はじめに
この記事は「生成 AI 入門してみた ① 基本編」に続く、第 2 部です。
第 1 部では、LLM・学習・ニューラルネットワークといった「生成 AI の土台」を整理しました。
この第 2 部では、「コンピュータは、どうやって“言葉”を扱っているのか?」 という疑問にフォーカスします。
ChatGPT は、文章を読んで意味を理解し、自然な文章を生成します。
ただしコンピュータは人間とは異なり、言葉を数値化しています。
この章では、自然言語処理(NLP)の仕組みを順番に見ていきます。
この記事は生成 AI 初心者が書いており、技術的に正しくない記載・表現が全然ありえます。
また技術的な正しさよりも、初心者・非エンジニアでも理解できるような粒度を目指して書きました。こちらご留意下さい。
目次
キーワード
- 推論・学習
- LLM
- ニューラルネットワーク・ディープラーニング
- LLM と AI エージェントの違い
第 2 部: 自然言語処理の仕組み編 ← 今ココ
キーワード
- 自然言語処理とは
- 機械翻訳との関係
- 単語の意味を理解する仕組み(ベクトル・word2vec)
- 文章を理解する仕組み(RNN・エンコーダ・デコーダ・seq2seq・Attention)
キーワード
- Transformer の理解がなぜ重要か
- seq2seq と Transformer の違い
- Transformer の構造
- Transformer の学習の仕組み
キーワード
- MoE
- RAG
- ReAct
この章でわかること
- 自然言語処理(NLP)とは何か
- 機械翻訳と生成 AI の深い関係
- 単語の「意味」を数値で表す方法
- 文章全体の意味を扱うための工夫
- なぜ生成 AI は、もっともらしい嘘(ハルシネーション)を作ってしまうのか
2-1. 自然言語処理とは
自然言語処理(Natural Language Processing, NLP) とは、コンピュータが人間の言葉(自然言語)を扱うための技術分野です。
生成 AI では、
- 入力されたプロンプトを読み取り
- その内容をもとに文章を生成する
という一連の処理すべてに、自然言語処理が使われています。
ここでまず押さえておきたいのは、コンピュータは言葉の意味を、そのままでは理解できないという点です。
人間にとっては当たり前の
- 単語の意味
- 文脈
- 曖昧さ
といったものは、コンピュータではそのままでは扱えないです。
そのため自然言語処理では、言葉を一度「数値化」してから処理するというアプローチを取ります。
2-2. 機械翻訳と自然言語処理の関係
自然言語処理や AI について勉強していると、機械翻訳の例がよく出てきます。
私は読みながら「なんでここで機械翻訳なんだ?」と正直思っていたので、まず関係性について書いておきたいと思います。
自然言語処理の発展の中で、機械翻訳は重要な技術でした。
英語を日本語に翻訳するとき、実際には次のような処理が必要になります。
- 元の文章の意味を理解する
- 意味を壊さず、別の言語で文章を作り直す
これはそのまま、
- 質問文を理解して
- 回答文を生成する
という生成 AI の処理と本質的には同じです。
実際、現在の LLM の中核技術である 「Transformer」 も、もともとは機械翻訳のために開発されました。
そこでこの章では、機械翻訳で培われてきた仕組みをたどりながら、自然言語処理の考え方を整理していきます。
