はじめに
今回は図を用いながら欠損値処理について触れていこうと思います。各章で説明した欠損値補完の方法については各章の最後に以下のようにコードを付属させています。
この枠内にコードとその動きを記述していきます
今回利用するデータはタイタニックデータ(https://www.kaggle.com/c/titanic) です。ここから予測がつく方もいらっしゃると思いますが、今回はデータ分析コンペ向けの欠損値処理になります。
ここで、注意です。初学者の方はコードを使う必要はあまりないと思われます。理由は、わからないものにわからないものを付属されてもなおのことわからなくなるからです。欠損値処理とは何かを知っている、どのような方法があるのかを知っている。最初はその程度で十分です。今回無理やりコードまで手を出さなくても良いと思います。
てな感じで初めて行きます!!
欠損値って
まずは軽く欠損値について触れていきたいと思います。欠損値処理とはつまり「欠損値」を処理することです。まあ、文字通りですね笑
そこで必要なのは欠損値とはなに?という話です。まあ、この記事を見ている時点で欠損値については知ってるよって人がほとんどだとは思うので軽くだけ触れてサクッと次にいっちゃいたいと思います。とはいうんですけどここで欠損値について固っ苦しく見ていってもつまんないので具体例で見ていきます。
多くの方がアンケートってのに答えたことがあると思います。アンケートって、必須回答部分と任意回答部分で分かれていることがほとんどですよね。例えば年代とか性別とか日時とか満足度とかは必須回答だったりしますけど、逆に誰ときたのかとか理由だったりとかは任意回答であることが多かったり。気分がいいから・副賞がもらえる可能性を上げたいから・時間に余裕があるから任意回答部分に回答してみたり時間がなかったり面倒くさかったり特に印象に残ったことがなかったから任意回答部分には答えなかったり。。
