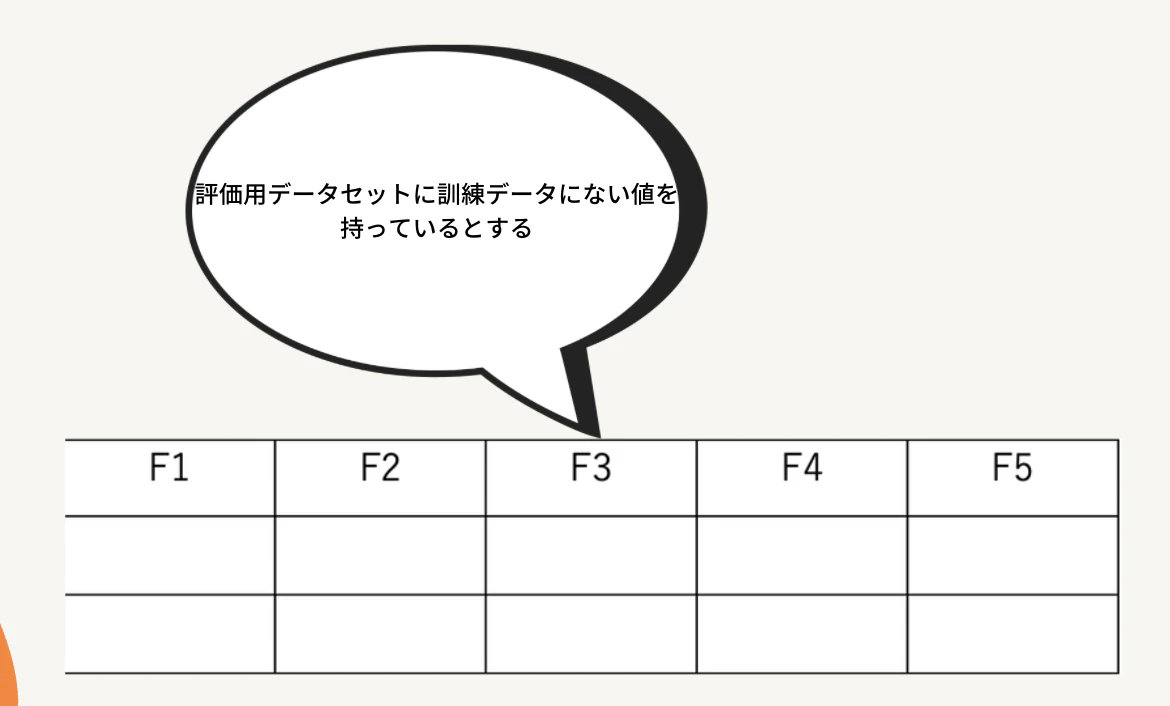
今は上記のような状況を考えます。F3部分に希少カテゴリがあり、これらは訓練データと評価データをくっつけたデータとしてください。元々欲しい部分(希少カテゴリ部分)は評価データの中にしかないので訓練データと評価データをくっつけて希少カテゴリ部分を評価データそれ以外の部分を学習データとすることで評価データ部分の予測をできるようになります。
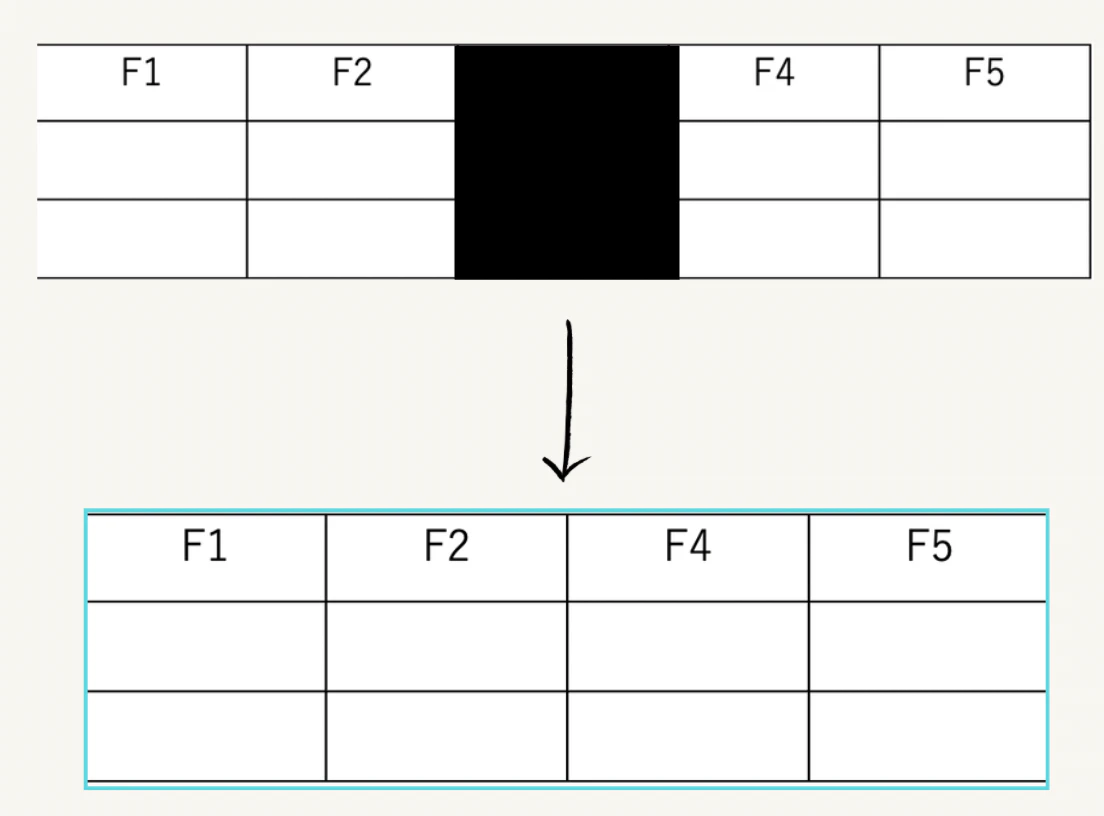
次ですね。F3部分にマスクをつけて、目的変数として分離します。