プラン
簡単にできることはだいたいやりました。
ここからモデルの実用的な性能を向上させるには何をすればいいでしょうか。
現在2つのアイデアがあります。
1.データセットの画像になんらかの情報を追加する。例えば長期的なトレンドや取引量など。
2.いくつかのレイヤーで自動的に学ばせ、一番良い結果だけを保存することで寝てる間などに性能の向上を図る。
1番はやってみましたが、2番は明日からやります。
問題1.
データセットの画像のうち63.77%が"up"としてラベル付けされていて、このモデルは"up"を連発することを過学習してしまうかもしれない。
実際にはこのモデル及び一般的な深層学習などの目的は損失関数の最小化であって、精度は学習においてはあまり関係ないのでこれは問題にならないように思えます。
参考. 実験として"up"とラベル付けした画像を適当に取り除くことでデータセットの中の"up"と"down"の比率を1:1にして学習をさせてみました。
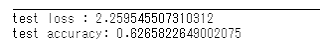
75 epochsの後この結果が得られました。
これでデータセットの不均衡が与えるモデルの予測精度への影響がわかるわけではありませんが、少なくともこの結果はこのモデルがコイントスで決めるBotよりはずっと性能がいいことがわかります。
問題2.
データセットやモデルが極端に単純化されているため、このモデルの唯一の機能はちょうど2カ月後の価格が上がっているか下がっているかを判断するだけになっていて、その期間の価格変動は考慮されていません。故に現実的な運用は危険かもしれません。
実用性を考える。
モデルに金融市場について最大限の情報を教え込むためにデータセットの画像に取引量を追加しました、悪いアイデアではなさそうですが、問題は取引量のスケールが画像毎に違うことがあることです。 Pyplotについてもう少し学ぶ必要がありそうです。
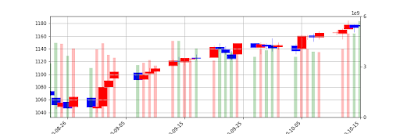
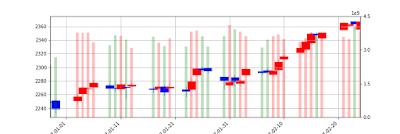
2010年からの2203個の画像をPythonに学ばせます。
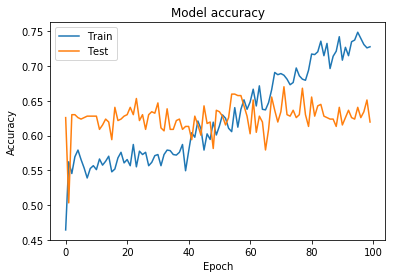
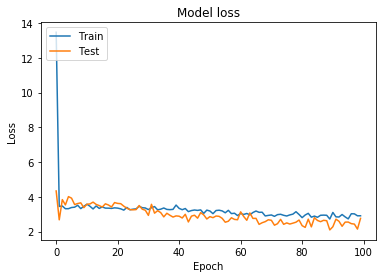
60 epochsくらいがいい感じに見えるので Epochs = 60に設定してもう一回やってみます。
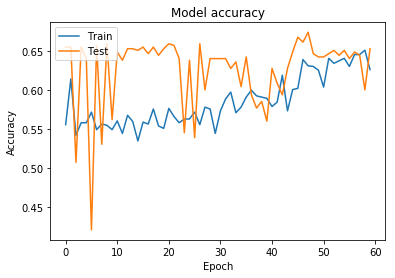
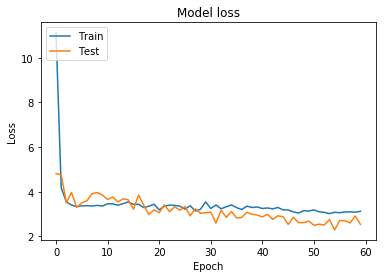
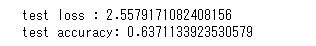
良い感じに見えます。
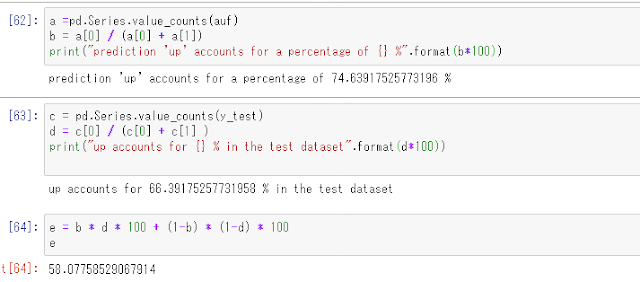
このモデルがテストデータを使って予測を行う時、 74.64%の確率で”up”と答えており、また全てのテストデータセットのうち66.4%は”up”のラベルを付けられています。
モデルが完全にランダムに74.64%の確率で”up”を出力する場合、このテストデータでテストした際の精度の期待値は58.07%ですので63.7%の精度を持つこのモデルは少なくともあてずっぽうよりは高性能だと言えます。
結論
このモデルは相場がほぼ常に上がると思っているいわゆるロンガー脳になってしまっており、実用性があまりないように感じられます。しかしながら一方でこのモデルが景気後退の兆候を察知するために使える可能性があるように思えます。できる限り”up”を出力しようとするモデルが”down”を答えとして出力するとき、その判断の背後に何かがあってもおかしくないからです。これからこのモデルの結果と予測を調査してそれが可能かどうか試してみます。
現在このモデルやデータセットは多くの問題をかかえています、一つひとつ問題解決していきいつかは実用的なAIを作りたいです。
余談ですが、自分のパソコンに学習をさせていると処理にかかる時間に驚かされます。量子コンピューターの記事をニュートンで読んだことがありますが、この処理にかかる時間が革新的に短くなるとすればAIと量子コンピューターの相性は抜群ですね。
今後の方針
1.取引量の追加の仕方があまりにもひどいのでpyplotについて学ぶ
2.リーマンショックのデータも学ばせる
3.実際の市場で試してみる
4.データ量を10倍以上にする。
現在はアメリカの代表的な企業40と日本の企業からトヨタのデータを使っていますがこれをS&P500の企業と日経平均225の企業全部までに広げたいと思います。それとも二つのETFのみデータとして使うのがいいのでしょうか。とにかくこれを試した後も使うデータについては色々試行錯誤したいと思います。 次からはどのデータを学習したかについても明記したいと思います。
また来週。