アンケートは基本的に集計してデータ化して分析するために使われますよね。ここで、100人から回答を得られたとして90人は全部の項目を回答してくれていたけど、10人は任意回答部分は一部しか答えてくれてなかった。そうしたらデータに穴が生まれますよね。それが欠損値です。身近にあるものなので想像はしやすいと思います。他にもアンケート用紙が破けてて回答がわからないとか欠損値が生まれる理由はいくらでも考えられます。
簡単にまとめれば欠損値はとある理由によって欠けたデータ部分のことを指します。
欠損値処理の方法について
上で欠損値とはそもそも何という話をしました。その上でどうやって欠損値があるデータ(先ほどのアンケートのような形)を分析していくのかについてみていきましょう。いくつかのパターンに分割できるので以下でまとめていきますね。
次の章からで具体的なメリット・デメリットまた図示、コードを書いていきますので今はこんなんあるんだー程度で大丈夫です。
- 1.欠損値を含む行(列)を削除
- 欠損値部分を消してしまおうという話です。例えば、一部だけしか回答してくれなかった回答者や一部の回答者からしか回答が集まらなかった問題についてその存在をなかったものとしてみましょうということですね。
- 2.欠損値に具体的かつありえない数値を挿入
- データ数は多ければ多い方がよろしいです。まあ、イメージはつきますかね。10人からしか回答を得られないものと1000人から回答を得られたものを比較したときは後者の方が精密っぽいですよね。1のやり方だと回答を得られてた部分も削られちゃうのでもったいねえ。ってことで欠損値部分にあり得ない数値を代入します。例えば1~5で回答をもらうものに対して欠損値は-9999みたいに取り得ない値を取るようにするってことです。
- 3.列で欠損値以外のデータを収集して代表値を欠損値に挿入
- 2つ目と同様で欠損値の部分は消したくないなあ。プラス2つ目は欠損値として(-9999として)処理してたけど欠損値としてではなくてあり得そうな値を突っ込みたい。けど、いろんなことすんのはめんどい。ってことで列ごとに数値計算(平均値とかね)して欠損値にその数値を入れちゃおうぜって話です。