目的変数として分離したのち希少データになる部分を評価データに、それ以外の部分を学習データとして分離することで一般の分析と同じように学習データの説明変数・学習データの目的変数・評価データの説明変数・評価データの目的変数(希少カテゴリ部分)の4つに分けることが可能になります。
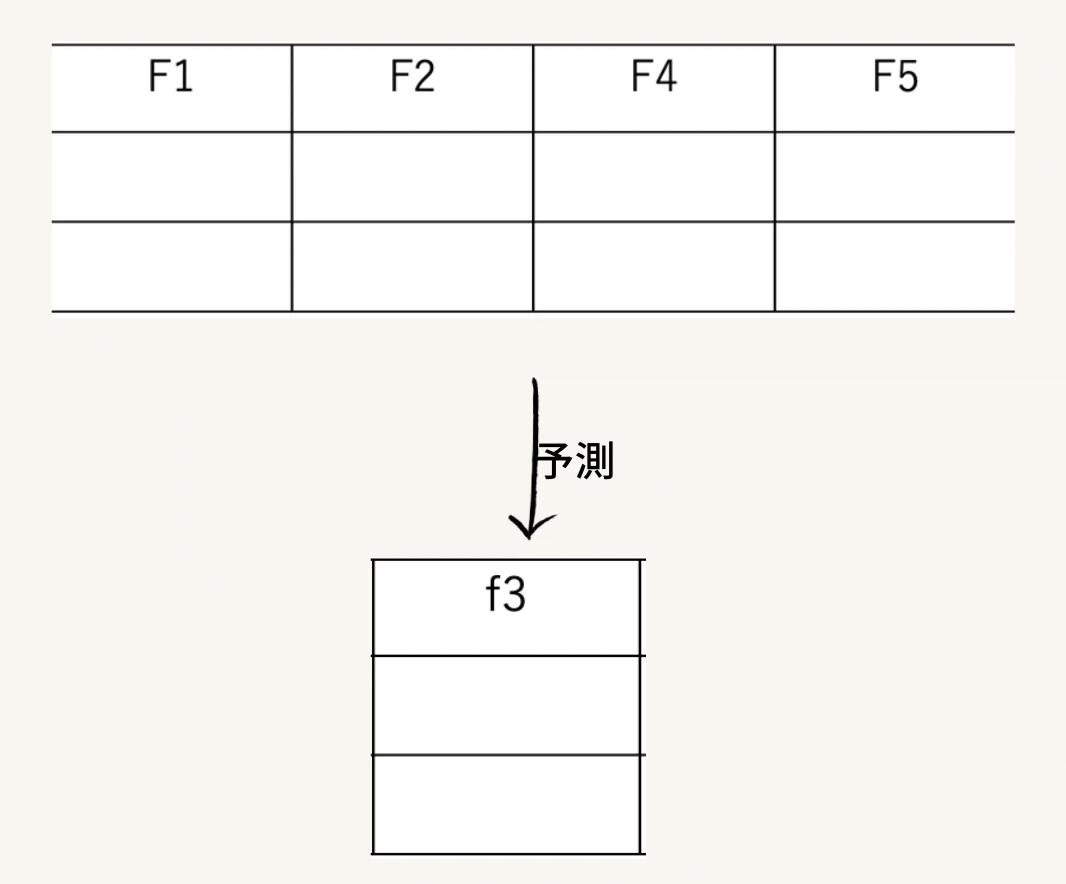
最後に、学習データを用いて作成した特長量や前処理の過程、分類器を利用して評価データの説明変数部分から希少カテゴリ部分を予測します。すると、希少カテゴリ部分が別カテゴリ(学習データの目的変数内にあるカテゴリ)に分類されるため、対処が可能です。
操作2:希少カテゴリ部分はNoneとして処理
操作1部分でも何度か出していますが、希少カテゴリと欠損値は同じように捉えることが可能です。