2-3. 単語の意味を理解する仕組み
単語を数値で表す必要性
例えば、コンピュータは「りんご」という言葉を、意味として直接理解することができません。
そのため自然言語処理では、
単語の意味を「数値の集まり」として表現します。
このとき使われるのが ベクトル という考え方です。
ベクトルとは、「複数の数値が並んだもの」くらいの理解で大丈夫です。
※ 数値の集合という意味で、高校数学等で出てくる「ベクトル」と似ていますが、厳密には異なります。
例えば単語を、
- 色
- 形
- 食べ物かどうか
- 感情的なニュアンス
といった複数の観点で数値化すると、
1 つの単語は「たくさんの数値の組み合わせ」で表せます。
このような表現方法を 分散表現 と呼びます。
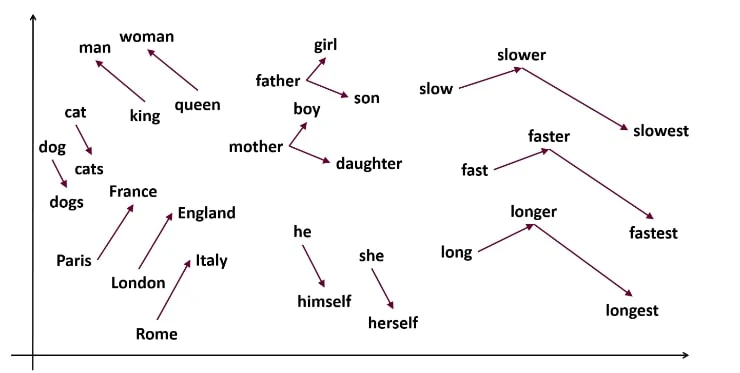
意味が近い単語は、数値も近くなる
分散表現の大きな特徴は、意味が似ている単語ほど、ベクトルも似た形になるという点です。
例えば、
- 「きゅうり」
- 「トマト」
- 「ピーマン」
は、文章の中で使われる場面が似ています。
その結果、これらの単語はベクトル空間上でも近い位置に配置されるようになります。
逆に、
- 「銀行」
- 「きゅうり」
のように意味が大きく異なる単語は、ベクトル空間上でも遠く離れます。
word2vec:文脈から意味を学ぶ
この「意味を数値で表す」仕組みを実現した代表的な手法がword2vec です。
word2vec の考え方は、「単語の意味は、その周囲に出てくる単語で決まる」というものです。
例えば、
- 「きゅうり」は「食べる」「野菜」「サラダ」と一緒に出やすい
- 「銀行」は「お金」「口座」「融資」と一緒に出やすい
こうした 共起関係 を大量の文章から学習することで、単語の意味を数値として捉えます。
穴埋め問題としての学習
word2vec の学習は「文章の一部を隠して当てるクイズ」のような形で行われます。
- 文章の中の単語を 1 つ隠す
- 周囲の単語から、その単語を予測する
- 正解との差をもとにモデルを調整する
この練習を繰り返すことで、単語を当てやすくするための内部表現(ベクトル)が洗練されていきます。
このように単語をコンピュータが理解できるようベクトル化することを、埋め込み(Embedding) と呼びます。
2-4. 文章の意味を理解する仕組み
単語をベクトルで表せるようになっても、それだけでは 文章全体の意味 は扱えません。
ベクトル化はあくまで「ボキャブラリ一覧表」を作るようなものです。
文章では、
- 単語の並び順
- 前後の文脈
- それまでに何が語られてきたか
といった情報が重要になります。
この目的で使われてきた代表的な仕組みが、RNN です。
RNN
RNN は、「リカレントニューラルネットワーク」「再帰型ニューラルネットワーク」と訳します。
通常のニューラルネットワークとの違い
通常のニューラルネットワークでは、入力層にデータ入力・隠れ層で計算・出力層で結果出力という処理を 1 回きり 行います。
一方、RNN では次のような処理が行われます。
- ある時点の入力データに対する出力結果を
- 次の時点の入力と一緒に再び同じネットワークへ渡す
これにより、 過去の情報を内部に保持しながら処理を続けることができます。
文脈を引き継ぐ仕組み
RNN の最大の特徴は、過去の情報を次の処理に引き継げることです。
文章を単語ごとに処理しながら、