- 4.他列を利用して欠損値を予測
- まあ、これは最初ハードルが高いと思います。ある程度データ分析に慣れてからでいいですね。簡単に説明すると3つ目の完全上位互換です。分析してその結果を欠損値に突っ込もうぜって話です。3つ目よりも欠損値内に入るデータの精度が高くなるのがいいところですね。
1.欠損値を含む行(列)を削除
メリット:基本的操作が非常に簡単
デメリット:データ数が少ない時には精度に大きな影響を及ぼす
メリット・デメリットに関してはこんな感じですかね。基本的にデータが多い時であってもデータの削除は好ましくないのでこの手段はあまり使われませんが、まあ紹介だけ。。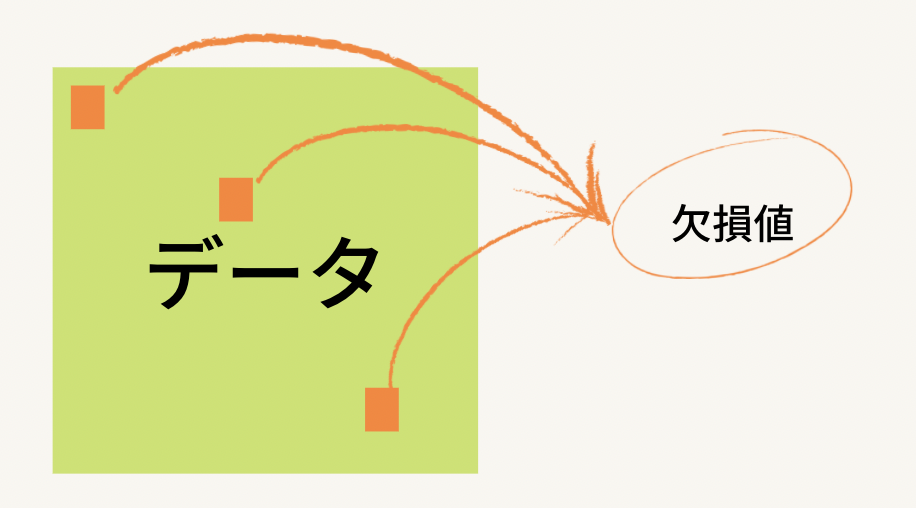
上の写真のようなデータがあったとします。今回は行についての操作を見ていきますが、列に関しても同様のことが言えるので、列についての操作が気になる方は以下の行の部分を列と読み替えてもらえればokです!
今回は三行のデータが欠損値を含んでいるとします。ここで行われる作業は欠損値を含む行を消してしまおう、ということです。なのでまずはデータの中で欠損値を含んでいる行と含まない行とを別個にしましょう。下の写真がそれになりますが、紫の枠線で囲まれている部分を今回欠損値を含んでいる行だとします。
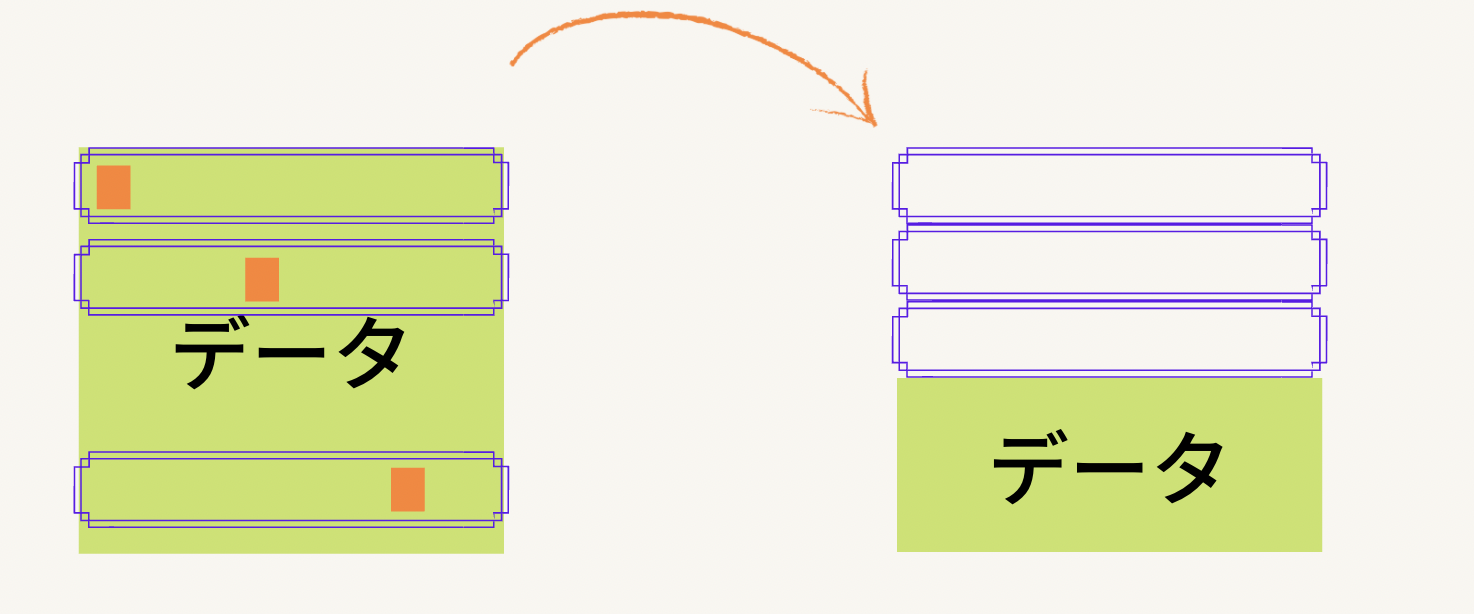
さて、これで欠損値が含まれている部分とそうでない部分が区別できました。ゴールは欠損値を含んでいる行を削除することだったので、今回紫の枠線で別にした部分を消しちゃいます。そうすると、下の写真のように最初の段階に比べて使えるデータの部分がだいぶちっちゃくなったのがわかると思います。