主にこちらが解決できるのはこれらがヒューマンエラーで起こった場合のみですね。なので、欠損値と同様に扱いましょうということでNoneにして欠損値処理として希少カテゴリを取り扱います。そうすると、操作1と同様学習データに既存のカテゴリから予測値を入れることができますね。これは欠損値処理の方に扱い方が近いので欠損値として処理をしたい場合はこちらを参照してください。
操作3:出現回数が一定回数以下のものをひとまとめにする
今回のものだけは少し注意が必要です。今回のものは厳密に言えば希少カテゴリではありません。希少カテゴリは評価データにしか存在しないカテゴリのことを指しますが今回はただ単に出現回数が少ないものについての操作になります。出現回数が少ないものに対する操作が他に幾つもあるわけではなく、紹介されていたサイトもあまり見なかったので紹介だけ。
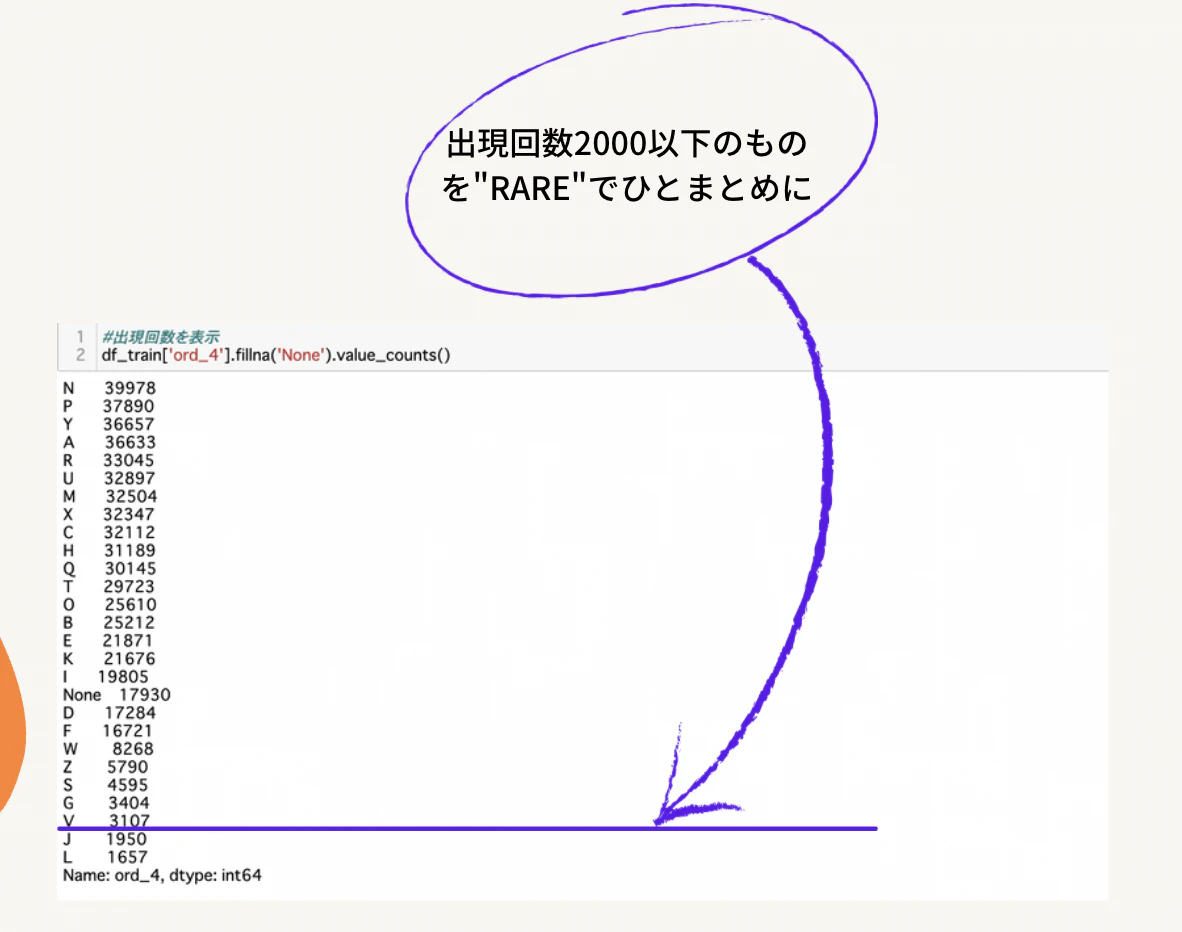
今回は上記のような場合を考えます。今回は2000以下のデータについて取り扱います。この閾値に関しては自分自身でご自由にお決めください。具体的にいくつで閾値を設定した方が良いというものは存在しませんが、僕のイメージとしてはまとめた時にそのカテゴリに入っているデータ数が一番少なくならないくらい、のイメージですかね。今回で言えば加算すると3500くらいになるので下から3番目くらいに属するようになるのでまあ2000で閾値切るかって感じですね。
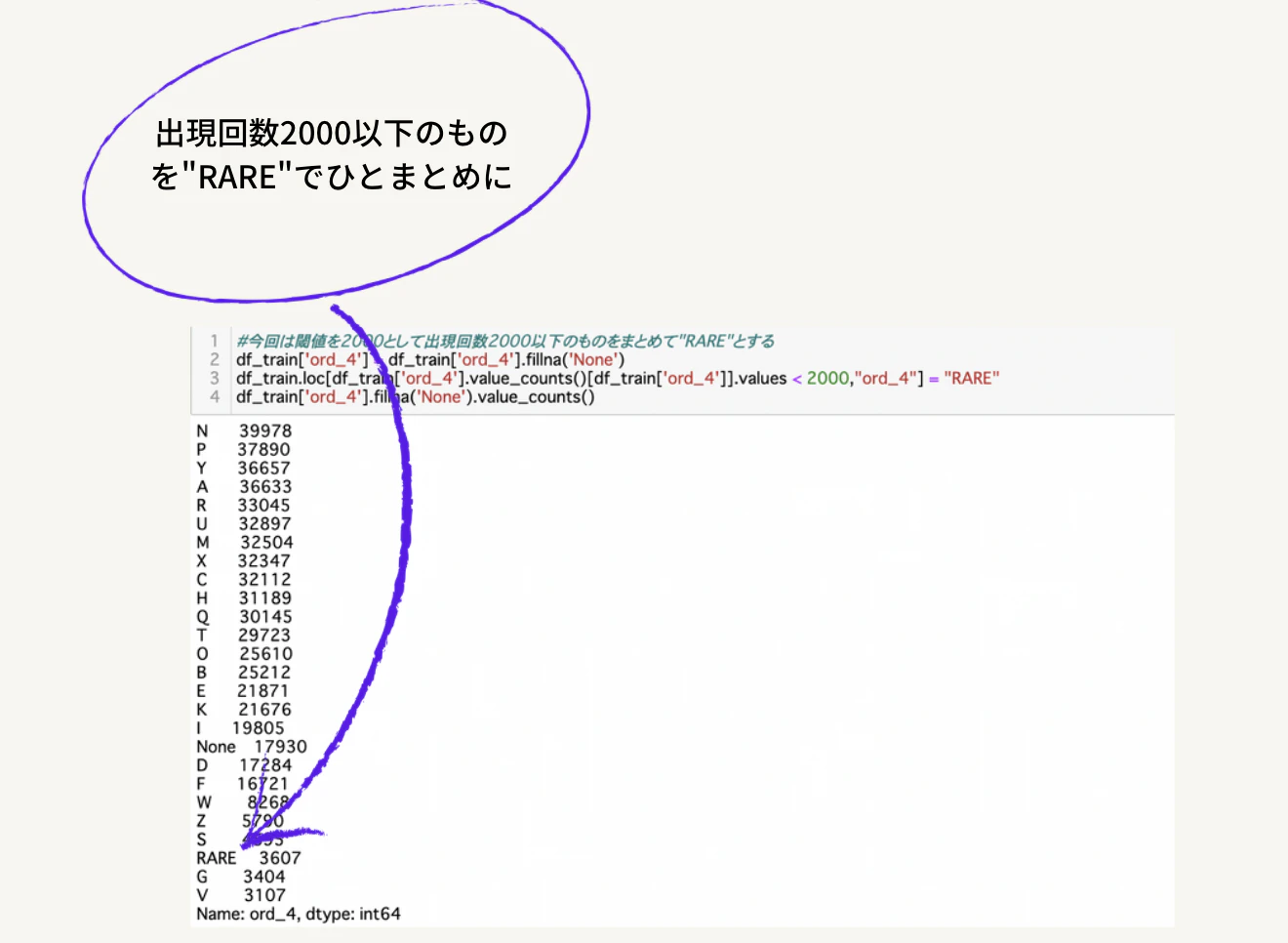
で、実際にした二つのカテゴリを"RARE"としてそれぞれのカテゴリ内にあるデータ数を見たときに下から三番目に来てますね。まあ、こうなればまあいいかなっと。これはご自身で手で動かしてみてトライアンドエラーしないことにはなんとも。。
さいごに
今回は希少カテゴリについて取り扱いました。結構説明を端折った部分もありますが基本的な前処理・分析知識を持っている方なら問題なかったかなと思います。もし、わかりにくかったです、という方はそれぞれに付属しているページに飛んでもらえると僕が以前書いた記事のページに飛びます。まあ、参考程度に。
みなさんの活動の一助と慣れていれば幸いです。最後までご覧くださりありがとうございました!