- ここまでに読んだ内容
- 文脈の要約
を内部に持ち回りながら計算します。
例えば、
私は赤い自転車に乗る
という文章を読む場合、
「赤い」を処理する時点で、RNN の中にはすでに「私」という情報が残っています。
こうして最終的に、文章全体の意味を 1 つの数値表現としてまとめることができます。
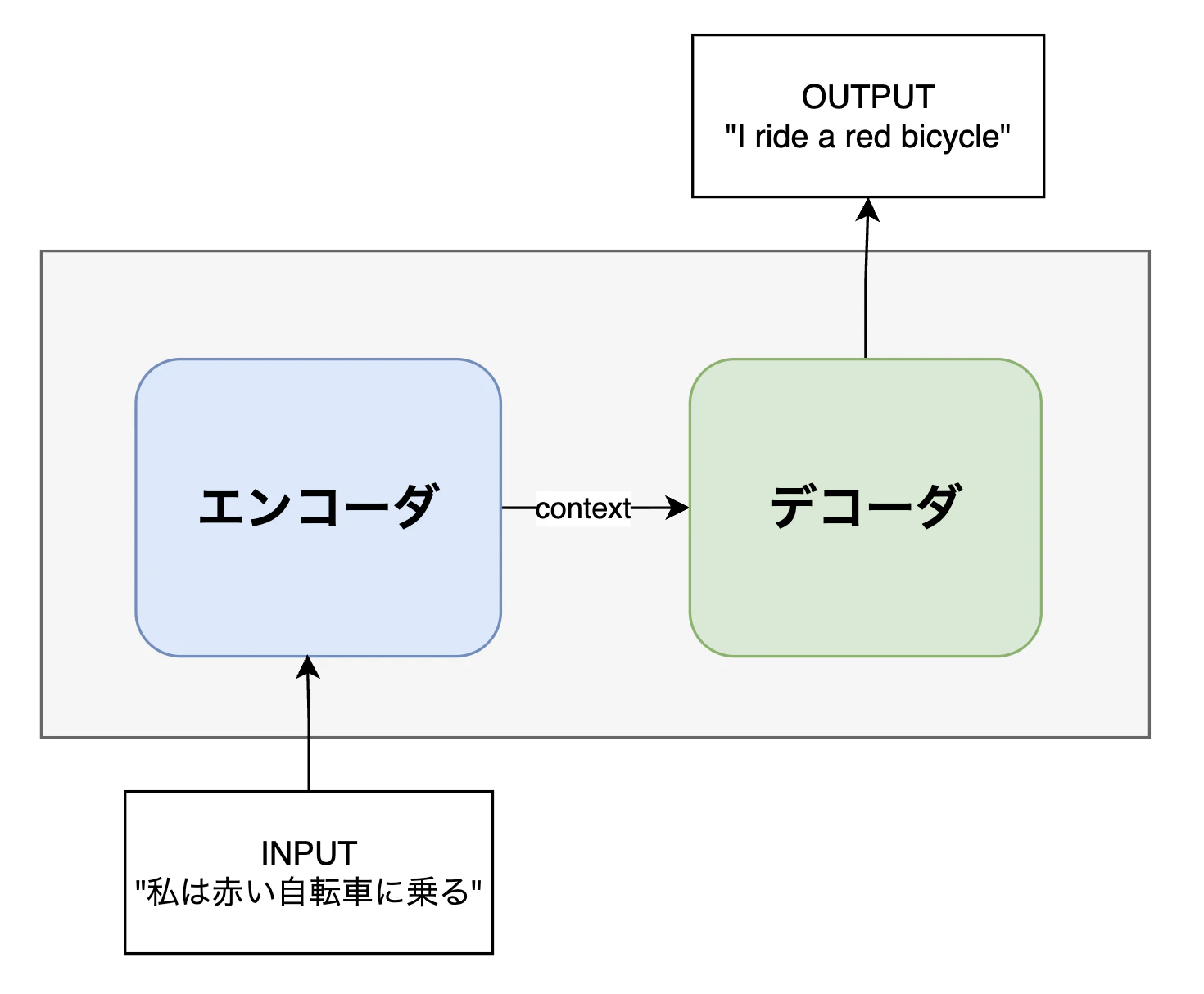
エンコーダ・デコーダと Seq2Seq
RNN を使った文章生成では、役割の異なる以下 2 つを組み合わせます。
- エンコーダ:入力文章を読み取り、意味を要約する
- デコーダ:その意味をもとに、文章を 1 語ずつ生成する
この構造を Seq2Seq(Sequence to Sequence) と呼びます。
機械翻訳では、
- エンコーダが翻訳元の文章を理解し
- デコーダが翻訳後の文章を生成する
という流れで処理が行われます。
Attention
RNN の弱点と Attention の仕組み
RNN にはその仕組み上、文章が長くなると、前半の情報が弱くなりやすいという弱点がありました。
これを補うために考え出されたのが、Attention(注意機構) です。
Attention では、「次の単語を生成するときに、入力文のどの単語が重要か」を都度判断します。
つまり、特定の単語に注意を払うということです。
※ そのほか、計算効率の向上も、RNN と比較した Attention のメリットとしてあります。
どこに注目するか
例えば、
彼はリンゴを食べた。それはとても甘かった。
という文章では、「それ」が「リンゴ」を指していることに注意を向ける必要があります。
Attention は、このような単語同士の関係性を数値的に捉える仕組みです。
この考え方が発展し、現在の LLM の中核である Self-Attention や Transformer へとつながっていきます。
2-5. おまけ:なぜハルシネーションが起きるのか
生成 AI は時々、もっともらしいが事実ではない文章を作ってしまうことがあります。
これを ハルシネーション と呼びます。
この現象には、自然言語処理の仕組みそのものが関係しています。
理由 ① 学習データに基づいてしか判断できない
LLM は過去に学習した大量のデータをもとに文章を生成します。
そのため、
- 学習データに存在しない事実
- 情報が足りない問い
に対しては、正確な答えを出せません。
理由 ②「次の単語を確率で選ぶ」という性質
LLM は「この文脈では、次にどの単語が来そうか」を確率で判断し出力し続けます。
その結果、本来なら「わからない」と答えるべき場面でも、確率から判断して文法的・文脈的に自然な単語を選び続けてしまうことがあります。
これが、
- 文章としては自然
- しかし内容は誤り
となり、結果的にハルシネーションにつながります。
※ 近年のモデル(例:GPT-5)では、このように当てずっぽうにするのではなく、「わからない」と判断させることで、ハルシネーションをなるべく発生させないよう対策しています。
まとめ
この章では、生成 AI を支える自然言語処理の基本的な考え方を整理しました。
- 単語はベクトル(数値)として扱われる
- 意味は文脈から学習される
- 文章理解・生成は機械翻訳の仕組みと深く関係している
次の第 3 部では、現在の LLM の中核となっている Transformer の仕組みを整理していきます。