そして、この写真のように元々一定の大きさを持っていたデータがだいぶちっちゃくなちゃうのが問題点なのです。紫の枠線で囲まれていた部分でも欠損値でない部分は存在しましたよね。(枠線で囲まれているうちオレンジで色が塗られていない部分ですね)それを自ら消しちゃうのはいかがなものかなあと。まあ、でも簡単なのは間違い無いですね。最後にこの操作ををするためのPythonコードを見てみましょう。
ちなみにですが、今回利用するタイタニックのデータは以下のようになっています。この章では訓練データに対してみていきます。(わからない人は飛ばしてもらって大丈夫です)

# データセットの取得
df_train = pd.read_csv('../input/train.csv')
df_test = pd.read_csv('../input/test.csv')
sample_submit = pd.read_csv('../output/gender_submission.csv')
# 訓練データ内で欠損値を持つ行を削除
df_train = df_train.dropna()
# ちゃんと欠損値が消えているかの確認
df_train.info()
2.欠損値に具体的かつありえない数値を挿入
メリット:欠損値そのものとしての情報を残せる
デメリット:明らかな外れ値になるので前処理などに注意が必要
メリット・デメリットに関してはこのくらいですね。欠損値そのものとしての情報を残せるということは前の章で見たようなデータが小さくなってしまう現象は起こり得ないということです。ただ、外れ値になるのでそこの部分は注意が必要ですね。外れ値に引っ張られるような前処理(有名どころはMin-Maxスケーリングでしょうかね)は使えなく無くなることに注意してください。ただ、分類器を決定木モデルにする場合は欠損値そのままで扱えるので何も操作がいらなくなります。
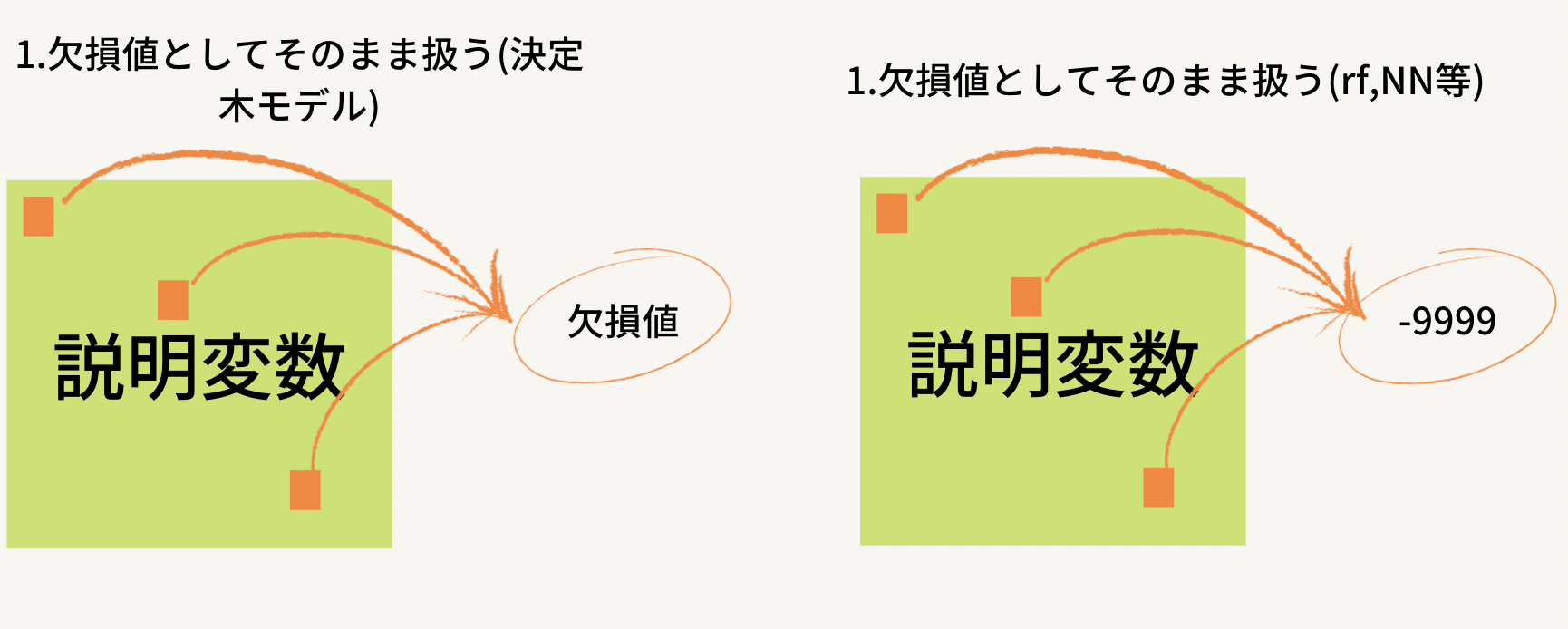
これも難しいことはありません。欠損値部分(写真ではオレンジで塗られている部分)にあり得ない数字を入れればいいだけです。ただし、文字ではなく数字であることを強くお勧めします。多くの分類機ではデータが数値型でないと動いてくれません。文字にしてもう一段階踏むなら、最初から数値入れちゃえってことですね。これもPythonコードでみていきます。
# 訓練データ内で欠損値に-9999を代入
df_train = df_train.fillna(-9999)
# ちゃんと欠損値に数値が入っているかの確認
df_train.info()
3.列で欠損値以外のデータを収集して代表値を欠損値に挿入
メリット:列での集計量を代入できるのであり得ない値を取らず前処理等が楽かつデータ削除がない
デメリット:あり得る値を取るがゆえ欠損値という情報は損失しやすいかつ妥当とは言えない値を代入する場合がある
こちらのメリット・デメリットはこんな感じ。デメリットの二つ目がわかりにくいかもなので少しだけ補足。と言いたいが、まずは代表値の具体的な例を見ていってから説明。
有名どころはこんな感じ。あとは最頻値とかですかねえ。今回代表値まで触れると記事が終わらなくなっちゃうので省略しますね。で、デメリットの二つ目に話を戻させてください。
例えば、回答がはい/いいえでわかれており、他のデータでは男性は100%「はい」を選択し、女性は100%「いいえ」を選択していた場合欠損値部分の性別が男性だった場合には「はい」を入れるのが妥当ですけど、女性の方が人数が多くて最頻値をとったら性別関係なしに「いいえ」が欠損値部分に入れられちゃいます。ってすると、妥当ではない気がしますよね。っていうことです。
では、どんな流れになっていくのか見ていきましょう。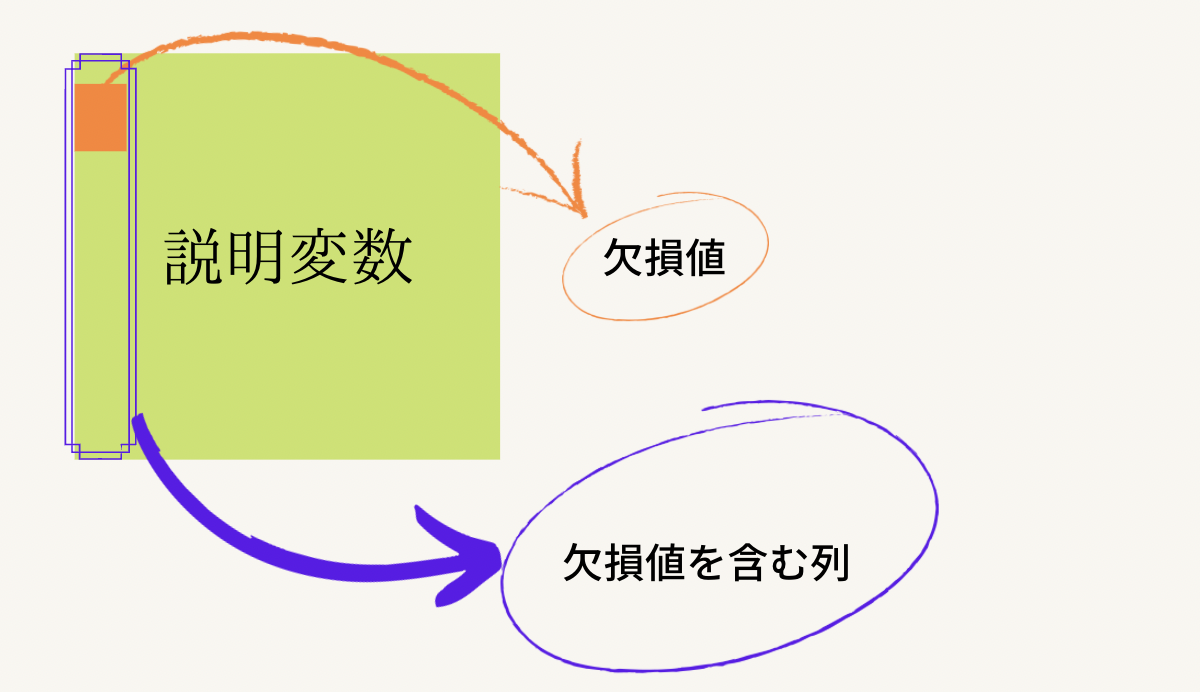
まず第一は欠損値を含んでいる列を取り出してくることです。上の写真で言えばオレンジで色付けされている欠損値部分を含んだ列を紫の枠線で取り出してきます。今回のお話の舞台はこの紫の枠線内だけになります。
今回は説明変数内にあることを明記するために緑色の四角で説明変数内におけるある列のお話であることを明確にしています。が、お話はあくまで紫の枠線の中でのお話です。この列に着目をします。今回欠損値部分を黒く塗っていますがそれは代表値の計算の際に除外されているからです。欠損値を無視して(イメージで言えば黒塗りして)それ以外の数字(データ)から平均値などの代表値を計算します。そして、導き出された代表値を今さっき黒塗りしていた欠損値部分に代入します。そうすると、列での代表値を欠損値部分に代入できますね。これもPythonコードでみていきましょう。今回はAgeの列に着目します。
# Ageの列内にある欠損値部分をAge列のmean(平均値)で補完
df_train['Age'] = df_train['Age'].fillna(df_train['Age'].mean())
# ちゃんと欠損値に数値が入っているかの確認
df_train.info()
4.他列を利用して欠損値を予測
メリット:比較的正確な数値を得られやすい
デメリット:面倒くさい
圧倒的に多く使われているのがこの手法です。比較的正確な数値が得られるため、精度向上に寄与しやすく面倒臭いというデメリット部分もClass文などである程度一般化させておくことで軽減されます。しかし、同時に初心者にはハードルが高くこれが欠損地補完を難しく考えてしまう要因のようにも感じます。最初にも書きましたがデータ分析に慣れてから挑戦するのが良いでしょう。ここでやる作業はデータ分析です。あとで詳しくみていきますが、データを作成し、説明変数と目的変数を作成し前処理をして分類器を作成します。「データ分析」自体の流れが怪しい方や訓練データとかテストデータとかが怪しい方はここに突っ込むと間違いなく沼にはまって嫌になります。僕がそうだったので笑。
てことで注意をダラダラと書き続けるのも嫌なので早速内容に入っていきます。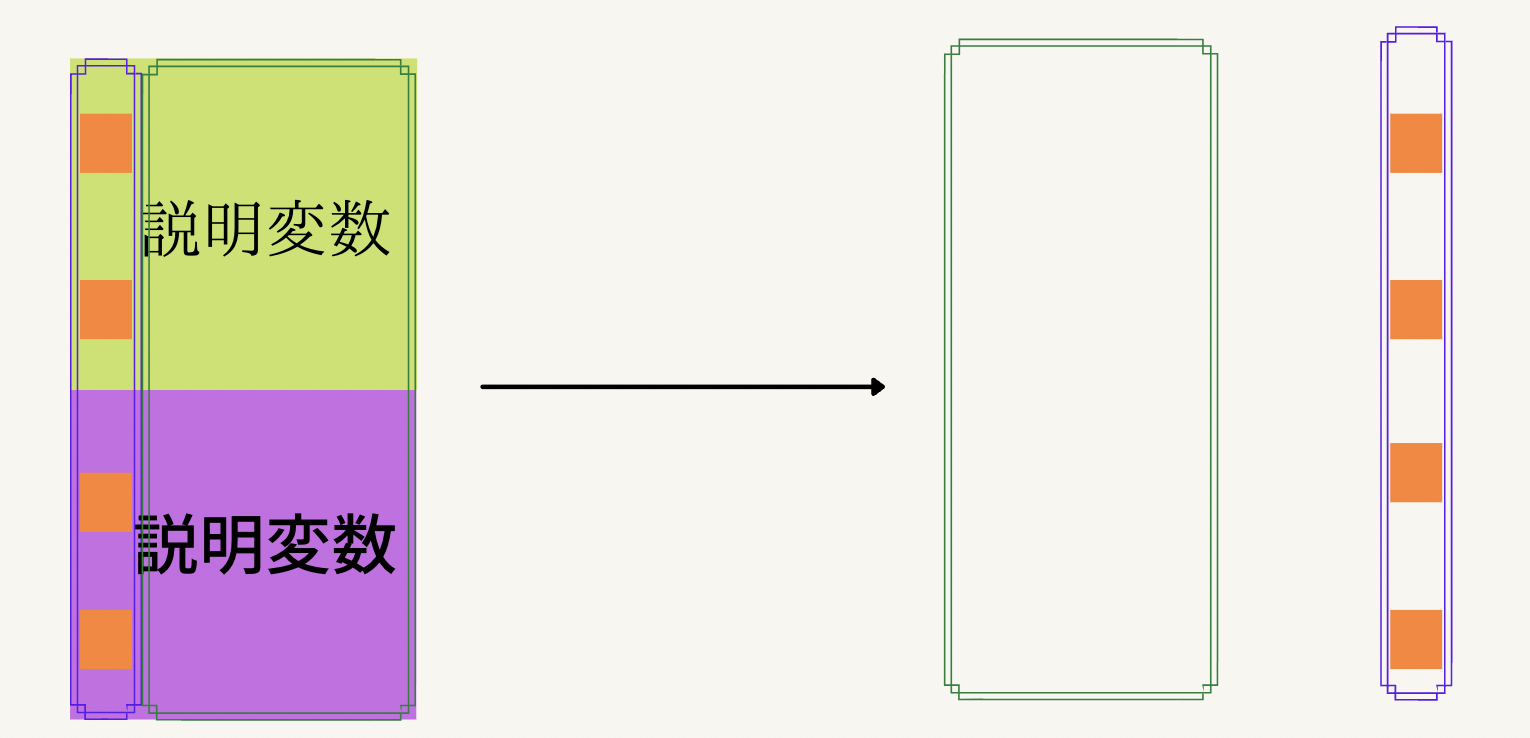
写真を見て色が違う二つの「説明変数」とラベルのついた四角が出てきてなんじゃ、これと思われると思うので説明しますね。緑色の四角は学習データにおける説明変数であり、紫色の四角は評価データにおける説明変数です。なんで学習データと評価データをくっつけるのかという話ですよね。まず、今回やりたいのは**「欠損値部分のデータに数値を入れたい」ことなのでこれを目的変数にセットします。残りの全て(学習データから元の目的変数は分離されているとします)を説明変数にします。当たり前のことですが、評価データにも欠損値は存在しますので学習データと評価データをくっつけて一つの大きなデータとしてみちゃいます。そうやって操作したものが矢印の後ろのデータセットになります。学習データ評価データをくっつけて欠損値部分を含む列とそれ以外の列を分離します。確認になりますが、欠損値を含む列が目的変数部分、それ以外の部分は目的変数に当たります。
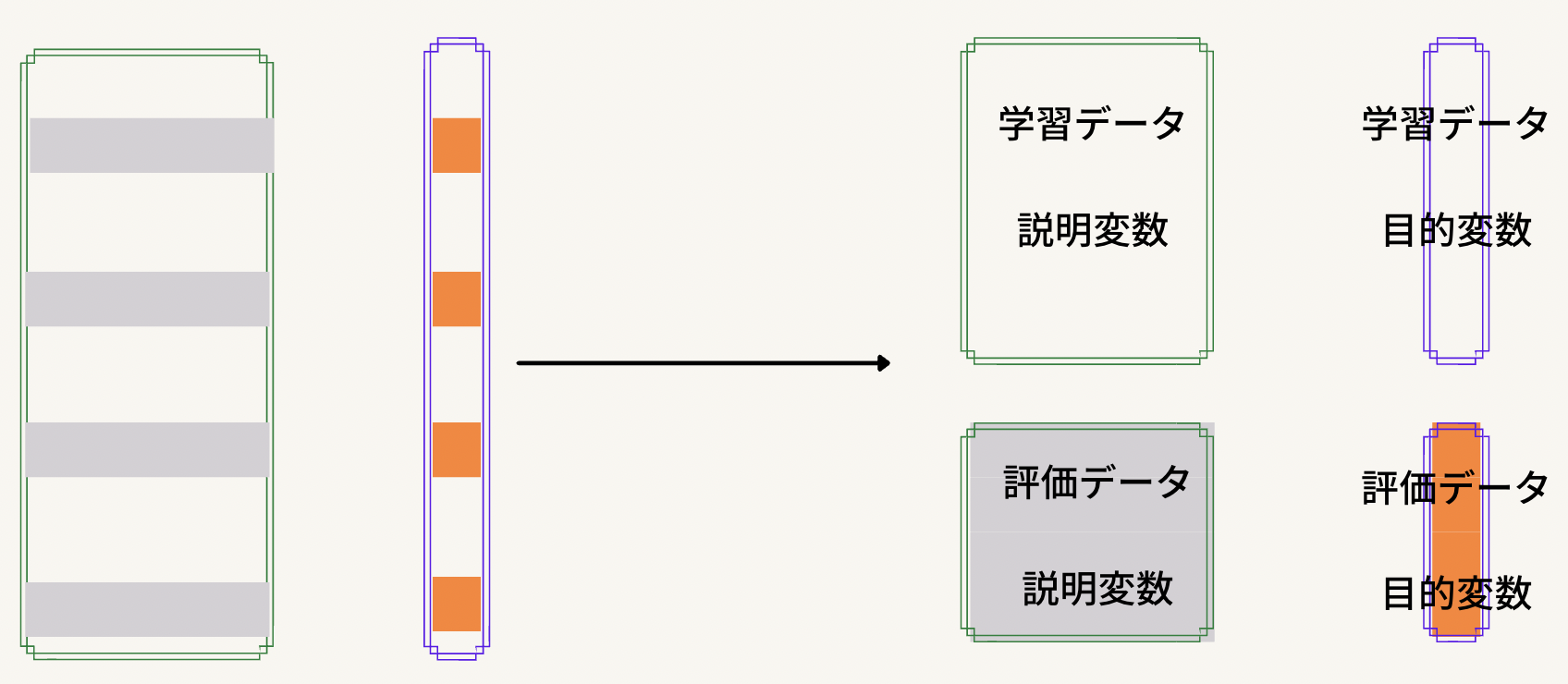
分離まで行ったら次の作業です。説明変数と目的変数の分離ができたので次は学習データと評価データの分離です。普通のデータ分析でもらうデータをイメージしてもらえれば結構ですが、評価データの目的変数部分は何も分かっていない部分(分析部分)になっており、それに対応したデータが評価データの説明変数内に入っていますよね。ということで今回何も分かっていない部分は欠損値部分**になり、それに対応した説明変数も評価データとして引っこ抜いちゃいます。上の写真がわかりやすいかなと思いますが、欠損値部分を含む行をまるまる評価データに変更しちゃおうということです。あとは3つのデータセットが揃っていますから(評価データ内の目的変数は予測する部分になるのでないとして扱う)前処理して分類器を作成して予測した値を欠損値部分に入れちゃえば終わりです。最後にPythonコードを見て終わりましょう。今回は図で説明をした3つへの分離までしか行いません。また、今回はEmbarkedの列を利用します。
# データ分析できる形にしよう
df_all = pd.concat([df_train,df_test],axis=0)
em_train = df_all[~(df_all['Embarked'].isnull())]
em_train.drop(['Embarked'],axis=1,inplace=True)#学習データの説明変数
em_test = df_all[(df_all['Embarked'].isnull())]
em_test.drop(['Embarked'],axis =1,inplace = True)#評価データの説明変数
em_target = em_train['Embarked']#学習データの目的変数
おわりに
今回は欠損値処理について学んでいきました。他にも方法はいくつか存在しますが使われることが多い、知られていることが多いものをとりわけピックアップしました。最初にも述べましたがわからないものをわからないもので説明されてわかるわけがありません。データ分析は焦ったらそこで負けです。
かくいう僕も最初は焦っていました。コードを暗記しなきゃとか、たくさんコンペに参加しなきゃとかとか。でもゆるゆるとやっていけば身についていきます。
色々なものに触れることでそのコードに触れたことがなくても、前にはわからなかったコードもいつの間にかスッと書けて理解できるようになっているものです。
今回の記事は初心者に向けて書いています。そのため、コードはあくまでサブ的な使い方を想定しています。データセットを読み込んで同じように実行していけば手元でデータを取得できるようにしています。結果として、目に見えるものとしてコードは利用してください。ただし、データのインポートとそれに伴うパス変更については各自で行うようにしてください。
長くなりましたが、最後まで読んでくださりありがとうございました!
ほんの少しでも皆さんの力になれれば幸いです!!